 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Каким компаниям нужен проактивный мониторинг сети?
Чем проприетарные системы мониторинга отличаются от решений open source?
Как выбрать решение?
От самописных систем мониторинга к проактивному подходу
Потребность в мониторинге корпоративной сети возникает с момента, когда в ней начинают работать больше одного компьютера. 20 лет назад все обходились пингованием узлов. С его помощью специалисты узнавали о доступности хостов, времени задержки и размерах передаваемых пакетов. Но сети постоянно росли, количество узлов увеличивалось, и пингования стало недостаточно для полноценного мониторинга сети.
Задачи ИТ-подразделений в компаниях стали расширяться. Появилась потребность не просто узнать, что узел находится в сети или что он отвечает на запросы, нужно было понимать, через сколько узлов проходит запрос, что влияет на скорость ответа и в каком месте возникают проблемы. Также было необходимо собирать информацию о настройках и маршрутах со всех устройств в сети и предоставлять данные в удобочитаемом графическом виде или в формате дашбордов. ИТ-специалисты начали создавать первые самописные системы мониторинга сетей, которые со временем становились все более сложными и продвинутыми (многие из этих разработок стали полноценными коммерческими продуктами).
Чуть позже на рынке появились продукты open source — например, популярные до сих пор Nagios или Zabbix. Следом подтянулись вендоры с собственными решениями: Juniper, Cisco, Huawei, Extreme Networks и др.
Главный плюс проприетарных продуктов в том, что они закрывают задачу под ключ — это не наборы «Собери сам». Вам не нужно руками добавлять оборудование, писать конфигурации, править сетевые схемы и настраивать все параметры для отображения, как в случае с решениями open source. Проблема открытого исходного кода — это зачастую отсутствие развития продукта, устаревшие интерфейсы и довольно скромный функционал, а также отсутствие системы резервирования. Проприетарные решения позволяют собирать намного больше информации с устройств и дают возможность не только мониторинга, но и полного управления системой, чего не может обеспечить open source. Но есть и минусы: они прилично стоят, и решение от конкретного производителя полноценно мониторит только его оборудование, а по остальному «железу» дает лишь общее представление. Если в рекламном проспекте написано обратное, это как минимум преувеличение. Да, система может отслеживать работоспособность и собирать минимальный набор конфигураций с чужого «железа», но глубоких настроек и детальной информации о работе сети вы не получите, как и возможности увидеть целостную картину ее состояния.
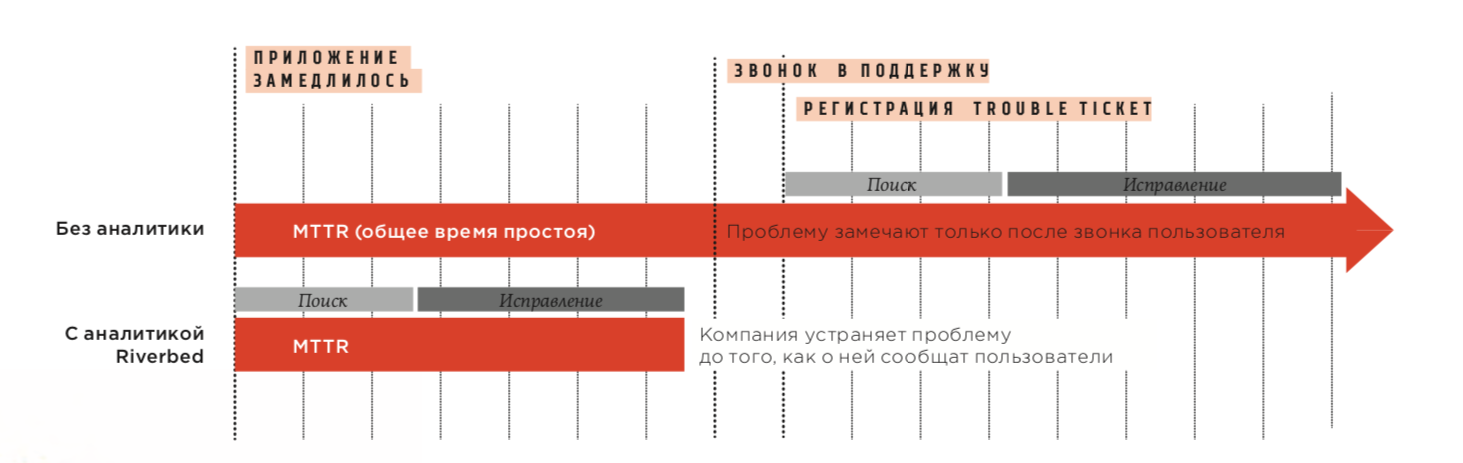
Сегодня следить за сетевым оборудованием уже недостаточно — проблемы могут возникать как в каналах связи, так и в соединениях между серверами и базами данных или даже устройствами конечных пользователей. Допустим, после внедрения системы виртуальных рабочих столов (VDI) пользователи начинают жаловаться на тормозящий интерфейс. Если оборудование и софт в порядке, понять причину поможет система проактивного мониторинга. Она соберет не только информацию по протоколу SNMP, но и данные с коллекторов Netflow, с агентов, установленных у конечных пользователей, метрики пакетов. Затем решение агрегирует все в едином портале (например, SteelCentral от компании Riverbed) и покажет, что происходит не только внутри каналов или приложений, но и у пользователей, а также какие приложения или события в сети, на серверах или в ПО привели к появлению задержек. Система предложит варианты решений и в будущем будет заранее сигнализировать о возможных признаках критичных изменений.
В системах проактивного мониторинга есть функционал ретроспективной и предиктивной аналитики, что позволяет находить проблемы до того, как на них пожалуется пользователь. Также с их помощью можно проводить всеобъемлющую аналитику — смотреть, что происходило с сетью, в каком месте появилась проблема, как решались инциденты, какие действия привели к необходимому результату.
В проактивном мониторинге используются технологии искусственного интеллекта и Big Data. К примеру, решение HPE Aruba Mobility Master (Aruba MM) собирает информацию о сети Wi-Fi, а затем автоматически настраивает ее так, чтобы каждый пользователь получал максимум скорости. SteelCentral от Riverbed собирает данные от систем коллекторов и позволяет понять зависимости, определить производительность и мгновенно разобраться в каждом инциденте.
На заметку
Даже если вы узнали о проблеме в сети спустя какое-то время, ретроспективная аналитика позволит найти ее источник. Стандартная система мониторинга не справится с подобной задачей.
Отраслевая специфика
Любому enterprise-бизнесу нужно анализировать свою сеть. Недавно мы развернули в крупной промышленной компании уже упомянутое Aruba MM со встроенной технологией Micro DPI и в первый же месяц отловили целую кучу ботнетов. Сейчас предприятия чаще атакуют изнутри, проактивный мониторинг позволяет оперативно анализировать трафик и своевременно закрывать уязвимости.
В России подобными системами в основном пользуются банки. Они уже более пяти лет осваивают эти решения и сейчас находятся на одном уровне с западными компаниями. Следом идут крупные страховые организации, а вот промышленность и ритейл сильно отстают.
Если несколько часов простоя сети не критичны для вашего бизнеса, скорее всего, сейчас вам не нужна система проактивного мониторинга. Например, для офлайнового ритейла временное выпадение нескольких магазинов из сети — не такая уж серьезная проблема. Задержки при торговле офлайн не так заметны: данные о ценах и складских остатках чаще всего передаются раз в день или в несколько дней. Но ситуация кардинально изменится, если час простоя для них будет стоить столько же, сколько он сегодня стоит для банков. Для последних суммы измеряются в миллионах долларов, причем для топ-10 — в десятках и даже сотнях миллионов.
Без квалифицированных специалистов вы будете использовать только 30–40% возможностей проактивного мониторинга. Поскольку финансовые организации по очевидным причинам не пускают к себе сторонних сетевых инженеров, мы рекомендуем им отправлять сотрудников на соответствующее обучение или привлекать в штат специалистов с опытом внедрения систем мониторинга. Эти вложения однозначно окупаются.
На заметку
Каким компаниям нужны системы проактивного мониторинга (по мере убывания потребности)
- Банки (топ-50)
- Страховые компании (топ-30)
- Аэропорты
- Транспорт
- Телеком-операторы
- Энергетика и нефтегазовый сектор
Выбор решения
Если компании нужно просто получать информацию о доступности сетевого оборудования, мы рекомендуем использовать систему мониторинга того вендора, чье «железо» уже установлено. Это может быть система Huawei eSight, Cisco Prime Infrastructure, Extreme Networks Access Control и т.д. При наличии в компании «зоопарка вендоров» (а это типичная ситуация для многих заказчиков) самым верным вариантом будет определить превалирующего производителя, установить и настроить его систему мониторинга, а затем подключить к ней оборудование других вендоров. Таким образом вы сможете контролировать и мониторить большую часть сети из одного места, а по остальным сегментам будете видеть общую информацию о доступности оборудования и его функционировании. Альтернативным вариантом могут быть решения open source, об их плюсах и минусах мы уже рассказывали раньше.
Для решения сложных задач подойдут продвинутые средства мониторинга: Riverbed, VIAVI или NetScout. Они позволяют проводить предиктивную и ретроспективную аналитику, а также собирать информацию со всех сегментов сети, включая приложения и инженерную инфраструктуру.
Продвинутые средства мониторинга также будут полезны, если за ИТ-инфраструктуру отвечают несколько подразделений. Когда в таких компаниях возникает проблема, чаще всего начинается пинг-понг: «Это у вас не работает! Нет, у вас!» Мониторинг поможет этого избежать: вы сможете точно определить, на чьей стороне инцидент, и разобраться с ним раньше, чем его заметят конечные пользователи. Системы типа Riverbed также подойдут для отслеживания состояния сети в региональных или зарубежных филиалах компании.
Продвинутый мониторинг позволяет прогнозировать, как перемены в ИТ-ландшафте скажутся на работоспособности сети. Например, если бизнес решил переехать в новый ЦОД, чтобы срезать косты или внедрить новое ПО, чтобы уменьшить время на тестирование, вы сможете заранее узнать, каких проблем стоит ожидать и как к ним подготовиться.
Кейс #1
Заказчик: Крупное промышленное предприятие с филиальной структурой.
Задача: Мониторинг оборудования сети в масштабах России для решения задач сетевого отдела и отдела информационной безопасности.
Результат: Создана адаптивная сервисная система ИБ для всей группы компаний. Запущен упреждающий мониторинг сети. Система мониторит более 4000 единиц оборудования в пяти регионах. Количество инцидентов ИБ, отслеживаемых в режиме реального времени, выросло в 10 раз. Работа по внедрению заняла около четырех месяцев.
Кейс #2
Заказчик: Банк из топ-20.
Задача: Запустить контроль метрик баз данных SQL, меток приложений, установить их корреляцию с бизнес-процессами в банке. ИТ-служба должна понимать, в какой момент наступает деградация процесса, чтобы принимать оперативные решения. Также нужно было запустить мониторинг мобильных приложений и контроль SLA.
Результат: Отслеживается состояние бизнес-процессов на основании меток приложений, определены их узкие места. Сформирован список мер по предотвращению задержек в бизнес-процессах, оптимизирована работа приложений, выделены цели и участки для улучшений.
Кейс #3
Заказчик: Страховая компания из топ-20.
Задача: Поиск и устранение лагов в работе системы видео-конференц-связи: картинка постоянно «рассыпалась», а звук значительно отставал от нее. Системой пользовался топ-менеджмент компании, что поднимало приоритет задачи до бизнес-критичной. Стоимость потенциального решения проблемы «в лоб» — апгрейда всей сети — составляла около 900 000 долларов, работа по миграции заняла бы около двух месяцев.
Результат: После внедрения системы проактивного мониторинга стало понятно, что проблема сети заключается не в загруженности каналов связи, а в неправильной настройке решения по приоритизации трафика. Также был необходим небольшой апгрейд нескольких узких мест на серверах с виртуальными контроллерами системы видео-конференц-связи. Совокупная стоимость решения составила около 81 000 долларов, ИТ-специалисты компании устранили проблему за 4 дня.



