 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
На наш взгляд, целесообразно провести аналогию между системами программирования и системами управления базами данных. Первые символизируют передовое начало в информационных технологиях; вторые идут следом с интервалом лет в 10 — 15. В свете этой аналогии реляционные СУБД можно уподобить системам программирования на языке Фортран-66. Известно традиционно высокое качество Фортран-компиляторов, обеспечивающее эффективность выполнения Фортран-программ, однако, строго говоря, это верно только по отношению к счетным программам. Понятно, что моделирование сложных структур данных средствами числовых массивов не только неприятно и чревато ошибками, но и ведет к неэффективному расходованию ресурсов памяти и процессора. Появившийся в Фортране-77 символьный тип данных, разумеется, не решил всех проблем.
Реляционные СУБД завоевали всеобщее признание за счет концептуальной простоты, надежности и эффективности. Сформировался стандарт на язык определения данных и манипулирования данными — SQL. Разработаны и реализованы методы распараллеливания и оптимизации выполнения SQL-запросов. Реляционные СУБД (как и Фортран-компиляторы) существуют, вероятно, для всех аппаратно-программных платформ. Но жизнь не стоит на месте. Особенно мощным катализатором развития является Интернет как хранилище и среда распространения данных разнообразной природы. И пользователям, и прикладным программистам нужны новые возможности, новые типы и структуры данных, нужны средства для добавления к базе данных собственных типов данных, желательно с сохранением выгод от распараллеливания и оптимизации. Если вернуться к аналогии с системами программирования, пользователи хотят объединить достоинства Фортрана и C++, не особенно задумываясь над тем, возможно ли это в принципе. Прикладные программисты хотят хранить в СУБД не только числа и тексты, но также изображения, видео и звук, выполнять над данными этих типов сколь угодно сложные операции, сохраняя в то же время всю присущую реляционной модели атрибутику. Понятно, что "универсальные солдаты" — большие бинарные объекты — не обеспечивают адекватного решения сформулированной задачи. По большому счету хотелось бы добавить к серверу реляционной СУБД возможность определения абстрактных типов данных.
"Подвиг надо — подвиг будет". Компания Informix разработала так называемый универсальный сервер СУБД, INFORMIX-Universal Server, построенный на основе собственных прежних разработок, а также таких известных продуктов, как СУБД Postgres и СУБД Illustra. В данной работе мы попытаемся рассмотреть INFORMIX-Universal Server версии 9.1 с точки зрения обслуживаемых им типов и структур данных, попробуем проанализировать достоинства и недостатки избранного компанией пути.
Краткий обзор типов и структур данных в INFORMIX®-Universal Server
Чтобы сделать реляционную СУБД адекватным компонентом современных приложений, необходимо предпринять по крайней мере три группы мер:
- пополнить набор встроенных типов данных;
- расширить спектр конструкторов структурных типов (структур данных);
- предоставить средства реализации абстрактных типов данных.
Приложения, использующие современные СУБД, строятся в архитектуре клиент/сервер. Если мы хотим, чтобы работа приложений была эффективной, перечисленные выше меры следует реализовать в сервере СУБД (по крайней мере, возможность реализации на серверной стороне должна существовать). Если вернуться к аналогии с системой программирования на Фортране, то следует заметить, что язык можно расширять двумя способами:
- написать препроцессор, отображающий новые возможности на стандартный язык;
- расширить входной язык, модифицировав компилятор.
Ясно, что первый путь проще, но он отчасти напоминает косметический евроремонт в старом здании без водопровода и канализации. С другой стороны, компиляторы, открытые для свободной модификации прикладными программистами, встречаются крайне редко (если вообще встречаются).
Применительно к СУБД первый вариант можно сопоставить с модификацией клиентской части (обычно это сравнительно простая и безопасная мера), второй же соответствует внесению изменений в серверную часть СУБД. В нашем случае желателен именно последний, трудный вариант, причем следует не просто выполнить однократное расширение, но дать возможность каждому прикладному программисту расширять сервер СУБД по своему усмотрению.
Разработчики INFORMIX-Universal Server пошли по второму пути, сделав эту СУБД объектно-реляционной, с расширенным набором встроенных типов, конструкторами структурных типов и средствами описания абстрактных типов данных.
Из типов данных, встроенных в INFORMIX-Universal Server, следует в первую очередь отметить две разновидности больших объектов — простые и интеллектуальные. Интеллектуальные большие объекты (текстовые или бинарные) допускают чтение/запись произвольных фрагментов, они подвергаются журнализации и могут откатываться.
INFORMIX-Universal Server позволяет определять новые типы данных. С точки зрения сервера СУБД эти типы могут быть атомарными или структурными.
Атомарные типы (называемые также типами со скрытой структурой) описываются средствами, внешними по отношению к серверу СУБД, и регистрируются в системном каталоге. Таким внешним средством может быть, например, язык C, на котором описывается представление объектов нового типа, а также функции, применимые к этим объектам (сравнение, отображение и т.п.). Хотя в терминах языка C подобные объекты могут определяться как структуры, сервер СУБД не знает и, следовательно, не интерпретирует их содержимое, то есть считает их атомарными.
К техническим моментам можно отнести средства для определения типов с новым именем, заимствующих у одного из ранее описанных типов внутреннее представление и функциональность. Подобная возможность присутствует, по-видимому, во всех системах с именной эквивалентностью типов; она необходима для частичного изменения поведения объектов со встроенной структурой.
Очень важным является введение в INFORMIX-Universal Server на уровне языка SQL структур данных (конструкторов типов) — множеств, мультимножеств, списков и реляционных строк.
Множество (конструктор SET) — это неупорядоченный набор однотипных элементов с поддержанием уникальности.
Мультимножество (конструктор MULTISET) — это множество, элементы в котором могут повторяться.
Список (конструктор LIST) представляет собой упорядоченный набор элементов. По существу это одномерный массив.
Реляционные строки как структурный тип данных представляют собой совокупность поименованных элементов — полей. В традиционных языках программирования аналогом реляционной строки является запись.
Множества, мультимножества и списки представляют собой однородные структуры, все элементы которых имеют один и тот же тип. Реляционные строки, вообще говоря, состоят из разнотипных элементов. INFORMIX-Universal Server не накладывает ограничений на тип элементов структурных объектов, то есть структуры данных могут быть вложенными.
Если придерживаться объектно-ориентированного подхода, каждый тип данных следует характеризовать двумя группами свойств:
- представлением значений данного типа;
- подпрограммами (методами), применимыми к значениям данного типа.
Обычно типы определяют не "с нуля", а наследуют свойства у ранее описанных типов, добавляя к ним новые компоненты и методы и/или изменяя поведение существующих методов. INFORMIX-Universal Server поддерживает одиночное наследование. Новые или модифицированные методы реализуются с использованием языка хранимых процедур (Stored Procedures Language — SPL) или какого-либо внешнего языка. В версии 9.1 в этом качестве могут выступать языки C и, с некоторыми оговорками, C++; в ближайших версиях к ним присоединится Java.
Если объекты нового типа предполагается индексировать, необходимо определить так называемые вторичные методы доступа, отвечающие за работу с индексами. INFORMIX-Universal Server предлагает несколько вторичных методов, применимых к данным различной природы. Например, для обслуживания индексов пространственных данных используются R-деревья, позволяющие эффективно разыскивать объекты по их пространственным координатам.
Новые подпрограммы (процедуры и функции), необходимо не только реализовать, но и зарегистрировать в базе данных. При регистрации можно сообщить информацию, способствующую оптимизации работы сервера. Если функция при заданных значениях параметров возвращает фиксированный результат и не имеет побочных эффектов, ее целесообразно специфицировать как невариантную. В таком случае оптимизатор в состоянии проиндексировать вызовы функций, избегая их многократного выполнения.
Центральное место в INFORMIX-Universal Server занимает концепция DataBlade ("лезвий данных" — по аналогии со сменными лезвиями в многоразовом бритвенном станке). Обычно модуль DataBlade представляет собой совокупность объектов (данных и программ), обеспечивающих законченную функциональность в какой-либо предметной области. Модули DataBlade добавляются к серверу СУБД, расширяя тем самым его возможности. Установленные модули доступны из SQL-запросов, из прикладных программ и из других модулей DataBlade. Возникает иерархия, характерная для объектно-ориентированных систем.
Существуют модули DataBlade для организации связи между Web-серверами и серверами СУБД, для работы с пространственными данными, для индексирования текстовых документов и т.п.
Очевидно, любая модификация (и, в частности, пополнение) сервера СУБД связана с определенным риском. Чтобы уменьшить этот риск, компания Informix организовала процедуру сертификации модулей DataBlade. Число сертифицированных модулей на момент написания статьи составляло около трех десятков и продолжало быстро расти. За счет этого пользователи и прикладные программисты получают в свое распоряжение большое число разнообразных, проверенных расширений для различных предметных областей.
В последующих разделах мы подробно опишем возможности INFORMIX-Universal Server по работе с расширенным набором типов и структур данных.
Расширение функциональности типов данных
В INFORMIX-Universal Server существует три основных направления расширения функциональности типов данных:
- определение новых подпрограмм (процедур и функций);
- определение новых функций преобразования типов;
- расширение классов операторов для вторичных методов доступа.
Далее мы по очереди рассмотрим эти направления.
Определение новых подпрограмм
Подпрограммы, которые в INFORMIX-Universal Server могут быть вызваны средствами SQL, подразделяются на следующие категории:
- операции (такие как +,-,* и т.д.) и ассоциированные с ними функции;
- встроенные функции (abs (), cos () и т.д.);
- агрегатные функции (SUM, AVG и т.д.);
- подпрограммы, определенные разработчиком приложений.
Реализация новых подпрограмм (методов), применимых к новым типам данных, является наиболее распространенным, но, пожалуй, и наиболее очевидным способом расширения функциональности сервера СУБД, поэтому в данном разделе мы уделим основное внимание другим способам.
Подпрограммы, входящие в состав сервера СУБД, как правило, рассчитаны только на встроенные типы данных. Чтобы распространить их на новые типы, определенные разработчиком, необходимо написать подпрограмму с тем же именем, что и стандартная, но с другими типами аргументов (то есть "перегрузить" имя стандартной подпрограммы). Механизм перегрузки обеспечивает естественность и однородность синтаксиса выражений и операторов SQL, обрабатывающих как встроенные, так и определяемые типы данных.
Для расширения функциональности операций следует перегрузить ассоциированные с ними функции — plus (), minus (), times () и т.п. Отметим, что перегружаться могут не только арифметические, но и текстовые операции (LIKE, MATCHES, ||), а также операции отношения (=, ≠, <, ≤ и т.п.).
Агрегатные функции, по сути являющиеся производными соответствующих операций, обычно распространяются на новые типы автоматически и не допускают явной перегрузки.
Новые подпрограммы (процедуры и функции, как перегружающие одноименные стандартные, так и совершенно новые) пишутся на языках C, C++ (в скором времени станет возможным использование для этой цели языка Java) или SPL и регистрируются в базе данных с помощью операторов CREATE PROCEDURE или CREATE FUNCTION. Естественно, подпрограммы, написанные не на SPL, необходимо до регистрации скомпилировать и поместить в разделяемую библиотеку, доступную серверу СУБД.
Приведем пример оператора регистрации функции:

Здесь предполагается, что тип my_int был тем или иным способом определен ранее, что реализующая операцию сложения C-функция называется my_plus, и что она не имеет побочных эффектов.
Функция my_plus будет вызываться тогда, когда аргументы операции сложения будут иметь тип my_int.
После регистрации подпрограмм, посредством оператора GRANT EXECUTE, необходимо предоставить права на их выполнение, например:

Определение новых функций преобразования типов
Функции преобразования типов, определяемые разработчиком приложений, позволяют обеспечить связь между новыми и уже существующими типами данных, избежать написания лишних подпрограмм в тех случаях, когда разумно воспользоваться уже разработанными средствами для сходных типов.
Обычно преобразования реализуются для типов со скрытой структурой и для именованных реляционных строк. В большинстве случаев преобразование связано с выполнением некоторых действий, которые нужно обычным образом оформить в виде функции (см. предыдущий пункт) и зарегистрировать в базе данных с помощью SQL-оператора CREATE CAST, например:

(здесь percent — ранее определенный тип).
Преобразования типов бывают явные и неявные. Первые задаются синтаксической конструкцией

или операцией

Неявные преобразования выполняются сервером СУБД автоматически при обработке выражений, параметров подпрограмм и т.п. По умолчанию с помощью конструкции CREATE CAST регистрируются явные преобразования. Ключевое слово IMPLICIT задает неявное преобразование:

Такое преобразование позволяет серверу СУБД переводить десятичные числа в проценты тогда, когда он сочтет нужным.
Расширение классов операторов для вторичных методов доступа
Под вторичным методом доступа в INFORMIX-Universal Server понимается совокупность средств, позволяющих строить индексные структуры, манипулировать ими и осуществлять к ним доступ. Стандартным вторичным методом доступа являются обобщенные B-деревья (имя метода — btree), рассчитанные на линейную упорядоченность хранимых значений. Для работы с пространственными данными могут использоваться так называемые R-деревья (имя метода — rtree), реализованные в ряде поставляемых модулей DataBlade. Для других прикладных областей возможно определение иных методов.
Важнейшей составной частью вторичного метода доступа является класс операторов, представляющий собой набор функций, ассоциированных с методом. Некоторые из этих функций (называемые стратегическими) могут входить в фильтрующую часть SQL-запросов, другие (вспомогательные) предназначены "для служебного пользования" сервером СУБД при операциях с индексными структурами. Если оптимизатор при обработке SQL-запроса встретит какую-либо стратегическую функцию, и если для соответствующего столбца определен индекс, оптимизатор, возможно, воспользуется этим индексом, и тогда будут вызываться вспомогательные функции.
Для метода доступа btree стандартным является класс операторов btree_ops, в который входят пять стратегических функций (соответствующих операциям отношения <, ≤, =, ≥, >) и одна вспомогательная функция — compare (), сравнивающая свои аргументы и, в зависимости от результата сравнения, возвращающая отрицательное, нулевое или положительное целое число.
Первоначально класс операторов btree_ops рассчитан только на работу со встроенными типами данных. Однако, пользуясь механизмом перегрузки, можно определить одноименные функции с аргументами новых типов (реализованных разработчиком приложений), после чего столбцы со значениями новых типов можно будет индексировать. В этом и состоит обобщенность B-деревьев в INFORMIX-Universal Server.
Пусть, например, мы определили новый тип ScottishName и хотим сравнивать шотландские фамилии таким образом, чтобы цепочки символов 'Mc' и 'Mac' не различались. Для индексирования подобных значений с помощью обобщенных B-деревьев необходимо реализовать на языках C или SPL пять стратегических функций (lessthan (), lessthanorequal (), equal (), greaterthan (), greaterthanorequal ()), одну вспомогательную функцию (compare ()), зарегистрировать их и создать индекс для столбца таблицы:

INFORMIX-Universal Server не позволяет переопределять стандартные подпрограммы, работающие со встроенными типами данных. Поэтому, если требуется изменить способ сравнения чисел или текстов, механизмом перегрузки воспользоваться не удастся. Можно, однако, определить новый класс операторов для вторичного метода доступа, и в рамках этого класса реализовать нужные функции, рассчитанные в том числе и на встроенные типы данных.
Пусть, например, желательно сравнивать целые числа по абсолютной величине. Определим для метода доступа btree новый класс операторов:

Поскольку в данном случае вторичный метод доступа остался прежним (это обобщенные B-деревья), должен сохраниться и смысл стратегических и вспомогательных функций, так что определение нового класса операторов по сути мало отличается от описанного выше расширения существующего класса.
Определим таблицу и индекс для ее столбца, использующий новый класс операторов:

Теперь при обработке запроса вида

возможно, будет использован индекс c_num_ix, с помощью которого выявятся все строки таблицы cust_tab, значения cust_num в которых лежат в интервале (-7; 7).
Определение нового вторичного метода доступа — действие возможное, но довольно сложное, и здесь сколько-нибудь подробно рассматриваться не будет. Отметим лишь, что классы операторов у новых методов могут принципиально отличаться от btree_ops. B-деревья рассчитаны на линейную упорядоченность индексируемых значений. Для многих типов данных такая упорядоченность не является естественной. Например, для вторичного метода доступа rtree, рассчитанного на работу с пространственными данными, определены следующие стратегические функции:
- Overlap () — истина, если пространственные области перекрываются;
- Equal () — истина, если области совпадают;
- Contains () — истина, если первая область-параметр содержит вторую;
- Within () — истина, если первая область входит во вторую.
Для метода rtree определены три вспомогательные функции:
- Union () — объединение областей;
- Size () — вычисление площади области;
- Inter () — пересечение областей.
- Очевидно, реализация R-деревьев коренным образом отличается от реализации B-деревьев.
Можно сделать вывод, что в INFORMIX-Universal Server индексные структуры оформлены как абстрактные объекты с методами, доступными для реализации прикладными программистами, и это является очень важным достоинством данного сервера СУБД.
Интеллектуальные большие объекты
Большими считаются объекты, которые логически принадлежат столбцам таблицы, но физически (по соображениям эффективности) хранятся в отдельных дисковых областях. Размер столбца, содержащего большие объекты, может достигать 4 Тб.
На Рис. 1 приведена иерархия типов больших объектов.
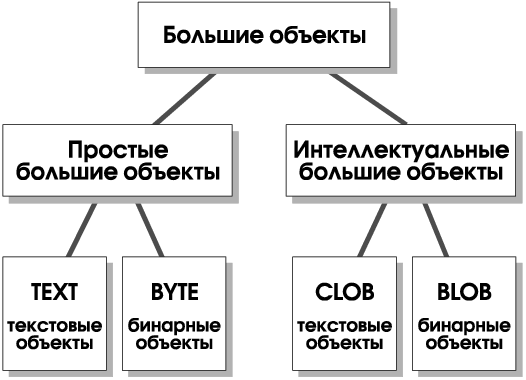
Интеллектуальные большие объекты, поддерживаемые в INFORMIX-Universal Server, позволяют снять неприятные реализационные ограничения, характерные для трактовки больших объектов реляционными СУБД. Такие объекты могут подвергаться журнализации и откатке, что важно для сохранения целостности и доступности данных.
Более точно — при определении столбца, содержащего интеллектуальные большие объекты, могут быть заданы параметры LOG или NOLOG, определяющие, будут ли протоколироваться операции с этим столбцом (с учетом текущего режима журнализации). В данном случае прикладной программист или администратор базы данных сам должен выбрать баланс между надежностью и эффективностью.
На уровне SQL к интеллектуальным большим объектам применимы следующие операции:
- FILETOBLOB, FILETOCLOB — копирование файла в большой объект (бинарный или текстовый соответственно);
- LOTOFILE — копирование большого объекта в файл;
- LOCOPY — копирование больших объектов.
Приведем пример использования операций с большими файлами:

Уже этот простой пример заслуживает некоторых пояснений. Во-первых, реально SQL-операторы работают не с самими большими объектами, а с их описателями. Эти описатели помещаются в таблицы, передаются подпрограммам на ESQL/C и т.п. Прикладная программа, получив описатель интеллектуального большого объекта, может работать с ним примерно так же, как и с файлом операционной системы. В частности, программисту, пишущему на ESQL/C, доступны такие функции, как:
- ifx_lo_read (чтение);
- ifx_lo_readwithseek (чтение с предварительным позиционированием);
- ifx_lo_write (запись);
- ifx_lo_writewithseek (запись с предварительным позиционированием);
- ifx_lo_seek (позиционирование)
и некоторые другие.
Второе пояснение относится к аргументу 'client' функции FILETOCLOB. В INFORMIX-Universal Server многие компоненты распределенного приложения клиент/сервер могут находиться или на клиентской, или на серверной стороне и изменение расположения компонентов не требует внесения существенных изменений в приложение. В данном случае сервер СУБД должен знать, как интерпретировать имя файла; обнаружив параметр 'client', он извлечет файл haven.rsm из текущего каталога клиентского компьютера.
Типы со скрытой структурой
Типы со скрытой структурой являются абстрактными в строгом смысле этого слова. INFORMIX-Universal Server лишен какой-либо информации об их внутреннем устройстве и может манипулировать соответствующими значениями только посредством предоставленных разработчиком методов.
Чтобы определить тип со скрытой структурой, необходимо выполнить следующую последовательность действий:
- описать на языке C (или другом внешнем языке) структуру определяемых объектов;
- написать на языке C (или другом внешнем языке) вспомогательные функции, вызываемые сервером СУБД;
- зарегистрировать определяемый тип в базе данных посредством оператора CREATE OPAQUE TYPE;
- зарегистрировать вспомогательные функции посредством операторов CREATE FUNCTION и CREATE CAST;
- предоставить права доступа к определяемому типу и его вспомогательным функциям посредством оператора GRANT;
- написать требующиеся для приложения дополнительные функции, которые можно вызывать средствами SQL, и зарегистрировать их;
- если нужно, реализовать специфические для определяемого типа вторичные методы доступа (функции для работы с индексами).
Ниже мы рассмотрим каждый из перечисленных этапов.
Описание структуры определяемых объектов
Структура определяемых объектов задается стандартным для языка C образом. Обычно это действительно структура (struct), которая может иметь как постоянную, так и переменную длину (более точно, переменную длину может иметь только последнее поле определяемой структуры).
Пусть, например, мы хотим хранить в базе данных информацию о плоских геометрических фигурах — кругах и многоугольниках. Для этой цели мы определим два разных типа со скрытой структурой.
Сначала опишем на языке C вспомогательный тип:

Для представления кругов можно воспользоваться следующей структурой фиксированной длина:

Более сложная структура необходима для хранения многоугольников, поскольку у них может быть произвольное число вершин:

Еще сложнее могут быть устроены объекты, хранящие двумерные изображения. Главная проблема состоит в многовариантности представления значений этого типа. Небольшие изображения хотелось бы хранить непосредственно в теле объекта, а большие изображения — в отдельных интеллектуальных больших объектах, помещая в значения лишь их описатели. Соответствующая C-структура может выглядеть следующим образом:

Разумеется, поле img_data будет иметь переменную длину, определяемую размером изображения.
Вспомогательные функции
Вспомогательные функции позволяют серверу СУБД манипулировать объектами определяемого типа. Перечень этих функций выглядит следующим образом:
- input — преобразование объекта определяемого типа из внешнего (по отношению к базе данных) текстового представления во внутреннее (описанное C-структурой);
- output — преобразование из внутреннего представления во внешнее (текстовое);
- import/export — обработка объектов определяемых типов при импорте/экспорте средствами массового копирования;
- importbinary/exportbinary — обработка объектов при импорте/экспорте во внутреннем формате средствами массового копирования;
- receive/send — преобразование объекта из внутреннего представления на клиентском компьютере в представление на сервере/обратное преобразование;
- assign — обработка объекта перед запоминанием его на диске;
- destroy — обработка объекта перед удалением реляционной строки, в которой он содержится;
- lohandles — получение списка интеллектуальных больших объектов, встроенных в значение определяемого типа;
- compare — сравнение объектов в процессе сортировки.
Первые восемь функций (от input до send) относятся к категории функций преобразования типов. Так, например, input обычно неявно вызывается сервером СУБД при обработке запросов на добавление или изменение, поступивших с клиентского компьютера, (см. Рис. 2) и осуществляет преобразование из типа LVARCHAR во внутреннее представление:

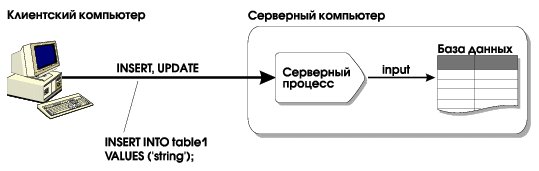
Тело функции circle_input будет состоять из ряда обращений к sscanf (); мы не станем приводить его.
Преобразования receive/send могут понадобиться в силу аппаратно-программных различий между клиентскими и серверными системами (разный аппаратный порядок байт, разное выравнивание структур, разная кодировка и т.п.). При подключении каждого клиента на сервер передается строка, характеризующая его (клиента) специфику. При реализации функций receive/send эта специфика должна быть учтена; в таком случае данные преобразования будут мобильными относительно смены клиентской платформы.
Преобразования, составляющие пары, (input/output, import/export и т.д.) должны быть взаимно обратными. Вообще говоря, не обязательно определять все преобразования. Например, если не заданы особые действия при импорте/экспорте средствами массового копирования, сервер СУБД воспользуется функциями input/output.
Для некоторых типов со скрытой структурой могут требоваться особые действия при сохранении соответствующих значений в базе данных и при удалении их из базы. Функция assign () вызывается непосредственно перед сохранением объекта на диске (см. Рис. 3), функция destroy () — непосредственно перед удалением.
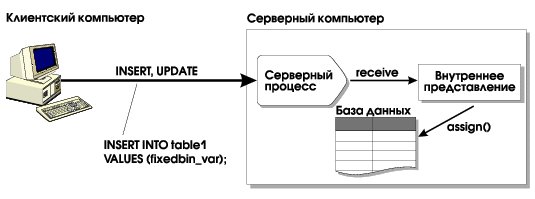
Заголовок метода assign для двумерных изображений может выглядеть так:

Обычно метод assign () реализуют тогда, когда часть данных приходится сохранять в отдельных больших объектах, или когда перед сохранением желательно приведение многовариантной структуры к выбранному каноническому представлению.
Функция destroy () — это типичный деструктор в смысле языка C++. Применение деструктора, как правило, связано с поддержанием числа ссылок на отдельно хранящиеся большие объекты.
Функция lohandles (), возвращающая список больших объектов, входящих в состав значения со скрытой структурой, необходима для выполнения операций архивирования, проверки целостности и т.п.
Функция compare () используется сервером СУБД при обслуживании индексных структур и при обработке SQL-операторов SELECT, содержащих конструкции ORDER BY, UNIQUE, DISTINCT, UNION. Эта функция входит в состав класса операторов для вторичного метода доступа btree (см. Разд. Расширение классов операторов для вторичных методов доступа).
Регистрация типа со скрытой структурой
Регистрация в базе данных типа со скрытой структурой выполняется посредством оператора CREATE OPAQUE TYPE с рядом параметров, основное назначение которых — сообщить серверу размер нового типа и некоторые детали его трактовки. Например, тип "круг" можно зарегистрировать следующим образом:

Внутреннее имя типа (circle_t), использованное в описании на языке C, здесь не фигурирует, поскольку серверу СУБД оно не нужно. Серверу сообщают лишь, что объекты нового типа со скрытой структурой circle будут иметь фиксированную длину — 24 байта (столько занимают три вещественных числа двойной точности).
Для регистрации типа — многоугольника может использоваться такая конструкция:

По умолчанию максимальный размер объекта со скрытой структурой составляет 2 Кб. Чтобы задать другое значение, можно использовать конструкцию MAXLEN, например:

В описываемой версии сервера СУБД максимальный размер не может превышать 32 Кб. Это нельзя считать сколько-нибудь обременительным ограничением, поскольку крупные компоненты могут представляться дескрипторами больших (обычно интеллектуальных) объектов.
Регистрация вспомогательных функций
Перед регистрацией вспомогательных функций их необходимо скомпилировать и поместить в разделяемую библиотеку, доступную серверу СУБД. Если предположить, что эта библиотека для типа circle расположится в файле /usr/lib/circle.so, регистрация первых восьми функций (input — send) может быть произведена операторами вида

Отметим, что здесь регистрируемые имена отличаются от имен C-функций; связь между ними устанавливается конструкцией EXTERNAL NAME. Впрочем, отличаются они и от input, output, ..., send. Дело в том, что в данном случае важно не имя, а выполняемое преобразование типов — именно оно связывает, например, circle_in со вспомогательной функцией input.
Функции assign (), destroy (), lohandles (), compare () должны регистрироваться именно под этими именами, поскольку для их определения и вызова используются механизмы перегрузки и разрешения имен. Регистрация функции assign () для типа polygon может выглядеть так:

Определение прав доступа к типу и вспомогательным функциям
Права доступа к типу выделяются оператором GRANT USAGE, например:

Для передачи прав на выполнение используется оператор GRANT EXECUTE:

Некоторую проблему составляет передача прав на выполнение функций с перегруженными именами (assign, compare и т.п.). Эту проблему можно решить по крайней мере двумя способами:
- указанием в операторе GRANT EXECUTE типов параметров функции;
- заданием в операторе CREATE FUNCTION специфического имени и использованием этого имени в операторе GRANT EXECUTE.
При первом способе мы можем использовать оператор

При втором способе можно зарегистрировать функцию и ее специфическое имя оператором

и затем передать права с указанием специфического имени:

Полиморфизм всегда привносит определенные технические проблемы; в INFORMIX-Universal Server с ними справились достаточно аккуратно.
Реализация прикладных функций
В качестве примеров прикладных функций, определяемых над типом со скрытой структурой и доступных из SQL, приведем функции для вычисления радиуса и площади круга. Первая из них очевидным образом записывается на языке C, компилируется, помещается в разделяемую библиотеку и регистрируется оператором

(Здесь предполагается, что C-функция также называется radius.) Вычисление площади запрограммируем на SPL:

Аналогично можно определить, а затем зарегистрировать функцию, возвращающую размер объекта-многоугольника:

В данном случае тело функции можно записать в виде выражения

с учетом того, что во всех реальных случаях параметры, имеющие скрытую структуру, передаются по ссылке.
Методы, определяемые для нового типа, могут иметь те же имена, что и встроенные функции, операторы и агрегирующие функции INFORMIX-Universal Server. После того, как подобный метод написан и зарегистрирован, естественно считать, что область определения стандартных средств сервера СУБД распространяются и на тип со скрытой структурой. В качестве примера можно реализовать над типом circle операции отношения (<, ≤, ...), используя сравнение радиусов кругов (применяется язык SPL):

Для типа polygon может оказаться целесообразной реализация функций определения перекрытия и вложенности многоугольников, вычисления их площадей и т.п.
Реализация вторичных методов доступа
Чтобы значения типов со скрытой структурой могли индексироваться, необходимо выбрать подходящие вторичные методы доступа и либо расширить существующие классы операторов, либо реализовать новые (см. выше раздел "Расширение классов операторов для вторичных методов доступа").
Если для определяемого типа естественной является линейная упорядоченность, целесообразно воспользоваться обобщенными B-деревьями и классом операторов btree_ops. Пример реализации стратегических функций для этого класса (lessthan, ...) приведен в предыдущем пункте. Вспомогательная функция compare () реализуется аналогичным образом.
Определение столбцов со значениями нового типа и индекса для этого столбца может выглядеть так:

Теперь при обработке SQL-запроса

оптимизатор в принципе может воспользоваться индексом circle_ix.
Многоугольники, вероятно, предпочтительнее индексировать с помощью R-деревьев. Чтобы построение такого индекса стало возможным, следует в первую очередь реализовать и зарегистрировать стратегические и вспомогательные функции класса операторов rtree_ops для нового типа со скрытой структурой:

После того, как эти действия выполнены, можно определять индекс для столбцов, содержащих многоугольники:

Индекс reg_spc_rix может быть использован оптимизатором при обработке запроса

Типы с новыми именами
Типы с новыми именами определяются на основе одного из существующих именованных типов посредством конструкции вида

(Разумеется, после создания необходимо предоставить права на использование нового типа, применив оператор GRANT USAGE; мы, однако, не будем останавливаться на подобных технических деталях.)
Новый тип наследует внутреннее представление и весь набор функций, применимых к старому типу. В то же время, над значениями нового типа можно определять подпрограммы, совпадающие по именам с ранее зарегистрированными, но реализованные по-другому. В частичном изменении поведения обычно и состоит смысл создания типа с новым именем. (Напомним, что INFORMIX-Universal Server не допускает переопределения стандартных подпрограмм, работающих со встроенными типами данных.)
Пусть, например, необходимо изменить способ сравнения целых чисел при построении индекса на основе B-деревьев. Как уже указывалось выше, в разделе "Расширение классов операторов для вторичных методов доступа", для целых чисел нельзя переопределить стандартные функции lessthan, equal и т.п. Можно создать новый класс операторов (так мы поступили в упомянутом разделе), но можно и воспользоваться типом с новым именем my_int, переопределив для него функции сравнения в рамках класса операторов btree_ops:

Как всякая система с сильной типизацией, INFORMIX-Universal Server не допускает перемешивания значений типов с новым и старым именем. Например, нельзя складывать или сравнивать значение типа my_int с обычным целым числом; необходимо явно указывать требуемое преобразование. Так, если мы определили таблицу

то для вставки с указанием значения в первом столбце придется воспользоваться конструкцией вида

Сервер СУБД при обработке оператора CREATE DISTINCT TYPE автоматически определяет две функции преобразования между значениями нового и старого типов. Более точно, он регистрирует лишь два имени, поскольку никаких действий для преобразования выполнять не нужно — представления значений нового и старого типов тождественны.
Приведем еще один пример SQL-оператора, использующего типы с новыми именами:

Следует еще раз отметить, что в INFORMIX-Universal Server аккуратно оформлены технические детали, присущие типизации и объектно-ориентированному подходу.
Структуры данных
INFORMIX-Universal Server поддерживает ряд структур данных (конструкторов типов), позволяющих образовывать составные объекты. Иерархия структур данных представлена на Рис. 4.
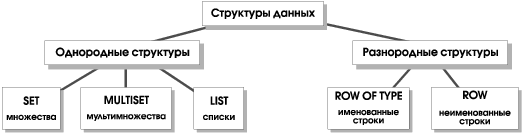
Однородные структуры данных состоят из однотипных элементов, разнородные — вообще говоря, из разнотипных.
Структуры данных могут быть вложенными, то есть в качестве элементов реляционных строк могут выступать множества, списки, другие строки, состоящие в свою очередь из атомарных или структурных значений. Имеются, однако, и некоторые ограничения. Так, элементы однородных структур не могут иметь тип TEXT, BYTE, SERIAL и SERIAL8, а значения элементов не могут быть неопределенными. Кроме того, в описываемой версии размер однородной структуры не может превышать 32 Кб.
В двух следующих разделах мы рассмотрим однородные структуры данных, после чего перейдем к разнородным структурам.
Множества и мультимножества
Множество — это неупорядоченная совокупность различных однотипных элементов. Множества описываются следующим образом:

Конструктор SET может использоваться не только для описания типов, но и для создания значений-множеств, например:

Приведем пример таблицы, в которую входит столбец типа множество. Эта таблица будет содержать сведения о сотрудниках — их имена и множества имен их подчиненных:

Приведем пример извлечения значений-множеств с помощью оператора SELECT:

Множества могут использоваться после предиката IN в конструкции WHERE оператора SELECT. Таким образом определяется, содержит ли множество нужные элементы. Приведем пример запроса, возвращающего имена сотрудников, имеющих подчиненного с фамилией Adams:

К множествам применима SQL-функция CARDINALITY, возвращающая число элементов. Для примера сформулируем запрос, возвращающий имена и число подчиненных тех сотрудников, которые руководят большими подразделениями (с числом служащих более 100):

Можно добавить строку к таблице со столбцами-множествами (добавляются сведения о сотруднике, не имеющем подчиненных):

Значения-множества, хранящиеся в столбцах, могут изменяться следующим образом ("отнимем" подчиненных у тех сотрудников, которые руководят служащими по фамилии Adams):

(В этом примере ключевое слово SET использовано в двух смыслах — как часть SQL-оператора UPDATE и как конструктор типа-множества.)
Наконец, "уволим" сотрудников, в подчинении у которых числится Adams:

Средствами SQL можно осуществлять доступ к значениям-множествам только как к единому целому (впрочем, уже в ближайших версиях это ограничение предполагается снять). Идея доступа к элементам множества средствами SPL и ESQL/C состоит в том, чтобы представить множество в виде производной таблицы, каждая строка которой содержит один элемент множества. Очевидно, любую операцию с множествами можно выразить в терминах реляционных операций над производными таблицами.
Следующий пример содержит описание хост-переменной языка ESQL/C, оператор отведения памяти для этой переменной, а также операторы создания таблицы со столбцом, содержащим множества, и извлечения одного множества в хост-переменную.

(Переменная a_set создается на клиентской стороне, отсюда описатель CLIENT. Описатель COLLECTION применим не только к множествам, но и к мультимножествам и спискам.)
В продолжение приведенного примера продемонстрируем операции с производной таблицей:

Выборка из производной таблицы ведется здесь с помощью курсора set_curs.
Мультимножества отличаются от множеств тем, что элементы в них могут совпадать.
Приведем пример добавления элемента к мультимножеству, извлеченному из таблицы.

Списки
Списки являются упорядоченными наборами элементов, занумерованных, начиная с 1.
Поскольку в работе со списками и множествами больше сходства, чем различий, в данном разделе мы ограничимся серией небольших примеров на языке хранимых процедур SPL.
Рассмотрим таблицу, в которой для каждой сотни будут храниться принадлежащие этой сотне простые числа и пары простых чисел-близнецов (отличающихся на 2). Структуру такой таблицы можно определить следующим образом:

Если предположить, что таблица уже заполнена, то извлечь простые числа, лежащие в пределах от 100 до 200, можно следующим образом:

Чтобы вставить элемент в определенную позицию списка, следует использовать конструкцию AT оператора INSERT. Если предположить, что по каким-либо причинам простое число 103 оказалось пропущенным, его можно поместить во вторую позицию списка посредством оператора

Если конструкция AT опущена, вставка производится в конец списка. Того же эффекта можно добиться, если производить вставку за последним элементом.
Напишем хранимую процедуру, добавляющую в конец списка простых чисел-близнецов, располагающегося в определенной строке, заданную пару-параметр.

Таковы возможности INFORMIX-Universal Server по работе с однородными структурами данных — множествами, мультимножествами и списками.
Реляционные строки
В INFORMIX-Universal Server структурные типы — реляционные строки (далее называемые просто строками) подразделяются на именованные и неименованные. Неименованные строковые типы могут использоваться только при описании других строк и таблиц. Именованные строковые типы разрешается использовать везде, где синтаксически допустимо имя типа; им мы и уделим основное внимание.
Реляционные строки аналогичны строкам реляционных таблиц (отсюда и название этой структуры данных), а их поля соответствуют элементам столбцов, с той, однако, разницей, что на поля не могут быть наложены ограничения, допустимые для столбцов.
При определении строкового типа задаются имена, а также типы полей, которые могут быть любыми, кроме SERIAL и SERIAL8 (некоторые ограничения накладываются также на употребление типов TEXT и BYTE).
Описание именованного строкового типа выглядит следующим образом:

После того, как строковый тип определен, с его помощью можно задавать тип столбцов таблицы:

(В таблице emp_info хранятся имена работников и сведения об их зарплате.)
Напишем процедуру на языке SPL, изменяющую в заданной пропорции базовую часть зарплаты заданного работника.

Мы видим (см. оператор LET), что для доступа к полям реляционных строк используется традиционная точечная нотация.
Средствами SQL можно выполнять проекцию отдельных полей реляционных строк, входящих в столбцы таблиц, например:

С помощью строкового типа можно определить типизированную реляционную таблицу:

При описании строкового типа создается лишь шаблон соответствующих объектов. Фактическое создание этих объектов с отведением под них памяти происходит при наполнении реляционной таблицы, например:

(напомним, что конструкция "::тип" означает приведение к заданному типу.) Попутно мы познакомились с конструктором строковых значений — ROW.
Приведем пример описания неименованного строкового типа, использованного в определении столбца следующей таблицы:

Структуры данных могут быть вложенными, как показывает следующий пример.

В следующем разделе будет рассмотрен весьма важный аспект объектно-ориентированной работы с реляционными строками и таблицами в INFORMIX-Universal Server. Имеется в виду механизм наследования.
Наследование
Наследование, наряду с инкапсуляцией и полиморфизмом, принадлежит к числу важнейших атрибутов объектно-ориентированного подхода. В INFORMIX-Universal Server механизм наследования может применяться к типам (более точно — к именованным реляционным строкам) и таблицам. Тип или таблицу, полученные путем наследования, мы будет называть преемниками; их "предки" будут именоваться предшественниками.
В INFORMIX-Universal Server поддерживается только одиночное наследование, то есть число предшественников не может быть больше единицы; на число преемников не накладывается каких-либо ограничений. Это означает, что типы или таблицы, полученные путем наследования, в общем случае образуют дерево. Пример такого дерева изображен на Рис. 5.
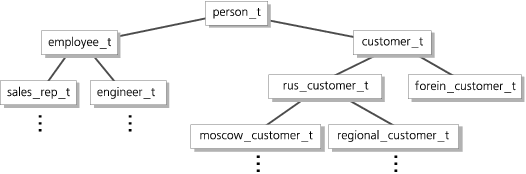
Наследование типов
В данном разделе, чтобы не усложнять изложение, мы рассмотрим серию примеров, в которых на каждом из уровней преемник будет только один.
Пусть определен следующий именованный строковый тип, описывающий людей:

Образуем тип-преемник, значения которого описывают работников:

В записях о работниках, помимо имени, даты рождения и адреса, унаследованных от типа person_t, будут храниться сведения о зарплате и имени руководителя.
Образуем теперь тип-преемник второго уровня, описывающий торговых представителей:

Значения типа sales_rep_t содержат девять полей — пять унаследованных и четыре собственных, явно заданных в описании типа. Получившаяся иерархия наследования показана на Рис. 6.
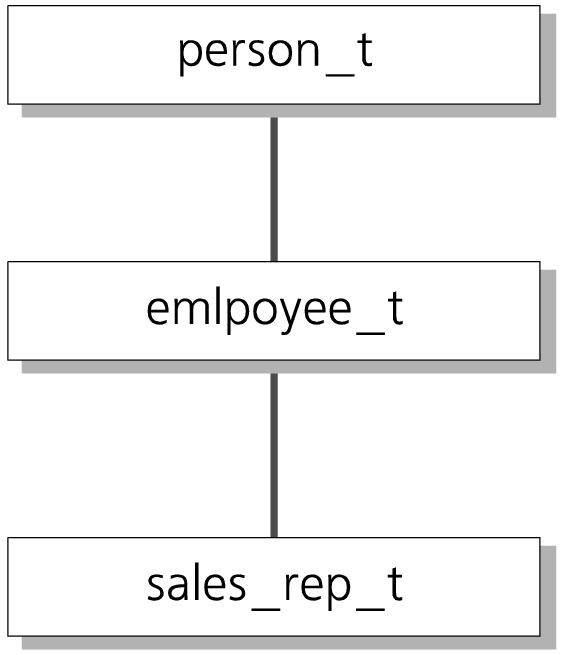
Все методы (процедуры, функции, операторы), определенные для типа-предшественника, автоматически распространяются и на преемников. В данном случае это означает, что методы типа person_t применимы к значениям типов employee_t и sales_rep_t. Аналогично, методы типа employee_t применимы к sales_rep_t. В то же время, для типов-преемников могут определяться свои методы, как новые, дополняющие функциональность, так и модифицированные, изменяющие функциональность, унаследованную от предшественника. В последнем случае имеет место перекрытие методов, которое необходимо отличать от перегрузки. Перегрузка расширяет область определения метода; перекрытие изменяет его на части области определения.
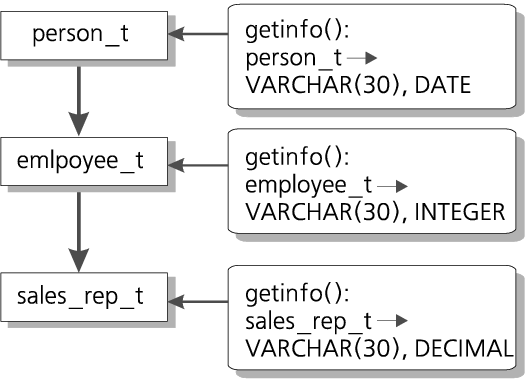
В качестве примера напишем на языке хранимых процедур SPL функцию get_info, возвращающую основные сведения о людях:

Функция get_info применима также к работникам и торговым представителям, однако мы можем реализовать для них специфические, модифицированные методы, например:

Эта функция применима и к работникам, и к торговым представителям, но не применима к значениям типа person_t. Пойдем в специализации еще дальше:

Эта функция применима только к значениям sales_rep_t. Таким образом, каждый тип в нашей иерархии наследования имеет специфический метод get_info (см. Рис. 7).
Перегруженные и перекрытые методы должны различаться числом, типами и/или порядком аргументов. Совокупность этих характеристик образует сигнатуру. Чтобы разрешить неоднозначности и определить, какой метод нужно вызывать в каждом конкретном случае, INFORMIX-Universal Server пытается подобрать совпадающую сигнатуру; если это не удается, он анализирует методы типов-предшественников.
Типы-преемники могут использоваться почти везде, где разрешено употребление предшественников. Единственное (и вполне естественное) ограничение возникает при отведении памяти и хранении объектов. Здесь соответствие типов должно быть точным. Например, если столбец таблицы имеет тип employee_t, то храниться в нем могут только значения данного типа, но не sales_rep_t.
Наследование таблиц
Наследование таблиц является развитием концепции наследования типов. В иерархии наследования могут участвовать только типизированные таблицы, типы которых (именованные строковые) образуют параллельную иерархию. Однако, кроме столбцов предшественников, таблицы-преемники наследуют ограничения (первичные ключи, уникальность, ссылочные ограничения), опции хранения, триггеры, индексы и методы доступа.
Предположим, что иерархия наследования типов person_t, employee_t и sales_rep_t уже определена. Образуем в качестве примера параллельную иерархию наследования таблиц (см. Рис. 8):

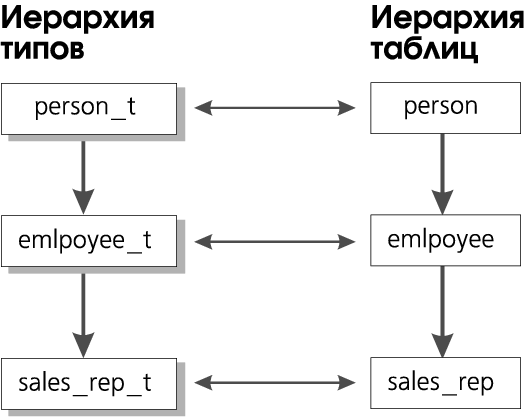
Усложним приведенный пример, включив в него дополнительные характеристики поведения таблиц:

Здесь первичные ключи и фрагментация хранения распространяются на все таблицы, ограничение зарплаты — на таблицы employee и sales_rep, режим блокировки — только на sales_rep.
При описании таблиц-преемников некоторые свойства предшественников могут переопределяться. Если, например, для таблицы со сведениями о работниках нужны свои опции хранения, их можно задать следующим образом:

Эти опции хранения унаследует и таблица sales_rep.
Отношение наследования между таблицами является динамическим в том смысле, что если меняются наследуемые характеристики таблиц-предшественников, это сразу же отражается и на преемниках (как на прямых, так и отделенных несколькими уровнями иерархии). По понятным причинам определения столбцов наследуемых таблиц изменять нельзя, но ограничения, индексы и триггеры — можно.
В INFORMIX-Universal Server запросы SELECT, UPDATE и DELETE, примененные к таблице, входящей в иерархию наследования, распространяются также на всех ее преемников. Например, запрос

вернет все столбцы таблицы person, а также унаследованные от нее столбцы таблиц employee и sales_rep (то есть столбцы name, bdate и address), причем нельзя будет определить, из какой таблицы выбрана та или иная строка результата. Если требуется ограничить запрос ровно одной таблицей, следует употребить конструкцию ONLY:

В этой связи особую осторожность необходимо соблюдать при модификациях и удалениях, например:

Без слова ONLY могут пострадать торговые представители с именем Джон.
Вполне естественно, что идеология "сквозного" прохождения запросов по иерархии наследования распространяется и на построение представлений. Например, в представление

войдут столбцы name из таблиц person, employee и sales_rep. Ключевое слово ONLY и здесь позволяет ограничиться ровно одной таблицей:

Подобные свойства делают наследование таблиц обоюдоострым оружием. Отчасти поэтому осуществить наследование может не всякий — необходимо обладать привилегией UNDER по отношению к соответствующей таблице.
Модули DataBlade
Модуль DataBlade — это функционально законченное расширение сервера СУБД, рассчитанное на определенное приложение или класс приложений.
Строго говоря, с модулями DataBlade не связаны какие-то особые возможности сервера или языковые конструкции. Такие модули строятся из компонентов, описанных выше, то есть из определяемых разработчиком подпрограмм, типов и структур данных, методов доступа и других объектов, хранящихся в базах данных. INFORMIX-Universal Server поддерживает создание и сопровождение модулей DataBlade, предоставляя соответствующий инструментарий — среду разработки, "упаковщик" модулей, утилиту регистрации, прикладной программный интерфейс (см. Рис. 9). Этот инструментарий и будет кратко рассмотрен ниже.
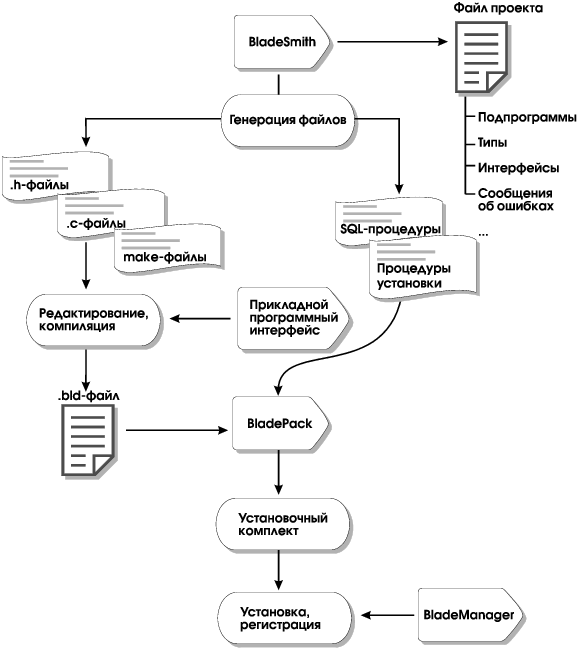
Среда разработки BladeSmith
BladeSmith — это современная среда разработки с графическим интерфейсом. За счет поддержки понятия проекта BladeSmith позволяет трактовать модули DataBlade как единое целое.
В среде BladeSmith можно определить такие объекты, как типы данных, подпрограммы, SQL-тексты, интерфейсы, сообщения об ошибках и др. В частности, интерфейс модуля описывает, какие объекты могут быть использованы извне, и в каких внешних объектах нуждается сам разрабатываемый модуль. В отличие от традиционных языковых сред, интерфейсная информация служит не для редактирования внешних связей, а для контроля целостности при регистрации модуля DataBlade, то есть для проверки того, что в базе данных присутствуют все необходимые компоненты.
Когда определения даны, происходит автоматическая генерация текстов на языках C, SPL, SQL. После этого разработчик может дописать тела C-функций и SPL-процедур, скомпилировать коды и собрать библиотеки. Вообще говоря, уже на этапе разработки целесообразно контактировать со специалистами компании Informix, чтобы учесть установившиеся или намечающиеся стандарты в различных предметных областях, договориться о префиксе в именах определяемых разработчиком объектов и о диапазоне используемых кодов ошибок. Когда модуль DataBlade будет отлажен, его рекомендуется представить в компанию Informix на сертификацию. На наш взгляд, эта процедура выгодна обеим сторонам.
Прикладной программный интерфейс
Программирование модулей DataBlade выполняется с использованием прикладного программного интерфейса и поддерживающих его библиотек и включаемых файлов. Этот интерфейс содержит следующие группы функций:
- манипулирование данными (опрос и установка параметров и переменных окружения, обработка структур данных (в том числе переменной длины), преобразование типов и т.п.);
- обслуживание сеансов, транзакций и потоков;
- обработка запросов (передача SQL-запросов, выдача информации о запросе и его результатах, выборка реляционных строк и их компонентов, обслуживание параметризованных запросов и курсоров);
- выполнение функций;
- управление памятью;
- управление областями для временного хранения результатов;
- реагирование на исключительные ситуации;
- выполнение служебных действий;
- манипулирование интеллектуальными большими объектами (создание, ввод/вывод, перемещение между базой данных и файлами операционной системы, накопление статистики и т.п.);
- поддержка абстрактных типов данных, имеющих несколько представлений;
- управление трассировкой
и некоторые другие.
Создание модулей DataBlade требует от прикладного программиста высокой квалификации буквально во всех аспектах его деятельности — от проектирования интерфейса до организации параллельного исполнения потоков. Ошибки программирования могут вызвать нештатное поведение серверного процесса. В этом смысле использование каждого из модулей DataBlade сопряжено с определенным риском. В то же время, нельзя сказать, что подобный риск является для реляционных СУБД чем-то абсолютно новым или специфичен только для INFORMIX-Universal Server. Там, где есть хранимые процедуры (а они есть во всех реляционных СУБД), вообще говоря, возможны любые сюрпризы. Процедура сертификации, организованная компанией Informix, позволяет свести число этих сюрпризов к минимуму.
Упаковщик BladePack
Упаковщик BladePack предназначен для изготовления установочных комплектов модулей DataBlade и других программных продуктов. Отправной точкой для работы упаковщика являются файлы проектов, сгенерированные с помощью BladeSmith.
Наличие графического представления программного продукта позволяет относительно несложно добавлять к нему новые компоненты и настраивать на конкретное окружение. BladePack способен генерировать установочную shell-процедуру install для Unix-платформ и программу setup для среды Windows NT.
В BladePack можно определить несколько разновидностей установочных комплектов (минимальная, типичная, максимальная, настраиваемая и т.п.). В общем, упаковщик берет на себя всю рутинную работу и позволяет ничего не забыть (или потом легко добавить забытое).
Утилита регистрации Blade Manager
Утилита Blade Manager предназначена для регистрации в базе данных новых модулей DataBlade. Такая регистрация делает доступной для пользователей функциональность, реализуемую модулем.
Помимо регистрации, Blade Manager позволяет получить информацию о регистрируемых и зарегистрированных модулях, аннулировать регистрацию модулей, ставших ненужными, установить клиентские файлы, необходимые для поддержки модулей DataBlade.
В принципе, регистрация модуля сводится к регистрации его компонентов посредством SQL-операторов CREATE TYPE, CREATE CAST, CREATE FUNCTION и т.д., содержащихся в файлах, сгенерированных на предыдущих этапах. Тем не менее, удобно иметь графическую среду, обладающую определенным интеллектом и проверяющую наличие всех необходимых внутренних и внешних объектов.
Доступные модули DataBlade
На момент написания статьи существовало 29 сертифицированных модулей DataBlade, расширяющих функциональность сервера СУБД для следующих предметных областей:
- хранилища данных;
- мультимедиа;
- финансовые приложения;
- геоинформационные системы;
- управление текстами и документами;
- WWW и электронная коммерция.
Мы попытаемся предельно кратко охарактеризовать по одному модулю для каждой из перечисленных областей.
Модуль OptiLink компании Consistency Point Technologies позволяет организовать работу с архивом оптических носителей средствами SQL. Пользователю не нужно заботиться о том, где располагается необходимая ему информация. Суммарный размер архива может составлять несколько терабайт при сохранении высокой скорости доступа, что практически обеспечивает оперативный доступ.
Модуль FaceRecognition компании Excalibur Technologies Corporation предназначен для организации базы данных с изображениями человеческих лиц, что может быть полезным правоохранительным органам, рекламным агентствам и т.д. Модуль дает возможность выделить основные особенности лица — его размер и форму, а также размер и форму глаз, носа и рта и их относительное расположение. На основании этой информации строится индекс изображений, позволяющий эффективно искать лица по заданным характеристикам.
Для финансовых приложений очень важен анализ динамики процессов. Модуль TimeSeries компании Informix содержит определение новых типов данных — временного ряда и календаря. Он предоставляет также более сорока функций для обработки данных, содержащих временные метки.
Модуль Geocoding компании MapInfo Corporation позволяет интегрировать традиционную и картографическую информацию в рамках одной базы данных, эффективно реализовать на серверной стороне обслуживание запросов по географическим атрибутам при сохранении традиционных для реляционных СУБД простоты обновления данных и удобства пользовательского интерфейса.
Модуль Document Objects — совместная разработка компаний Informix и ArborText — решает актуальные задачи эффективного поиска и многократного использования документационной информации, отображения различными средствами (печать на бумажных носителях, вывод на Web-страницы и т.п.) при сохранении единства информационного источника, быстрого определения новых документов на основе накопленных знаний. Помимо механизма модулей DataBlade, успеху разработки способствовало применение стандартного обобщенного языка разметки (SGML).
Модуль Web компании Informix позволяет создавать Web-приложения, способные строить HTML-документы, включающие в себя информацию, динамически извлекаемую из базы данных. Программирование таких приложений ведется не на основе механизма CGI-процедур, а с помощью создания Web-страниц, содержащих специальные тэги и функции. Генерацию SQL-запросов и форматирование результатов берет на себя модуль Web. Таким образом, этот модуль одновременно играет роль среды разработки и моста к INFORMIX-Universal Server.
Заключение
INFORMIX-Universal Server версии 9 представляет собой новое поколение СУБД, которые принято называть объектно-реляционными. Возможно, точнее было бы переставить эти слова, поскольку в данном случае реляционное начало, несомненно, доминирует. Это очень важно, поскольку реляционные СУБД стали привычными и для разработчиков, и для пользователей, в них вложены огромные средства и "революционный" переход к чисто объектным базам, конечно же, нельзя считать приемлемым.
Новые возможности INFORMIX-Universal Server органично расширяют стандартные средства реляционных СУБД, не отнимая традиционных достоинств — непроцедурное задание запросов, их оптимизация и распараллеливание, разграничение доступа, управление транзакциями, резервное копирование, репликация данных и т.п. Подобная органичность базируется на продуманной архитектуре сервера СУБД, изначально рассчитанной на глубокую параметризацию и настройку.
На наш взгляд, специалистам Informix удалось всесторонне продумать процедуру разработки модулей DataBlade, включая технические, организационные и маркетинговые аспекты. Сообщество фирм-разработчиков во главе с компанией Informix способно очень быстро наращивать количество доступных высококачественных модулей DataBlade, по существу расширяя функциональность сервера СУБД до сервера приложений при сохранении такого важнейшего достоинства, как эффективность.
У INFORMIX-Universal Server версии 9.1 остался значительный потенциал для развития. В нее вошли далеко не все возможности, присутствовавшие в объектно-реляционной СУБД компании Illustra и допускающие естественное встраивание в сервер компании Informix. Несомненно, уже следующая версия порадует новыми продвижениями по пути интеграции реляционных и объектно-ориентированных средств.

