 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Решение этой задачи уже не является далекой перспективой. Компанией Hitachi Data Systems на ИТ-рынок выпущен программно-аппаратный продукт, открывающий новую категорию решений хранения данных – Networked Storage Controller (NSC). Настоящая публикация представляет его потенциальным заказчикам, раскрывая новые возможности управления уровнями систем хранения данных.
КОРОТКО О ГЛАВНОМ
С каждым днем предприятиям требуется хранить все больший объем информации – и больше различных типов информации – в течение более длительных периодов времени. При этом необходимо обеспечить сохранность этой информации как в краткосрочной перспективе – для быстрого восстановления, так и в долгосрочной перспективе – для совершенствования процесса управления компанией (для принятия управленческих решений). ИТ-менеджерам нужны новые решения для хранения данных – и аппаратные, и программные, – которые позволили бы выделять в системах хранения данных взаимодополняющие уровни хранения данных, каждый из которых оптимизирован в соответствии с конкретными специфическими требованиями к производительности, емкости, надежности и стоимости хранения данных.
В ближайшие два года приоритетной целью для производителей систем хранения данных станет воплощение идеи многоуровневых СХД в удобную реальность. Этот процесс потребует дальнейшего развития как аппаратных, так и программных средств, а также стимулирует разработку новых архитектур систем и устройств хранения данных.
Новые решения для создания многоуровневых СХД должны обеспечивать:
- поддержку многочисленных и разнородных (гетерогенных) CХД, которые можно разделять на уровни хранения, соответствующие специфическим требованиям к хранению различных типов данных;
- общие (единые) средства репликации данных, которые позволят перемещать данные между уровнями СХД, приводя в соответствие ценность данных и этап их жизненного цикла с показателями доступности, производительности, безопасности и стоимости уровня хранения;
- масштабируемую виртуализацию, позволяющую управлять ресурсами многоуровневой СХД как одним пулом, который можно разделять между пользователями и/или обслуживать как единое целое;
- возможность деления на логические разделы, что позволит использовать одну систему как несколько отдельных систем, настраивая каждую из них в соответствии с требованиями конкретных приложений или групп пользователей.
Решение, обладающее перечисленными возможностями и потенциально способное изменить устоявшийся рынок CХД, IDC называет сетевым контроллером хранения (Networked Storage Controller – NSC). NSC – это новая категория продуктов на рынке решений для хранения данных, включающая как аппаратные, так и программные компоненты. По мнению IDC, NSC окажет значительное влияние на развитие архитектур хранения данных. Использование NSC позволит расширить возможности интеллектуальных дисковых массивов, обеспечив управление многочисленными прикрепленными (attached) внешними системами хранения данных без ущерба для производительности или надежности.
Первой компанией, разработавшей решение для хранения данных класса NSC, оказалась компания Hitachi Data Systems, которая в сентябре 2004 года объявила о начале поставок TagmaStoreTM Universal Storage Platform (USP). Такие продукты, как TagmaStore USP, помогут ИТ-менеджерам внедрить в масштабе всего предприятия многоуровневое хранение данных, оптимизированное в соответствии с требованиями приложений.
ТЕКУЩЕЕ ПОЛОЖЕНИЕ ДЕЛ
Рост объемов СХД продолжится
Емкость систем хранения данных, которые используются на современных предприятиях, достигает такого уровня, при котором традиционные системы хранения данных перестают соответствовать потребностям организаций с точки зрения гибкости, экономической эффективности и удобства администрирования. Проведя недавно опрос 492 ИТ-менеджеров в средних (1001 000 сотрудников) и крупных (>1 000 сотрудников) американских компаниях, IDC установила, что средняя емкость СХД (исключая системы для настольных компьютеров) в этих организациях составляет 298 ТБ. СХД наиболее крупных компаний, в которых число сотрудников превышает 10 000, имеет еще большие объемы – средняя емкость составляет 578ТБ.
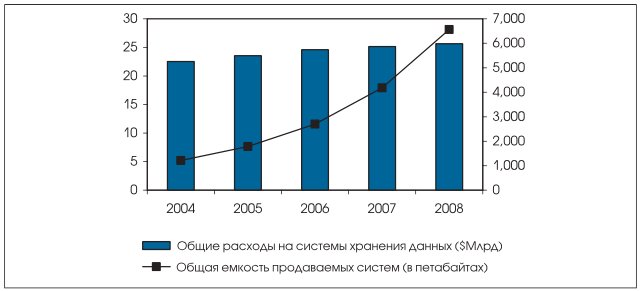
Исследование, проведенное IDC по используемым на предприятиях системам хранения данных, ясно показывает, что в ближайшем будущем потребность компаний в увеличении емкости этих систем продолжит расти (см. Рис. 1). По прогнозу IDC, с 2005 по 2008 год общая емкость систем хранения данных, ежегодно устанавливаемых по всему миру, увеличится на 367%, с 1,786 ПБ до 6,562 ПБ. В то же время, что так же ясно показывает Рис. 1, сумма, которую компании потратят на аппаратное обеспечение дисковых систем, чтобы достичь этой новой емкости, в течение того же периода времени увеличится очень незначительно, с $23,5 млрд до $25,6 млрд.
Таким образом, компании планируют значительно увеличить емкость CХД, но при этом рассчитывают сохранить низкие темпы роста расходов на оборудование СХД и на ИТ-персонал, который устанавливает эти системы и управляет ими. Компаниям нужны системы хранения данных, которые помогли бы им удовлетворить эти требования.
Изменение потребностей компаний приводит к изменению состава хранящейся информации
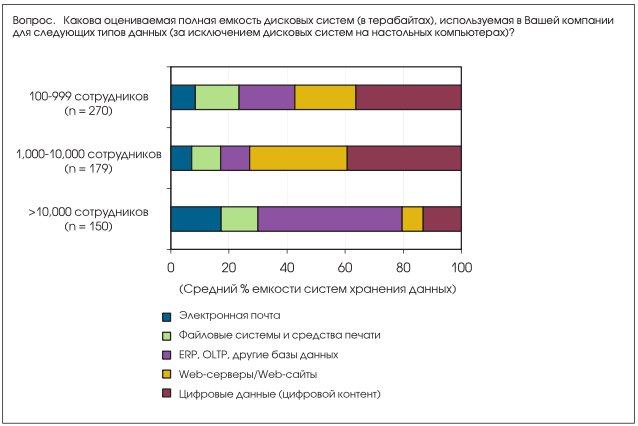
Кроме того, в упомянутом выше исследовании компания IDC попросила ИТ-менеджеров указать те приложения и типы данных, на которые расходуется емкость систем хранения данных на их предприятии. Объем данных и диапазон типов данных, которые стимулируют инвестиции компаний в СХД, сильно различаются независимо от размера компаний (см. Рис. 2). По-
прежнему значительная часть ресурсов СХД выделяется на базы данных и общие файловые сервисы (файловые системы), т.е. на типы приложений, существующие уже в течение десятилетий. Оптимизация систем хранения данных также производится, в основном исходя из специфических требований к производительности именно этих приложений.
С другой стороны, большой интерес вызывает значительная (и быстро растущая) доля дисковой емкости, выделяемая для хранения таких относительно недавно появившихся приложений, как электронная почта, web-серверы и цифровой контент. Чтобы более эффективно удовлетворять потребности клиентов, компаниям сейчас требуется собирать и хранить самые разнообразные данные (например, истории болезней, переписку с клиентами, изображения и видеозаписи).
Эти новые типы информации и являются главным стимулом для наращивания емкости систем хранения данных; однако требования, которые они накладывают на СХД, часто и радикально различаются по таким характеристикам, как цена/производительность, цена/емкость и управляемость. Поддержка новых типов данных и увеличение жизненного цикла всех данных требуют создания СХД, обеспечивающих большую гибкость в управлении данными, настройке показателей производительности и оптимизации стоимости хранения.
Непрерывность бизнеса: необходимо гарантировать доступность всех типов данных
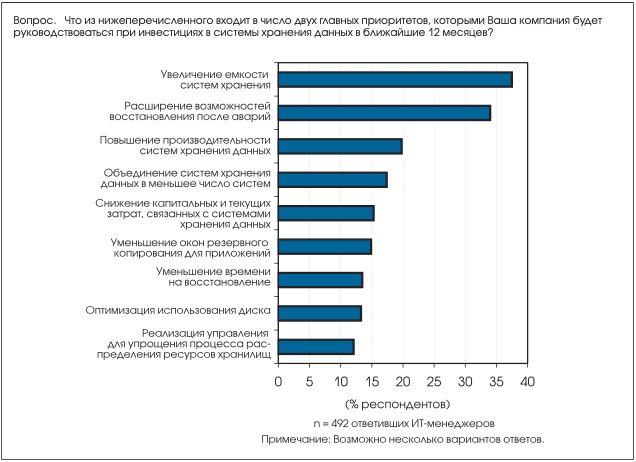
В том же исследовании IDC попросила компании выделить два главных приоритета, которых они будут придерживаться при инвестициях в СХД в текущем году (см. Рис. 3). Только два элемента были указаны в качестве главного приоритета более чем 30% из 492 ИТ-менеджеров: увеличение емкости систем хранения данных (37%) и расширение возможностей восстановления после аварий (32%). Кроме того, в значительном количестве ответов упоминались и другие проблемы защиты данных: уменьшение времени восстановления (14 %) и уменьшение окон резервного копирования (интервалов времени, отведенных для подготовки резервной копии) для критически важных приложений (14%).
Традиционные СХД долгое время играли значительную роль при обеспечении непрерывности бизнеса. Однако существенное изменение потребностей предприятий сводит на нет применение традиционных СХД для этих целей, из-за недостаточной производительности и ограниченных возможностей администрирования. Необходимы новые системы хранения данных, которые позволят экономически эффективно обеспечивать защиту более широких диапазонов информации.
ПЕРСПЕКТИВЫ НА БУДУЩЕЕ
Функциональность, необходимая для создания многоуровневых СХД
Описанное ранее изменение требований к функционалу СХД находит отражение в изменении запросов, адресуемых предприятиями к поставщикам систем хранения данных. ИТменеджеры хотят получить решения, которые позволят им выделять в сетевой системе хранения данных дополнительные уровни, оптимизированные в соответствии с конкретными требованиями к производительности, емкости, надежности и стоимости хранения.
Создание таких решений станет приоритетным направлением работы производителей систем хранения данных на ближайшее время. Этот процесс потребует развития аппаратных и программных средств, а также будет стимулировать разработку новых архитектур хранения данных. Для многих компаний своевременное включение в этот процесс позволит значительно повысить конкурентоспособность.
Что нужно для создания и эффективного использования многоуровневых систем хранения данных?
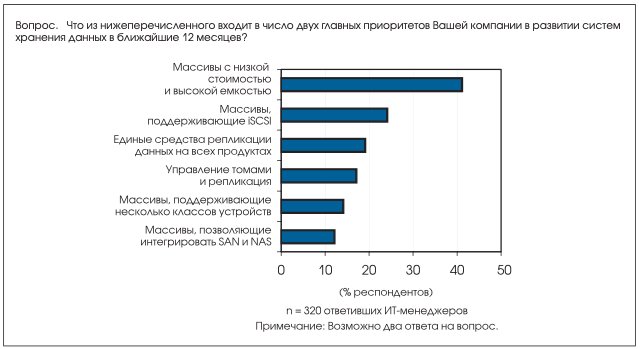
Для этого требуется устройства хранения данных (возможно, от разных производителей), с различными функциональными возможностями и ценой, которые могут быть поделены на уровни хранения данных, отвечающие уникальным и изменяющимся требованиям для размещения разнообразных типов данных. Наиболее часто предприятия заявляют о необходимости дополнить существующий портфель продуктов для хранения данных системами с низкой стоимостью и высокой емкостью. Эта необходимость подтверждается результатами опроса, проведенного IDC среди ИТ-менеджеров (см. Рис. 4).
Также это исследование позволило выявить ряд функциональных возможностей, реализацию которых заказчики ожидают от производителей систем хранения данных. Среди названного отмечены:
- • Единые средства для репликации данных, которые позволят перемещать данные между уровнями СХД, приводя в соответствие ценность данных и этап их жизненного цикла с показателями доступности, производительности, безопасности и стоимости уровня хранения;
- • масштабируемую виртуализацию, позволяющую управлять ресурсами многоуровневой СХД как одним пулом, который можно разделять между пользователями и/или обслуживать как единое целое.
В ходе исследования не задавался вопрос еще об одной важной функции, которая сыграет существенную роль в будущих СХД – логических разделах (logical partition). Логические разделы позволяют распределить ресурсы одного физического устройства хранения данных на несколько виртуальных устройств, каждое из которых можно независимо настраивать для отдельных приложений и/или групп пользователей. Эта стратегия доказала свою эффективность на мэйнфреймах и на крупных UNIXсерверах, поэтому логические разделы должны стать частью любой многоуровневой инфраструктуры хранения данных.
Виртуализация: переход от физического к логическому
Объединяя различные ресурсы хранения данных для их использования многими серверами и приложениями, ИТ-специалисты в первую очередь сталкиваются с необходимостью защитить администраторов серверов и приложений от сложностей, связанных с обслуживанием оборудования, реконфигурацией и управлением ресурсами хранения данных.
Для этого системы хранения данных должны поддерживать уровни логической абстракции (обычно называемой виртуализацией) между физическими портами на данном дисковом массиве, блоками данных на конкретных дисковых группах и логическими томами или файлами, к которым серверы или приложения должны иметь доступ.
В частности, необходимо разработать следующие сервисы виртуализации:
- Виртуализация подключения к SAN. Так как к дисковому массиву через SAN получают доступ несколько (иногда десятки) серверов, то распределение физических портов массива между ними превращается в обременительную управленческую проблему и становится препятствием для полного использования возможностей СХД. Производители систем хранения данных должны разработать такие продукты, которые позволят создавать несколько виртуальных портов на одном физическом порте Fibre Сhannel, а также управлять этими портами.
- Виртуализация логических дисков и томов. Любая модификация приложения (например, добавление новых серверов, устройств хранения данных или функций) требует выполнения сложного комплекса действий по изменению настроек как на серверах, так и на дисковых массивах. Эти действия могут быть причиной ошибок и простоев, что увеличивает время, необходимое на развертывание и модификацию приложения. Производители систем хранения данных должны разработать надежные сервисы управления логическими дисками (LUN) и томами для распространения расширенных сервисов управления информацией и хранением данных на модульные системы хранения данных, поддерживающие различные типы дисков.
Помимо этих основных сервисов, необходимо создать соответствующее аппаратное обеспечение с производительностью, достаточной для значительного повышения масштабируемости и гибкости решений по виртуализации без ущерба для доступности данных или без увеличения расходов на управление СХД.
Единые средства репликации данных: согласованное перемещение и восстановление данных
Репликация данных (внутри одной системы и между двумя и более системами) является той важной функцией СХД, для которой необходимо как можно быстрее преодолеть ограничения, имеющиеся в существующих системах хранения данных. На настоящий момент решения по копированию данных, например такие, как моментальные снимки данных (snapshot) для резервного копирования в автономном режиме, часто функционируют только на каком-либо одном семействе дисковых массивов.
Удаленное копирование на другую систему хранения данных, хотя и возможно в случае установки необходимого программного обеспечения на каждой из систем, но обычно функционирует только на однородных (часто очень дорогих) системах, что вынуждает ИТ-менеджеров создавать островки из недоиспользованных систем хранения данных. Все это разнообразие приводит к росту затрат на администрирование и сокращает возможности взаимодействия.
Сочетание репликации данных с виртуализацией управления томами позволит существенно усовершенствовать механизмы перемещения, защиты и восстановления данных. Благодаря этому можно более эффективно использовать уже существующие системы в качестве вторичных систем хранения данных, например для быстрого локального восстановления или для долгосрочного хранения не изменяющихся данных.
Еще более важно, что это дает возможность установить согласованные политики копирования и восстановления данных на всех системах хранения. Такая согласованность позволит сократить управленческие расходы и одновременно значительно улучшит защиту данных для всех типов корпоративной информации.
Производители СХД должны разработать решения, поддерживающие:
- широкий спектр функций репликации для производимых ими же продуктов;
- функции репликации для множества других платформ, чтобы предприятия могли реализовывать решения, наилучшим образом соответствующие их потребностям.
Логическое разбиение: настройка систем хранения данных под динамические требования
Третьей важной функцией, на которую пока обращают мало внимания, но которая в конечном счете станет основой для любой эффективной многоуровневой СХД, является возможность создания логических разделов. Логические разделы, первоначально разработанные для мэйнфреймов и доступные сегодня на крупных Unixсерверах, обеспечивают возможность динамического и легко настраиваемого выделения вычислительных ресурсов для нескольких различных прикладных задач. Они позволяют максимально использовать ресурсы, по-прежнему гарантируя, что во время пиковых нагрузок критически важные приложения получат всю необходимую им вычислительную мощность.
Усложнение технологий многоуровневого хранения данных, так же как потребность в виртуализации и единых средствах репликации данных, превращают наличие логических разделов в обязательную функцию для будущих поколений систем хранения данных. Разбиение на логические разделы должно включать:
- Логические и физические SAN-порты (например, установка различных уровней пропускной способности для отдельных виртуальных портов на основании фактических требований сервера/приложения).
- Кэш-память (например, выделение кэш-памяти устройства хранения (storage cache) в зависимости от интенсивности процесса чтения/записи для каждого логического диска).
- Распределение процессорной мощности для отдельных логических дисков (LUN) или томов (например, динамическое выделение различной вычислительной мощности в зависимости от времени дня или календарной даты).
Таким образом, поставщики аппаратных и программных средств для хранения данных должны разработать такие технологии создания логических разделов, которые обеспечат динамическое выделение любых ресурсов хранения данных.
Средства для построения многоуровневой СХД – возможные варианты
Реализация новых функциональных возможностей (расширенные возможности виртуализации, единые средства репликации данных и разбиение на динамические логические разделы) для создания многоуровневых СХД требует роста доли инвестиций в программное обеспечение по сравнению с традиционными системами хранения данных, особенно в средства управления гетерогенной средой хранения данных. И действительно, в течение последних двух лет все основные производители систем хранения данных значительно увеличили объем своих инвестиций в разработку программного обеспечения и в приобретение дополнительных программных продуктов у сторонних разработчиков.
Однако такой акцент на разработке программного обеспечения приводит к игнорированию другой, не менее важной проблемы. Размах планов по внедрению многоуровневых СХД остро ставит перед поставщиками этих систем задачу разработки новых аппаратных платформ, поддерживающих упомянутые дополнительные программные функции. При этом, как и при любой эффективной разработке аппаратного обеспечения, разработчики пытаются удовлетворить множеству критериев, чтобы создать оптимальные решения для конкретных групп клиентов. В случае многоуровневых систем хранения данных наиболее важными критериями являются доступность данных, масштабируемость производительности, модульность системы, простота интеграции программного обеспечения, возможность взаимодействия с другими устройствами хранения данных и (как всегда) общая стоимость.
Рассмотрим подробнее различные подходы производителей систем хранения данных и их партнеров к разработке нового поколения аппаратной платформы для многоуровневой СХД. Эти методы отражают сегментацию, которую IDC использует в настоящее время при исследовании решений для многоуровневого хранения данных. Выбор наилучшей платформы для создания многоуровневой СХД в том или ином случае зависит от нескольких факторов, включая максимальный объем подлежащего контролю пула данных, сложность поддерживаемых приложений и степень необходимости тех или иных функциональных возможностей.
Контроллеры дисковых массивов (array-based): традиционное решение
Использование встроенных контроллеров дисковых массивов в качестве аппаратной платформы для таких сервисов, как виртуализация и репликация, отражает текущий, традиционный подход к обеспечению функционирования дополнительных сервисов хранения данных. Этот метод хорошо работает для небольшого количества устройств хранения данных и ограниченной сложности приложений, использующих эти устройства.
Однако такой способ имеет несколько существенных недостатков, которые заведомо ограничивают сферу его применения небольшими однородными инфраструктурами, а именно:
- Ограниченная масштабируемость. Контролируемая емкость и доступная производительность ограничены возможностями конкретного дискового массива.
- Невозможность распространения на другие системы. Сервисы виртуализации и репликации могут использоваться только в архитектуре «система к системе», что увеличивает сложность и уменьшает возможности применения.
- Недоиспользование ресурсов. Программное обеспечение должно быть установлено на каждой системе, независимо от того, требуется ли это для выполнения основных функциональных задач данной системы.
- Ограниченная способность к взаимодействию. Программное обеспечение обычно является специфическим для разных классов систем; и, за небольшим исключением, одна и та же реализация расширенных сервисов обработки данных не может использоваться на системах разных типов даже от одного и того же производителя, тем более от разных производителей.
Автономные специализированные устройства (appliance): ограниченная масштабируемость ограничивает будущее
Другой подход к реализации платформы для расширенных сервисов хранения данных (виртуализации, репликации данных, миграции данных) – использование автономных специализированных устройств (appliance), размещаемые в сети хранения данных («in-band») между серверами и устройствами хранения данных. Подобные решения поставляются компаниями CNT, FalconStor и HP.
Существует несколько типов автономных устройств:
- стандартные серверы с адаптерами(HBA) Fibre Channel;
- специально сконфигурированные устройства (оптимизированные по производительности и надежности) на базе стандартных процессоров, имеющие большую кэш-память и специализированные (выделенные) FC-соединения;
- устройства или blade-модули на базе интегральных микросхем ASIC со встроенными соединениями Fibre Channel.
Автономные устройства не имеют некоторых недостатков, присущих решениям на базе контроллеров дисковых массивов. Они обеспечивают функционирование дополнительных сервисов для множества различных и разнородных устройств, включая системы от разных поставщиков. Благодаря использованию в автономных устройствах стандартных операционных систем, разработка приложений для них также осуществляется намного быстрее, чем в случае встроенных решений. Однако реализации, основанные только на стандартных серверах, по-прежнему имеют недостаточную производительность.
Основные же ограничения, связанные с этим методом, следующие:
- Недостаточная производительность и масштабируемость в случае больших объемов данных (сотни ТБ). Отметим, что для устранения этого ограничения некоторые поставщики используют кластерные технологии.
- Проблемы с целостностью системы и данных, так как любая потеря соединения между кэшем специализированного устройства и дисковой системой может привести к потере данных.
- Возникновение задержек из-за открытия и перенаправления пакетов данных, а также из-за необходимости актуализации информации о местонахождении логических дисков (LUN) для каждой дисковой системы
- Потенциальные проблемы с безопасностью данных, так как каждый пакет данных открывается для получения информации о маршрутизации, что в результате может отразиться на комплексной (end-to-end) целостности данных.
Интеллектуальные FC-коммутаторы: использование растущих возможностей SAN
Еще один подход к созданию платформы для функционирования дополнительных сервисов хранения данных состоит в использовании растущей производительности и интеллектуальных средств, встроенных в FC-коммутаторы SAN. Как и в случае локальных сетей передачи данных, где интеллектуальные Ethernet-коммутаторы могут управлять маршрутизацией IP-трафика на уровне порта, FC-коммутаторы могут использовать обработку на уровне портов, чтобы быстро выполнить достаточно сложные операции по маршрутизации отдельных блоков информации. К таким операциям относятся: виртуализация логических дисков (LUN), синхронная репликация данных и преобразование данных между несовместимыми сетевыми стандартами (FC-iSCSI шлюзы).
Многие известные производители систем хранения данных и/или программного обеспечения, включая EMC и VERITAS (недавно была приобретена компанией Symantec), стремятся использовать новое поколение FC-коммутаторов от основных поставщиков такого оборудования – Brocade, Cisco, CNT и McDATA.
Использование интеллектуальных FCкоммутаторов требует наличия сервера политик, который бы управлял параметрами политик для отдельных портов и обрабатывал редкие исключительные ситуации. Основная часть программного обеспечения, используемого для установки и управления расширенными сервисами обработки данных, будет размещена на серверах политик.
Очевидно, что для реализации такого подхода требуется наличие постоянных соединений между сервером политик и интеллектуальными FC-коммутаторами. Однако на сегодня не существует стандартных протоколов (проект сейчас рассматривается) для таких соединений; поэтому каждый поставщик программного обеспечения должен разрабатывать отдельные решения для работы с каждым из основных FCкоммутаторов.
Помимо упомянутых выше проблем, для этого метода существует несколько других ограничений:
- Возможность потери данных в случае возникновения сбоя соединения между коммутатором и дисковой системой (хотя в таком случае задержка часто меньше, чем в случае использования специализированных устройств, но, тем не менее, для приложений с большим количеством транзакций проблема остается актуальной).
- Проблемы обеспечения целостности системы защиты данных, задержек из-за открытия и перенаправления пакетов данных и вследствие необходимости постоянной актуализации информации о логических томах (LUN) также актуальны для этого подхода.
- Хотя совокупная производительность и масштабируемость данных решений очень высоки, существующие их варианты имеют ограниченные возможности по настройке отдельных приложений или портов (подобные логическому разбиению); поэтому есть риск не полностью использовать доступную производительность на одних портах, в то время как другие порты будут перегружены.
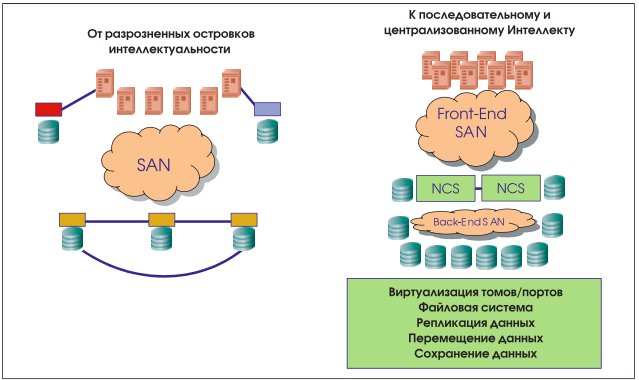
Networked Storage Controllers: платформа нового поколения
Новейшая разработка для создания многоуровневой архитектуры хранения данных – это решение, которое IDC называет сетевым контроллером хранения (networked storage controller (NSC)). Как новый класс решений, способный значительно изменить способы построения систем хранения данных, NSC является важной частью рынка СХД, и IDC внимательно следит за ее развитием.
Эта новая категория продуктов, которая появилась на рынке недавно – в 2004 году. NSC – связующее звено между подключенной к серверам сетью хранения данных (SAN) и всеми дисковыми ресурсами. С его помощью можно расширить многие из возможностей интеллектуальных дисковых массивов, обеспечив управление внешними прикрепленными (attached) системами хранения данных без ущерба для производительности, надежности и безопасности (см. Рис. 5).
Возможность возложить выполнение многих функций по перемещению и управлению данными на NSC обеспечивает большую гибкость при выборе архитектуры решения. Это позволяет при меньших затратах лучше использовать доступную дисковую емкость, быстрее восстанавливать данные и эффективнее осуществлять текущее управление ресурсами хранения. Появляющиеся решения класса NSC должны:
- обладать надежными интегрированными функциями агрегирования портов, управления логическими томами и репликации данных без риска для безопасности данных и без задержек при передаче данных;
- обеспечить гибкие возможности внедрения без ущерба для согласованности и унификации функций;
- быстро и экономически эффективно масштабироваться с минимальным воздействием на текущие операции, в т. ч. обеспечивать возможность логического разделения ресурсов NSC, чтобы удовлетворять меняющимся требованиям;
- эффективно интегрироваться с другими более высокоуровневыми системами управления ресурсами хранения;
- обеспечить сервисы для быстрого и беспрепятственного перемещения данных на существующих и будущих системах хранения.
NSC-решения должны обеспечить выполнение этих требований без ухудшения показателей производительности, без снижения надежности соединений и без усложнения управления, которое может потребовать значительного увеличения персонала.
Решения на основе NSC разрабатываются двумя группами поставщиков. Одна группа состоит из новых компаний, которые разрабатывают свои собственные NSC-системы, а также интеллектуальные приложения, устанавливаемые на них. Основная трудность для этих компаний заключается в обеспечении совместимости со всеми возможными устройствами хранения данных, с которыми им может потребоваться установить связь, и в разработке надежного набора дополнительных сервисов.
Другая группа состоит из поставщиков уже существующих систем хранения данных (таких как Hitachi Data Systems, IBM и Sun Microsystems), разрабатывающих или уже поставляющих NSC-системы в качестве основных компонентов своих решений, относящихся к новому поколению систем хранения данных.
HITACHI DATA SYSTEMS: НОВОЕ ПОКОЛЕНИЕ СИСТЕМ ХРАНЕНИЯ ДАННЫХ
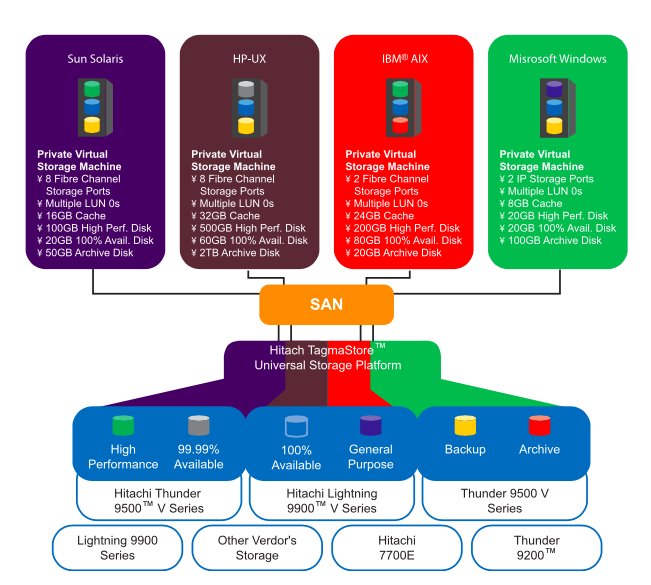
В сентябре 2004 года компания Hitachi Data Systems объявила о выходе универсальной платформы хранения TagmaStoreTM Universal Storage Platform (TagmaStore USP), которая является фундаментом для создания нового поколения решений для многоуровневого хранения данных. TagmaStore USP представляет собой одно из первых решений класса NSC.
Основным аппаратным элементом TagmaStore USP является Hitachi Universal Star NetworkTM – масштабируемый матричный коммутатор третьего поколения с массово-параллельной обработкой (см. врезку «Архитектура TagmaStore USP»). Коммутируемая архитектура позволяет обеспечить высокий уровень модульности и производительности, а также исключительную масштабируемость, вместе с поддержкой виртуализации и управления внутренними и внешними подключаемыми дисковыми ресурсами общей емкостью до 32 ПБ. Она также поддерживает возможность разбиения на логические разделы ресурсов TagmaStore USP – FC-портов, кэш-памяти и как внутренней, так и внешней дисковой емкости.
Вместе с объявлением TagmaStore USP был анонсирован ряд программных продуктов (см. врезку «Программное обеспечение TagmaStore USP»), обеспечивающих функциональность, присущую Network Storage Controller:
- виртуализация ресурсов – ПО Hitachi Universal Volume Manager
- разбиение на логические разделы – ПО Hitachi Virtual Partition Manager
- виртуализация и управление логическими томами – ПО Hitachi Volume Migration
- единое средство репликации данных – ПО Hitachi Universal Replicator.
Архитектура TagmaStore USP
Архитектура TagmaStore USP представляет собой эволюционное развитие архитектуры предшествующих массивов HDS Lightning 9900 и 9900V – третье поколение коммутируемой архитектуры Universal Star Network Crossbar Switch Architecture.
Основой системы является интеллектуальный коммутатор, который состоит из двух отдельных сетей: cache hierarchical star network(C-HSM) и control memory hierarchical star network ( CM-HSN). Первая – сеть передачи данных к/от глобального кэша данных. Вторая сеть – CM-HSNотвечает за обмен управляющей информацией между процессорами и управляющей памятью (Control Memory). Таким образом, поток управляющей информации полностью отделен от потока данных.
Сache hierarchical star network (C-HSM) стоится на основе кэш-коммутаторов, которых в TagmaStore USP может быть до 4. Каждый кэш-коммутатор имеет 16 путей к модулям кэшпамяти 16 путей в сторону процессоров (в два раза больше, чем Lightning 9900 V) и представляет собой специально разработанный перекрестный коммутатор, который функционирует как комбинация мультиплексора, арбитра пути и неблокируемого сетевого коммутатора. Всего 64 пути в процессорную сторону и 64 пути к модулям кэш-памяти поддерживают одновременное выполнение до 128 параллельных операций кэш-памяти.
Сontrol memory hierarchical star network (CM-HSN) имеет более простую структуру – это комбинация соединений точка-точка между модулями управляющей памяти и front-end / back-end director (FED/BED). Управляющая память содержит информацию о статусе, местоположении и конфигурации кэш-памяти, данных в кэш-памяти и конфигурации системы в целом (так же, как и другую информацию, связанную с текущим состоянием системы). Иными словами, управляющая память содержит данные о данных (или метаданные, как их иногда называют) Области управляющей памяти попарно зеркалированы.
C-HSN обеспечивает передачу данных со скоростью 68 Гбайт/с, CM-HSN – со скоростью 13 Гбайт/с. Таким образом, агрегированная производительность коммутатора – 81 Гбайт/с.
Front-End Director (FED) – это устройство, отвечающее за внешние интерфейсы TagmaStore USP и определяющий тип и количество соединений с серверами и мейнфремами или с SAN. TagmaStore USP поддерживает до 6 FED, которые обеспечивают следующие внешние интерфейсы: Fibre Channel, ESCON, FICON и Ethernet. Максимально возможное количество внешних портов – до 192 Fibre Channel, до 48 FICON-портов, до 96-ESCONпортов. Также USP поддерживает до 32 1Gbps Ethernet портов для NAS-устройств с CIFS и NFS протоколами.
Back-End Director (BED) – это устройство, отвечающие за интерфейсы к внутренним дискам и определяющие количество FC-AL петель, идущих к пулу внутренних дисков. TagmaStore USP может иметь от 1 до 4 BED, суммарно поддерживающие 64 2Gbps FC-AL петли.
Сложная задача для HDS: создание нового рынка
В силу своей роли инновационного лидера на формирующемся рынке продуктов NSC, компания Hitachi при развитии первого поколения NSC-решений для своих корпоративных клиентов сталкивается с несколькими проблемами. Деятельность компании должна базироваться на тщательном анализе результатов и смелых новациях, а также на прочном фундаменте сочетания оборудования и программных продуктов с профессиональными услугами высокого уровня.
Усилия компании по созданию средств масштабируемой виртуализации в гетерогенной среде, единых средств репликации данных и управления СХД, реализованных в TagmaStore USP, представляют собой важный первый шаг, который выводит компанию на ведущее место в индустрии систем хранения данных. Однако средства TagmaStore USP для репликации, виртуализации и управления, имеют пока еще ограниченную поддержку унаследованных систем, а также систем хранения от других ведущих поставщиков. Все больше крупных предприятий преднамеренно выбирают разные системы хранения данных, разработанные различными поставщиками, для каждого уровня хранения в своей инфраструктуре. Такие компании не хотят переплачивать за дополнительную дисковую емкость, и в то же время пытаются добиться улучшения взаимодействия систем хранения через SAN. Ведущим поставщикам систем хранения данных (нравится им это или нет) придется принять меры, чтобы учесть подобные настроения их заказчиков.
Для реализации виртуализации HDS использует простой подход. Universal Storage Platform «выглядит» для подключенной внешней системы хранения как сервер Windows NT. HDS полагает, что это позволит быстро включить в список поддерживаемых внешних систем почти все дисковые массивы, доступные на сегодня. В своем анонсе Hitachi объявила, что намеревается обеспечить широкую поддержку неоднородных систем хранения в середине 2005 года. И действительно, в ноябре 2004 года Hitachi объявила о поддержке продуктов IBM ESS, в конце декабря 2004 года – систем хранения EMC Symmetrix и DMX.
Перед HDS и ее конкурентами стоит еще одна важная задача: включить все прежние инструменты и утилиты управления хранением данных в общую инфраструктуру управления. Когда предприятия начнут оценивать возможные варианты решений многоуровневого хранения, им потребуются простые, легко внедряемые решения для управления, которые обеспечат возможность согласованного и автоматизированного администрирования.
HDS уже анонсировала новые версии своих ранее существовавших решений по управлению хранением данных, учитывающие возможности TagmaStore USP и сопутствующего программного обеспечения, но необходимо предпринять дальнейшие шаги, которые позволили бы обеспечить эффективную поддержку многоуровневого хранения данных.
Для более глубокой интеграции необходимо:
- использование согласованных процессов и алгоритмов для выполнения задач, которые затрагивают различные устройства и приложения;
- использование стандартных инструментов для планирования заданий, создания отчетов и обеспечения безопасности;
- обеспечение интегрированной автоматизации и технологического процесса (workflow) на основе заданных политик.
Кроме того, HDS должна обеспечить поддержку существующих процессов управления, сохранив возможность внесения изменений в эти процессы.
Программное обеспечение TagmaStore USP
ПО Hitachi Universal Volume Manager обеспечивает виртуализацию до 32 ПБ внутренней и внешней дисковой памяти.
В качестве внешней памяти в первой версии это программное обеспечение поддерживало дисковые массивы производства HDS Lightning 9900 и 9900V (включая версии, продаваемые HP и Sun), Thunder 9500V, а также более старые системы 7700E. Позже была добавлена поддержка систем хранения IBM ESS и EMC Symmetrix и DMX.
ПО Hitachi Virtual Partition Manager позволяет распределять внутренние и внешние физические ресурсы хранения – включая Fibre Channel порты, кэш и диски – по независимо управляемым виртуальным частным машинам хранения данных (Private Virtual Storage MachinesPVSM).
ПО Hitachi Volume Migration новая версия ПО Hitachi CruiseControl для Universal Storage Platform, которая позволяет автоматизировать перемещение логических томов (LUN) по внутренним и внешним подключаемым системам хранения, облегчая размещение данных по различным уровням хранения.
ПО Hitachi Universal Replicator реализует асинхронную удаленную репликацию, включая репликацию в гетерогенной среде для подключенных внешних систем хранения.
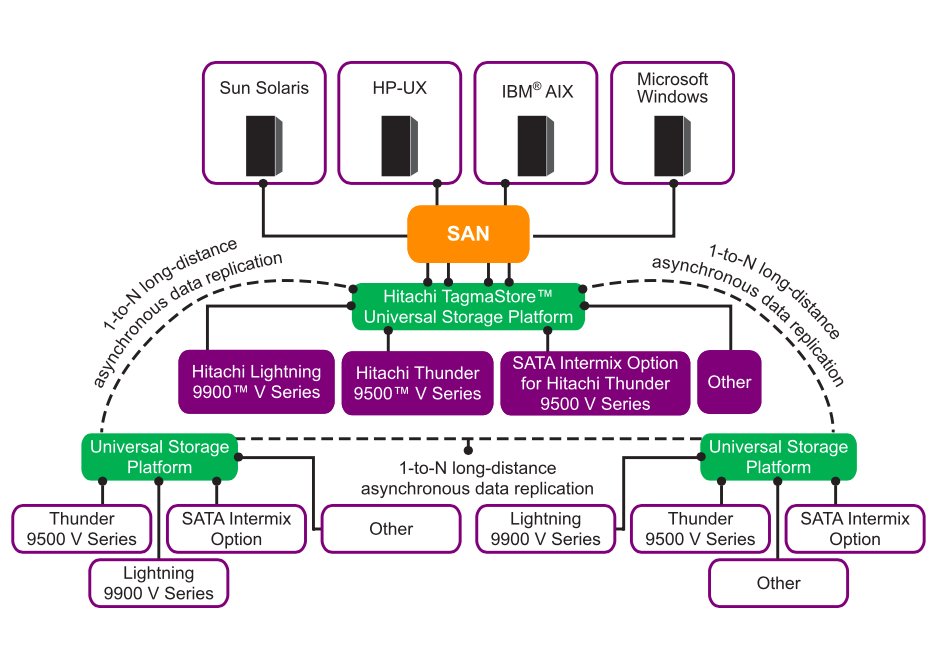
Hitachi Universal Replicator поддерживает такие возможности как ведение журналов на дисках; защиту от сбоя канала; копирование с опросом наличия изменений ("pull" copying) и сценарии обеспечения непрерывности бизнеса для нескольких центров обработки данных (multi-data center operation).
Расширение предложения услуг – ключ к успешной реализации
К сожалению, не приходится ожидать мгновенного появления единственно верного метода построения корпоративной инфраструктуры хранения данных, использующей многоуровневые СХД, единые средства репликации данных и управления в целях повышения эффективности деятельности ИТ-подразделений.
Самое современное и интегрированное решение для хранения данных окажется бесполезным, если ИТ-подразделения не будут применять эффективные методы консолидации систем хранения, переносить данные на новые системы и менять существующие политики и процедуры, чтобы автоматизировать выполнение повторяющихся задач администрирования. Эффективное внедрение, всегда имеющее большое значение, является особенно важной проблемой, когда дело касается таких решений, как системы хранения данных с использованием NSC.
ИТ-менеджеры нуждаются в помощи своих поставщиков, поскольку они устанавливают правила и процедуры для соглашений о назначении имен, модернизации приложений, обслуживания (provisioning) и для определения политик репликации. Любой производитель или поставщик СХД, стремящийся быть конкурентоспособным на этом рынке, должен расширять спектр своих профессиональных услуг, чтобы обеспечить эффективное развертывание решений многоуровневого хранения данных и успешное внедрение существующих и будущих продуктов.

