 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Поэтому ретейлеры стремятся увеличить точность сегментации, но это также означает усложнение модели. И здесь помогает машинное обучение (ML): оно повышает точность прогнозов и позволяет ответить на насущные вопросы.
1. Что купит клиент?
Клиентов часто теряют, когда в магазине нет нужного товара. Например, женщина каждый месяц покупает крем за 10 тысяч рублей, и у нее рядом с домом два магазина косметики. В одном крема часто нет, во втором — есть. Скорее всего, она пойдет во второй, даже если там дороже, просто чтобы не тратить время.
2. Как оптимизировать работу персонала?
Несложный пример — планирование рабочих смен для кассиров и продавцов-консультантов.
Один путь — статистический анализ. Аналитик смотрит на поведение клиентов в зависимости от дня недели и видит, что в субботу покупают больше всего, а в пятницу и в воскресенье чуть меньше. После проверки статистическими тестами достоверность этой гипотезы подтверждается, выводы передают бизнесу для составления расписания персонала.
А если рассмотреть вариант, когда 7 марта приходится на среду? Купят ли в день перед женским праздником меньше, чем в пятницу 9 марта? А выпускные? Или местные праздники? Тут много факторов, которые нельзя объять простыми правилами. Вместо того чтобы усложнять правила и вводить исключения, можно построить модель, которая сделает прогноз для потока клиентов на конкретный день.
ML помогает в самых разных случаях. Ниже мы рассмотрим кейс, который реализовали для одного из крупнейших ретейлеров России. Мы построили 2 модели и сделали прогноз, кто из клиентов придет в магазины в ближайшие две недели и что купит.

Размер маркера на рисунке показывает распределение дохода в разных регионах. Мы привыкли, что Москва и Санкт-Петербург являются лидерами по всем показателям — суммарному доходу, среднему чеку и, разумеется, числу клиентов. Но один из больших городов России заметно опережает их по среднему чеку.
А значит, сосредоточив маркетинговые усилия лишь на двух столицах, мы потеряем потенциальную прибыль в перспективных регионах.

Профиль трат клиентов одной и той же возрастной категории варьируется в разных регионах, он зависит от множества факторов, которые сложно учесть только бизнес-правилами. Если магазин находится в районном центре, многие клиенты заходят в него редко, но метко: разом покупают товаров на большую сумму. Значит, им нужно предложить оптимальную «корзину» незадолго до их следующего визита вместо частых промопредложений. В другом регионе клиенты ходят в магазин чаще, так что можно повысить чек на один визит за счет маркетинговых акций или индивидуальных предложений.
Для создания моделей были взяты данные за несколько лет:
- По чекам: кому принадлежит бонусная карта из чека, когда сделана покупка, что купили, какова была скидка, покупка это или возврат.
- По людям: регион и город, дата рождения и пол, согласие на рассылки по телефону или по почте.
- По товарам: к какой категории или сегменту они принадлежат, область применения и т.д.
Мы убрали шум из данных (карты продавцов, возвраты, покупки услуг, а не товаров) и посчитали нужное (процент скидки, возраст). Дальше мы могли бы долго и утомительно описывать агрегацию данных для моделей, но не думаем, что это важно. Гораздо интереснее результат. Первая модель предсказала треть покупателей, которые придут в ближайшие 2 недели. Вторая выдавала рекомендации: товары, которые человек купит, причем вместе с артикулами. В итоге 30% клиентов приобрели хотя бы один товар из спрогнозированных моделью.Благодаря нашим разработкам сеть узнала клиентов в лицо и теперь может прогнозировать продажи на будущее: ретейлер знает, кто придет к нему в ближайшее время и что купит. Например, если конкретный клиент традиционно ничего не покупает зимой, то не нужно отправлять ему дорогостоящее SMS в январе. Модели также оптимизируют рассылки: человек, отвечающий за них, смотрит на прогноз и сразу понимает, кому послать e-mail, а кому срочное SMS.
После очистки данных мы знали самый большой и самый маленький чек у каждого покупателя, среднюю, медианную и максимальную скидку, сколько раз он приходил и сколько товаров из каких категорий покупал. Эти параметры пересчитали на промежутки: последняя неделя, 2 недели, месяц, 3 месяца. Такая скрупулезная работа позволила построить модели с высокой точностью прогнозирования.

На рисунке показаны «типичный месяц» и «типичная неделя». Для дней недели дополнительно указан интервал ошибки.
В течение «типичного месяца» нет праздников, поэтому распределение по неделям очень схоже. Но в феврале или марте мы бы увидели, как это распределение изменяется при приближении 23 февраля и 8 марта под влиянием дополнительных факторов.
Конечно, не обошлось без подводных камней. Например, в ходе проекта мы также определяли влияние рассылок с товарной рекомендацией — проверяли, приводят ли напоминания клиентам о товарах к покупкам.
Для этого предсказанный сегмент покупателей разделили на 3 группы:
- Контрольная — ничего не посылали.
- Группа с напоминаниями — посылали общий текст от магазина.
- Группа с рекомендациями — посылали SMS с конкретными товарами, предсказанными моделью.
Благодаря нашим разработкам сеть узнала клиентов в лицо и теперь может прогнозировать продажи на будущее: ретейлер знает, кто придет к нему в ближайшее время и что купит.
После эксперимента мы проанализировали результаты и выяснили: люди, заранее получившие рекомендации, покупали меньше, чем клиенты, не получавшие сообщений. Были меньше и средний чек, и количество приобретенных товаров. Сказать, что ситуация обескуражила, — значит не сказать ничего. Стали искать, в чем причина, и выяснили, что магазины отправляли клиентам сообщения в определенный мессенджер, а его пользователи в нашем сегменте изначально покупали меньше по сравнению с другими клиентами. Об этом не знали даже сами маркетологи ретейлера. Так что эксперимент получился нечистым, но по его итогу мы ввели в модель параметр «пользователь мессенджера». Этот эпизод показывает, как тщательно нужно выбирать каналы для общения с клиентами.
Отсюда можно сделать 2 вывода:
- Данных много не бывает.
- Иногда взгляд аналитика со стороны дает свежую идею.
Планирование складов — прогнозирование продаж
Дальше у проекта возможны несколько вариантов развития. Например, можно прогнозировать покупки в конкретном магазине — модель будет показывать, что в нем купят в ближайшее время. Тогда администратор магазина сможет вовремя заказать со склада нужный товар.
Анализ покупок в конкретной торговой точке поможет сформировать выкладку товаров. Так, если в магазин приходит много покупателей-мужчин, отдел с мужской продукцией не стоит размещать в дальнем углу.
Нельзя забывать о каннибализации магазинов. Если две точки продаж одной сети находятся рядом, одна может оттягивать поток клиентов на себя, а второй магазин будет простаивать. Можно построить модель, которая будет отслеживать подобные явления и сигнализировать об этом. И эту ситуацию можно будет легко предотвратить — принять меры.
Машинное обучение — мощный инструмент, который может многое: от прогнозирования потока клиентов до отслеживания каннибализации магазинов. Но это невозможно сделать без данных и за несколько дней, иначе мы получим модель, «состряпанную на коленке». Часто при построении моделей выявляются неочевидные закономерности, о которых не знали даже бизнес-пользователи. За построением качественного анализа данных всегда стоит целая команда специалистов — аналитиков Data Science, тестировщиков, Data-инженеров и многих других. Именно их опыт, внимательность и нацеленность на результат гарантируют вам качественный прогноз.




Александра Царева
аналитик Дирекции по разработке и внедрению программного обеспечения компании «Инфосистемы Джет»
Комментарий
Сегментация клиентов
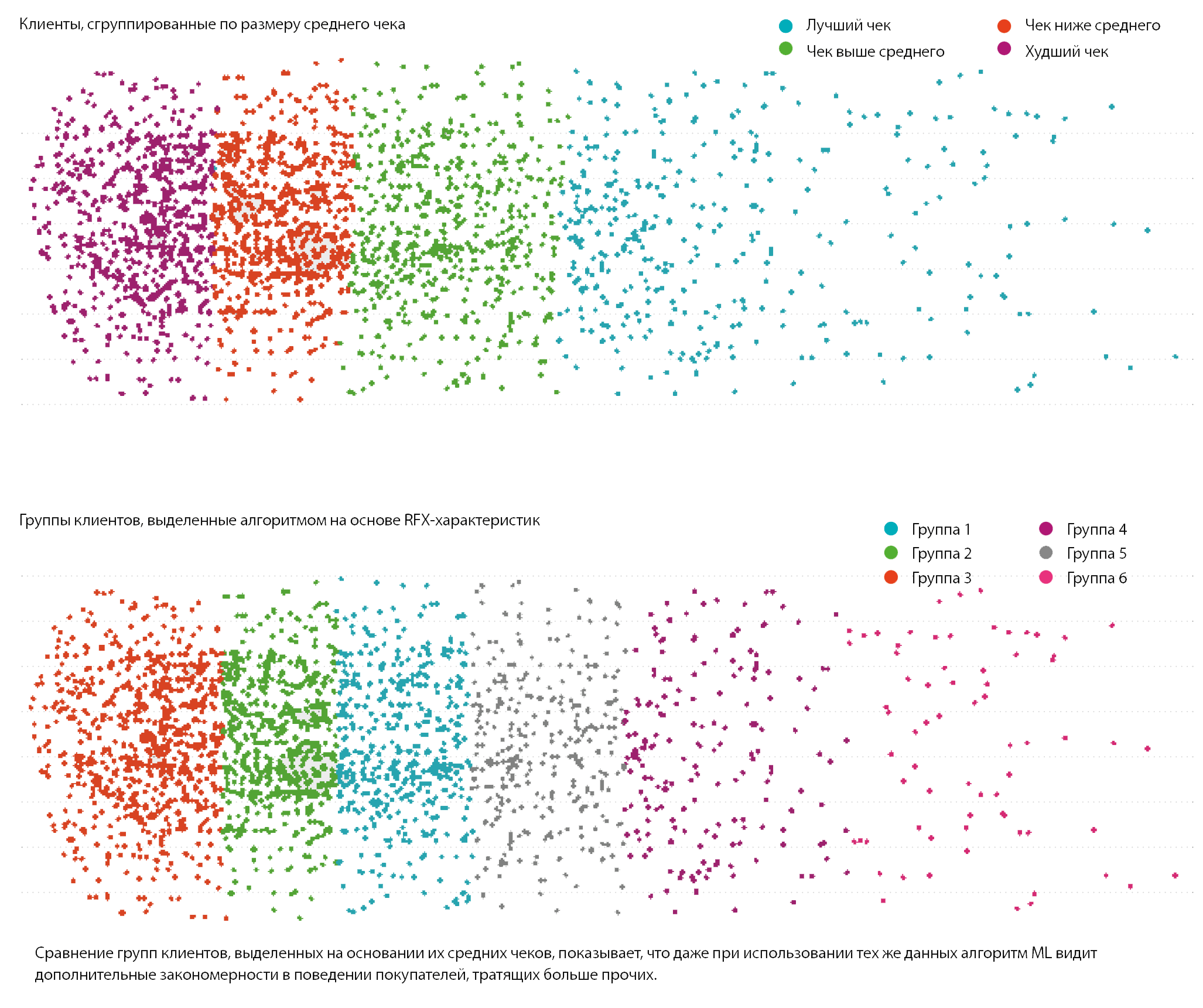
Применение науки о данных позволяет обнаружить новые закономерности, которые были скрыты в доступной до этого информации. Хорошим примером служит сравнение групп клиентов через RFM-сегментацию (Recency Frequency Monetary) и сегментацию с использованием алгоритмов ML.
RFM-сегментация основана на использовании трех основных показателей: давности последней покупки, частоты покупок за период в целом и суммы, потраченной клиентом. На основании этих данных выделяют основные группы: «транжиры», «лояльные клиенты», «почти потерянные клиенты» и т.п., — что позволяет маркетологам включать нужную целевую группу в определенную рассылку или делать предложения именно для этой группы.
Например, на основании RFM-сегментации мы можем выделить сегменты покупателей и представить их как точку в трехмерном пространстве (рис.6)
RFM-сегментация клиентов показана в трехмерном пространстве «средний чек — частота покупок — число дней с последнего визита» и в проекции этого пространства на плоскость. Эта визуализация позволяет маркетингу сделать предварительные выводы о структуре клиентского поведения и распределении клиентов по группам.
Такая экспресс-визуализация позволяет нам представить, как среди всей массы клиентов распределяются различные группы, какая между ними пропорция в настоящий момент и как она изменилась в исторической перспективе.
Вернемся к нашим клиентам, представленным «на плоскости». Да, можно разделить их по доходу, который они приносят, чтобы включать в маркетинговые кампании самых доходных, но будет ли этого достаточно для эффективного планирования?
Алгоритм машинного обучения даже в этих весьма распространенных данных уже видит дополнительные возможности: проанализировав их, он разбивает клиентов на 3 группы. Можно провести более глубокий анализ и узнать, например, по каким причинам алгоритм относит покупателей к тем или иным категориям. Возможно, часть высокодоходных клиентов составляют стилисты, сопровождающие своих заказчиц на шопинге и использующие свои скидочные карты, а некоторые могут активно делиться своей карточкой с другими — таким образом появляются показавшиеся алгоритму значимыми особенности в визитах покупателей. В любом случае найти ответы на эти вопросы можно, внимательно изучив данные и собрав дополнительную информацию о своих клиентах по результатам уже первого применения алгоритмов машинного обучения.
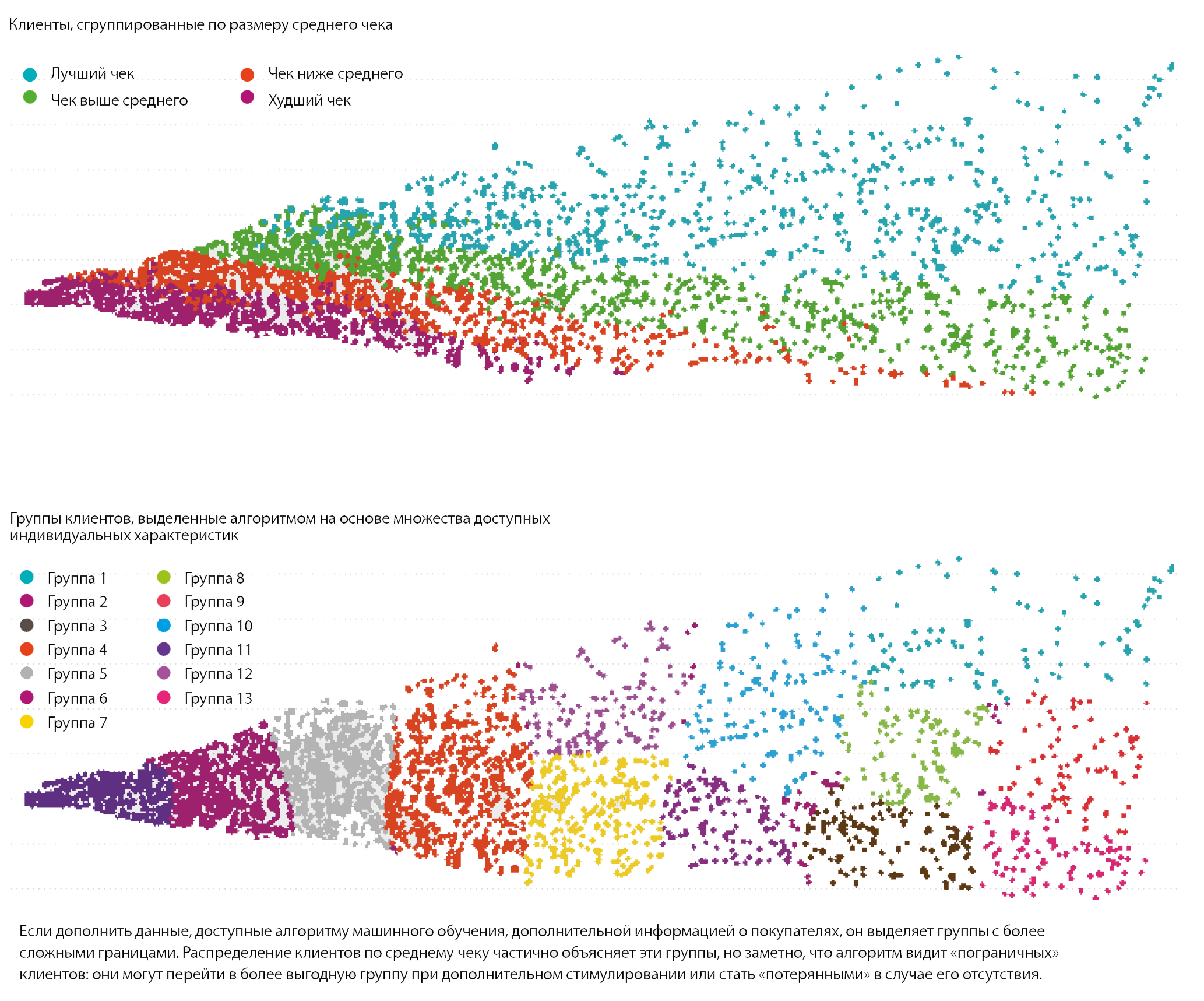
Посмотрим на распределение все тех же клиентов, которые были классифицированы с помощью RFM-характеристик, но теперь их профиль был дополнен новыми данными по полу, возрасту, особенностям покупательского поведения и др.
Само по себе изменение расположения точек на плоскости никакого нового знания не дает: это просто проекция, призванная максимально сохранить их положение. Но если сравнить, какие выводы делает алгоритм на основании дополнительных факторов, с распределением клиентов по уровню трат, становится понятно, что он заметил новые особенности.
Например, есть группа, которая охватывает как лучших клиентов, так и их «соседей», приносящих меньшую прибыль. Выделение причин, которые стоят за решением алгоритма, — вопрос для аналитика. Эта группа может включать клиентов, которые при дополнительном стимулировании покажут большую доходность. Или, напротив, вошедшие в эту группу клиенты с большей доходностью на самом деле не особо перспективны и повышение доходности было случайным отклонением — стимулировать их дополнительно бессмысленно. Эти и другие теории выдвигаются в кабинетах, но проверяются экспериментально: они позволяют узнавать больше о клиентах и развивать алгоритмы, помогающие найти неочевидные для человека взаимосвязи.