Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Большое количество статей, обучающих материалов и документации описывают традиционный подход к оптимизации СУБД Oracle, основанный на знании большого количества значений коэффициентов производительности (Ratio tuning). Дальнейшая оптимизация БД связана с улучшением этих коэффициентов, однако с ростом сложности ИС такой подход становится все менее эффективным.
Возникает парадокс, когда все коэффициенты находятся в границах требуемых диапазонов, а недовольство пользователей производительностью своей ИС (временем отклика) растет все больше и больше.
На практике оказывается гораздо важнее уметь оценивать производительность ИС как единого целого, включая аппаратный комплекс, системное программное обеспечение, а также воздействие со стороны сетевого окружения.
Рассматриваемая в статье методология обследования ИС демонстрирует кто, когда и с помощью каких программных средств должен выполнять комплексное обследование ИС.
Приводится пример реального отчета по обследованию информационной системы на основе СУБД Oracle 8i и сервера Sun Microsystems Sun Fire 480. Разбираются выданные рекомендации, описывается их применение и достигнутый после применения данных рекомендаций результат.
Данная статья предназначена для руководителей и специалистов IT-подразделений, занимающихся эксплуатацией промышленных систем на основе СУБД Oracle, и желающих получить максимальную производительность своей ИС.
При возникновении проблем с производительностью информационной системы на основе СУБД Oracle необходимо проводить полное исследованиепрограммно-аппаратного комплекса, а не только проводить измерение отдельных компонентов производительности СУБД (Perfomance Ratio). Кажется, что этот факт достаточно очевиден. Современные программно-аппаратные комплексы настолько сложны, что проблема может находиться где угодно.
Бездумное обновление аппаратного обеспечения не всегда сможет решить вопрос увеличения производительности, напротив, в некоторых случаях может ее (производительность) понизить! Важно определить, в чем заключаются «узкие места» ИС, какие действия следует предпринять для их преодоления, понять какая следующая проблема может ожидать и правильно наметить стратегию развития ИС.
В данной статье рассматривается процесс оптимизации на примере реальной системы. Но сначала стоит обратить внимание на часто встречающие мифы и легенды об оптимизации ИС, обсудить роль администраторов ИС в работах по оптимизации, а также рассказать о разработанных специалистами компании «Инфосистемы Джет» программных средствах для исследования состояния ИС.
2. Мифы и легенды
Оптимизация ИС всегда была окружена слухами и легендами, например, о магических параметрах БД, способных привести к ускорению работы пользователей в десятки раз или о sql-запросах, которые вдруг начинают формировать отчеты с космической скоростью.
Стоит поблагодарить авторов-фантастов за создание и развитие таких легенд, они делают все возможное, чтобы сотрудники подразделений, занимающиеся оптимизацией ИС, никогда не оставались без работы.
Но некоторые заблуждения являются просто вредными для общего понимания ситуации. На них стоит обратить внимание!
2.1 Миф параметра fast=true
Часто можно услышать высказывание о том, что ускорить работу БД в несколько раз можно только с помощью настроек БД. Более того, часто возникают вопросы во сколько раз ускорится работа БД, если увеличить, например, кэш БД или журнальный буфер. К сожалению, изменение параметров самой БД практически не влияет на производительность ИС, за исключением случаев, когда были допущены грубейшие ошибки. Настройки могут повлиять на скорость выполнения отдельных процедур, но в целом поведение всей системы не сильно изменится (примерно на 10-15%). Правда состоит в том, что не существует универсального параметра, который позволил бы решить все проблемы разом.
Вместо поиска магических параметров БД в файле настроек init.ora следует сосредоточиться на общем времени отклика системы, а также на определении составляющих времени ожидания – ведь пользователя беспокоит большое время выполнения бизнес-процедур, а не размер кэша БД.
Подход, основанный на детализации времени отклика системы, подробно описан в главе 3.4, там же изложен метод количественной оценки роста производительности после изменения параметров СУБД.
Таким образом, перед изменением любого параметра необходимо знать ответы на следующие вопросы: почему и зачем нужно его изменить, в чем ожидается выигрыш производительности и каким образом измерить произошедшие количественные изменения? Ответы на эти вопросы приводятся также в главе 3.4.
2.2 Миф более быстрых ЦПУ
Всегда ли установка более быстрых ЦПУ поможет Вам справиться с проблемами производительности? К сожалению, не всегда. Если перед обновлением ЦПУ проблема тщательно не изучена, то лучшим результатом будет то, что ситуация не ухудшится и деньги будут просто потрачены зря, при этом возможно возникнут и дополнительные проблемы!
В статье «The Practical Performance Analyst» описывается, что в случае конкуренции за ЦПУ обычных пользователей и программных роботов (batch jobs) возможно увеличение времени отклика системы для обычных пользователей.
Можно представить ситуацию, когда система испытывает перегрузку дисковой подсистемы. После установки более быстрых ЦПУ программные роботы еще быстрее будут получать доступ к ЦПУ, смогут выполнять больше запросов на чтение-запись в единицу времени и «добьют» дисковую подсистему. Время отклика системы для реальных пользователей увеличится.
Таким образом, установка более быстрых ЦПУ может решить данную проблему, только если они являются «узким местом»!
2.3 Миф об утилизации ЦПУ
Администраторов часто волнует вопрос большой загрузки их ЦПУ, но на самом деле стоит волноваться как раз в обратном случае!
Что означает загрузка ЦПУ? То, что ИС работает, а не простаивает. Если пользователи имеют большое время отклика (наиболее важная характеристика системы) при простаивающих ЦПУ, важно найти причину. Одной из возможных причин могут быть блокировки (блокировки БД (dml locks, latch) или блокировки ОС (inode)).
Что касается загрузки ЦПУ, то иногда приводятся следующие данные – загрузка ЦПУ во время рабочего дня должна быть примерно 60%-80%, достигая 90% процентов в пиковые моменты (имеется в виду, прежде всего, запас прочности системы). Строго говоря, степень загрузки ЦПУ следует определять по размеру очереди выполнения (run queue) – примеры приводятся в главе 5.
Таким образом, ЦПУ должны быть максимально загружены, но не перегружены!
2.4 Миф числа пользователей
Вопрос о том, «сколько процессоров мне необходимо?» звучит от пользователей очень часто. При этом характеризуя свою ИС часто говорят – «у меня будет 200 пользователей». Но число пользователей не может служить оценкой числа необходимых процессоров (например, аналитический отчет способен загрузить систему гораздо сильнее, чем интерактивные пользователи).
Для определения необходимого количества процессоров нужно знать архитектуру построения ИС и используемые средства для ее построения. Эти данные могут помочь наметить пути возможной оптимизации.
Какие же методы существуют для оценки необходимого аппаратного обеспечения? Если система не промышленная (например, такая, как Oracle Application), необходимо самостоятельно проводить нагрузочное тестирование. Эмулируя работу интерактивных пользователей и одновременно получая и анализируя системную статистику, можно с высокой точностью получить оценку необходимой процессорной мощности и требования к дисковой подсистеме.
Не экономьте на оценках производительности системы! Вложения в нагрузочное тестирование окупятся на этапе выбора аппаратного обеспечения!
2.5 Миф однократной настройки
Руководители подразделений, отвечающие за сопровождение ИС, часто задают вопросы: «Ну хорошо, мы настроем систему – на сколько мне хватит этой настройки? Неужели опять придется вызывать консультантов через год, а то и быстрее?».
Ответ крайне прост – все зависит от того, насколько данная ИС изменится за это время – сколько появится новых пользователей, как изменится состав данных, сколько появится новых форм и отчетов.
Очень полезно отслеживать и затем отображать на графике все изменения ИС (возможно за прошедший год сильно изменилась ИС, обновлено оборудование). И поэтому, если проблемы с производительностью возникли вновь – необходимо повторить исследование ИС!
Здесь уместно провести аналогию с техническим обслуживанием (ТО) автомобиля. Никто из водителей не приходит в ужас от необходимости регулярной замены масла и фильтров, прохождения обязательной процедуры техосмотра. Относитесь к настройке ИС, как к ТО вашего автомобиля – просто придется определить частоту настройки самостоятельно, на основании изменений, происходящих с ИС и, что важно, заложить в бюджет средства на данную процедуру!
3. Низкая производительность ИС. Кого винить и как исправить ситуацию?
Чаще всего вопросы производительности возникают уже во время работы, поэтому стоит рассматривать ситуацию функционирующей информационной системы.
Информационная система работает успешно, группа системных администраторов справляется с ежедневными задачами, но все чаще и чаще возникают жалобы пользователей о том, что их не устраивает время отклика, из бухгалтерии сообщают, что подготовка квартального отчета занимает целый день.
На технических совещаниях, которые теперь проводятся одно за другим, администраторы БД считают, что виноваты разработчики системы, разработчики обвиняют во всем администраторов. Пользователи выражают свое недовольство все сильнее. Моральная обстановка на предприятии ухудшается, и как правило, крайними становятся администраторы БД. Скорее всего, все согласны с этим мнением – ведь кажется очевидным, что данную ситуацию должен исправлять администратор БД.
Наверно всех сильно удивит тот факт, что администраторы БД вообще не отвечают за производительность ИС! Они отвечают только за оптимальную настройку СУБД, и это не всегда означает, что после настройки ИС в целом начнет работать производительно.
Важно также знать разницу между производительностью ИС и производительностью СУБД, а также стоит разобраться, кто же должен найти причину низкой производительности ИС. Для этого определим, что входит в понятие оптимизации СУБД и уточним обязанности администратора БД.
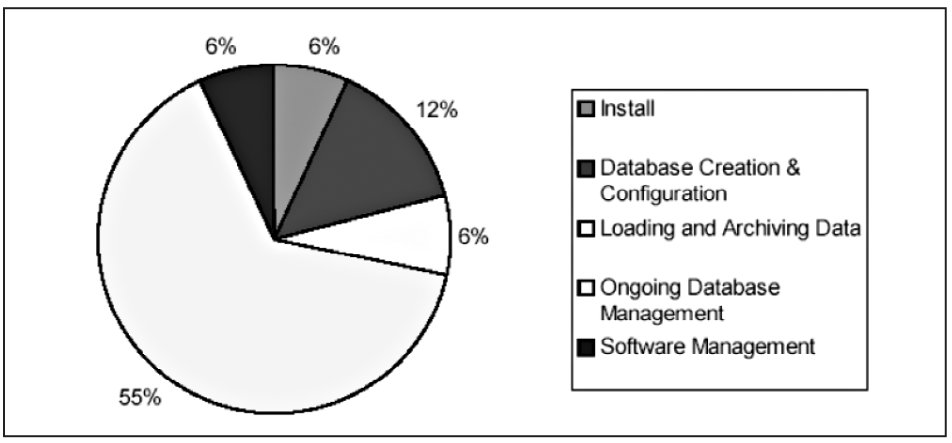
3.1 Обязанности администратора БД
Вообще говоря, нет документа, в котором обязанности администратора СУБД собранны воедино в формальном виде, тем не менее стоит попытаться сформулировать их, используя Руководство администратора БД и некоторые статьи известных специалистов по Oracle.
Из Рис. 1 видно, что в сферу ответственности администратора СУБД в первую очередь входит:
- Установка программного обеспечения, установка обновлений для уже существующего программного обеспечения;
- Создание баз данных, размещение СУБД на дисковой системе; планирование обновлений аппаратного обеспечения;
- Загрузка и выгрузка пользовательских данных;
- Управление доступностью. Резервирование и восстановление БД;
- Контроль БД. Управление пользователями, правами доступа, безопасностью системы;
- Мониторинг работы БД. Проверки протоколов сообщений СУБД (alert.log).
Это еще не полный список обязанностей администратора – стоит отметить такие задачи, как самообучение, взаимодействие с другими администраторами, обучение пользователей и разработчиков... Из приведенного списка видно, что большую часть времени занимают рутинные операции по поддержанию жизнедеятельности вашей ИС. И администраторам часто просто некогда изучать еще ОС и аппаратные особенности своей ИС.
3.2 Оптимизация СУБД
Процесс оптимизации СУБД Oracle описан в учебном курсе Oracle 9i Perfomance Tuning, в нем подробно рассматриваются необходимые настройки СУБД и приводится оценка того, насколько оптимально выполнены эти настройки. Некоторые из них приведены в Табл. 1.
Администратор СУБД отвечает за то, чтобы были выполнены все необходимые настройки СУБД. Как оценить, что такие настройки выполнены оптимально? Во-первых, параметры должны соответствовать значениям в таблице 1, и, во-вторых (возможно это более важная оценка), нужно убедиться в отсутствии значительного времени соответствующих событий ожиданий (waits events) на уровне пользовательской сессии или экземпляра БД в целом. Так, например, правильно выбранный размер журнального файла (Redo log space request) должен привести к отсутствию событий ожиданий.
Исходя из приведенного примера может показаться, что оптимизация БД крайне проста. Измеряем соответствующие параметры, смотрим, попадают ли они в необходимые диапазоны, если нет, то действуем согласно вышеприведенным инструкциям.
Но даже оптимально настроенная СУБД (с точки зрения администратора) не обязательно означает максимальную производительность ИС! Почему ранее упоминалось, что администраторы СУБД не отвечают за производительность ИС? Да потому, что у них нет для этого необходимых средств и часто знаний (не по их вине)!
Возвращаясь к примеру выше, даже уменьшив время ожидания для события space request, скорее всего, не удастся решить все проблемы производительности, связанные с журнальным файлом. Скорее всего потребуется перенести журнальные файлы Redo log space request на более быстрые или менее загруженные диски. Для этого нужно знать ответы на следующие вопросы: какие диски и как загружены в системе, что такое вообще «загруженный диск», знать, как ОС работает с подсистемой ввода-вывода, как включить в ОС асинхронный ввод вывод и т.д. – т.е. знать дополнительно ОС и аппаратные средства. Может ли штатный администратор БД знать все это? Вероятнее всего, нет. Это не входит в программу курсов, и на это у него практически нет времени.
Администраторам СУБД достаточно знать, что buffer hit ratio в течение дня имеет значение не менее 99.78%, что означает, что проблем с чтениями в СУБД нет. Но так ли это на самом деле? Не совсем. Cary Millsap в своей работе «Why You Should Focus on LIOs Instead of PIOs» предупреждает о том, что опасность логических чтений часто недооценивается. В этом можно убедиться на реальных примерах. Большое число логических чтений ведет к использованию большого числа защелок (latches) и, следовательно, увеличивает время ожидания серверного процесса на процессоре и время ожидания для конечного пользователя.
Так что нам дает тот факт, что у работающей ИС высокий процент попаданий наших запросов в кэш БД? Было минимизировано число дисковых чтений, но как это сказалось на времени отклика системы? Ведь если присутствует огромное количество логических чтений (из кэша БД), то наше приложение все равно работает медленно. Таким образом, получается, что для оптимизации производительности ИС данный параметр не дает практические ничего! А ведь это один из основных параметров оптимизации в классическом представлении.
Тем не менее, автор придерживается мнения, что это нормальный подход, когда администратор СУБД должен отвечать только за настройку СУБД.
Следует ли из вышеперечисленного, что вообще не нужно обращать внимание на параметры СУБД? Ни в коем случае. Правильный вывод – не останавливайтесь только на изменении параметров СУБД!.
3.3 Кто должен заниматься оптимизацией СУБД?
Теперь стоит остановиться на вопросе – кто же должен заниматься оптимизацией ИС? Автор придерживается мнения, что «в обычном штатном расписании такая позиция просто не предусмотрена».
Проще говоря, в штате не должно быть специалиста по оптимизации ИС. Почему? Дело в том, что это специфичный род деятельности, во многом основанный на опыте. И достаются эти знания путем исследования достаточно большого количества различных систем.
Формализовать такой опыт практически невозможно, а эту работу можно сравнить с детективной работой. Кажется все просто – собери улики (данные о производительности), опроси свидетелей (пользователей и администраторов) и поймай преступника (причину низкой производительности системы). Однако почти каждое дело (ИС) уникально по-своему. И тут очень важен полученный ранее опыт.
Хотелось бы подчеркнуть следующее: работа по оптимизации ИС никак не связана с ежедневной поддержкой ИС, т.е. с тем, чем обязаны заниматься ваши администраторы.
Оказывается, в фирмах-поставщиках ОС и СУБД инженеры, отвечающие за производительность, также выделены в отдельные подразделения. Так в Oracle существует Oracle Support Services Centers of Expertise, в Sun Microsystems Sun's Enterprise Engineering Group1. Статьи инженеров вышеперечисленных подразделений представляют особенную ценность для получения знаний о внутреннем мире БД и аппаратной платформы.
Мне кажется, что были приведены достаточно убедительные аргументы, что персонал не виноват в сложившейся ситуации. Перейдем теперь к более интересному вопросу: что же делать? Какой есть выход из этой ситуации?
3.4 Что делать?
Все звучит очень просто: необходимо выполнить комплексное обследование информационной системы, для того, чтобы определить «узкие места», а также оценить их влияние на общий отклик системы.
Для выполнения работ по оптимизации в компании «Инфосистемы Джет» была разработана методология обследования и набор программных средств Jump-Jet.
Речь о них пойдет в следующей главе.
4. Теория оптимизации
4.1 Когда нужно исследовать ИС?
Практически неважно, на каком этапе развития находится информационная система – нужно серьезно ее исследовать, документировать результаты данного исследования, а также получить средства для такого исследования, чтобы при необходимости повторить его самостоятельно, через какой-то промежуток времени. Кто предупрежден о предстоящих проблемах – тот вооружен знаниями, как этим проблемам противостоять.
Рассмотрим конкретные рекомендации разработчикам и специалистам службы сопровождения на каждом из этапов развития ИС. Разработка ИС. На этапе разработки желательно провести лекции для разработчиков о современных методах разработки и опциях версии, которую они используют, вероятно не потребуется изобретать велосипед, потому что необходимые разработчикам механизмы уже введены в новых версиях.
Необходимо познакомить разработчиков с практическими приемами сбора и обработки данных о производительности sql-запросов, убедить их обращать серьезное внимание на производительность ИС еще на этапе ее разработки. Почему это так важно? Потому что, как правило, на этом этапе у разработчиков еще нет достаточного объема тестовых данных, а без реального объема данных успешно работает практически любой код.
Внедрение. Одним из вопросов, возникающих при внедрении ИС, является вопрос о том, какое аппаратное обеспечение потребуется для реальной эксплуатации ИС. Для этого, необходимо при помощи разработчиков, написать код для нагрузочного тестирования. Получив данные о производительности в тестовом окружении, с помощью пакета Jump-Jet можно выполнить расчет (sizing) программно-аппаратного комплекса для реальной эксплуатации системы. А обнаруженные «узкие места» исправить до начала эксплуатации системы.
Эксплуатация. При эксплуатации ИС вопрос производительности считается одним из главных, поскольку, если не обеспечивается требуемое время реакции системы – эта система не выполняет возложенных на нее функций. Необходимо собирать данные о производительности ИС постоянно, так как постоянно меняется ИС – разработчики устанавливают новое ПО, в систему добавляются новые пользователи, данные внутри БД также изменяются. Хорошо, если удается справляться со вновь возникающими проблемами изменением параметров системы, но рано или поздно потребуется обновление аппаратного обеспечения. Как правило, обновление аппаратного обеспечения требует времени и соответствующих позиций в бюджете. И если есть данные о росте нагрузки на систему во времени, то и легко можно предоставить соответствующие расчеты для руководства.
4.2 Jump-Jet
4.2.1 Сборданных
Пакет Jump-Jet представляет собой набор программных утилит, используемых специалистами группы программных решений (ГПР) компании «Инфосистемы Джет» для сбора данных о производительности ИС, их обработки и графического представления. Собираются данные о настройках ОС и СУБД, конфигурации аппаратной части (физическая память, процессоры, дисковая подсистема, сетевые интерфейсы). Накапливаются данные о производительности ИС: загрузке процессоров, дисков, виртуальной памяти, загрузке сетевых интерфейсов, о выполненном объеме работы внутри БД.
Собранная статистика позволяет сделать выводы о текущей производительности системы и наличии единичных точек отказа. По результатам обследования формируется аналитический отчет, в котором описывается текущее состояние ИС, а также выдаются рекомендации по изменению настроек ОС СУБД и обновлению аппаратной и программной частей ИС.
Сбор данных о производительности ИС полностью основан на стандартных утилитах, рекомендуемых компанией Oracle и поставщиками OC и оборудования. Администраторы БД и ОС, несомненно, в той или иной степени знакомы с этими утилитами, возможно уже используют часть из них.
Немаловажен и тот факт, что эти утилиты поддерживаются фирмами производителями.
Для примера, стоит привести список утилит для ОС Solaris 2.5-9 и СУБД Oracle 8i-9i:
- Sun Explorer. Это пакет (package), выпускаемый и поддерживаемый фирмой Sun Microsystems.
- Утилиты сбора системной статистики, оформленные в виде одного командного файла. Реально, это очень хорошо знакомые администраторам утилиты iostat, vmstat, mpstat, sar, netstat. Если используется дополнительное программное или аппаратное обеспечение, данный список может расширяться. Так, скажем, если используется Veritas File System, то к этому списку добавляется vxstat.
- Oracle Remote Diagnostic Agent (RDA). Это утилита, собирающая конфигурацию БД и сервера приложения (IAS), рекомендуемая Oracle Support. Преимущество ее использования в том, что если возникнет серьезная проблема в ИС и ее не удается решить самостоятельно, то у Вас уже есть все данные для обращения в Oracle Support.
- Oracle Statspack. Statspack – пакет, который пришел на смену знаменитым скриптам utlbstat/ebstat. Суть его крайне проста. В БД создается пользователь perfstat и PL/SQL пакет statspack. С помощью вызова процедуры этого пакета делается «снимок» (snap) системной статистки экземпляра Oracle на текущий момент и эта информация вносится в архивные таблички. Начиная с версии 8i пакет Statspack входит в состав БД.
Соответствующие средства формируются для необходимой ОС и версии СУБД. На данный момент поддерживаются следующие ОС:
- Sun Solaris (2.5 – 9)
- HP-UX (10.X и 11.X)
- Compaq Unix (OSF1) 4.x и 5.x
- Intel Linux (RedHat 7.3 и AS 2.1)
- Поддержка платформы Microsoft Windows ожидается в ближайшее время.
Для версии СУБД Oracle до 8.0 использовать пакет Statspack невозможно, поэтому используется набор sql-скриптов, разработанных специалистами ГПР.
Установка вышеприведенных утилит может производиться как самими администраторами ИС, так и специалистами ГПР. Инструкции по установке могут быть получены с сайтов поставщиков утилит или из документа «Jump-Jet. Установка и эксплуатация».
Важно понимать, что для сбора данных о производительности системы необходимо выбрать момент максимальной загрузки системы – когда система реально загружена и пользователи испытывают проблемы со временем ее отклика. Поэтому, время обследования необходимо согласовать с эксплуатационными службами.
Для оценки производительности системы в терминах бизнес-транзакций необходимо получить представление о количестве и типе документов, введенных пользователями за время исследования. Имеются в виду новые открытые счета, проведенные платежи, выполненные выписки и т.п. Если такую информацию можно получить, то на ее основе можно провести оценку необходимого оборудования при росте, скажем, числа пользователей. Как правило, аналитики, работающие с конкретной информационной системой, такой информацией владеют. Остается уговорить их предоставить эту информацию.
4.2.2 Методологияоптимизации
Обработка информации основана на программных утилитах и методологии сбора и обработки данных, разработанных специалистами ГПР. Как уже упоминалось ранее, данный подход направлен на изучение времени отклика для конечных пользователей. С другой стороны, нужно понимать, что каждая информационная система достаточно уникальна и поэтому может потребовать отдельного подхода.
Основные методы оптимизации ИС излагаются в статьях «The СОЕ performance method» и «Yet Another Performance Profiling Method». Суть данного подхода изложена ниже.
Традиционный подход к оптимизации БД Oracle основан на использовании большого количества коэффициентов производительности (анализ коэффициентов производительности, Ratio tuning). Большинство таких коэффициентов приведено в главе 3.2.
Этот подход прост и понятен, однако становится неэффективным из-за возрастающей сложности информационных систем. Увеличивающийся объем данных требует новых сложных программных и аппаратных средств. Проблема с производительностью может находиться где угодно. К тому же техника анализа коэффициентов производительности предполагает, что приложение однородно по своей структуре, т.е. является OLTP или DSS приложением. В настоящее время такая ситуация встречается крайне редко.
Исследование производительности и возможностей сложной системы основано на математической дисциплине, известной как Теория очередей. В Теории очередей есть статистические методы, позволяющие эффективно анализировать поведение системы процессов, в частности, как зависимые процессы оказывают взаимное влияние. Такое описание предполагает некоторый уровень сложности и требует от читателя специальных математических знаний. Но для развития осмысленного понимания задействованных принципов можно использовать упрощенный подход.
Фундаментальная формула, которую нужно понимать, такова:
Время отклика = Время обслуживания + Время ожидания (Response Time = Service Time + Wait Time)
Если время обслуживания или время ожидания велико, оно прямо влияет на конечное время ответа. Динамические представления СУБД Oracle предоставляют нам статистику, которая позволяет рассчитать время обслуживания и время ожидания. Однако рассчитанное время отклика будет всегда меньше или равно актуальному времени отклика для реального пользователя. Эта разница объясняется внешними факторами, такими как задержки (latency) в сети или очередях монитора транзакций (если они используются).
Наша ИС всегда состоит из следующих компонентов:
- Аппаратуры
- Операционной системы
- Базы данных
- Приложения
Почему же всегда «виноватой» в низкой производительности оказывается БД? Необходимо изучить ситуацию целиком, понять архитектуру выбранного решения, знать требования, предъявляемые бизнесом к ИС.
Чтобы получить представление о текущем состоянии дел необходимо обратить внимание на следующие компоненты:
- Сеть
- Память
- Процессор
- Дисковая подсистема
Итак, когда есть сведения о системной части (аппаратной и операционной системе) и известно как используются системные ресурсы, можно перейти к расчету Времени отклика и осознанию основных факторов, влияющих не него.
Время обслуживания может быть получено из динамических представлений V$SYSSTAT или V$SESSTAT как компонента «CPU used by this session»:
select a.value «Total CPU time» from v$sysstat a where a.name = ’CPU used by this session’;
Время ожидания может быть получено из динамических представлений V$SYSTEM_EVENT и V$SESSION_EVENT, суммируя все времена ожидания, за исключением некоторых из них:
select sum(time_waited) «Total Wait Time» from v$system_event where event not in (’pmon timer’, ’smon timer’, ’rdbms ipc message’, ’parallel dequeue wait’, ’virtual circuit’, ’SQL*Net message from client’, ’client message’, ’NULL event’);
Итак, можно теперь рассчитать Время отклика, после чего перейдем к цели наших исследований – оценке влияния тех или иных ожиданий на общее время отклика системы. Так, если все время ожидания свободного места в журнальном буфере составляет только 2% от общего времени отклика, то после уменьшения данного времени ожидания на 50%, можно получить только 1% уменьшения времени отклика.
Вот, соответственно, где лежит ответ на самый задаваемый вопрос: что даст исправление того или иного параметра БД? Теперь есть возможность на него ответить. Сосредоточившись на уменьшении показателей времен ожидания, мы получим максимальный эффект.
Не стоит останавливаться только на получении Времени отклика. Далее можно получить достаточно интересные данные. Рассмотрим, как потребляет ЦПУ наша БД. Для этого рассчитаем компонент прочее ЦПУ (CPU other) по формуле:
Прочее ЦПУ = Время отклика – Время разбора предложений – Время рекурсивных запросов
(CPU other = CPU used by this session – Parse time CPU – Recursive CPU)
select a.value «Total CPU»,
b.value «Parse CPU»,
c.value «Recursive CPU»,
a.value b.value c.value«Other»
from v$sysstat a, v$sysstat b, v$sysstat c
where a.name = ’CPU used by this session’
and b.name = ’parse CPU time’
and c.name = ’recursive CPU’;
Компонент Прочее ЦПУ отвечает за время, потраченное на работу с кэшем СУБД, извлечении записей или поиска по индексу. Обычно, высокий процент отношения Прочее ЦПУ/Время отклика говорит о наличии неэффективных SQL, просматривающих слишком много блоков в кэше СУБД – т.е. совершающих логические чтения.
select a.value «Total CPU»,
b.value «Parse CPU»,
c.value «Recursive CPU»,
a.value b.value c.value«Other»
from v$sysstat a, v$sysstat b, v$sysstat c
where a.name = ’CPU used by this session’
and b.name = ’parse CPU time’
and c.name = ’recursive CPU’;
И это еще не все. Стоит внимательно изучить все прочие времена ожиданий. Это может потребовать значительного времени – от нескольких дней до нескольких недель. Сначала надо разобраться в причинах возникновения ожидания и наметить пути уменьшения времени ожидания. Возможно потребуется взаимодействие с разработчиками для исправления кода приложения. Проанализируйте наиболее ресурсоемкие sql выражения и предложите разработчикам пути их исправления. Например, опция секционирования больших таблиц (partition option) может помочь ускорить работу с большими объемами данных. Запланируйте остановку системы для внесения соответствующих исправлений.
Это достаточно трудоемкая и продолжительная работа. Именно поэтому, при выдаче рекомендаций важно выделить те из них, которые могут быть выполнены в ограниченное время и применение которых даст максимальный эффект.
4.2.3 Следующий шаг
Следует отметить еще и следующий факт. Администраторы тех ИС, где были проведены исследования, получают достаточно мощный инструмент для анализа производительности обслуживаемой системы. Полученный отчет может использоваться как базовый, для последующего анализа произошедших изменений. Простой пример – администраторы могут через некоторое время повторить съем статистики самостоятельно и по результатам полученных данных убедиться в росте нагрузки на систему или влиянии тех или иных изменений в аппаратной или программной средах. В сложных ситуациях вновь собранные данные могут быть переданы в ГПР для более детального анализа. Таким образом, происходит обучение обслуживающего персонала, подготовка к переходу на новый уровень общения со службами поддержки.
4.3 Круговорот оптимизации в природе
Конечно, большинство обращений в ГПР происходит в момент возникновения проблемы в ИС. Важно правильно сформулировать проблему, описать действия, которые привели к эскалации проблемы. Такими действиями может быть установка на первый взгляд безобидного кода или другое изменение приложения. Как правило, требование выдвигается в это время только одно – восстановить работоспособность системы как можно быстрее. Только во время решения проблем удается обратить внимание эксплутационных служб на «запущенность» ситуации в целом и привлечь их внимание к необходимости регулярного обследования системы.
Гораздо реже (но все же встречается!) ситуация, когда требуется провести исследования работающей системы, в которой проблемы с производительностью встречаются, но еще не стали доминирующими. И здесь, как уже упоминалось в главе 2, основным вопросом является «Как часто мне нужно проводить подобного рода оптимизацию?».
Ответ приведен на рисунке ниже. После того, как удастся справиться с одной проблемой, Вам придется решать следующую проблему. А затем возникнет еще одна и так далее.
Важно понимать, что усилия здесь не бесконечны. Разные проблемы имеют различное влияние на систему. Вы можете знать о неоптимальном отчете, но поскольку дисковая подсистема пока справляется, не обращать на нее внимания, так как необходимо решить более важную проблему производительности для on-line пользователей. Ее решение даст возможность выиграть время на исправление отчета.
На этом не стоит останавливаться. Если проблему с отчетом не решить, в дальнейшем она возникнет уже как более серьезная – после роста числа пользователей или роста объема данных. Поэтому важно регулярно собирать статистику производительности системы, повторять исследование системы, даже если кажется, что нет критичных проблем.
Частоту таких исследований желательно проводить ежеквартально для систем, которые активно развиваются и дорабатываются, и ежегодно для более стабильных систем. Естественно требуется внеочередное исследование, если возникнет необходимость резко увеличить объем данных или изменить аппаратную платформу.

4.4 Правило 80/20
Может быть вместо столь сложной работы с настройками системы стоит обратить внимание на приложение? Существует достаточно много мнений о том, что сколько ни занимайся оптимизацией системы в целом, гораздо проще и эффективнее исправить приложение. Правильно ли это утверждение? И да, и нет. «Да» – поскольку изменения в sql-запросе могут повысить его скорость в несколько раз (личный рекорд до 40 раз), а достичь таких результатов при оптимизации ИС в целом практически невозможно. «Нет», потому что изменить такой запрос не всегда возможно, например, в случаях, когда приложение является закрытым или такой запрос диктуется сложными бизнес-правилами. Изменить бизнес-правила чаще всего нельзя или этот процесс может потребовать долгих согласований.
По некоторым оценкам до 80% проблем, связанных с производительностью системы, находится в области исправления кода приложения. Но где конкретно? На этот вопрос можно ответить только после обследования ИС.
В данном материале рассматриваются случаи без явных нарушений логики создания приложений, и никакая оптимизация системы не поможет в случаях, когда приложение простаивает, например, из-за ожидания снятия блокировки пользователем, который ушел на обед... Все-таки те 20% которые остаются на системную оптимизацию, это не так уж и мало. Ведь изменение параметров БД ОС происходит прозрачно для пользователей, не требует их уведомлений, согласований и т.п.
Если Вы обнаружили, что проблема приложения состоит в плохом коде и Вы можете исправить его без исправления бизнес-логики, сделайте это немедленно!
5. Практика оптимизации
Рассмотрим пример из реальной практики. Была исследована корпоративная система (КИС), рассчитанная примерно на 200 пользователей, на основе 2-х процессорного сервера Sun Microsystems SunFire 480 – сервера класса рабочей группы. Система выполняет промышленную систему класса предприятия.
Системы подобного рода достаточно распространены, очевидна и ситуация вокруг таких систем – небольшой бюджет, один администратор, а обучение администраторов чаще всего в бюджет не включено.
Выполнить настройку СУБД оптимальным образом в подобной ситуации является не совсем простой задачей и требует серьезного знания СУБД. Но с этой задачей администраторы БД, как правило, весьма успешно справляются. Но приходит время, когда оптимальных коэффициентов производительности уже недостаточно. Система работает мало производительно. Разработчикам за счет численного превосходства достаточно успешно удается свалить все проблемы эксплуатации на администратора БД.
Естественным выходом из создавшейся ситуации является заключение договора на внешний аудит ИС. При заключении договора обговариваются следующие вопросы:
- Каковы объемы работ (кол-во серверов и экземпляров БД)?
- Каков график съема данных о производительности ИС? (ИС должна быть нагружена в момент съема статистики, но не перегружена).
- Требуется ли изучать политику резервного копирования БД?
- Требуется ли изучать сетевое окружение?
- Требуется ли выдавать рекомендации по обновлению программно-аппаратного комплекса (позволяет ли бюджет такое обновление)?
- Кем будут применяться выданные рекомендации, специалистами заказчика или исполнителя?
Данные вопросы собраны в специальную анкету, высылаемую заказчику перед заключением договора.
Установка необходимого ПО и сбор данных о производительности производится либо самими администраторами, либо специалистами ГПР, по договоренности с отделами эксплуатации.
Ниже приводятся выдержки из Аналитического отчета, дающие общие представление о ситуации.
Аналитический отчет обследования информационной системы полностью приведен в следующей статье.
5.1 Аппаратная часть
КИС построена на основе сервера класса SunFire 480, имеет 2 процессора с частотой 900 МГц, 4096 Mb памяти и 2 внутренними дисками по 36 Гб под управлением ОС Solaris 5.8.
В системе установлен сетевой адаптер производительностью 1 Gbit/c.
Дополнительно к системе подключен дисковый массив D2, содержащий 5 жестких дисков.
В рамках ИС функционируют 2 экземпляра СУБД Oracle SPRI и SCEC, исследованию подвергается только экземпляр SPRI.
5.2 СУБД
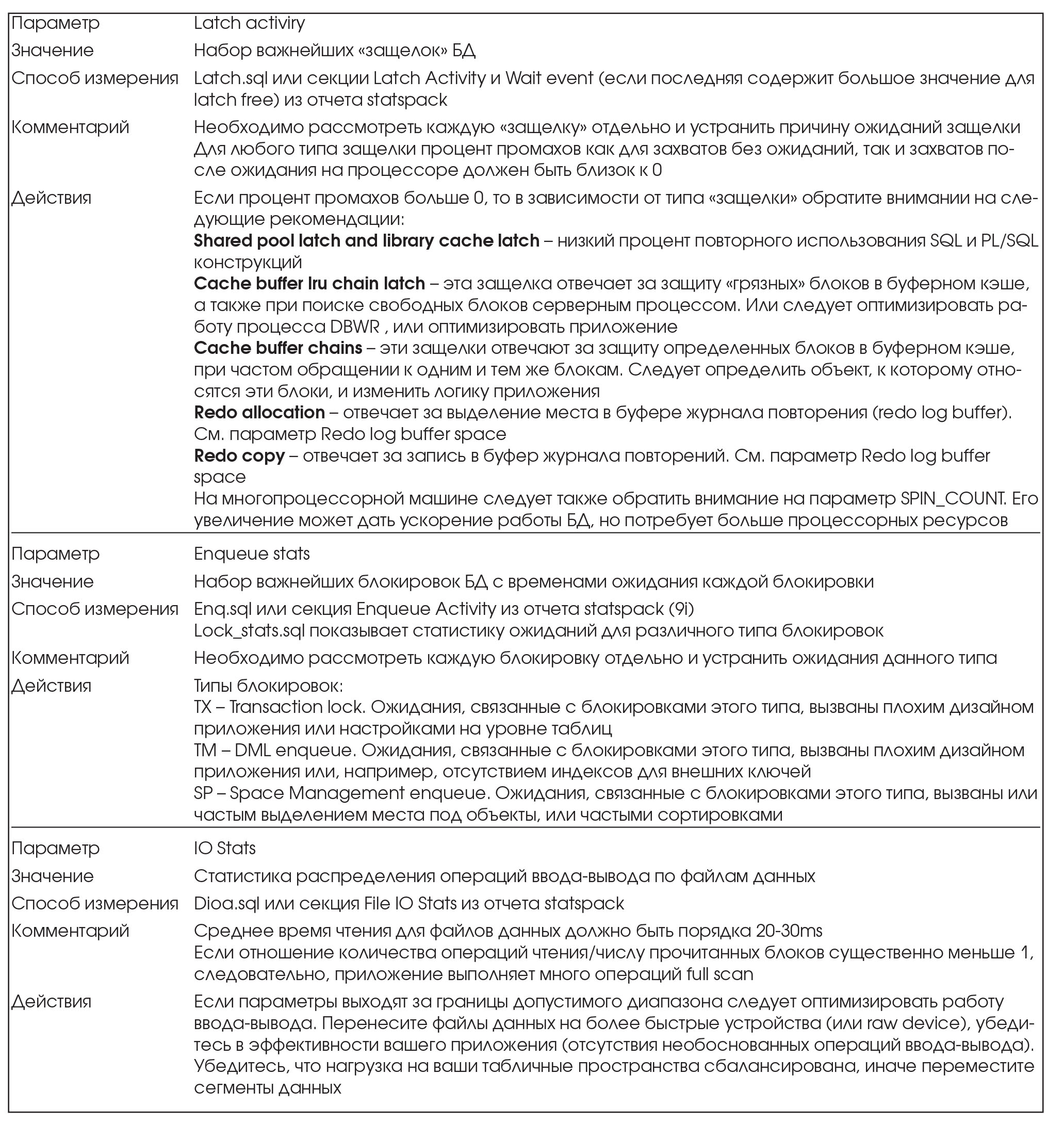
На сервере КИС используется СУБД Oracle 8.1.7.0. Функционирует 2 экземпляра БД: SPRI и SCEC. Исследованию подвергался только экземпляр SPRI. Его основные параметры (SGA) приведены в Табл. 2:
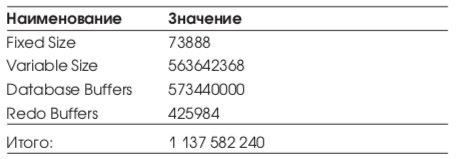
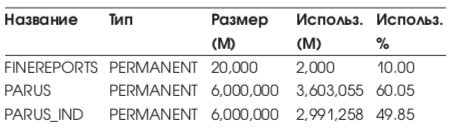
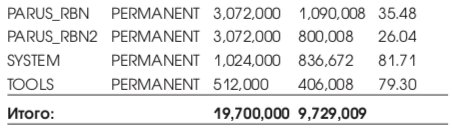
Список табличных пространств приведен в Табл. 3.
5.3 Профиль рабочего дня
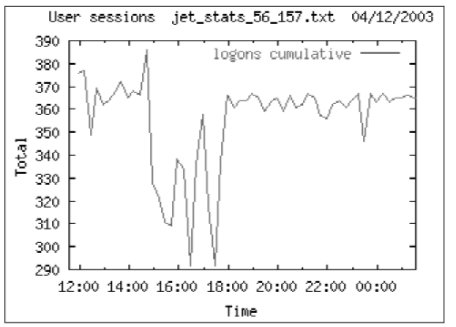
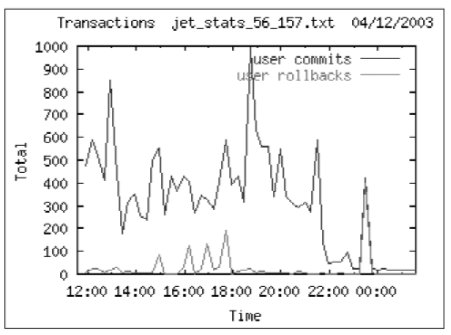
Во время съема статистики работало до 200 реальных пользователей (400 сессий объясняется особенностями построения приложения), которые выдавали до 1000 транзакций за 15 мин. (время между снятием статистики). Соответствующие графики приведены ниже.
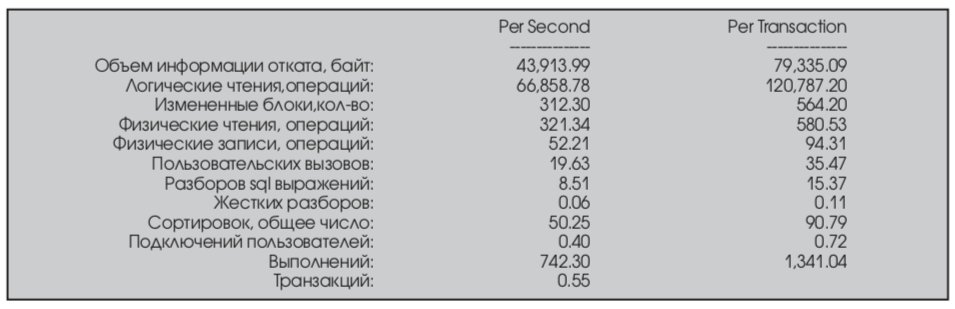
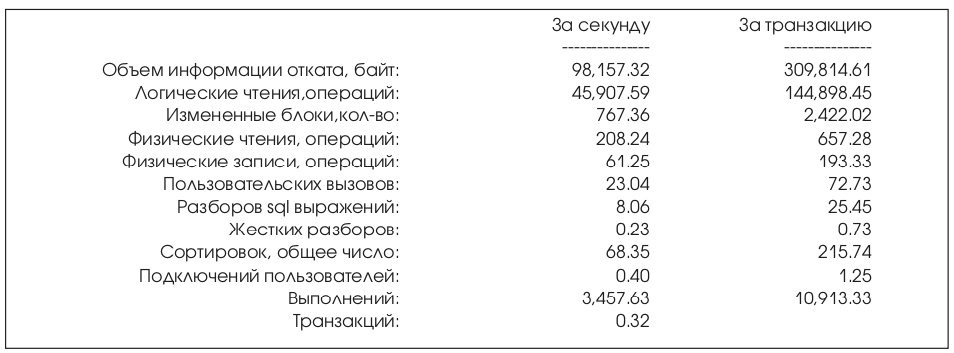
На Лист. 1 показаны данные о производимой работе СУБД в единицу времени и в расчете на 1 транзакцию. Формулы для получения представленных данных приведены в приложении.
Под термином “транзакция” понимается операция фиксации изменений commit или отказ от фиксации (rollback). Т.е. общее число транзакции = сумма commits + rollbacks.
Undo информация – информация, содержащаяся в журналах отката (redo logs).
За это время СУБД показала достаточно высокие показатели эффективности работы. Сами показатели приведены на Лист. 2.
Необходимые данные можно получить из отчета Statspack. Согласно этому отчету, общее время обслуживания составило:
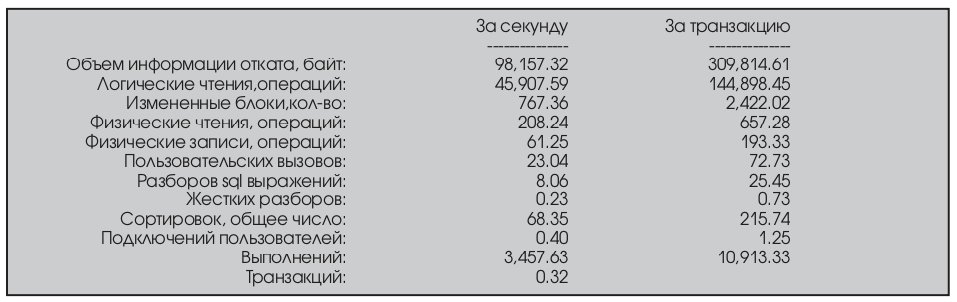

'Service Time' = 763,099,594 cs (компонент CPU used by this session отчета Statspack).
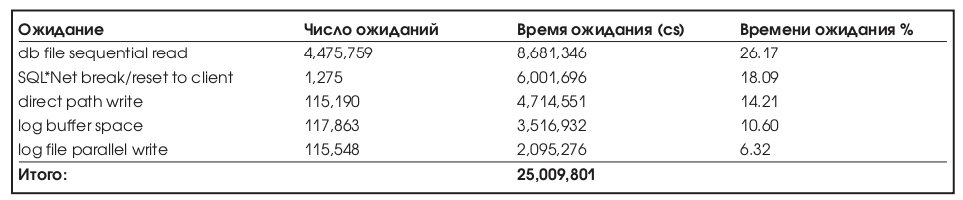
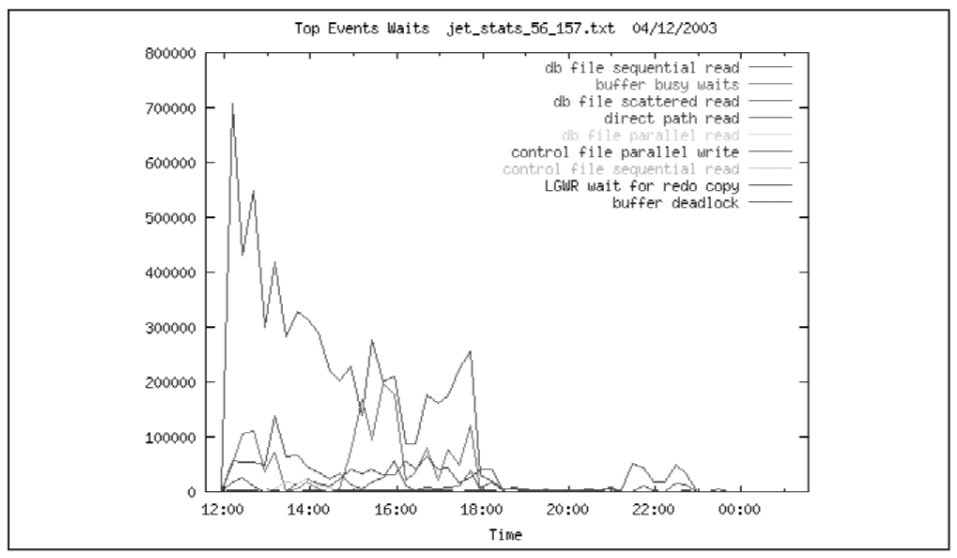
Ожидания СУБД, на выполнение которых было затрачено больше всего времени, приводятся в Табл. 4.
Рассчитаем время ожидания и общее время ответа:
Wait Time' = 33,172,892
'Response Time' = 763,099,594 +25 009 801 = 796,272,486
Таким образом, можно оценить, что время обслуживания занимает 95,8% всего времени ответа конечного приложения. Изменение параметров СУБД, направленное на уменьшение времени ожидания, даст нам около 4% уменьшения времени ответа для конечного приложения – то есть необходимо сосредоточиться на уменьшении времени обслуживания.

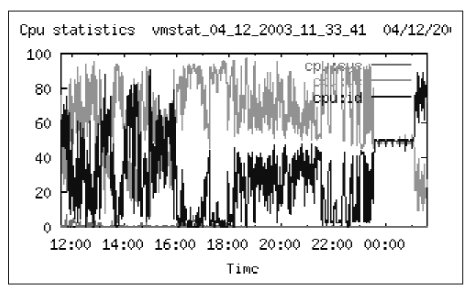
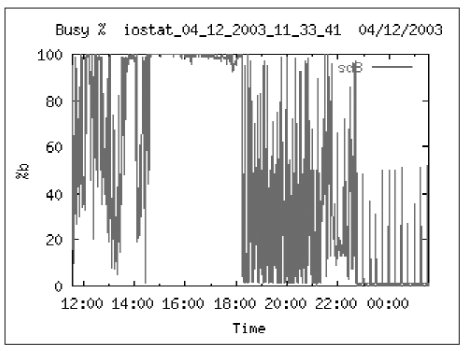
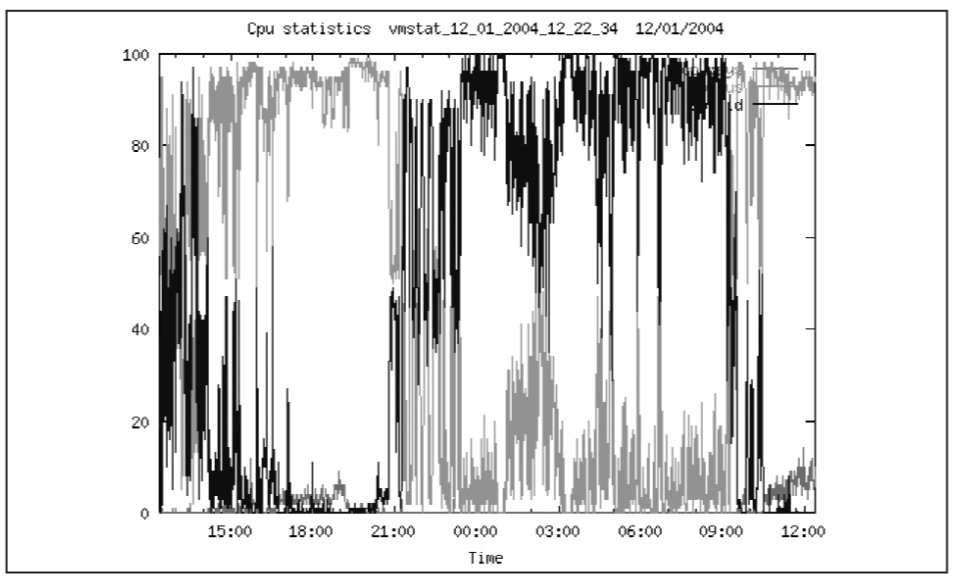
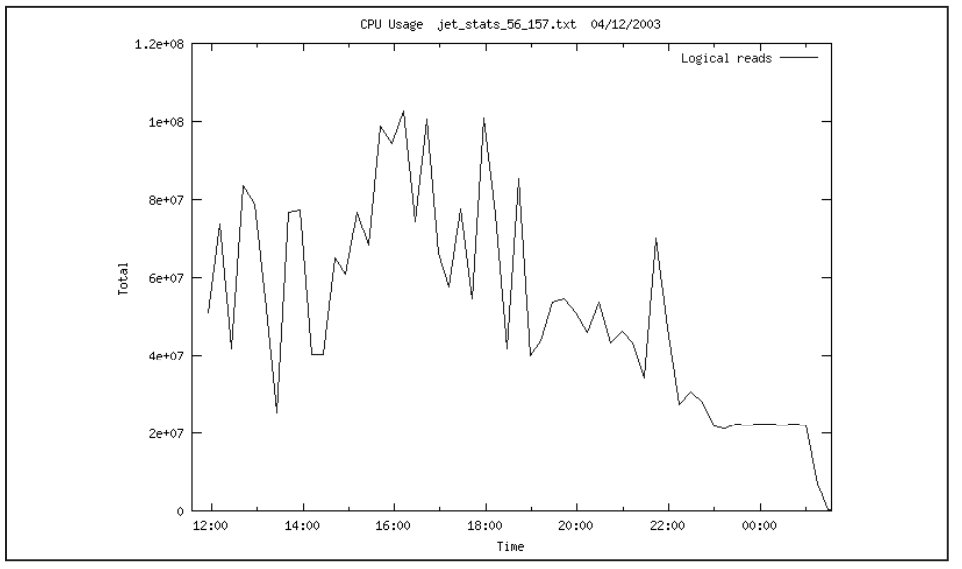
Действительно, разбираясь с настройками ОС и аппаратной частью были обнаружены 2 проблемы: слишком большая загрузка дисковой подсистемы и ЦПУ. На Рис. 5 показана загрузка ЦПУ. Видно, что существенное время она превышает 80%. С другой стороны, загрузка дисковой подсистемы также слишком велика. На Рис. 6 показана загрузка диска sd8. На протяжении 4-х часов диск был занят на 100%.
Из графика (Рис. 7) видно, что наибольшее влияние на работу системы оказывают ожидания, связанные с чтениями данных. Прочие ожидания также связаны с вводом выводом.
6. Применение рекомендаций
Как видно из предыдущей главы, проблем в настройках самой БД найдено не слишком много и ожидаемый эффект от применения невелик. Какой же выход из этой ситуации?
Из приведенных данных видно, что перегружены и процессоры, и дисковая подсистема. Очевидно, что первоочередным решением является модификация дисковой подсистемы. Во-первых, это увеличит отказоустойчивость комплекса в целом, ведь в том состоянии, в котором система находилась во время исследования, сбой любого диска приводил к необходимости восстановления БД.
Во-вторых, если проверить время простоя ЦПУ (idle time), можно увидеть значительное время ожидания операции ввода вывода (%wio).
Поскольку система допускала простой в выходные дни, было принято решение дополнительно установить имеющиеся в наличии жесткие диски (sd10, sd11, sd26) и собрать в соответствии с выданными рекомендациями программный массив данных (RAID 1+0) на основе ПО Solstice DiskSuite.
Параллельно выполнялись рекомендации по модификации параметров ОС и параметров СУБД.
После применения рекомендаций, исследование ИС было повторено самостоятельно администратором ИС. Надо учитывать, что нагрузка в обоих исследованиях хоть и являлась типичной для данной системы, но все-таки имеет некоторые различия.
Посмотрим на данные о производимой работе СУБД в единицу времени и в расчете на 1 транзакцию (Лист. 3).
ИС удалось выполнять 0.55 транзакций в секунду (против 0.32 на Лист. 1). Это неплохой результат, так как удалось увеличить производительность в 1.7 раза. Это конечно, несколько завышенная оценка, но рост производительности налицо.
Системе удается выполнять и больше логических чтений в единицу времени. При этом также удалось выполнить 321.34 физических чтения в секунду (против 208.24 на Лист. 1). Правда, при этом число физических записей уменьшилось до 52.21/с (против с 61.25/с).
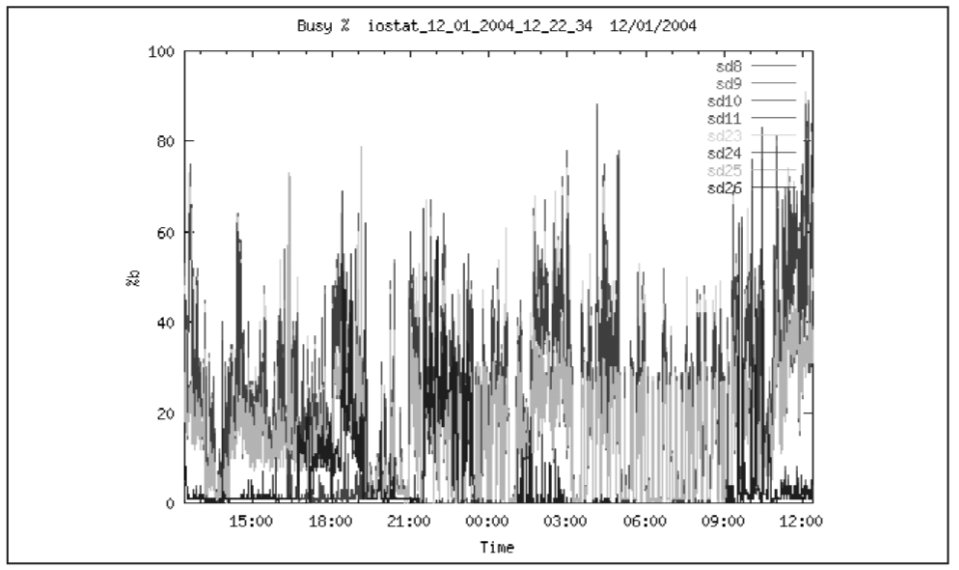
На Рис. 8 приводятся данные о проценте загрузки отдельных физических дисков. Видно, что нам удалось «уйти» от 100% загрузки отдельных дисков.
Как было сказано в главе 4.3, после решения одной проблемы, проявляются следующие.
Мы видим, что уже среди наибольших событий ожиданий есть события enqueue и latch free. Хотя требуется дополнительные исследования причин возникновения этих событий ожиданий, скорее всего, потребуется добавление процессорной мощности. Это вполне ожидаемый эффект, поскольку собранный массив – программный, а значит, его работа требует дополнительных процессорных ресурсов. На Рис. 9 приводится график загрузки процессоров системы. Если сейчас добавить процессоры, то это принесет уменьшение времени отклика конечного пользователя.
Несмотря на то, что процесс оптимизации достаточно продолжителен, и одна проблема может возникать за другой, эффект от каждого нашего шага – очевиден!
7.Что ждет администраторов БД с выходом Oracle 10g
Версия СУБД Oracle 10g выходит2 под лозунгом «Self-managing, gridready database», что, конечно, вызвало беспокойство среди администраторов. Что значит самоуправляемая (self-managing)? А что же будут делать администраторы?
По мере появления материалов о будущей версии все становится на свои места – новой версией все еще надо будет управлять, просто появились средства, упрощающие этот процесс.
Стоит обратить внимание на разъяснения Toma Kyte, Вице-президента корпорации Oracle, ведущего проекта asktom.oracle.com:
«Разве Вы собираетесь уменьшить количество приложений в своей БД? Разве Вы будете только удалять пользователей и не захотите их заводить? Разве вы собираетесь продать все свои диски, потому что ваша БД становится все меньше и меньше? Конечно нет. В большинстве случаев количество приложений будет расти, количество пользователей и объем БД будет также расти, приложение станет еще критичнее для бизнеса. И что самое главное все это должно управляться все тем же количеством администраторов.
Какой же выход из этой ситуации? Один из выходов – проводить больше времени администраторам на работе, другой – переложить на БД часть рутинных операций. Оптимизация “плохих” запросов – в большинстве случаев БД сама может справиться с этим, а вот работу по созданию эффективных схем данных может выполнить только квалифицированный человек, но не программное обеспечение. Обнаружение объектов, в которых много свободного пространства и высвобождение его – может сделать БД, не надо тратить время администратора».
Как видно из приведенного отрывка, упор был сделан на снятие рутинных операций с администраторов, высвобождение их времени на работу, действительно требующую их квалификации и времени.
Рассмотрим новые возможности управления БД, которые будут доступны администраторам БД. Курсивом идет комментарий автора к заявленным возможностям.
ASM (automatic storage management) обеспечивает эффективное распределение ввода-вывода между всеми имеющимися в наличии дисками. ASM также уменьшает время простоя БД во время перегруппировки файлов БД между отдельными дисками. ASM предоставляет упрощенный интерфейс для управления дисковой подсистемой.
Мы видим, что действительно труд администратора упрощается. Но администратор должен устанавливать новые диски и подключить к ASM новые дисковые группы. Правда при этом ему не придется заниматься распределением ввода-вывода. Это будет сделано автоматически.
AWR (аutomatic workload repository) – теперь БД сама будет собирать и анализировать статистику своей производительности. Результаты анализа предоставляются графически через Web интерфейс. Результатами являются как измеренные статистики, так и рекомендации администратору по изменению параметров БД.
Действительно, выглядит это впечатляюще. С помощь графического интерфейса можно проникнуть в проблему достаточно глубоко и тут же получить совет по ее исправлению. Но на самом деле, это мощный аналитический комплекс, построенный на основе пакета statspack из версий Oracle 8i-9i, хорошо известен администраторам. Ранее приходилось анализировать результаты его работы вручную. Теперь анализ результатов автоматизирован, что сокращает время на принятие решения, но никаким образом не освобождает администратора от знания принципов работы своей БД.
AMT (automatic maintenance tasks) – автоматически оценивает информацию из репозитория AWR и выполняет рутинные операции, такие как сбор статистики, перестройка индексов в указанное администратором время.
Рутинные операции у хороших администраторов уже автоматизированы. Наверное теперь будет легче согласиться с предложенным БД расписанием, чем разрабатывать собственные скрипты. Но всегда ли это будет лучше?
Вывод: для начинающих администраторов управление БД с выходом версии 10g существенно упрощается. Наверное меньше шансов совершить грубые ошибки при управлении БД. Некоторые простые шаги по оптимизации теперь будут подсказаны самой БД.
Но все выше перечисленное ни в коей мере не избавляет администраторов от необходимости понимания механизмов работы БД!
8. Список литературы
- Performance Management: Myths & Facts, Cary V. Millsap, Oracle Corporation
- The Practical Performance Analyst , Gunther, N. 1998.. McGraw-Hill, New York.
- So what does an oracle dba do? And do i need one? Steve Lemme, Platinum Technology, inc.
- Oracle DBA Checklist, Thomas B. Cox, with Christine Choi, http://www.geocities.com/tbcox23
- Simplify your job – automatic storage management, Paul Manning,Angelo Pruscino, Oracle Corporation
- The self-managing database:: automatic performance diagnosis. Кyle Hailey, Oracle corporation, Graham Wood, Oracle corporation
Приложение. Терминология и формулы отчета Statspack
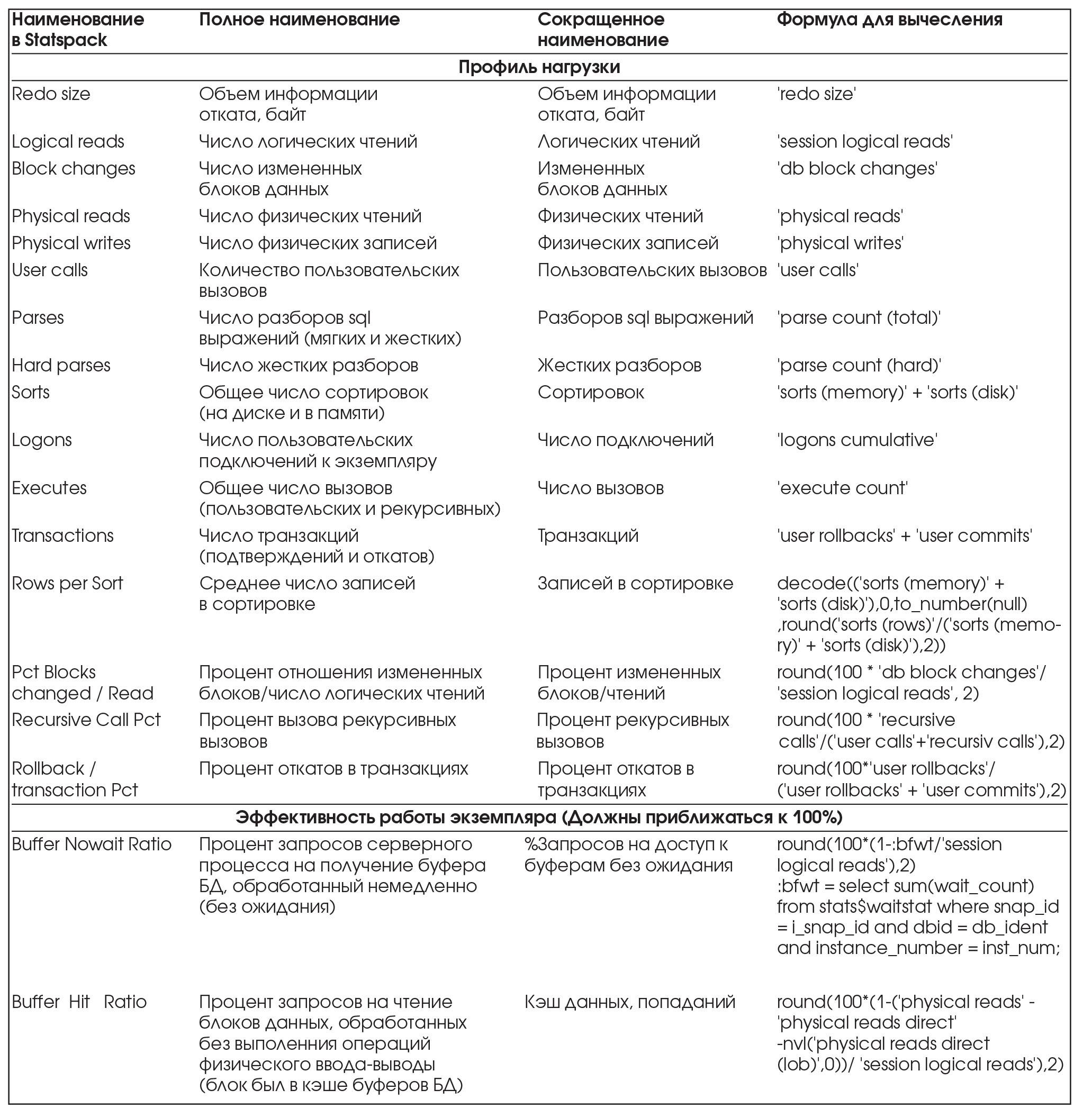
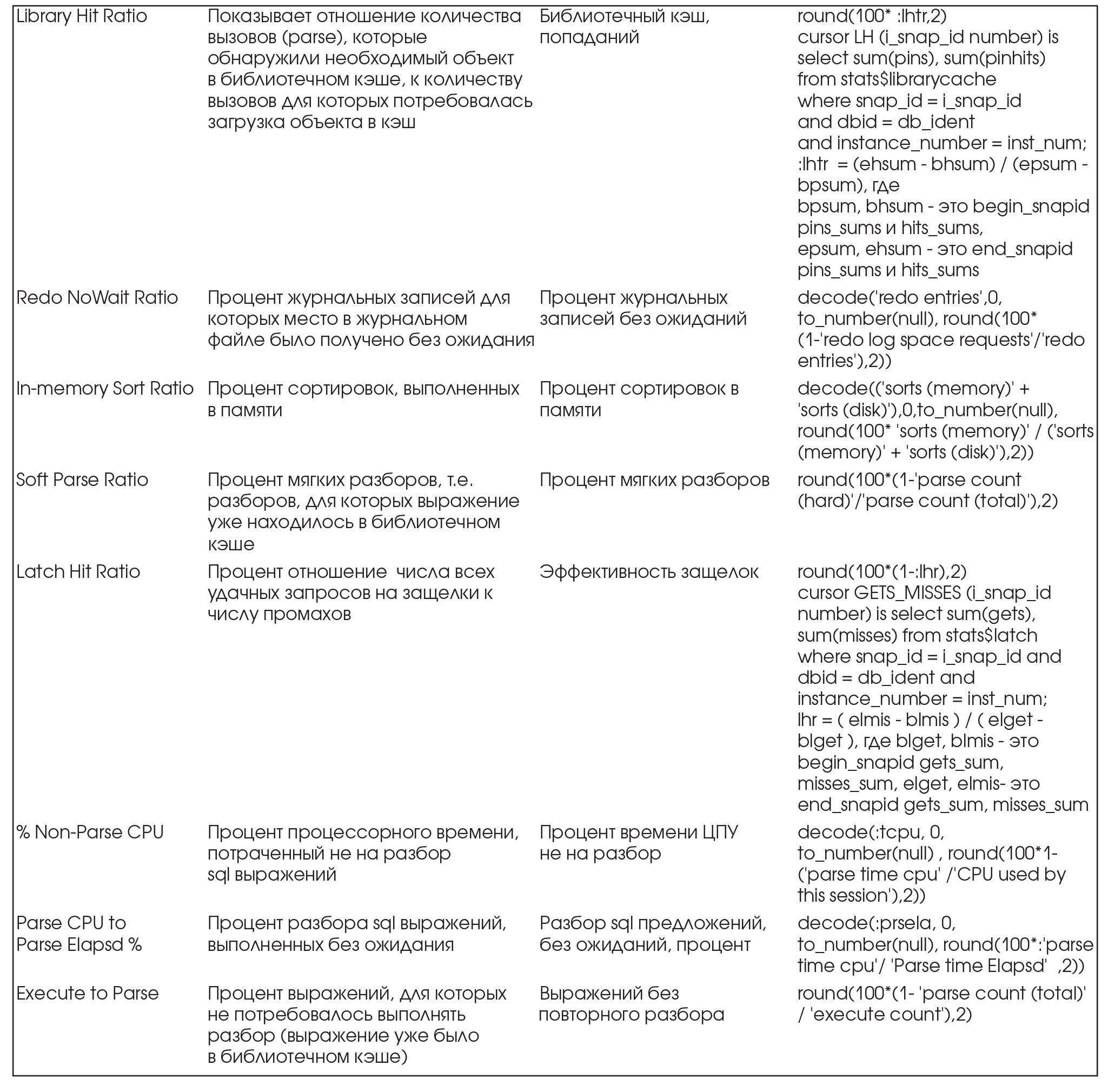
Пакет Statspack предоставляет для первоначального анализа производительности СУБД две основные секции своего отчета Профиль нагрузки (Load Profile) и Эффективность работы экземпляра (Instance Efficiency Percentages).
Для удобства восприятия аналитических отчетов, часть используемых терминов переведена на русский язык.
В таблице ниже приводятся параметры производительности из отчета Statspack, полное и сокращенное русское наименование, а также формула, используемая Statspack'ом для расчета параметра.
Все параметры основаны на системной статистике. Описание используемых системных статистик приведено в таблице. Полное описание системных статистик можно посмотреть для версии 8.1.7 по адресу: http://download-west.oracle.com/docs/cd/A87860_01/doc/server.817/a76961/apc2.htm#30 176, а для версии 9.2 по адресу: http://downloadwest.oracle.com/docs/cd/B10501_01/server.920/a96 536/apc2.htm#1186645.
Для получения значения статистики между двумя снимками в пакете Statspack используется процедура Sysdif.

Сервер SPRI Обследование информационной системы
Данный документ построен следующим образом: в разделах 2, 3, 4 дается общее описание прикладной задачи и программно-аппаратного комплекса.
В разделе 5 приводятся показатели загрузки и производительности ИС во время исследования. В этом разделе собраны данные, полученные при исследовании ОС и СУБД.
В разделе 6 приводятся выводы и рекомендации по модернизации ИС.
1.1 Сокращения и наименования
Далее по тексту используются следующие сокращения:

Далее по тексту используются следующие переводы английских терминов:
2. Состояние прикладных задач
Сервер SPRI является одним из основных серверов Заказчика. Основным приложением является Система ПАРУС вер. 8.5.1.1.
2.1 Требования к функционированию прикладных задач
Система Парус разработана компанией «Корпорация ПАРУС» включает в себя несколько бизнессфер деятельности предприятия:
- Управление финансами (финансовое планирование, бухгалтерский учет, консолидация).
- Маркетинг и логистика (маркетинг (клиенты), закупки, склад, реализация, магазин).
- Управление производством (учет затрат и калькуляция себестоимости, технико-экономическое планирование, техническая подготовка производства).
- Управление персоналом (учет персонала, табельный учет рабочего времени, расчет заработной платы).
Приложение должно функционировать в период 10.00-18.00 5 дней в неделю (понедельник-пятница). Потеря данных недопустима. Простой системы в рабочее время допустим не более 30 мин.
3. Аппаратная часть
ИС SPRI построена на основе сервера класса SunFire 480, 2 процессора с частотой 900 МГц, 4096 Mb памяти и 2 внутренними дисками по 36 Гб под управлением ОС Solaris 5.8.
В системе установлен сетевой адаптер производительностью 1 Gbit/c.
Дополнительно к системе подключен дисковый массив D2, содержащий 5 жестких дисков.
Общий вид ИС приведен на рисунке 1.
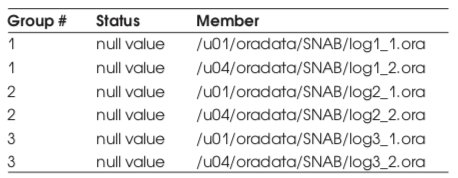
В рамках ИС функционируют 2 экземпляра СУБД Oracle SNAB и SCEC, исследованию подвергается только экземпляр SNAB.
В следующих главах дается более детальное описание аппаратной части.
В Табл. 3 приводятся сводные характеристики сервера.

Всего в сервере установлено 4096 Mb физической памяти.
3.1 Описание дисковой подсистемы
Дисковая подсистема состоит из двух внутренних дисков и внешнего дискового массив D2. D2 представляет собой 5 отдельных дисков, так называемый JBOD (Just a Bunch Of Disks). Никакой логики массив не поддерживает.

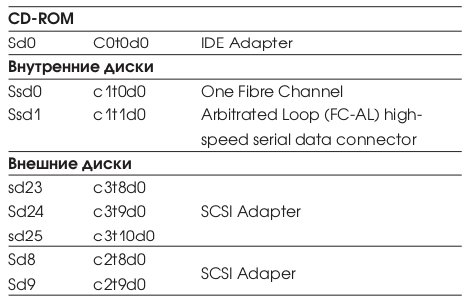
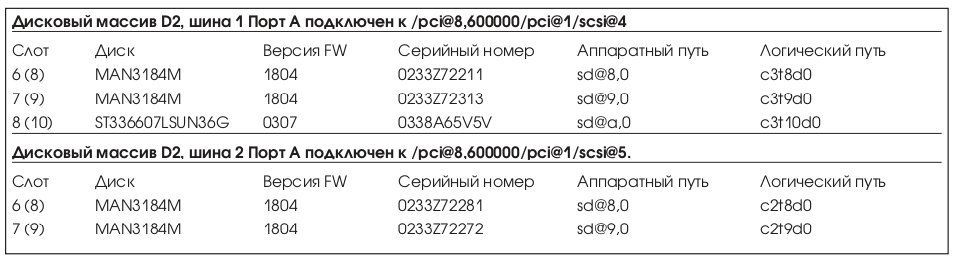
Диски массива D2 подключены через 2 контроллера к серверу. В Табл. 5 приводится список внутренних дисков, в Табл. 7 приводятся диски массива D2.
Внутренние диски подключены к отдельному контроллеру и называются соответственно c1t0d0 и c1t1d0.
В операционной системе Solaris приняты имена устройств как в форме c?t?d? так и форме sd??. Для удобства чтения следующих разделов соответствие названий приведено в Табл. 6.
4. Системное ПО
4.1 Операционная система
На сервере SPRI используется операционная система Solaris:
- Solaris 8 2/02 s28s_u7wos_08a SPARC
Также установлено (но не используется) следующее программное обеспечение:
- Solstice DiskSuite
- Solstice DiskSuite Tool
Для подключения внешних дисков используется ПО StorEdge RAID Manager.
Важнейшие переменные ядра ОС приводятся на Лист. 1.

Размеченное дисковое пространство приводится на Лист. 2.
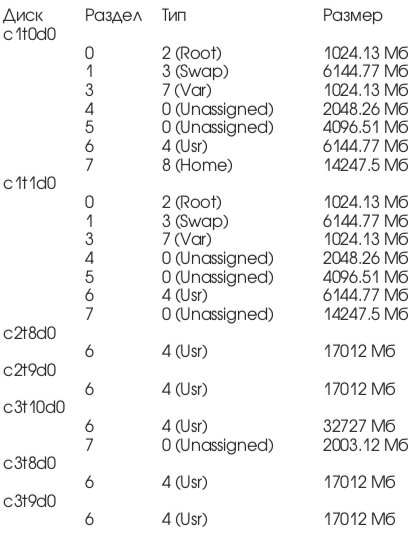
Часть разделов не размечена и, таким образом, не используется в работе.
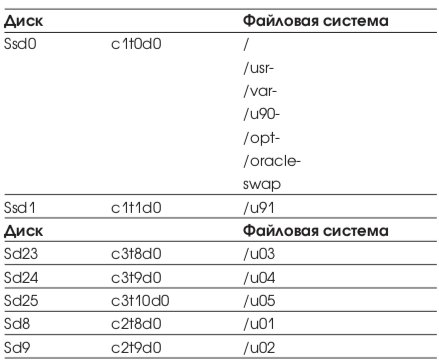
Соответствие файловых систем и физических дисков приводится в Табл. 8.
4.2 СУБД
На сервере SPRI используется СУБД Oracle 8.1.7.0. Функционирует 2 экземпляра БД: SNAB и SCEC. Исследованию подвергался только экземпляр SNAB. Его основные параметры (SGA) приведены в Табл. 9.
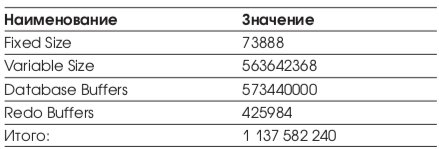
Для общей памяти экземпляра (SGA) Oracle использует ISM память. На Лист. 3 приведен список сегментов ISM памяти, используемой обоими экземплярами.
Для экземпляра SCEC SGA составляет: 622604448 байт.
Экземпляр SNAB ведется в режиме архивирования протоколов транзакций (archive log), c двумя директориями для хранения архивных журналов. Кодировка СУБД CL8MSWIN1251. Размер блока данных СУБД 8192 байт. 3 управляющих файла (control file). 3 группы журнальных файлов (redo logs) по 104 Mb.
Установлены все опции кроме Java и Parallel server. На момент проведения измерений не было установлено активных заданий (jobs).
Backup СУБД производится с помощью скрипта, выполняющего команду alter tablespace bеgin backup. Результирующие файлы помещаются на файловую систему /u91.
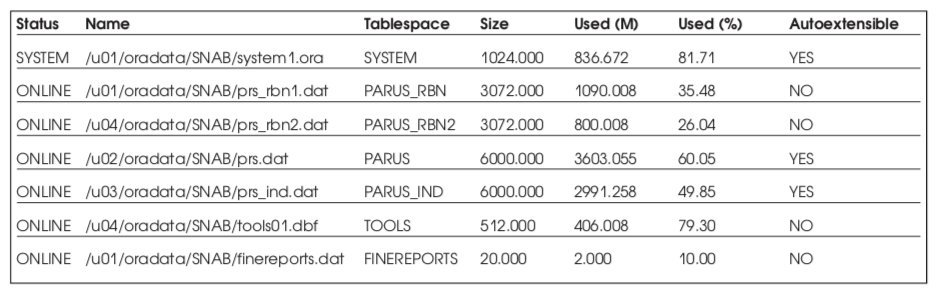
Список табличных пространств приведен в Табл. 10.

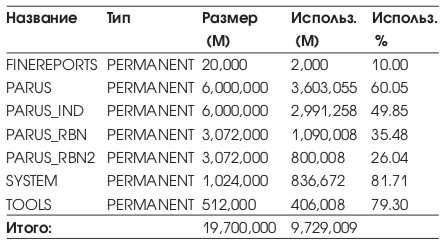
Общий объем СУБД: ~20 Gb, реально используемый 9,7 Gb. Временное табличное пространство PARUS_TEMP является локально управляемым (locally management).
Для удобства восприятия графиков нагрузки на дисковую подсистему в Табл. 11 приводятся сводные данные, объединяющие различные наименования физических устройств, названия файловых систем и расположения на них различных типов данных СУБД.
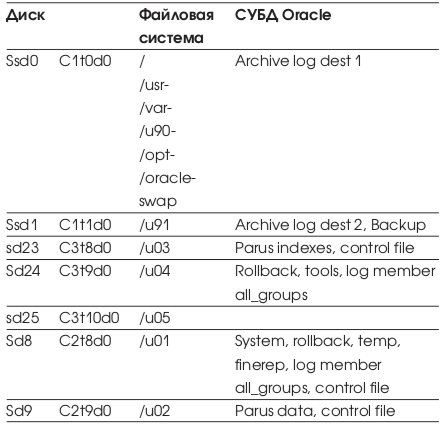
Исходя из этой таблицы, можно ожидать, что диски sd8, sd9 окажутся наиболее загруженными.
Дополнительные конфигурационные данные приведены в приложении.
5. Профиль рабочего дня
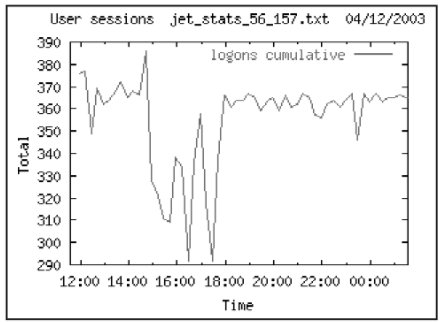
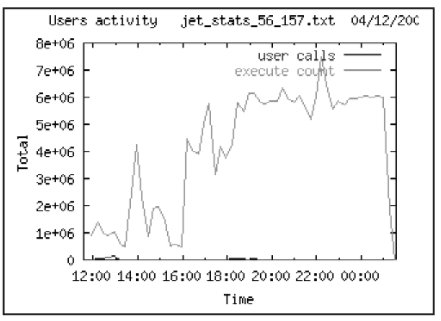
Сбор данных о производительности ИС проводился во время аудита в период с 04.12 11:30 по 05.12 10:00. Во время рабочего дня можно выделить несколько пиков активности в системе – в 12 часов, между 16 и 18 часами, а также между 22-24 часами во время выполнения резервного копирования. Среднее число пользовательских сессий во время сбора данных около 360. Реальных пользователей системы примерно 160-180. Объясняется это особенностью клиентского места – каждое клиентское место открывает 2 соединения с СУБД.
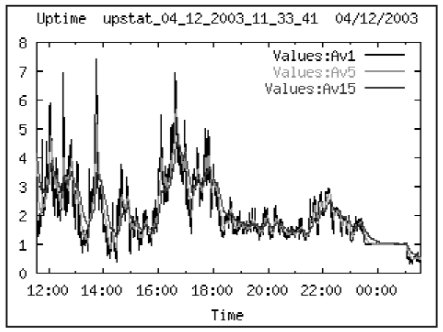
В качестве первого обзора загруженности ИС можно использовать данные о длине очереди процессов на выполнение (run queue). Считается, что ИС достаточно загружена, если длина очереди = 3 х количествово процессоров. Из Табл. 2 видно, что этот параметр превышался 3 раза за исследуемый период. В принципе это допустимый показатель, но следует обратить внимание на загрузку процессоров и определить ее причину.
На рисунках ниже показана активность пользователей во время сбора статистики.
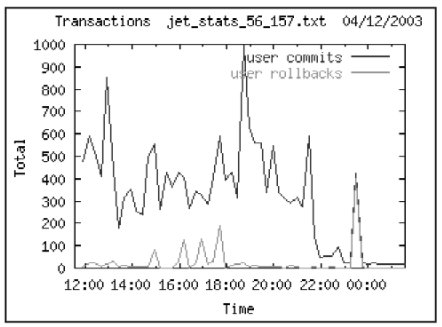
На Лист. 4. показаны кумулятивные данные о производимой работе СУБД в единицу времени и в расчете на 1 транзакцию.
Под термином транзакция понимается операция фиксации изменений commit или отказ от фиксации (rollback). Т.е. общее число транзакции = сумма commits + rollbacks.
За это время СУБД показала достаточно высокие показатели эффективности работы. Сами показатели приведены на Лист.5.
Все показатели (кроме разбор sql предложений) очень хорошие. Это означает, что в целом СУБД настроена оптимально. Низкий показатель «разбор sql предложений» вызван конкуренцией за защелки и/или недостаточной производительностью ЦПУ.
Но, к сожалению, приведенные выше показатели еще не означают, что ИС работает производительно, и что пользователи получают малое время реакции, на свои запросы. Основой для оценки времени реакции являются системные ожидания и общее время, затраченное на обработку запросов.
На основе метода YAPP, предложенного Anjo Kolk и Shari Yamaguchi, оценим влияние ожиданий СУБД на общую производительность ИС. Это позволит нам получить оценки того, как изменение настроек СУБД может повлиять на общую производительность системы.
Общее время ответа для конечного приложения (Response Time) можно определить как сумму времени обслуживания (Service Time) и времени ожидания (Wait Time):
Response Time = Service Time + Wait Time
Необходимые данные можно получить из отчета Statspack. Согласно этому отчету, общее время обслуживания составило:
'Service Time' = 763,099,594 cs (компонент CPU used by this session отчета Statspack).
Ожидания СУБД, на выполнение которых было затрачено больше всего времени, приводятся в Табл. 12:
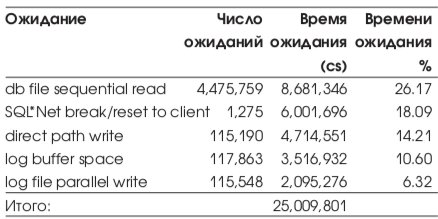
Исходя из вышеприведенных данных, получаем: 'Wait Time' =25 009 801 и соответственно 'Response Time' = 763,099,594 +25 009 801 =
788,109,395.
Таким образом, можно оценить, что время обслуживания занимает 96,8% всего времени ответа конечного приложения. Изменение параметров СУБД, направленное на уменьшение времени ожидания, даст менее 4% уменьшения времени ответа для конечного пользователя – то есть необходимо сосредоточиться на уменьшении времени обслуживания.
В следующих главах подробно рассматриваются загрузка CPU, физической памяти и дисковой подсистемы
5.1 Загрузка процессоров
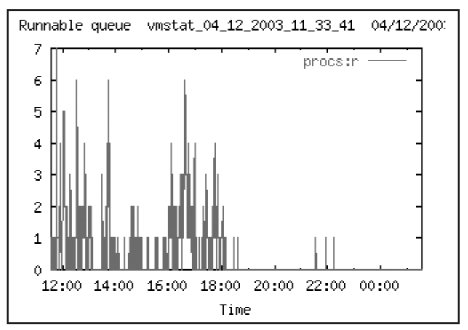
Наиболее простой оценкой загруженности системы является параметр run queue. Он показывает размер очереди выполнения – количество процессов, ожидающих в очереди на выполнение. Этот параметр позволяет оценить степень загруженности процессоров системы.
Если число процессов в очереди более чем в 3 раза превышает количество процессоров – значительно увеличивается время ожидания процессом кванта времени CPU. В интерактивных системах возрастает время реакции на запрос. Мы видим, что число 6 достигается во время рабочего дня 3 раза. Можно сделать вывод о том, что система работает на пределе мощности.
Рассмотрим графики загрузки процессоров системы. Для удобства на графиках приводятся данные за интервал времени 12.04 – 22.04.

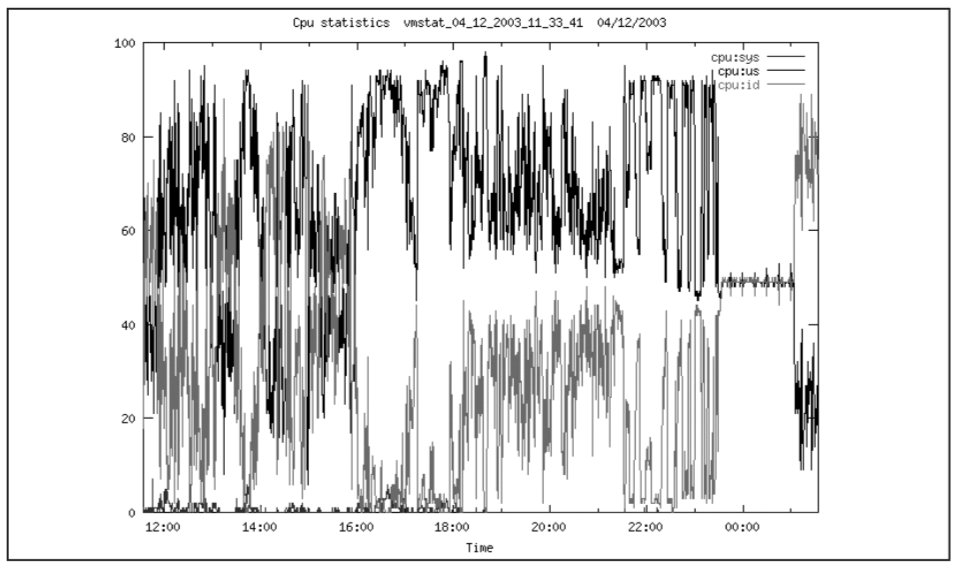
На этом рисунке видно, что загрузка процессоров большую часть времени превышает 80%, другую часть времени превышает – 90% (это время расходуется на обслуживание пользовательских процессов – а точнее СУБД Oracle).
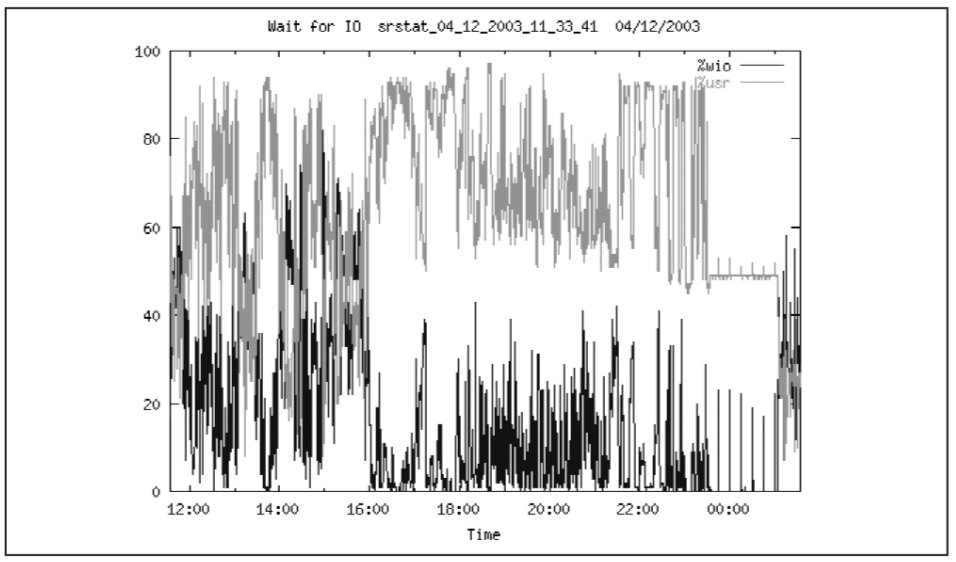
На Рис. 9 показано, что существенную часть процессорного времени (%wio), часто до 40%, а иногда до 80% процессоры ожидают ввода-вывода. Согласно Oracle8 Administrator's Reference for Sun SPARC Solaris 2.x, если процент %wio превышает более 20%, дисковая подсистема перегружена. Другие источники допускают более высокий процент %wio. Тем не менее, необходимо наметить пути модернизации дисковой подсистемы с целью уменьшения процента %wio.
Рассмотрим, на что расходуется время ЦПУ в СУБД Oracle.
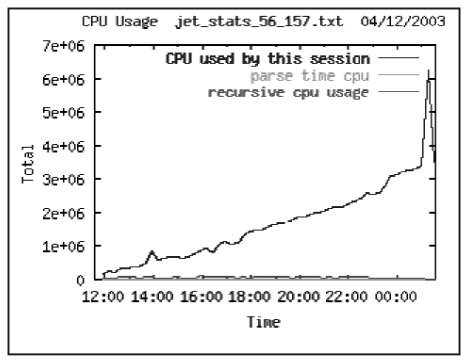
Компонент CPU Other отвечает за время, потраченное на работу с кэшом СУБД, извлечения записей или поиска по индексу. Обычно высокий процент отношения CPU Others/CPU used by this session говорит о наличии неэффективных sql, просматривающих слишком много блоков в кэше СУБД – т.е. совершающих логические чтения. Так на графике, очевидно в течение рабочего дня была запущена процедура, завершившаяся к 00 ч.
Рассчитаем компонент CPU Other (данные из Instance Activity Stats отчета Statspack).
CPU Other = CPU used by this session – Parse time CPU – Recursive CPU = 763,099,594 – 5,037,583 – 87,677 = 757974334 или 99% от CPU used by this session.
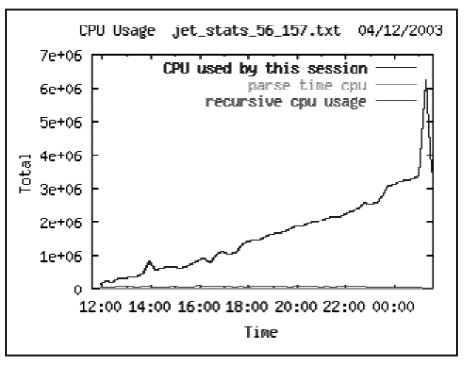
Так как компонент CPU Other составляет 99% компонента CPU used by this session можно сделать вывод, что необходимо сосредоточиться на логических чтениях в системе.
Таким образом, косвенно подтверждается, что приложение использует связанные переменные (bind variables), настройки СУБД позволяют использовать разобранные sql выражения снова и снова, не прибегая к повторному жесткому разбору.
Рассмотрим логические чтения более подробно. График логических чтений приведен на Рис. 10.
В работе Cary Millsap говорится, что логические чтения представляют собой значительную опасность производительности экземпляра, поскольку превышают по объему в тысячи раз физические чтения, а по затратам мощности всего в ~100 дешевле физических чтений.
Ниже приводится список запросов (Лист. 6), выполнивших наибольшее количество логических чтений. Именно на эти запросы следует обратить внимание в первую очередь. Необходимо помнить, что в этом списке могут быть и pl/sql процедуры и sql выражения, входящие в эти процедуры.
Следует изменить вышеприведенные sql выражения так, чтобы они выполняли меньше логических чтений.
5.2 Загрузка оперативной памяти
Общий объем физической памяти 3920 Mb.
Типичное распределение физической памяти (данные в Mb) во время рабочего дня приведено в Табл. 13.
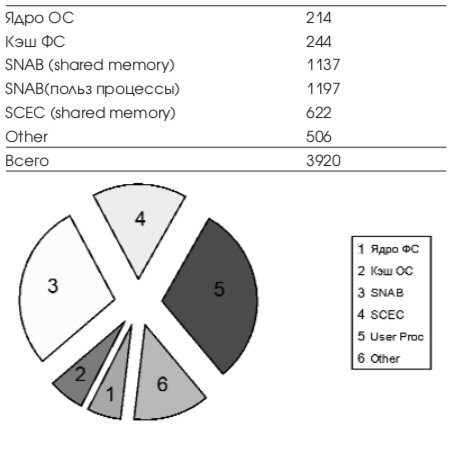
Компонент Other это сумма памяти разделяемых библиотек, процессов экземпляра SCEC и свободной памяти. Выше приведенное распределение дает нам пути нахождения дополнительной памяти в системе.
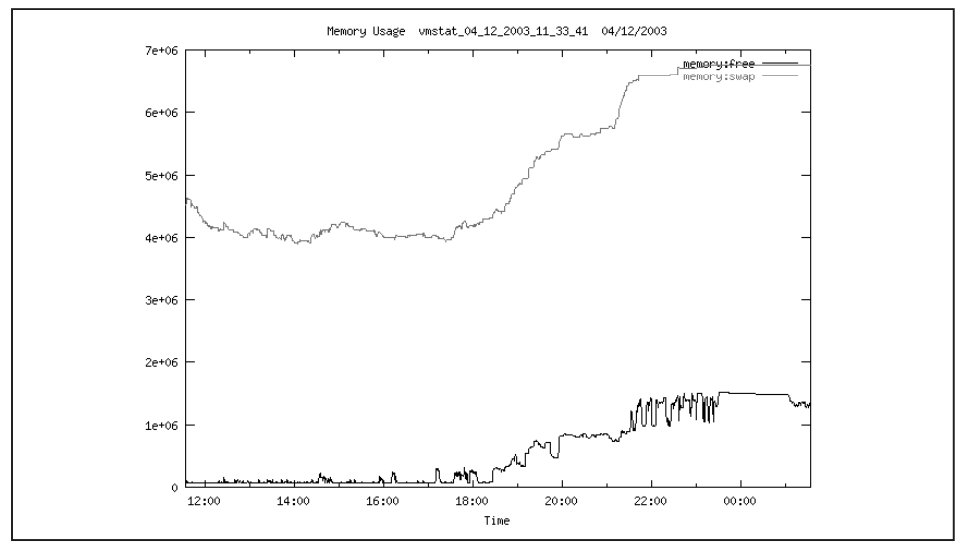
Рассмотрим сколько же реально во время работы доступно свободной памяти и swap. График приведен на Рис 11. Реально свободная физическая память около 70 Mb. Из них около 80% – свободная память кэша файловой системы. Тем не менее, данного количества памяти вполне достаточно, так как приложения работают с виртуальной памятью, в которую включается swap. А памяти swap более чем достаточно.
С другой стороны, так как файлы данных находятся на файловой системе UFS, можно ожидать активности системы, выраженной в загрузке/выгрузке страниц памяти на диск.
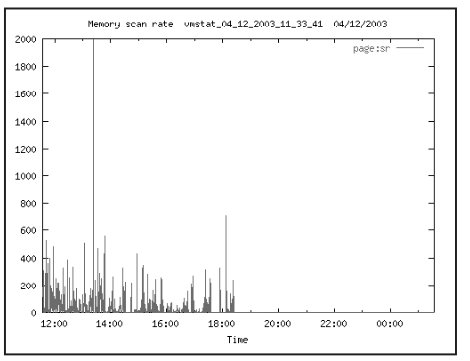
На Рис. 12 показана активность scan rate число страниц памяти, которое просматривается за секунду. Видно, что в моменты реальной работы пользователей данный параметр значительно превышает значение 192, а это означает, что кэш файловой системы активно используется для файлов СУБД и приводит к значительной дополнительной нагрузке. Исследуя график активности ввода – вывода страниц памяти на Рис. 13, можно обратить внимание, что пики такой активности совпадают с активностью приложения, и, следовательно, создают дополнительную нагрузку на систему.

5.3 Загрузка дисковой подсистемы
Общее представление о загруженности дисковой подсистемы можно получить из мониторинга общего количества процессов, ожидающих ввода вывода. На Рис. 14 видно, что в течение рабочего дня число таких процессов достигало значения 6, а в 12 часов даже 7. Это говорит о том, что в отдельные моменты времени дисковая подсистема явно перегружена. Какие именно диски перегружены, рассматривается ниже.
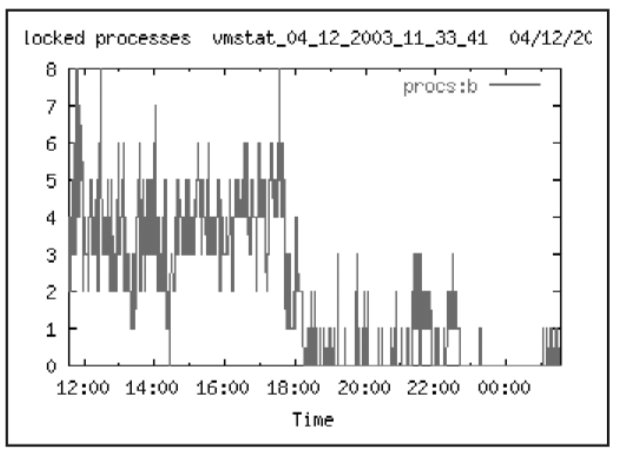
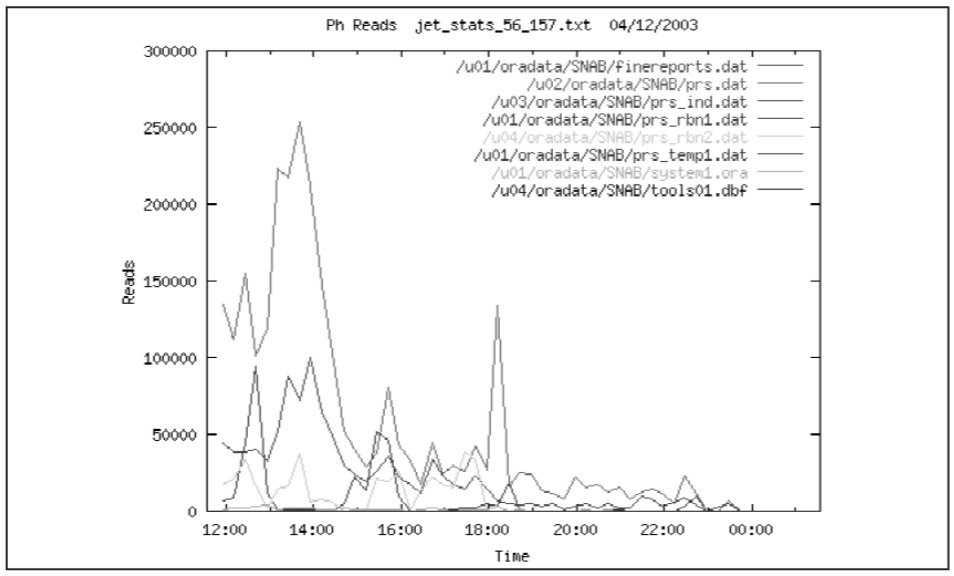
Рассмотрим также активность экземпляра SNAB – чтения и записи по файлам данных СУБД.
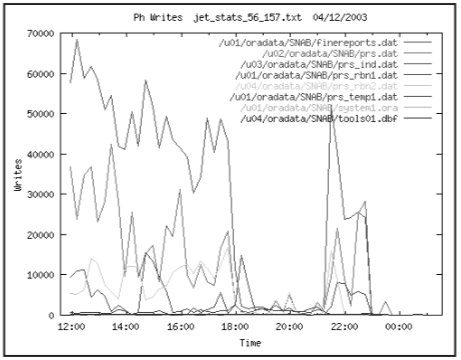
Графики чтения и записи приведены на следующих рисунках. Наибольшая нагрузка на чтение ложится на файлы табличного пространства PARUS, а нагрузка на запись на файлы табличного пространства PARUS_IND.
На Рис.17 и Рис. 18 приведены графики загрузки отдельных дисков ОС. Параметр Svc_t определяет среднее время выполнения операции ввода вывода. Параметр %busy – процент загруженности диска. Совместно эти два параметра дают качественную оценку загруженности дисковой подсистемы.
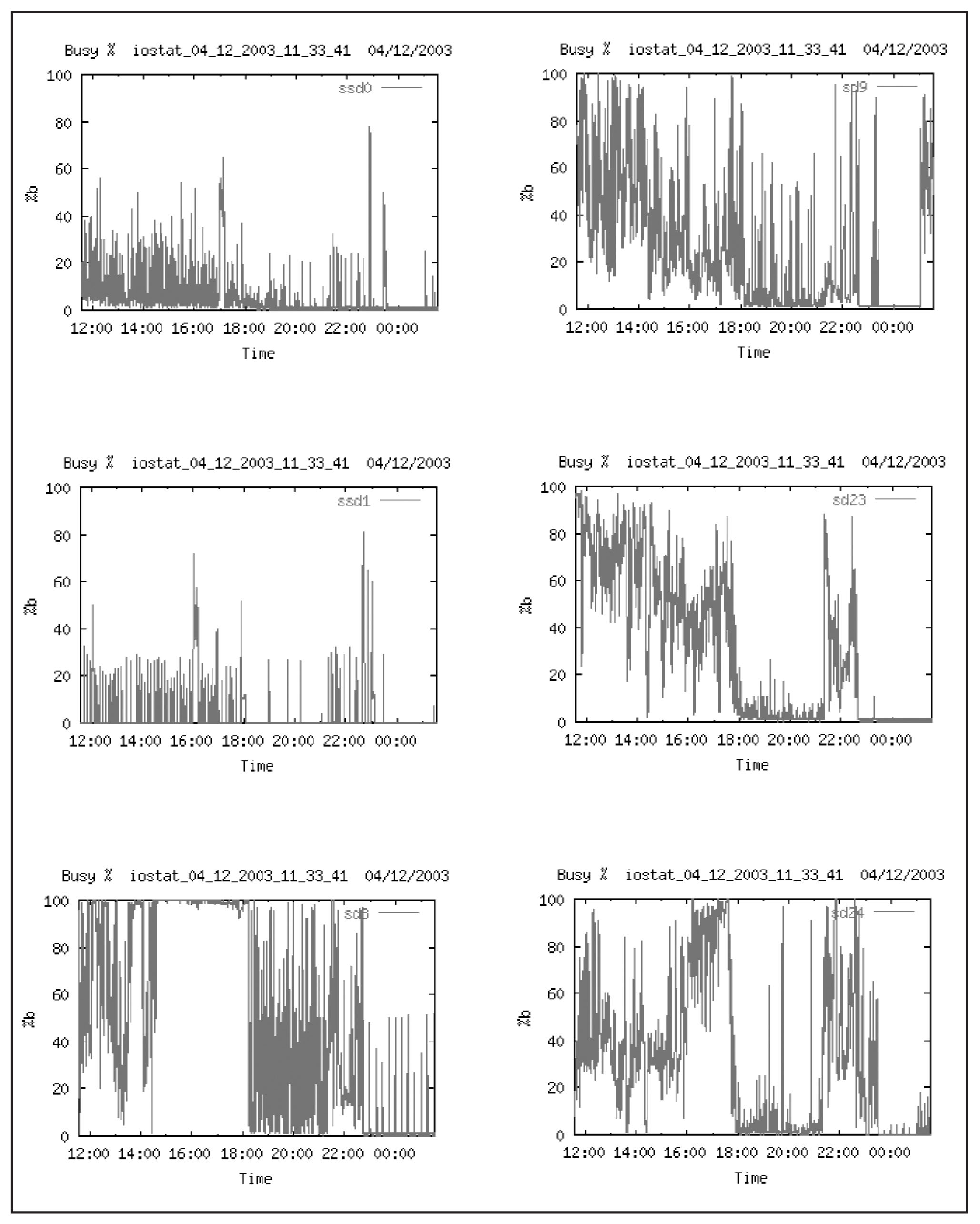
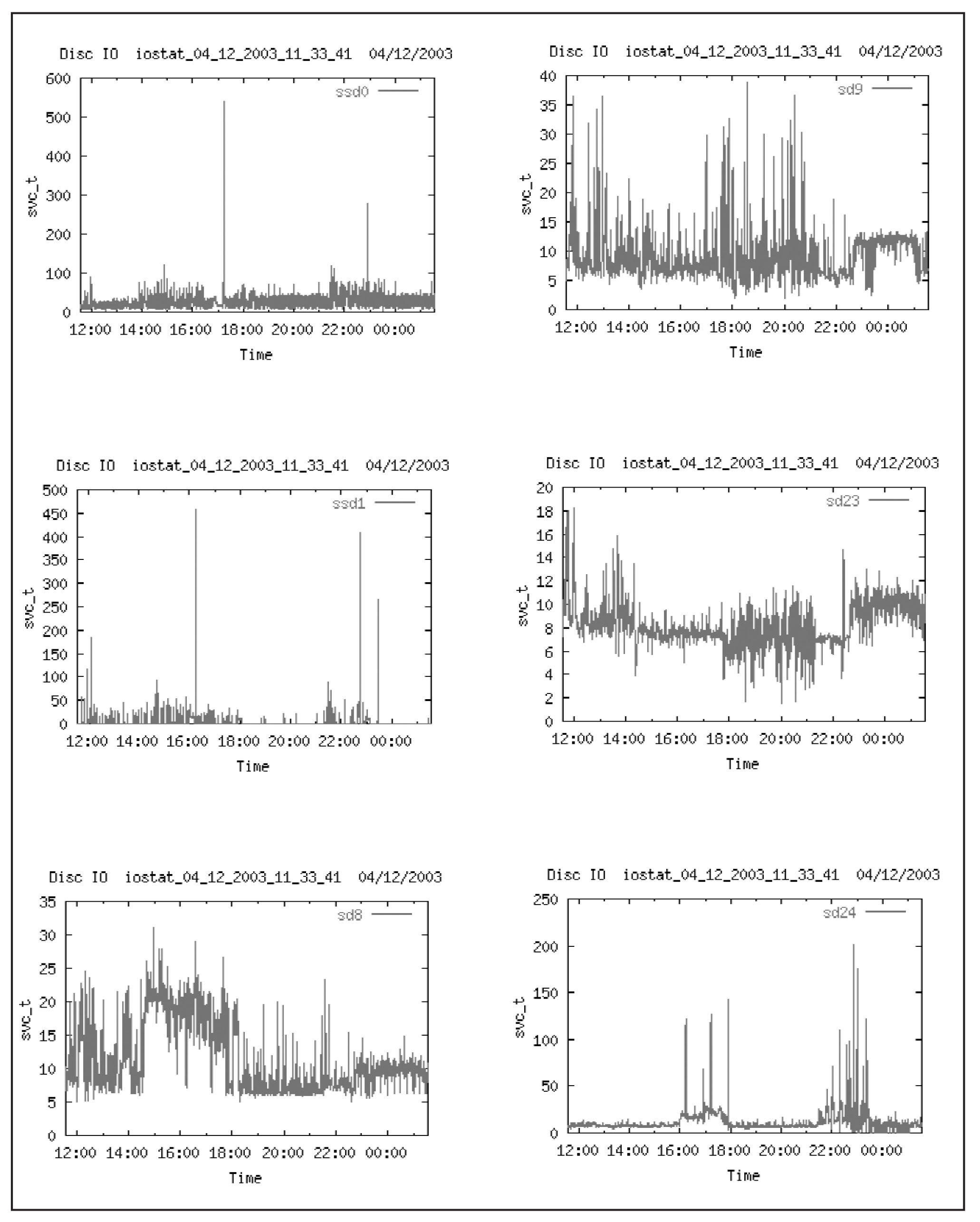
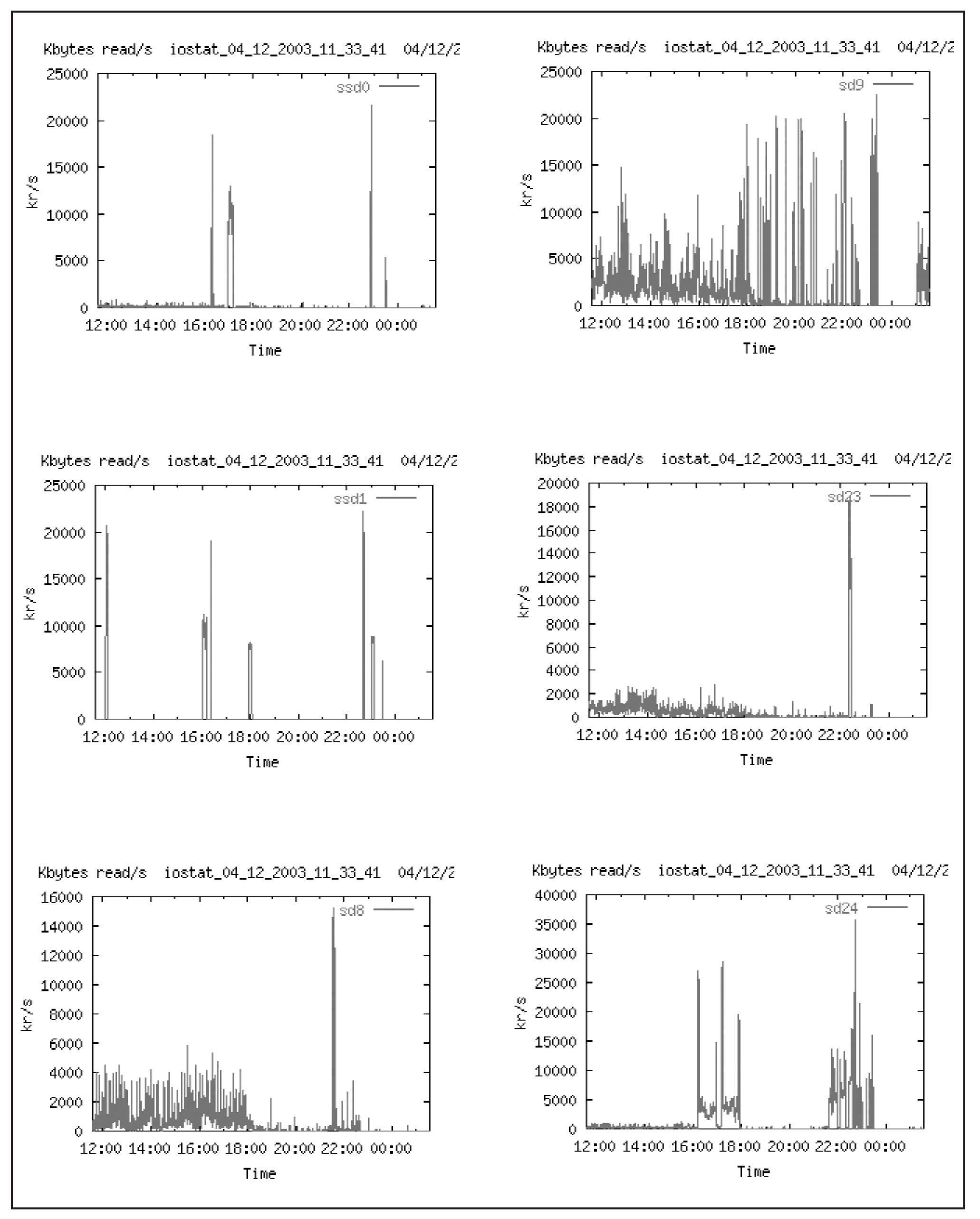
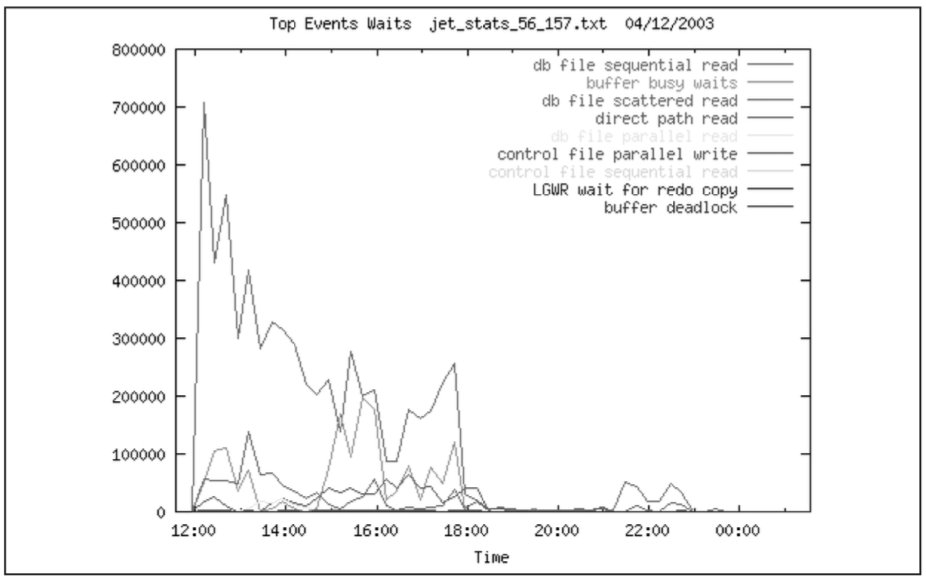
На Рис. 19 и Рис. 20 показаны объемы производимых операций Кб/c. Видно, что на операции записи наиболее загруженными являются диски sd8, sd23. Следует ожидать, что к такой активности приводят записи в rollback segments и redo logs для sd8 и записи в индексы для sd23. Для операций чтения наиболее загружен диск sd9. Следует ожидать, что к такой активности приводят чтение данных (full scan).
5.4 Сетевой интерфейс
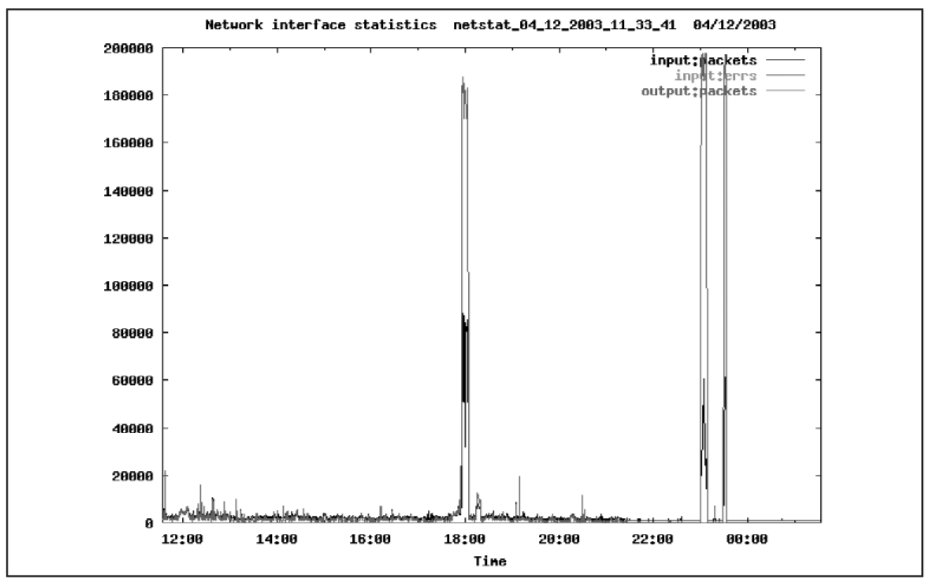
Сетевой интерфейс функционирует без ошибок. Число пакетов, принятых и отправленных через сетевой интерфейс, показано на Рис. 21.
Пик в 23 часа вызван окончанием операции резервного копирования и передачей резервной копии на другой сервер. Видно, что в прочее время загрузка сетевого интерфейса невелика. Следовательно, можно предположить, что сеть не является узким местом информационной системы.
5.5 Прочие статистики СУБД
График с наиболее важными ожиданиями блоков данных различных типов приведен на Рис. 22.
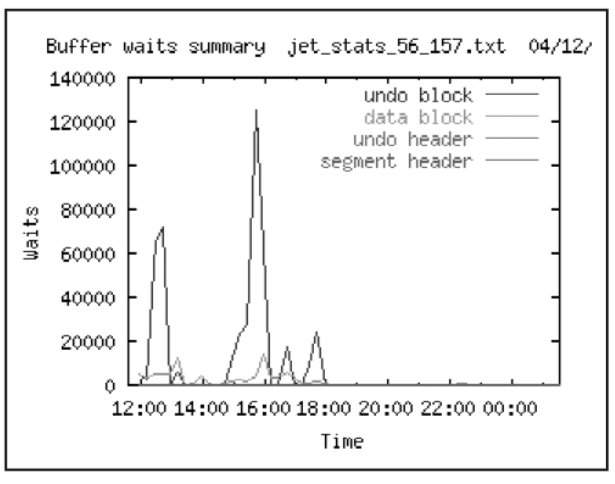
Видно, что наибольшая конкуренция за undo blocks. Действительно, всего сегментов отката 14, что при существующем кол-ве пользователей системы недостаточно.
На Рис. 22 приведено распределение времен ожиданий по типам ожиданий. Из-за масштаба событие SQL*Net break/reset to client не показано, но всплеск данного ожидания приходится на интервал времени 9.00 9.20 05.12. Скорее всего, это связано с приходом сотрудников на работу и запуском приложения.
Из графика видно, что наибольшее влияние на работу системы оказывают ожидания, связанные с чтениями данных. Прочие ожидания также связаны с вводом выводом.
6. Выводы и рекомендации
Система работает без запаса производительности. Добавление пользователей в систему или увеличение объемов данных в настоящее время может привести к серьезным проблемам с производительностью .
Необходимо срочно увеличить число процессоров и обновить дисковую подсистему.
Повысить производительность ИС можно также, выполнив оптимизацию приложения. Если добавить процессоры, то в единицу времени будет производиться больше полезной работы, и, как следствие возрастет нагрузка на дисковую подсистему, которая и так перегружена. Поэтому рекомендуется вначале обновить дисковую подсистему, сделав ее не только производительней, но и надежней.
Настройки СУБД на данный момент выполнены оптимально, и их изменение увеличит производительность системы всего лишь на несколько процентов. Поскольку большинство настроек вызовет увеличение нагрузки на систему в целом, на данном этапе без изменений в настройках ОС и аппаратной части ИС это просто опасно.
Следует уделить внимание оптимизации приложения, так как это снизит общую нагрузку на систему, позволит произвести настройки СУБД, направленные на производительность.
6.1 Рекомендации по обновлению аппаратной части
Поскольку на данный момент при выходе из строя любого из дисков дисковой подсистемы потребуется восстановление СУБД, первостепенной задачей является обновление дисковой подсистемы и, таким образом, увеличение надежности ИС, без потери производительности. Объем БД на данный момент не слишком велик по современным меркам (~10 Gb), поэтому рекомендуется использовать RAID уровня 0+1. Размер записи желательно установить равным 128 Kb + 8192 bate (размер блока СУБД). Ниже рассматривается два возможных варианта такого обновления:
- Аппаратный RAID класса T3 c объемом кэша не менее 1 Gb. Данный аппаратный массив позволит снизить потребление CPU по сравнению с программными решениями, обеспечить необходимый уровень надежности. Если подключить к данному массиву дополнительный существующий сервер, можно разработать план взаимного переноса экземпляров БД между серверами, в случае выхода из строя одного их них. Это позволит значительно повысить надежность ИС. Для размещения данных рекомендуется использовать ПО Veritas Volume Manager и Veritas File System.
- Программный RAID на основе ПО Solstice DiskSuite (входит в OC Solaris). Необходимо выделить 2 физических диска под размещение протоколов транзакций (redo logs), создав из них группу уровня 0+1 (зеркало + страйп, длина страйпа 64 Кб) и разместив на них протоколы транзакций в сырых устройствах (raw device). Резервирование протоколов транзакций средствами СУБД в данном случае не нужно, так как оно будет выполняться средствами ОС. Прочие диски, не менее 5, объединить в одну дисковую группу, создав группу уровня 0+1 и разместив на ней СУБД. На данный момент массив D2 подключен по 2 аппаратным контроллерам и в нем установлено 5 дисков (4*17 Gb + 1*36 Gb). Удобно дополнительно установить в него 6-ой диск и организовать RAID уровня 0+1 на дисках массива D2. Отдельный физический диск следует выделить под архивные логи транзакций (archive logs). Необходимо учитывать, что использование программного RAID может увеличить загрузку CPU, поэтому перед ее выполнением рекомендуется произвести оптимизацию приложения (см. дальше) или увеличить количество CPU.
После обновления дисковой подсистемы и оптимизации приложения следует еще раз измерить загрузку процессоров, а точнее распределение времени на системное (vmstat:sy), пользовательское (vmstat:us) и время простоя (vmstat:id), а также состояние очереди выполнения (vmstat:r) и очереди процессов, ожидающих ввода вывода (vmstat:b). В зависимости от показанных результатов рекомендуется дополнительно установить 1 или 2 системных процессора. Это обеспечит ИС необходимый запас производительности. Считается, что ИС имеет достаточный запас производительности, если большую часть времени ее процессоры загружены на 60-70%, в пиковые моменты времени 90%. На данный момент загрузка процессоров порядка 90% присутствует большую часть рабочего дня.
Для хранения резервных копий БД и архивных журналов транзакций надо приобрести ленточное устройство класса DLT3.
6.2 Рекомендации по изменению политики резервного копирования
Рекомендуется использовать для операций резервного копирования ПО Rman из стандартной поставки ПО Oracle. Это позволит производить резервное копирование стандартным способом, рекомендованным Oracle, предоставляя возможность ведения каталога выполненных операций резервного копирования и некоторые другие сервисные функции.
Для помещения резервных копий на ленточное устройство следует воспользоваться ПО Veritas NetBackup Business Server. Данное ПО позволит централизовать политику резервного копирования для нескольких серверов одновременно.
6.3 Рекомендации по обновлению версий ПО
Рекомендуется:
- Обновить СУБД Oracle до уровня версии патча 8.1.7.4.
Следующим шагом может стать обновление версии и СУБД до версии 9i.
6.4 Рекомендации по изменению настроек ОС
Рекомендуется:
- Монтировать те файловые системы, на которых располагаются файлы данных Oracle с ключом directio. Это позволит при обращении к ним миновать уровень кэша операционной системы, что ускорит обращения СУБД к своим данным, а также высвободит системные ресурсы от ненужной работы по загрузке – выгрузке страниц памяти (swapping and paging). Включить directio можно динамически для любой смонтированной файловой системы: mount -o remount,forcedirectio /my/filesystem.
- Установить системный параметр maxphys (/etc/systems), равным 1048576 (1 Mb). Это позволит оптимизировать дисковые операции ввода вывода при полных сканированиях таблиц.
- Установить параметр bufhwm равным 157286400 (150 Mb). Это позволит ограничить сверху физическую память, отводимую под кэш файловой системы. Размер кэша файловой системы не играет значительной роли в производительности ИС, так все данные должны кэшироваться СУБД Oracle.
6.5 Рекомендации по изменению настроек СУБД
Рекомендуется:
- Увеличить число сегментов отката (rollback segments). Oracle рекомендует использовать число сегментов отката равным числу активных сессий системы, поделенных на 4.
- Увеличить размер буфера журнала транзакций (log_buffer) до значения 1 Mb (текущее значение 409600 байт). Это позволит оптимизировать работу с журналами транзакций.
- Установить значение параметра java_pool_size = 0, или установить его равным 20Mb, одновременно установив опцию java virtual machine.
- Уменьшить значение параметра db_file_multiblock_read_count = 16. Это позволит Oracle выполнять чтения размером 128 Кб, что должно совпадать с размером записи дисковой подсистемы (см. 6.1). Эта рекомендация может изменить планы некоторых запросов.
- Увеличить число процессов DBWR, установив значение параметра db_writes_process = 2 (число процессоров).
- Установить значение параметра _filesystemio_options = setall, что позволит использовать механизм Direct/IO для доступа файлам данных, расположенных на файловых системах, смонтированных опцией DirectIO. Одновременно установить значение параметра disc_async_io = TRUE (значение по умолчанию).
Число сессий в СУБД превышает число реально работающих пользователей.
Рекомендуется:
- Разделить пользователей на группы по характеру их работы. Для пользователей, выполняющих оперативную работу, использовать режим dedicated, для прочих использовать режим mts. Для этого следует установить параметры mts = и параметр large_pool_size = 50 Mb.
- Изменить значение параметра optimizer_index_caching, установив его в значение 90. Одновременно, поскольку ИС не испытывает недостатка в оперативной памяти, рекомендуется увеличить значение db_block_buffer до 9765 (~800 Mb).
- Уменьшить значение параметра shared_pool_size до значения 200 Mb.Текущий объем (500 Mb) не требуется для работы ИС.
- Перевести табличные пространства PARUS и PARUS_IND из dictionary в local managemnt режим управления. Это позволит снизить количество рекурсивных системных вызовов СУБД.
- Изменить значение параметра spin_count. Рекомендуется установить его равным 128. Выполнять эту рекомендацию можно только после того, как измениться в сторону уменьшения загрузка CPU.
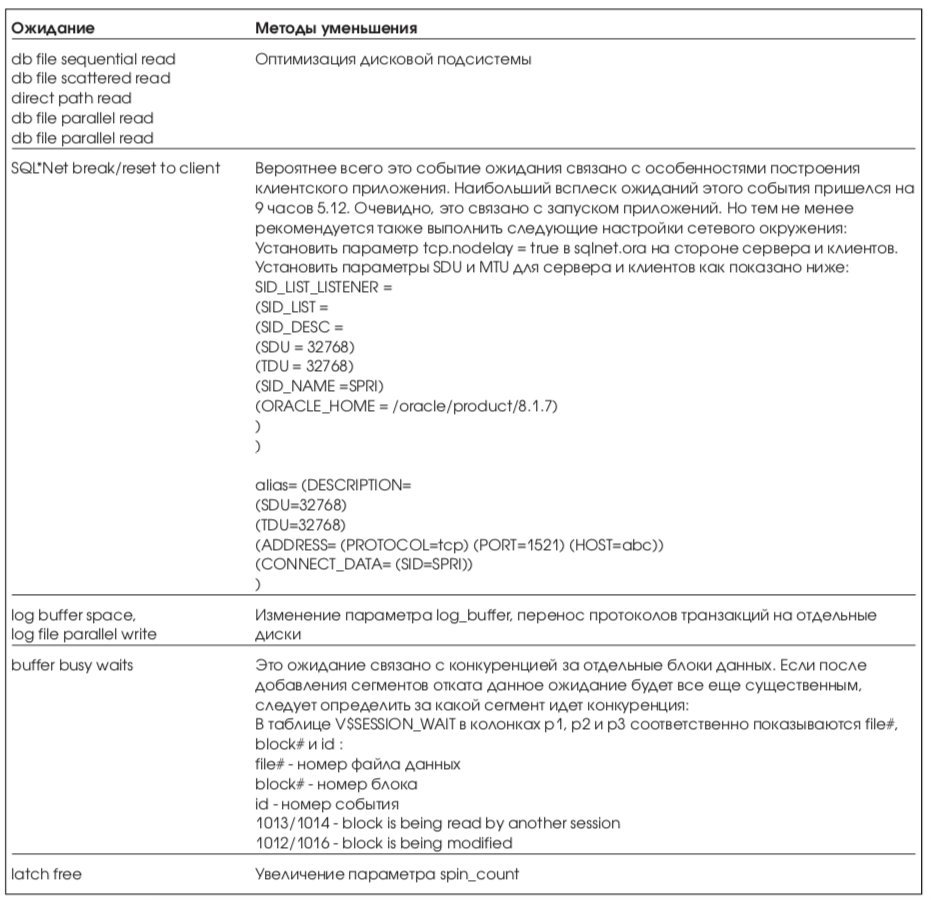
Ниже приводятся текущие основные ожидания системы и предложенные методы их уменьшения (Табл. 14).
6.6 Рекомендации по оптимизации приложения
При оптимизации приложения следует сосредоточиться на оптимизации логических чтений. Логические чтения представляют собой серьезную угрозу производительности ИС. Список sql-запросов, выполнивших наибольшее количество логических чтений см. в таблице. Если нет доступа к исходному коду, можно воспользоваться механизмом stored outlines.
Вероятнее всего, что пользователи не закрывают свои приложения в конце рабочего дня. Рекомендуется установить профили пользователей (profiles) с тем, чтобы автоматически прекращать простаивающие больше нескольких часов сессии пользователей, освобождая ресурсы для действительно работающих пользователей. Возможно это потребует согласования с бизнес подразделениями.
6.7 Рекомендации по настройкам безопасности
Несмотря на то, что ИС является внутренней, следует выполнить следующие настройки безопасности.
Для СУБД Oracle:
NARY_ACCESSIBILITY = false, что позволит защитить системный словарь данных;
- Защитить сетевой процесс прослушивания (lisener) паролем;
- Включить сбор протокола сетевого процесса прослушивания;
- Включить аудит важных событий для ИС;
Установить единую консоль сбора протоколов СУБД и ОС, такую, как Symantec Intruder Alert, или аналогичную.
Для ОС:
- Отключить протоколы telnet и ftp. Использовать для подключения только защищенное соединение SSH.
8. Приложение. Дополнительные данные о конфигурации СУБД
Параметры СУБД, установленные в значения, отличные от значений по умолчанию, приведены на Лист. 7.