 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Задача обработки потока финансовых сообщений может быть разбита на три основных этапа. Для полученного сообщения необходимо выделить его структурные элементы — произвести разбор. Разобранное сообщение помещается в базу данных для хранения и последующей обработки. Обе операции оформляются как единая транзакция (неделимое действие). Далее информация из сообщений, находящихся в базе данных, преобразуется в поток финансовых транзакций и/или поток новых сообщений, возможно, в другом формате. Входной поток сообщений может поступать как от внешних (интерфейсных) систем, так и от внутренних систем банка, которые генерируют сообщения для взаимодействия друг с другом и с внешними системами.
Первый этап обработки связан с разбором сообщения, записанного в определенном формате. При этом возникают проблемы, связанные с отсутствием единого стандарта на форматы сообщений. Так, если в области расчетов в валюте существует стандарт SWIFT, то для рублевых платежей подобный стандарт пока не разработан и многие банки создают свои форматы, которые внедряют среди банков-корреспондентов. В результате банки все чаще сталкиваются с проблемой поддержки многих форматов, что требует от разработчиков автоматизированных систем создания универсального механизма описания форматов сообщений. Кроме того, периодические изменения стандартов (SWIFT делает это раз в год) приводит к необходимости быстрого "включения" нового формата в цикл обработки.
Многообразие форматов сообщений предъявляет особые требования к структуре базы данных, где разобранные сообщения должны храниться для последующей обработки. Желательно, чтобы появление нового или изменение существующего формата не приводило к модификации схемы базы данных, что, в свою очередь, устраняет необходимость изменения модулей прикладных программ, осуществляющих доступ к данным.
Заметим, что с момента поступления сообщения в систему обработки до его сохранения в базе данных существует вероятность потери сообщения в случае сбоя системы. Возможность такой ошибки должна быть исключена. Для этого два первых этапа — разбор и сохранение — оформляются как единая транзакция, а возникновение ошибки на любом из них приводит к "откату" всех изменений. Если в системе предусматривается загрузка пачки сообщений (batch file), то необходимо иметь механизм работы с точками сохранения, что позволит возобновить процесс загрузи при возникновении сбоя. При этом, данный механизм должен обеспечивать отсутствие потерянных или повторно загруженных сообщений.
На заключительном этапе система должна произвести действия по обработке ранее полученных сообщений. Основные трудности при этом связаны с неполнотой и недостоверностью информации, выделенной из финансового сообщения. Примером такой ситуации является несоответствие имени получателя платежа и номера счета, принадлежащего данному клиенту. Это может возникнуть, например, вследствие ошибок, внесенных при вводе сообщения его отправителем. В системе должны быть реализованы специальные методы, позволяющие осуществить принятие решения в условиях подобной неопределенности. При этом, вероятность неправильного зачисления должна быть близка к нулю.
Таким образом, можно сформулировать основные требования к системе обработки сообщений. К группе общих требований, безусловно, относятся надежность, эффективность и гибкость системы. Необходимо отметить и требования к безопасности, так как система обрабатывает финансовую информацию. Как отмечалось выше, наличие средств описания форматов и универсальных методов хранения сообщений, а также средств обработки транзакций, является необходимым условием работы системы. Еще раз отметим, что основной целью создания системы является изменение технологии работы, позволяющее сократить ручное вмешательство в процесс обработки, тем самым повысив пропускную способность при снижении стоимости обработки.
База данных сообщений
В Прил. I рассматриваются основные моменты решения задачи выделения структурных элементов сообщения. После получения дерева вывода сообщения необходимо сохранить данную структуру для последующей обработки. Возможности, предоставляемые языком описания формата (Format Definition Language, FDL) по описанию новых форматов, должны поддерживаться методами хранения сообщений. База данных должна состоять из двух частей, одна из которых содержит информацию о формате сообщения, другая — собственно сами сообщения. В части описания формата для каждого символа языка FDL определяются имена объектов базы данных, где хранятся значения данного символа. Таким образом, структура базы данных позволяет сохранять сообщения в произвольном формате, если информация о формате (в виде данных) внесена в базу данных форматов.
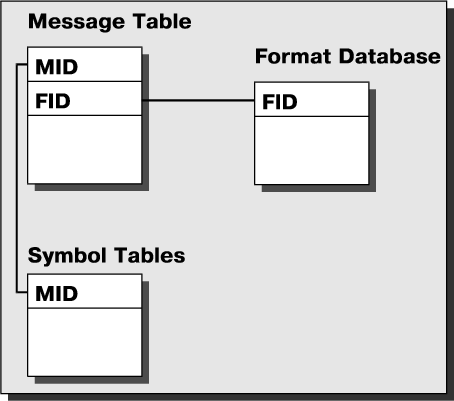
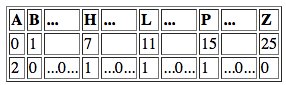
Рассмотрим более подробно структуру базы сообщений. Значения символов, составляющих сообщения, хранятся в отдельных таблицах реляционной базы данных. Набор таблиц определяется множеством типов значений символов предметной области. Так, большинство финансовых сообщений содержат символ, значение которого соответствует сумме финансовой транзакции, выраженной в определенной валюте. Таким образом, в базе должна существовать таблица, столбец которой имеет тип данных, соответствующий числам с фиксированной точкой. Для каждого значения символа, помещенного в базу данных сообщений, нужно хранить указатель на сообщение, которому символ принадлежит. Таким указателем является уникальный номер сообщения в базе данных — Message Identifier (MID). В базе данных существует таблица, содержащая заголовки всех сообщений, в которых хранится общая информация для данного сообщения. Доступ к записям таблицы заголовков осуществляется по значению поля MID, которое является уникальным ключом. Одним из полей данной таблицы является поле FID (Format Identifier) — код формата сообщения. По значению поля FID система выбирает информацию о формате сообщения (Рис. 1).
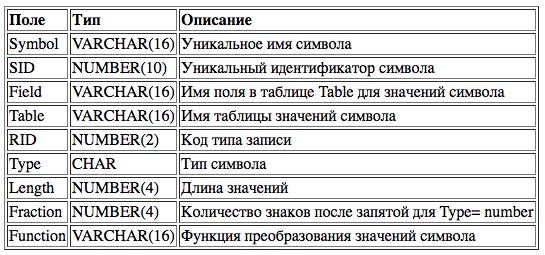
Структура таблицы форматов символов приведена в Таб. 1.
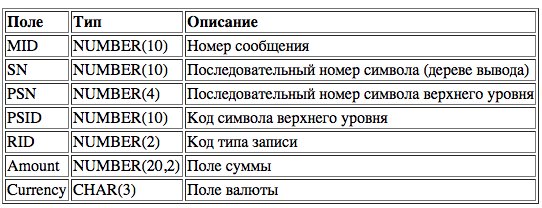
Таблицы, содержащие значения символов, должны допускать хранение значений нескольких символов в одной записи. Для этого необходимо организовать соответствие между именем символа и именем поля базы данных. Каждая запись в таблицах символов имеет поле RID (Record Identifier), а информация о формате символа содержит имя поля в таблице и значение RID, которое определяет множество записей, где хранятся значения символов. В Таб. 2 приведен пример структуры таблицы AMOUNT, содержащей значения сумм транзакций с указанием кода валюты.
Запись в базе данных форматов для символов AndAmount и Currency имеет вид, приведенный в Таб. 3.

Для простоты изложения в приведенном примере не показаны колонки, соответствующие другим атрибутам символов. Заметим, что значение поля SID является ключом в таблице символов. Хотя имя символа (колонка Symbol) и является уникальным для каждого символа, мы используем более короткий ключ для обеспечения реляционных связей. Если символы TnxAmount и TnxCurrency отличаются по формату от символов AndAmount и Currency (причина, по которой они были введены), но их значения могут храниться в той же таблице AMOUNT, то соответствующие записи в базе форматов должны иметь вид, приведенный в Таб. 4.

Примеры записей, которые могут хранится в базе данных сообщений приведены в Таб. 5.
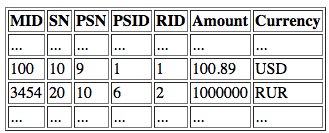
Первая запись относится к значению символов AndAmount и Currency, которые имеют последовательные номера 10 и 11 соответственно, а вторая строка определяет значения для TnxAmount и TnxCurrency, последовательные номера 20 и 21 соответственно. Для того, чтобы определить имя символа, которому соответствует элемент в таблице значений, необходимо сформировать ключ доступа из имени таблицы, имени колонки и значения поля RID. Таким образом, для суммы 100.89 из первой записи приведенного примера система может определить значение ключа поиска в таблице форматов как (stAMOUNT, Amount, 1) и по этому значению определить имя символа AndAmount.
Заметим, что в структуре сообщения присутствуют символы, которые не содержат конкретных значений. Такие символы являются "предками" других символов в дереве вывода сообщения. Для хранения этих символов в базе данных сообщений достаточно иметь общую таблицу, в которой присутствуют только служебные поля — MID, SN, PSN, PSID, RID.
Рассмотрим более подробно назначение поля Function в таблице форматов символов (Таб. 1). При сохранении символов в таблицах базы данных в некоторых случаях необходимо проделывать преобразования значений символов. Так, сумма транзакции в формате сообщения SWIFT содержит символ запятая в качестве разделителя целой части числа. Семантика языка SQL не допускает использование запятой в качестве части числа (NUMBER). Таким образом, для сохранения значений суммы необходимо провести преобразования числа в формат базы данных. Данное преобразование задается в виде значения поля Function и в приведенном примере оно равно строке "TO_NUMBER". По символическому имени система вызывает функцию и передает ей в качестве параметра сохраняемое значение. При извлечении символа из базы данных проводится обратное преобразование.
Для обеспечения доступа к сохраненным сообщениям используется язык запросов (Мета-SQL), где имена объектов базы данных заменены на "пути" к символам FDL в заданной структуре сообщения. Так, для выбора всех платежей в американских долларах может быть построен запрос следующего вида:
select * from MT100
where MT100.Amount.Currency =
'USD'
Опишем действия подсистемы доступа к базе данных по выполнению приведенного выше запроса. Вначале необходимо произвести разбор данного предложения на Мета-SQL и выделить имена символов, участвующих в запросе. Так, символ, стоящий в части предложения FROM определяет имя формата запрашиваемых сообщений. По данному имени выбираются характеристики символов, которые могут входить в сообщения заданного формата. Символ Amount включает в себя базовый элемент Currency, для которого подсистема определяет имена таблицы и колонки, хранящих значения данного символа. Эту информацию подсистема извлекает из базы форматов сообщений. После того, как установлены реальные объекты базы данных, программа должна преобразовать запрос на Мета-SQL в запрос системы управления базой данных на соответствующем ей языке запросов. В нашем случае таким целевым языком является SQL.
Безусловно, необходимо иметь возможность построения отношений на множестве сообщений. Предположим, что стоит задача найти пары сообщений SWIFT, связанные между собой по значению поля 20 (Transaction Reference Number). Запрос на языке запросов к базе данных сообщений может выглядеть следующим образом:
select * from MT100, MT910
where
MT100.TRN = MT910.TRN
Заметим, что запросы на Мета-SQL преобразуются системой в запросы на языке SQL, а, следовательно, основные конструкции языка SQL поддерживаются в данном языке запросов. Следующий пример использует конструкцию LIKE языка SQL для поиска всех платежей формата РКЦ (MAKET3), содержащих код МФО, который начинается со строки '99'.
select * from MAKET3
where
MAKET3.CLIB like '99%'
Остается открытым вопрос о том, каким образом информация о формате попадает в базу данных форматов сообщений. Решением данной проблемы может быть преобразование программы на языке FDL в некоторые данные, содержащие необходимую информацию о формате и способе хранения символов сообщений. Для этого в FDL вводятся дополнительные свойства символов языка. Так, значение свойства TABLE определяет имя таблицы, где хранятся значения символа, а свойство FIELD задает имя поля в данной таблице. Ниже приведен пример определения символа с заданными значениями свойств TABLE и FIELD.
define CLIB as field {
MATCH=9(.*)
TABLE=stBANKCODES
FIELD=Code
};
После того, как сообщение выбрано из базы данных посредством выполнения запроса на Мета-SQL, оно помещается в память программы в виде структуры данных, названной структурой сообщения. Система должна обеспечить набор функций (API), работающих с данной структурой. Основой данного интерфейса является функция извлечения значения символа по заданному символическому имени. При этом нужно учитывать, что один и тот же символ может встречаться в разным местах сообщения и иметь в этом случае разную семантику. Таким образом, для получения значения символа функция принимает в качестве аргумента строку, описывающую путь до нужного символа по дереву вывода сообщения. Например, следующий вызов извлекает значение для валюты платежа сообщения SWIFT MT100 (параметр msg — указатель на структуру сообщения):
Currency = getSymbol (msg,
"Amount.Currency");
Для эффективной работы с символическими именами применяются методы хеширования, позволяющие по имени символа извлечь из оперативной памяти загруженную из базы информацию. Заметим, что для повышения производительности системы информация о форматах может загружаеться в память процесса доступа к базе данных сообщений.
Транзакции с точками сохранения
Описанные выше первые два этапа обработки потока сообщений представлены единой транзакцией, что должно исключить потерю или повторную загрузку сообщений. Заметим, что время выполнения одной транзакции должно быть достаточно мало, чтобы гарантировать успешное ее завершение. Это, как правило, связано с двумя аспектами механизма обработки транзакций. Во-первых, каждая транзакция требует определенного количества ресурсов в процессе своего выполнения. Количество ресурсов и время, на которое они предоставляются, пропорциональны стоимости выполнения транзакции. Кроме того, длительные транзакции, отвлекая большое количество системных ресурсов, могут существенно снижать производительность системы в целом, а отсутствие необходимых ресурсов для завершения транзакции приводит к ее "откату" и потере всех результатов ее работы. Во-вторых, вероятность возникновения сбоя для длительной транзакции больше, чем для транзакции, выполняющейся доли секунды.
Длительные транзакции в системе обработки сообщений возникают при загрузке пачки (batch file) сообщений. При этом каждое сообщение должно быть считано из пачки, разобрано и сохранено в базе данных. Таким образом, общий процесс загрузки разбивается на этапы загрузки отдельных сообщений, каждый из которых представляет собой короткую транзакцию. В рамке данной транзакции по загрузке одного сообщения система осуществляет запись в специальный журнал точек сохранения, где хранится информация, позволяющая возобновить работу с заданного места в случае возникновения сбоя. Данный механизм позволяет избежать выделение большого количества системных ресурсов и повышает надежность процесса загрузки.
Обработка сообщений
Рассмотрим основные моменты, связанные с обработкой сообщений. Задачей данного этапа является минимизация количества ручного труда, необходимого для обработки потока сообщений. Чем больше сообщений обработано без участия человека, тем больше производительность системы и ниже стоимость обработки. С другой стороны, требования безопасности и надежности не позволяют перевести всю обработку в автоматический режим.
Как уже отмечалось выше, одна из основных проблем обработки сообщений обусловлена тем, что информация, извлеченная из сообщения, часто является недостоверной и противоречивой. Данная проблема не возникает для простых форматов, где передаются коды и отсутствует текстовая информация (МАКЕТ 3), но для сложных форматов, таких как формат SWIFT, является одной из основных. Приведем простой пример. Предположим, что получено сообщение SWIFT MT100 (платежное поручение) и по нему необходимо произвести зачисление средств на счет номер 70000194, принадлежащий компании "ALPHA INTERNATIONAL". При этом в имени компании в поле 59 сообщения MT100 (поле 59 содержит номер счета и имя получателя платежа) содержится ошибка и произведено сокращение слова в названии. Таким образом, полученная информация может иметь следующий вид:
59:/70000194
ALHA INT.
Возможны различные варианты работы системы в этом случае. Во-первых, система может произвести автоматическое зачисление, но будет ли это правильно, если, предположим, другим клиентом банка является фирма АО "АЛЬХА", имеющая номер счета 70000193. Второй вариант работы предусматривает вмешательство оператора, что, в свою очередь, приводит к потерям в производительности.
Безусловно, существуют различные методы работы с частично искаженной информацией. В описываемой системе была построена знаковая статистика на строках имен и для каждого клиента хранилось множество допустимых имен со значениями статистики. При этом, система осуществляет проверку достоверности имени в рамках описанного множества допустимых искажений (пропуск символа, добавление символа, замена символа), так что имя считается правильным, если значение статистики на нем не больше заданного порогового значения.
Рассмотрим пример построения знаковой статистики на множестве имен клиентов банка. В качестве характеристики имени (строки символов) введем вектор целых неотрицательных чисел (n1, n2, n3,..., nk), где k — количество символов в алфавите, из которого составлены строки имен. Каждая позиция i в векторе соответствует коду символа в алфавите и содержит количество символов, встретившихся в строке с данным кодом i. В качестве примера в Таб. 6 приведено значение вектора для имени ALPHA.
Для каждого клиента банка может существовать множество различных имен, набранных в результате анализа сообщений, приходящих на имя клиента. В начале своего существования база данных имен пуста и по мере получения сообщений система проводит "обучение", запоминая новые допустимые имена с их векторами характеристик. Добавление имени в базу происходит под руководством оператора системы, который и принимает решение о том, что входная строка является новым вариантом имени клиента. После того, как в базе имен накапливается достаточное множество вариантов, система начинает работать в режиме сравнения характеристик имен. Для этого необходимо определить меру близости векторов характеристик и некоторое пороговое значение, которое определяет множество "почти одинаковых" строк имен. В качестве меры расстояния рассмотрим следующую функцию, заданную на множестве пар векторов:
![]()
где символ S означает суммирование по индексу i от 1 до k. Заметим, что данная функция взята для демонстрации подхода к решению задачи, а в реальной системе используется более сложная функция. Выбор порогового значения для функции F осуществляется по количеству ошибок, которое считается допустимым при вводе имени клиента оператором, отправляющим сообщение, и должно гарантировать отсутствие ошибок, приводящих к принятию неправильного имени как допустимого для данного клиента. Остается заметить, что при правильном подборе функции F количество вариантов имен для данного клиента должно быть небольшим. Реально построенная система обеспечивает 70-80 процентов прямых зачислений (без участия оператора), если среднее количество имен на одного клиента равно 2,5-3. При этом исключается зачисление для неверно указанного имени клиента.
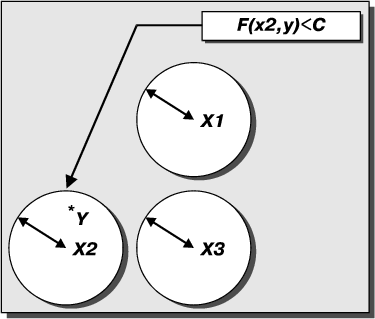
Рассмотренная выше задача возникает, когда задано значение образца (в нашем примере правильного имени клиента, вычисленного по значению счета) и необходимо установить вхождение характеристики образца в некоторую окрестность (в смысле функции расстояния) для заданного набора векторов (Рис. 2).
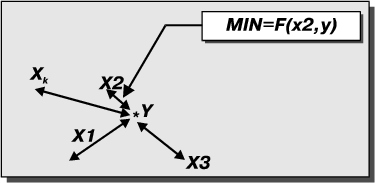
Более сложная проблема связана с определением для пришедшего значения имени значения образца из большого множества образцов. Примером подобной задачи является определение кода банка по его имени. В этом случае из множества заданных характеристик имен необходимо выбрать имя и соответствующий ему код, для которого "расстояние" до тестируемого вектора минимально (Рис. 3).
После решения проблем информационной неполноты сообщений необходимо преобразовать полученную информацию в соответствующие выходные форматы. Для такого преобразования может понадобиться дополнительная информация. Подобной информацией часто являются таблицы кодов и имен банков, таблицы перекодировки номеров счетов, информация о клиентах банка и многое другое. Данная информация может храниться в базе данных самой системы, а может быть получена и из существующих систем, например, из банковской системы.
Организация взаимодействия с другими системами
Система обработки сообщений должна взаимодействовать со многими программами банка, которые, как получают обработанные потоки сообщений, так и являются источниками входных потоков. Разработка интерфейсов к различным системам становится одной из важных задач создания системы обработки сообщений. Наличие языка описания форматов позволяет облегчить задачу разбора потоков входящей информации, но в любом случае остается необходимость написания интерфейсных модулей, которые адаптируют различные протоколы взаимодействия, существующие во внешних системах, к единому протоколу системы обработки сообщений.
Рассмотрим более подробно взаимодействие системы обработки сообщений и банковской системы. На вход банковской системы поступает поток транзакций (проводок), полученных в результате обработки сообщений. Поступление транзакций может осуществляться как в режиме on-line, так и в виде загрузки файла транзакций (batch mode). Если в банковской системе существует подсистема подготовки сообщений, то выходом этой подсистемы может служить поток сообщений, поступающий в систему обработки сообщений. Отметим, что необходимо иметь некоторую связь между проводками в банковской системе и сообщениями, хранящимися в базе данных системы обработки. Такое соответствие реализует система референсов — алфавитно-цифровых кодов, которые вносятся в качестве информационного поля в транзакцию и являются значениями определенных полей в финансовых сообщениях. По значению референса можно установить связь проводка-сообщение. Сообщения, поступающие от интерфейсных систем и непосредственно попадающие в систему обработки сообщений, могут порождать в банковской системе транзакции (проводки), которые, в свою очередь, должны быть источниками финансовых сообщений. Таким образом, система подготовки документов осуществляет доступ к базе данных сообщений для получения информации при формировании исходящих сообщений. Процесс генерации проводок для банковской системы может проходить как в автоматическом режиме, когда информация в сообщении является достаточно полной, так и в режиме просмотра предварительно сформированных транзакций оператором системы. Сообщения, поступающие от подсистемы подготовки документов, могут потребовать дополнительной обработки в системе обработки сообщений. Так, имена клиентов в сообщениях SWIFT могут приходить из банковской системы на русском языке, и их необходимо заменять на имена, записанные латинскими буквами.
На Рис. 4 приводится схема информационных потоков между системами.
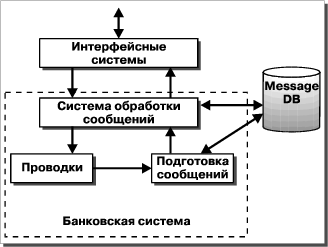
Ранее под внешними системами мы понимали системы, которые являются либо источниками финансовых сообщений, либо приемниками выходных потоков. С другой стороны, для решения задачи обработки сообщений необходима организация взаимодействия с программами, предоставляющими некоторые сервисные функции. Так, для генерации выходного потока платежных поручений, отправляемых по телексу, необходимо вычислить значение электронной подписи (тестового ключа) для каждого сообщения. Данная функция может быть реализована в отдельной системе, которая содержит собственную базу банков-корреспондентов.
Выбор инструментария
Выбор инструментария является важным этапом в процессе проектирования системы. Для реализации идей, описанных выше, в качестве основных средств были выбраны СУБД Oracle7 и монитор транзакций TUXEDO. В качестве языка программирования было решено использовать C/C++. Программы системы работают под управлением операционных систем MS Windows 3.1 и Solaris 2.3. Подробный анализ данных систем выходит за рамки этой статьи. Далее мы дадим лишь краткое обоснование сделанного выбора.
Рассмотрим основные достоинства использования монитора транзакций в системах обработки данных. Общую архитектуру системы, базирующейся на использовании монитора транзакций, можно представить в виде трехуровневой модели — клиент приложения (Application Client — AC) — сервер приложений (Application Server — AS) — менеджер ресурсов (Resource Manager — RM) [2]. В нашем случае в качестве менеджера ресурсов выступает Oracle7. Сервер приложений (AS) предоставляет программе клиента протокол взаимодействия с сервером базы данных, более высокого уровня, чем SQL. Программа клиента, обращаясь к AS, открывает транзакцию, в которую могут быть вовлечены несколько серверов приложений, работающих, возможно, с различными RM. Обработка такой распределенной транзакции производится монитором транзакций (TM).
Использование данной технологии приводит к организации среды распределенных вычислений на более высоком уровне по сравнению с классической моделью клиент-сервер. Монитор транзакций позволяет поместить основную часть обработки данных на более мощном вычислительном ресурсе — сервере, на котором работает программа сервера приложений. Размещение менеджера ресурсов и AS на одной машине сокращает сетевой трафик и увеличивает скорость обработки данных. При этом, клиент приложения общается с AS на более высоком, "прикладном" уровне. Разделение общей задачи, решаемой системой, на группы функций, реализуемых в различных AS, позволяет упростить разработку системы и ее дальнейшее развитие. Добавление новой функции (сервиса) приводит к изменению в соответствующем сервере приложения и не затрагивает остальные части системы. Новый сервис становится доступным клиентам приложений через стандартный интерфейс, предоставляемый монитором транзакций.
Монитор транзакций TUXEDO был выбран в качестве инструментального средства после того, как была получена и протестирована копия данного продукта, поставляемая Novell бесплатно. После детального тестирования и написания отдельных модулей будущей системы было принято решение об использовании TUXEDO для разработки системы.
Выбор системы управления базой данных проводился по результатам тестирования нескольких СУБД. СУБД Oracle7, обладая наивысшей производительностью по сравнению с другими системами, имела XA интерфейс к монитору транзакций, что позволяло использовать возможности TUXEDO по распределенной обработке. Заметим, что библиотека Oracle7, реализующая интерфейс XA (Oracle XA Library), входит в стандартную поставку. Особо отметим наличие двух методов оптимизации SQL запросов в Oracle7. Первый метод (Rule-Base Approach) основан на анализе предложения на языке SQL и определении множества путей доступа к данным (Access Paths) [3]. Каждому типу доступа приписан вес (Rank). Система весов статическая и не меняется от запроса к запросу. При Rule-Base оптимизации система выбирает путь доступа с наименьшим весом. Таким образом, при данном подходе использование индекса, построенного для колонки реляционной таблицы, всегда предпочтительней, чем последовательный доступ к записям базы данных. Второй метод оптимизации (Cost-Based) основан на анализе данных, лежащих в реляционных таблицах. Использование данного подхода предусматривает построение некоторой статистики на множестве таблиц, принимающих участие в запросе. Данный метод оптимизации эффективен при использовании динамического SQL, когда предложения языка запросов формируются во время выполнения программы, что важно для построения системы обработки сообщений, где подсистема доступа к базе данных строит запрос на языке SQL по информации из базы данных форматов сообщений.
При создании больших систем необходимо иметь средства коллективной разработки. Данные средства позволяют осуществлять контроль за последовательностью вносимых изменений в исходные тексты программ, исключая возможность потери более поздних исправлений в результате копирования старых файлов исходных текстов. У разработчика появляется возможность автоматически отслеживать версии файлов и фиксировать их для отлаженной системы. В качестве такого средства была использована система SPARCWorks/TeamWare (SunSoft). Использование TeamWare позволяет создавать рабочее пространство (Workspace), где каждый разработчик хранит свою копию файлов исходных текстов [4]. Для проекта системы описывается иерархия рабочих пространств, где корневое рабочее пространство является местом хранения исходных файлов отлаженной системы. Для двух пространств, связанных отношением наследования, определяются два типа транзакции по перенесению файлов исходных текстов из одного пространства в другое. В момент совершения транзакции система проверяет допустимость копирования файлов, сравнивая версии файлов и время их модификации. При возникновении конфликта, когда происходит попытка затереть более "свежий" файл старой копией, система сигнализирует об этом и предлагает разрешить конфликт путем сравнения файлов специальной утилитой. Данный простой механизм избавляет разработчика от многих проблем, связанных с неконтролируемым внесением изменений в код программы.
Архитектура системы
Рассмотрим общую архитектуру системы обработки сообщений (Рис. 5) и опишем ее основные модули.
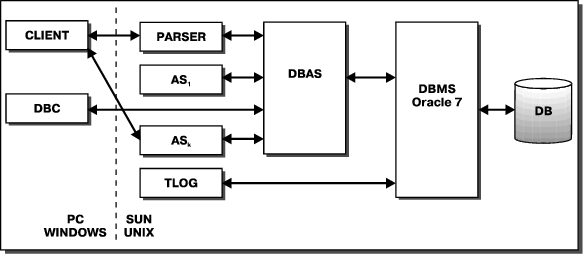
CLIENT — клиент приложения — программа, которая работает на PC под управлением MS-Windows. Осуществляет взаимодействие с внешними системами (например, ST400 — интерфейс с системой SWIFT), обрабатывает запросы пользователя, осуществляет управление транзакциями. Одной из основных функций клиента приложения является получение входного потока сообщений и выделение в нем отдельных сообщений. Данная программа выполняет роль адаптера внешних систем, обрабатывая различные протоколы обмена сообщениями. Так, для ST400 программа CLIENT получает входной файл, где сообщения разделены специальными символами, и осуществляет обработку формата данного файла.
Для работы с базой данных сообщений существует клиент приложения DBC (DataBase Client), который позволяет интерактивно вводить запросы на языке Мета-SQL, отображать полученные сообщения на экране и сохранять результат запроса в файле. Сами запросы могут быть сохранены для дальнейшего использования и могут содержать параметры, ввод которых осуществляется пользователем в момент выполнения запроса.
Приведем пример работы программы DBC. Предположим что пользователь хочет извлекать из базы данных все сообщения MT100 (SWIFT) для заданной даты и суммы платежа. В этом случае пользователь может создать и сохранить для дальнейшего использования запрос следующего вида:
select * from MT100
where MT100.ValueDate =
:Vdate
AND MT100.AndAmount =
:Amount
Обрабатывая данный запрос, программа DBC распознает :Vdate и :Amount как параметры запроса и запросит значения для этих параметров у пользователя. После выполнения подстановки параметров запрос отправляется на выполнение серверу приложений DBAS.
PARSER — сервер приложения — программа разбора сообщений. Получает текст сообщений от программы CLIENT, разбирает сообщение и получает его дерево вывода (структуру сообщения), передает полученную структуру сообщения серверу DBAS для сохранения в базе данных. Данный сервер имеет единственную функцию — PARSE.
DBAS — сервер приложений базы данных сообщений. Предоставляет интерфейс к базе данных сообщений в виде основных операций — вставка сообщения (DB_INSERT), запрос (поиск) (DB_SELECT), извлечение сообщения (DB_FETCH) и удаление сообщения (DB_DELETE). Операция DB_SELECT (сервис в терминах монитора транзакций TUXEDO) возвращает множество уникальных ключей (MID — Message ID) для сообщений, удовлетворяющих условию запроса. Для извлечения конкретного сообщения из базы данных используется сервис DB_FETCH. Запрос к базе данных сообщения записывается на языке Мета-SQL. Данный сервер приложений "скрывает" реальную реляционную структуру базы данных от остальных модулей системы, предоставляя интерфейс языка обращения к базе данных сообщений (Мета-SQL). Сервис DB_FETCH, получая на вход уникальный номер (ключ) сообщения в базе данных сообщений, возвращает структуру сообщения (дерево вывода). Для работы со структурой сообщений существует библиотека функций, позволяющая производить доступ к значениям полей сообщения по символическим именам полей.
TLOG — сервер журнала транзакций. Осуществляет журнализацию (logging) при обработке продолжительных по времени транзакций. Так, программа CLIENT вызывает TLOG при загрузке файла сообщений (batch file) из ST400. Данный сервер приложений предоставляет следующие функции:
- запись в журнал (TL_WRITE),
- чтение из журнала (TL_READ),
- открытие журнала (TL_OPEN),
- закрытие журнала (TL_CLOSE).
Перед началом длительной транзакции клиент приложения вызывает функцию TL_OPEN и открывает журнал для записи точек сохранения. При открытии журнала сервер TLOG проверяет существование ранее не закрытого журнала, а, следовательно, и не завершенной транзакции (длительной). Если обнаруживается существование такой транзакции, клиент приложения может прочитать последнюю запись, принадлежащую данной транзакции, и продолжить выполнение прерванного процесса. После каждого этапа транзакции клиент делает запись в журнал, вызывая функцию TL_WRITE.
AS — серверы приложений, осуществляют обработку сообщений, находящихся в базе данных. Данные модули используют DBAS для доступа к сообщениям. Так, программа генерации файла транзакций (проводок) для банковской системы выбирает сообщения из базы данных, определяет имя клиента банка, номера его счета, подготавливает детали проводки, сохраняет проводку в выходном файле. Добавление в систему новой функциональности сводится к написанию нового сервиса в существующем AS, либо к разработке нового сервера приложения. Кроме того, необходимо внести изменения в программу клиента приложения.
Отметим, что описанная архитектура системы позволяет быстро осуществлять подключение новых источников сообщений. Программа CLIENT реализует протокол взаимодействия с новой системой, преобразуя его в протокол вызовов сервера приложений PARSER.
Производительность системы
Приведем некоторые показатели производительности системы по загрузке и извлечению сообщений из базы данных. Для оценки времени работы программы была поставлена серия экспериментов для разного типа сообщений. Для каждого типа сообщений и для фиксированной операции (разбор-загрузка в базу и извлечение из базы) было сделано два замера времени для разного количества сообщений. Разность полученных замеров времени выполнения операций, деленная на разность количества сообщений, принималась за время выполнения операции для одного сообщения данного типа. Таким образом, если n — это количество обрабатываемых сообщений, а c — время обработки одного сообщения, то для двух измерений мы имеем следующее выражение разности:
![]()
, где T — общее время дополнительных действий, которое не зависит от количества обрабатываемых сообщений.
Разделив полученное выражение на разность
![]()
, мы получаем значение c. В Таб. 7 приведены результаты измерений, которые проводились на SUN SPARCstation 5.

Заметим, что наиболее сложным форматом является формат SWIFT. Соответственно, время на разбор и сохранение в базе данных сообщений данного формата больше, чем для других форматов. В проведенном эксперименте предполагалось, что длина сообщений MT100 одинакова для всех сообщений. Таким образом, в результирующей таблице измерения для сообщений формата SWIFT даны в виде время на сообщение (сек./ сообщение). Сообщения формата MAKET3 и Выписка РКЦ состоят из последовательности одинаковых строк. Для этих сообщений измерения проводились для отдельной строки сообщения. Заметим, что соотношение времени разбора сообщения к времени его сохранения в базе данных составляет приблизительно 2:1.
Заключение
Система обработки финансовых сообщений была разработаны на основе принципов, изложенных выше. Система обеспечивает обработку сообщений, получаемых из сети SWIFT и системы рублевых расчетов ASTRA (МАКЕТ 3). Полученные сообщения автоматически преобразуются в транзакции для банковской системы. Исходящие сообщения преобразуются системой в соответствующие выходные форматы и подготавливаются для отправки.
Использование технологии монитора транзакций позволило сократить время разработки системы и существенно повысило ее надежность.
Разработанный язык описания форматов сообщений (FDL) позволяет в короткие сроки "подключать" новые форматы сообщений. Так, время на введение нового формата, что означает возможность его загрузки в базу данных, составляет примерно день. Единый интерфейс к базе данных, который не зависит от формата сообщений, позволяет в короткие сроки проектировать и создавать серверы обработки сообщений.
Хочется отметить переносимость созданной системы. После того, как система обработки сообщений была разработана на компьютере SUN (SPARCstation 5), она была перенесена на платформу HP9000, где работает под управлением операционной системы HP-UX. Процесс переноса сводится к перекомпиляции исходных текстов программ. Поддержка соответствий двух версий для Solaris 2.3 и HP-UX осуществляется при помощи средств коллективной разработки SPARCWorks/TeamWare.
Выражаю благодарность Андрею Корневу за помощь в написании статьи, а также сотрудникам Информационно-технического Управления банка, принимавшим участие в создании системы.
Литература
- А. Ахо , Дж. Ульман -- Теория синтаксического анализа, перевода и компиляции -- М.: Мир, 1978
- TUXEDO System "Application Programming" -- UNIX System Laboratories Inc. (Novell)
- ORACLE7 Server Concepts Manual -- Oracle Corporation
- CodeManager User's Guide. SPARCworks/TeamWare -- SunSoft
I. Язык описания форматов сообщений
Рассмотрим основные моменты решения задачи выделения структурных элементов сообщений.
Дадим несколько определений.
Пусть задано множество символов (литер) ∑. Под сообщением будем понимать форматированный текст — строку в алфавите ∑, предназначенный для обмена данными между автоматизированными системами обработки информации.
Для дальнейших рассуждений нам понадобится определение грамматики [1]:
Грамматикой называется четверка G = (N, ∑, P, S), где
- N — конечное множество нетерминальных символов;
- ∑ — непересекающееся с N множество терминальных символов;
- P — конечное подмножество множества элемент которого (a, b) называется правилом грамматики;
- S — выделенный символ из N, называемый начальным символом;
![]()
Формат сообщений определяет множество допустимых, правильно построенных сообщений и задается набором правил. Формально формат может быть описан контекстно-свободной грамматикой (КС-грамматикой) [1]. При этом семантика (смысл) сообщения представляется деревом вывода сообщения в данной КС-грамматике. Для описания формата бывает удобно выделить набор элементов (нетерминальных символов), значения которых, выраженные цепочками в алфавите ∑, определяют значения базовых понятий предметной области. Примерами таких понятий могут служить <КОД ВАЛЮТЫ>, <ДАТА ВАЛЮТИРОВАНИЯ>, <СУММА>, <КОД БАНКА> и т.д. Путь от вершины дерева вывода, составленный из имен нетерминальных символов, до базового элемента определяет смысл значения базового элемента. Так, например, если символ <СООБЩЕНИЕ> является начальным (исходным) символом КС-грамматики формата, то цепочка <СООБЩЕНИЕ>.<ЗАГОЛОВОК СООБЩЕНИЯ>. <КОД БАНКА> задает код банка отправителя сообщения, а цепочка <СООБЩЕНИЕ>. <ТЕКСТ>.<КОД БАНКА> — код банка-получателя платежа (банка-бенефициара). Формат базовых понятий сообщений может быть описан более узким классом грамматик — классом праволинейных грамматик. В этом случае возможно задание форматов базовых элементов в виде регулярных множеств (выражений) в алфавите ∑.
Рассуждения, приведенные выше, привели к идеи создания языка описания формата FDL (Format Definition Language), использование которого позволило решить задачу первого этапа обработки сообщений.
В FDL формат представляется "программой" (скриптом) языка. Интерпретатор языка, выполняя скрипт, получает на выходе дерево вывода сообщения (структуру сообщения). Нетерминальные символы грамматики, описывающей формат, представляются символами (symbol) языка FDL. Символы обладают набором свойств (property), используемых интерпретатором для построения структуры сообщения. Так, свойство ЗНАЧЕНИЕ (VALUE) содержит в процессе выполнения скрипта значение данного символа — цепочку литер алфавита ∑. Формат базовых понятий (символов) задается регулярными выражениями языка, а правила грамматики — основными операторами FDL. Регулярное выражение, соответствующее символу, является значением его свойства MATCH.
Рассмотрим более подробно механизм регулярных выражений языка FDL.
Определение регулярного выражения в FDL аналогично понятию регулярного выражения системы UNIX. Выражения строятся из односимвольных регулярных выражений, каждое из которых представляет множество допустимых символов (литер) алфавита ∑. Из множества всех символов ∑ выделяется множество управляющих символов C = { ., ^, /, [, ], *, — }. Мы заранее предполагаем, что литеры из С принадлежат алфавиту ∑. Символы алфавита, не принадлежащие C, носят название печатных символов и составляют множество P. Полное определение односимвольных регулярных выражений приведено в Таб. I-1.
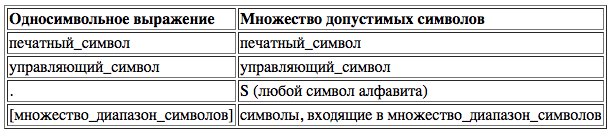
Ниже приведены примеры односимвольных регулярных выражений:
- a, d, e, Z — символы алфавита ∑.
- //, /^, /[, /*, /., /-, /] — управляющие символы из множества C, которые следуют за символом '/'.
- Cимвол '.' представляет любой символ ∑.
- [adcvt] — соответствует множеству {a, d, c, v, t}.
- [1-9] — множество цифр от 1 до 9.
- [^123] — символ '^' задает множество символов из алфавита ∑, которое не содержит символы, следующие за '^' ( S \ {1, 2, 3} ).
Приведем дополнительные правила формирования односимвольных регулярных выражений:
- Управляющие символы '.', '*', '[', '^', '-' и '/' имеют специальное значение, только если они встречаются вне квадратных скобок ('[', ']'). Внутри квадратных скобок данные символы соответствуют символам алфавита '.', '*', '[', '^', '-' и '/'.
- Если символ '^' не является первым символом в множестве символов, помещенных в квадратные скобки, то он теряет свое специальное значение и соответствует символу алфавита '^'. На-пример, регулярное выражение [123^5] допускает любой символ из множества {'1','2','3','^','5'}.
- Если символ '-' является первым символом в множестве символов, помещенных в квадратные скобки, то он теряет свое специальное значение и соответствует символу алфавита '-'. На-пример, выражение [-asdf12] соответствует множеству {'-','a','s','d','f','1','2'}.
- Правая квадратная скобка ']', которая завершает множество символов, может быть первым символом после левой квадратной скобки и в этом случае она соответствует символу ']'. Например, регулярное выражение []+1] допускает любой символ из множества {']','+','1'}.
- Регулярное выражение ** соответствует символу '*'.
Сложные регулярные выражения строятся из односимвольных регулярных выражений путем их последовательного сцепления и применения оператора репликации * (управляющий символ '*'). Так, выражение ac* определяет множество всех строк в алфавите #, начинающихся с литеры 'a', с последующей цепочкой из нуля или более символов 'c'.
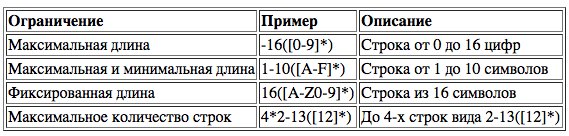
Далее определение регулярного выражения расширяется введением ограничений на длину и добавлением понятия варианта в регулярном выражении. Определение регулярных выражений с ограничениями на длину приведено в Таб. I-2.
Для реализации работы с регулярными выражениями необходимо разработать алгоритм и провести оценку его сложности. Для примера рассмотрим алгоритм разбора цепочки символов по заданному регулярному выражению (регулярное выражение без ограничений на длину). Для этого введем следующие определения.
Входной поток символов алфавита — это цепочка вида
![]()
где k — текущая позиция во входной цепочке символов, а L — длина последовательности символов.
Регулярное выражение представляется в виде:
![]()
где cp — односимвольное регулярное выражение, p - текущая позиция в регулярном выражении, N — длина выражения. Заметим, что каждое односимвольное регулярное выражение определяет множество допустимых символов (регулярное множество). Сложное регулярное выражение образуется из односимвольных регулярных выражений, соединенных символом '*'. Без ограничения общности мы можем переписать выражение c1,c2,..., cp,...,cN в виде:
![]()
где Mp — множество допустимых символов и cp — либо '*', либо пустая строка (e).
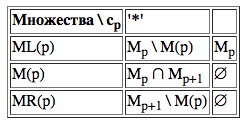
Определим множества M(p) как пересечение множеств Mp и Mp+1
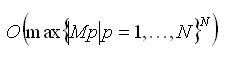
, если cp = '*', и как пустое множество (∅), если cp — пустая строка. Множество ML(p) определяется как Mp \ M(p). Аналогично, MR(p) = Mp+1 \ M(p), если cp — '*', и MR(p) = ∅, если cp — пустая строка. Ниже приведена сводная таблица (Таб. I-3) определений множеств M(p), ML(p) и MR(p) (p = 1,...N , где MN+1 = ∅).
Если множества Mp и Mp+1 соединены символом '*', то для символа входной цепочки ak возможны четыре варианта принадлежности различным подмножествам алфавита #:
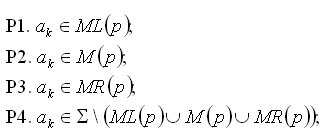
Для случая cp = мы имеем следующие варианты:
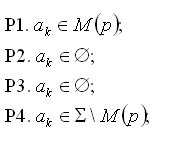
Таким образом, множества, соответствующие вариантам P1, P2, P3, P4, образуют разбиение (непересекающееся покрытие) алфавита #. Определим предикаты Pj (j=1,2,3,4). Предикат Pj(ak) принимает значение TRUE, если символ ak удовлетворяет условию Pj. Предикат P0(p) принимает истинное значение, если cp = '*' (p=1,..,N).
Определим состояние автомата разбора как вектор состоящий из двух координат s=(k, p) , где k — номер текущего элемента во входной цепочке, а p — номер односимвольного регулярного выражения (множества допустимых символов). Если алгоритм заканчивает свою работу в состоянии s=(k, N), то в этом случае входная цепочка a1,a2,...,ak допускается регулярным выражением. В противном случае входная последовательность символов отвергается данным регулярным выражением.
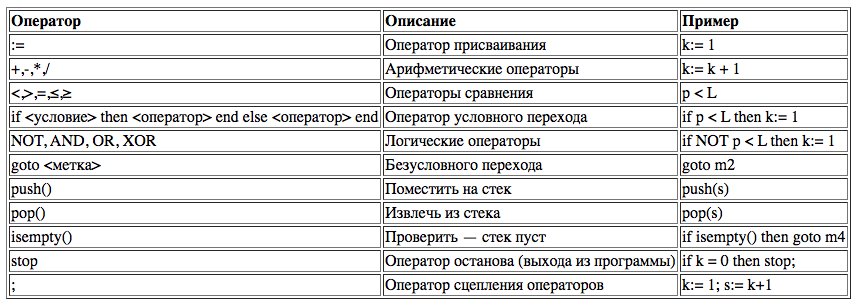
Для описания алгоритма разбора входной цепочки необходимо определить модель вычислителя, на котором данный алгоритм будет реализован. Неформальное определение множества операторов автомата приведено в Таб. I-4. Запись алгоритма разбора на языке программирования высокого уровня показана на Листинг I1.

Заметим, что алгоритм начинает свою работу, когда множества M(p), ML(p) и MR(p) заранее построены.
Проводя оценку сложности алгоритма, можно рассматривать два подхода. Первый подход заключается в построении оценки в худшем случае, когда подбираются входные данные алгоритма, обеспечивающие максимальное количество операций при его выполнении. Второй подход — построение оценки в среднем — требует более сложных математических вычислений, связанных с построением вероятностной модели поведения алгоритма. Попытаемся продемонстрировать первый подход к оценке алгоритма. Заметим, что наиболее тяжелым в вычислительном смысле является вариант, когда cp = '*' (p=1,..,N). При этом, если для символа ak выполняется условие P2 ( ak ∈ M(p) ), то алгоритм сохраняет на стеке состояние для возможного возврата. Таким образом, осуществляется полный перебор возможных вариантов. Количество таких вариантов определяется выражением:
![]()
где |M(p)| — мощность множества M(p)
Оценку сложности алгоритма в худшем случае можно дать как
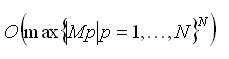
Возвращаясь к описанию FDL, приведем пример регулярного выражения, определяющего BIC код банка в сообщении MT100 (SWIFT).
![]()
Основными конструкциями языка являются операторы MATCH и SAVE, которые работают со списком символов. Оператор MATCH выделяет из входного потока литер строки, соответствующие значениям символов FDL, используя регулярные выражения, заданные для параметров вызова оператора. Данный оператор возвращает значение TRUE, если входной поток литер соответствует (допускается) заданным регулярным выражением. Полученное значение может быть проверено условным оператором языка. Оператор SAVE сохраняет значения символов FDL в выходном буфере, который после завершения работы программы содержит структуру (дерево вывода) сообщения. На Листинг I2 приведен фрагмент программы на языке FDL для сообщения SWIFT MT100. Строки, ограниченные последовательностями символов /* и */, являются строками комментариев.

Таким образом, применение FDL позволяет сократить время описания нового формата, так как отпадает необходимость в программировании на языке низкого уровня. Форматы базовых символов, определенные ранее, могут использоваться в сообщениях других форматов. Данный механизм позволяет создавать библиотеки символов, покрывающих большинство понятий предметной области. Разделение скрипта FDL на две части — определение форматов символов и описание формата сообщения — исключает дублирование информации о формате символов для разных классов сообщений. При этом изменения в формате базового символа автоматически отражаются на всех скриптах FDL, использующих данный символ. Пример описательной части скрипта приведен на Листинг I3.

Описание символа может содержать определение и для других атрибутов. Так, в основном тексте приводится пример, содержащий значения для атрибутов TABLE и FIELD.


