 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Но часто случается так: компания сталкивается с серьезной проблемой, и традиционная система резервного копирования не позволяет восстановиться за то время, которое в компании считается целевым. По факту SLA, которому должна соответствовать система резервного копирования, не выполняется. Увы, за время своей работы мы накопили множество печальных примеров, подтверждающих это. Ниже мы приведем два кейса и дадим советы, какие технические средства позволят сократить время восстановления. Выбирая кейсы, мы останавливались на примерах, связанных с базами данных, где хранилась наиболее критичная для бизнеса информация.
Человеческий фактор
Заказчик: крупная страховая компания.
Краткое описание причины аварии: ошибка персонала, неправильная установка патча на Oracle.
Описание проблемы:
Речь идет о крупной компании, которая имеет зрелое ИТ-подразделение и вкладывает достаточно средств в его оборудование и персонал. Достаточно сказать, что СУБД Oracle работала на двух Oracle Exadata, распределенных по двум технологическим площадкам, с проработанным DR-решением и настроенной системой резервного копирования.
В один печальный день было принято решение установить патч на СУБД Oracle. К сожалению, инженер не дочитал инструкцию до конца: «Что я, патч не установлю без бумажки?!» — и неправильно сделал это. Ошибку заметили через несколько часов, когда СУБД стала вести себя странно и сообщать об этом в журналах. Тогда инженер принял решение откатиться. Это действие окончательно обездвижило оба экземпляра базы (все изменения успели отреплицироваться на Standby) и испортило все данные.
Компания осталась без своего главного информационного актива — базы данных, через которую работали все бизнес-процессы. Бизнес практически встал.
Решение:
Заказчик принял решение восстанавливаться из резервной копии. В то время восстановление базы в 5 ТБ (сейчас ~15 ТБ) заняло — внимание! — более 30 часов! Итого, через 1,5 дня восстановили базу на день раньше аварии. Но данных-то было больше! Все остальное силами программистов и персонала восстанавливали из других систем компании, из первичной документации (бланков заявлений, копий, сканов). На это ушло еще 1,5 дня напряженной работы.
Итого:
2 High-End системы Oracle Exadata, Oracle Standby, работающая система резервного копирования и 3!!! дня полного простоя при неправильной установке патча. Было ли это допустимо согласно регламенту компании? Конечно же, нет.
Основная проблема: отсутствие средств быстрого восстановления при логических ошибках.
Как можно было избежать:
Для смягчения последствий подобных аварии нужно двигаться в двух направлениях. С одной стороны, делать резервирование чаще, а с другой — иметь возможность быстро восстановиться. Могли бы помочь следующие продукты:
Oracle FlashBack — технология, позволяющая делать не только «накат» новых данных на резервную систему Oracle, но и откат до нужной транзакции. При такой схеме можно было бы откатить систему до начала проблем с патчем, что сильно бы облегчило восстановление данных.
Технология Snapshot. Мгновенные снимки позволяют резервировать и восстанавливать данные за секунды. При этом они слабо влияют на производительность, и есть возможность делать снимки достаточно часто (например, раз в час). Таким образом, можно было откатиться на час назад и восстанавливать только час потерянных данных.
Continuous Data Protection — непрерывная защита данных. Это проприетарные устройства или ПО, позволяющее логировать все записи с возможностью отката на любую точку во времени. Действует аналогично Oracle FlashBack, но для любых данных.
Аппаратный сбой
Заказчик: Федеральная служба в одном из субъектов РФ.
Краткое описание причины аварии: аппаратная ошибка внутри дискового массива.
Описание проблемы:
В этот раз у компании чуть менее развитая ИТ-инфраструктура, зато чаще встречающаяся у наших заказчиков: дисковые массивы среднего уровня, СУБД Oracle, Standby не используется.
Как это часто бывает, в пятницу, когда все уже радостно собирались домой, произошел аппаратный сбой массива. Из-за бага в прошивке при отказе диска массив превратил данные в кашу. От этого перестали работать базы данных сервиса федерального уровня. Более суток заказчик ждал решения от вендора СХД. После анализа всех логов вендор дал свое заключение: данные потеряны!
Решение:
Заказчик принял решение о восстановлении из резервной копии. Этот процесс занял примерно сутки, несмотря на все ухищрения и тюнинг производительности (база довольно большая). Пока восстанавливалась БД, резервная копия логов была утеряна (был выставлен слишком маленький Retention Period, СРК удалила их сама).
Дальше — глубже. Компания, как и многие другие, в некоторые моменты использовала нелогируемые операции в Oracle, что серьезно повышает производительность, но не оставляет шансов восстановиться, кроме как из резервной копии. То есть делать ее надо сразу же после прохождения сессии операций. Естественно, об этом с годами в службе эксплуатации забыли. Таким образом, часть данных была полностью утеряна.
Еще несколько дней потребовалось на полное воссоздание инфраструктурных сервисов — не было резервных копий операционных систем, бинарников, конфигураций и т.п.
Всю потерянную информацию собирали из первичных документов (сторонние базы, бумажные документы, данные на компьютерах операционистов), что заняло еще 3 дня. Некоторые документы, возможно, так и не удалось восстановить.
Итого:
Проблема с массивом вызвала потерю данных и простой около недели! В современных условиях это может привести к банкротству компании.
Основные проблемы:
- СРК была настроена неверно, пробные восстановления не проводили.
- Не было средств оперативного восстановления в случае аварии и дублирующих систем.
- Не было четкого DR-плана.
Как можно было этого избежать:
- Использовать Oracle Standby, расположенный на другом массиве. Это позволило бы в течение непродолжительного времени переключиться на работающий экземпляр данных.
- Oracle ZDLRA позволил бы в гораздо более сжатые сроки восстановить БД на резервном оборудовании.
- Грамотные планирование процессов резервного копирования и восстановление позволили бы избежать таких больших потерь и восстановиться менее чем за сутки.
Вывод. Из вышеприведенных примеров видно, что системы резервного копирования были установлены и настроены, но несмотря на это восстановиться в сроки, указанные в SLA, им и близко не удалось.
Основные проблемы систем резервного копирования
Опираясь на свой опыт, мы решили выделить ряд проблем, на которые, по нашему мнению, читателям стоит обратить особое внимание.
Скорость резервного копирования и последующего восстановления
На данный момент скорость backup прямо пропорциональна объему данных, при этом у всех наших заказчиков годовой рост данных не менее 30%. За 3–4 года данные как минимум удваиваются, но у некоторых компаний этот показатель даже выше, при этом за то же время скорость резервного копирования не меняется вовсе. Здесь можно сделать простой вывод, что те сроки и те SLA, которые были 3–4 года назад актуальны, сейчас нужно увеличивать как минимум вдвое. При этом требования бизнеса к восстановлению данных (RPO/RTO) постоянно растут.
Постепенно происходит перевод всех бизнес-процессов компании в ИТ и отмирание бумажной первички (копии и оригиналы документов, заявления, сканы и т.п.). Все крутится внутри ИТ-систем, и потеря данных — это, по сути, потеря всего. ИТ больше не имеет права на ошибку. В тех кейсах, которые мы привели, все то время, пока данные в силу разных обстоятельств были недоступны, компании не могли функционировать. Это приводило как к прямым потерям, когда невозможно осуществлять основной бизнес-процесс организации, так и к неявным, например, к репутационным, которые не так просто измерить в денежном эквиваленте, но которые в перспективе могут нанести не меньший ущерб компании.
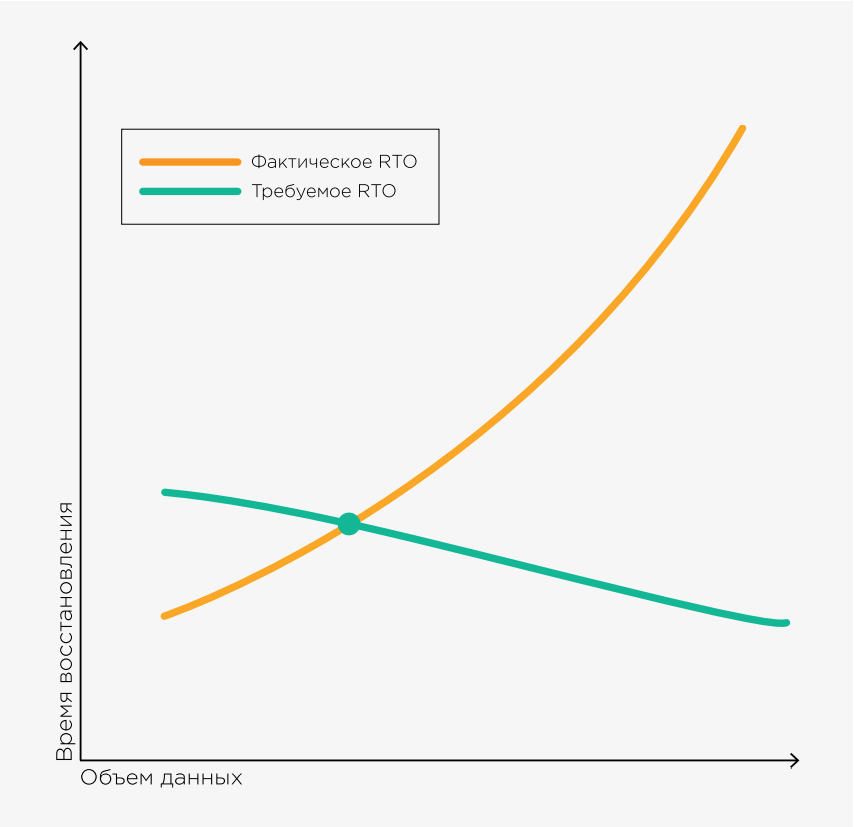
На рисунке я отразил свои наблюдения, касающиеся времени восстановления (RTO). C ростом данных фактическое время восстановления непременно растет, при этом требования SLA только ужесточаются. Точка на графике, где фактическое время равно требуемому, для большинства заказчиков уже пройдена.
Низкая гранулярность восстановления
Фактически большинство ошибок связано с потерей какой-то части данных. При этом традиционные средства резервного копирования позволяют восстанавливать данные напрямую из backup, но чаще приходится восстанавливать систему целиком. Если ваша база данных занимает 15 ТБ, вы потратите на это несколько суток. Заказчиков, у которых требование RTO (Recovery Time Objective) — 2 дня, мы не знаем. В нашей практике таких примеров не было, когда бы клиент сказал: «Ребята, восстанавливаться 2 дня — это нормально, я потерплю», — если администратор случайно удалил несколько строк из базы данных. Довольно частая проблема, с которой сталкиваются наши клиенты: как вычленить небольшой кусочек данных из резервной копии, не восстанавливая ее саму (и не тратить на это несколько суток).
Чрезмерное RPO (Recovery Point Objective)
В мире, где пропала бумажная первичка и все хранится в ИТ-системах, каждую секунду создаются данные, которые хотелось бы сразу защитить, — в тот же момент, когда они были созданы. Но с помощью классических систем резервного копирования это сделать невозможно. Для каждой порции данных есть определенный длительный период времени, в течение которого эти данные существуют во всем мире в единственном экземпляре. Наши заказчики хотят защищать данные непрерывно, с момента их появления. При принятии решения о восстановлении с резервной копии, скорее всего, придется восстановиться на сутки назад, дальше данные за сутки нужно будет еще откуда-то получить. Как правило, это долгая работа администраторов, занимающая несколько дней. При самом негативном развитии событий это может обернуться потерей важнейшей информации. Конечно, вопрос не ограничивается только резервным копированием, он касается построения ИТ-системы в целом, но тема СРК в данном случае очень важна, нельзя ей пренебрегать.
Скрытые ошибки
К сожалению, до сих пор нет вариантов дешево и быстро проверить, насколько качественно сделана резервная копия. Конечно, это можно сделать с помощью периодических тестовых восстановлений, но это очень дорогая операция с точки зрения усилий людей и ИТ-ресурсов. Эта работа отдельной команды на отдельном железе.
Увы, большинство наших клиентов этим не занимается. Часто складывается такая ситуация, что все делают резервные копии, но к моменту восстановления, оказывается, что их можно было не делать — они просто не восстанавливаются, несмотря на внешне правильную работу СРК. Это происходит по различным причинам. И лучше всего это можно продемонстрировать на примере. Один наш заказчик использовал систему SAP с базой данных Oracle. Резервное копирование осуществлялось встроенными средствами SAP с помощью одного из крупнейших вендоров СРК.
Были настроены 2 разные политики резервного копирования: одна из них файловая - копировала данные операционных систем и настройки ПО, а вторая — саму базу данных. Поскольку они были направлены на одну и ту же систему, был настроен список исключений, в который занесли базу данных. Файловая политика учитывала этот список и не резервировала те директории, в которых лежала БД. Из-за особенностей архитектуры СРК, политика резервирования БД игнорировала список исключений и корректно копировала нужные данные.
В одном из релизов ПО данный вендор исправил эту «ошибку», с этого дня обе политики стали учитывать список исключений и обходить базу данных стороной. Причем это никак не отразилось на ошибках в ПО СРК, так как она работала штатно: все данные, не указанные в списке, резервировались нормально. Система рапортовала о своей исправности.
Таким образом, все работало больше полугода. До того момента, пока не понадобилось восстановиться...
Несистемный подход
Немаловажная проблема – несистемный подход к проблеме резервного копирования. СРК исторически строилась силами либо самой компании, либо привлеченного со стороны интегратора. На момент построения она, безусловно, отвечала всем требованиям и выполняла свою функцию целиком и полностью. С течением времени ИТ-ландшафт компании изменялся. При этом система резервного копирования просто подстраивалась под него по мере развития системы, и чаще всего никакой системный подход, который бы учитывал важность соответствия системы изначальным показателям на всех последующих этапах, не соблюдался. Строя СРК у себя в организации, помните — это только часть вашей стратегии по защите данных.
Мы представили несколько кейсов, которые демонстрируют, что подход к защите данных должен быть комплексным. Увы, СРК — это всего лишь резервный парашют, а не серебряная пуля, поэтому приступая к ее созданию, нужно четко представлять, какое место она займет в рамках глобальной стратегии по защите данных.
Чтобы проверить, насколько системно вы подошли к вопросу построения СРК, ответьте на несколько простых вопросов:
- Есть ли у вас выстроенная модель рисков, в рамках которой прописано место СРК?
- От каких сбоев вас защищает СРК?
- Как вы защищаетесь от остальных рисков (это могут быть не просто технические решения, но и другие компенсационные меры)?
- Уверены ли вы в том, что система восстановится в установленные сроки?
- Проверяли ли вы это на практике?
Решение
Опираясь на собственный опыт и опыт наших заказчиков, мы постарались выработать подход, позволяющий решить или существенно уменьшить последствия перечисленных проблем. Суть нашего подхода:
Первое — необходимо отвязать скорость резервного копирования и восстановления от объема системы. Производители систем хранения данных, прикладного ПО и СРК предлагают использовать некоторый инструментарий, применимый для решения этой проблемы. Ниже я опишу самые перспективные из них.
Мгновенные снимки (snapshot), позволяющие производить резервное копирование и восстановление данных за секунды, практически не влияя на производительность. Это делается средствами массива, и при этом может управляться СРК, быть частью ее политики. Такой backup и восстановление реально занимают секунды, что выгодно отличает эту технологию от классических систем с отчуждаемыми носителями.
Другим решением может быть использование различных средств приложений, например, Oracle Standby, DB2 HADR, MS SQL Always On. Все эти средства позволяют иметь работающую копию продуктивной системы, отвязанную от исходной, которую можно развернуть мгновенно. Это позволяет начать работу сразу после сбоев.
Второе — дать возможность восстанавливать только нужные данные. Наш подход учитывает, что при восстановлении части данных нам не требуется копировать всю систему целиком, мы можем восстановить данные, которые нам нужны на данный момент. Это достигается возможностью быстро развернуть либо использовать уже развернутые системы, которые эти данные содержат. Так же как и в первом случае, snapshot позволяют решить эту проблему (можно быстро открыть snapshot на соседний сервер и вытянуть необходимый кусочек данных). Сюда же можно отнести технологии непрерывной защиты данных, например, Oracle Standby с Flashback, решения continuous data protection (CDP). Они позволяют быстро развернуть работающую копию данных на нужный момент времени.
Когда нужно достать один логический блок, например, строку или таблицу БД, эти средства серьезно облегчают задачу, позволяя восстановить необходимый кусочек данных, не восстанавливая всю копию целиком.
Третье — уменьшить промежуток между появлением данных и их защитой. Этого можно достигнуть несколькими методами, опираясь на специфику того или иного конкретного случая и степень важности данных.
Например, для менее критичных систем временной интервал для резервного копирования может быть уменьшен до нескольких часов. В этом случае мы используем мгновенные снимки. Они могут служить точкой восстановления, которую можно делать раз в час. Часть современных массивов достаточно хорошо справляется с этими процессами и может хранить достаточно большое количество снимков систем. Это прекрасный выход из ситуации, когда нужно откатиться на некоторое время назад.
Для наиболее критичных систем временного интервала может не быть совсем – данные нужно защищать непрерывно. Существует несколько решений этого класса, например, Oracle Standby с FlashBack, который позволяет откатить базу данных на некоторое время назад благодаря логированию всех изменений. Также можно использовать ПАК Oracle ZDLRA, который практически синхронно получает все изменения в БД, либо программно-аппаратные комплексы общего назначения, например, EMC RecoverPoint, ПО Vision Solutions Double-Take. Они тоже логируют все изменения и позволяют восстановиться на любую точку в интервале времени.
Сейчас мы говорим только об оперативном восстановлении. В случае больших аварий или необходимости восстановиться на большее время назад обычные резервные копии остаются незаменимым инструментом. Но в нынешних условиях это только запасной парашют, раскрываемый в последний момент.
Если говорить об инновациях в системах резервного копирования и восстановления, нельзя не упомянуть Oracle Zero Data Loss Recovery Appliance (ZDLRA). Этот программно-аппаратный комплекс семейства Oracle Engineered Systems предоставляет возможность резервного копирования и быстрого восстановления Oracle Database любых платформ и любых Edition (Enterprise и Standard). В основе ZDLRA лежат виртуальные backup-базы (Virtual Full Backup), получаемые на основе первого полного backup и последующих журналов изменений. За счет этих виртуальных backup можно восстановить базу данных на любой момент времени значительно быстрее, чем при классическом использовании СРК по схеме «раз в неделю полный backup, раз в сутки инкрементальный». Можно сказать, что ZDLRA продолжает направление, заданное Oracle Exadata. В Exadata за счет специального Software реализована инновационная система хранения, оптимизированная под задачи Oracle Database. А в ZDLRA функционирует специальное Software, оптимизирующее резервное копирование именно Oracle Database.
Четвертое — уменьшение скрытых ошибок. Существует только один способ убедиться в корректной работе резервной копии — попробовать ее восстановить. Это самый правильный и редко используемый нашими заказчиками метод.
Но мы предлагаем выход и из этой ситуации. Во-первых, иметь легко восстанавливаемые экземпляры систем. Это опять история о snapshot- и standby-системах, которые можно достаточно быстро развернуть и проверить. Времени и сил это займет несравнимо меньше, чем «разматывание» всей резервной копии. Конечно, это помогает далеко не всегда, но оставляет чуть больше надежды, что в случае ЧП будет можно восстановить данные хотя бы этими средствами.
Во-вторых, некоторые СРК позволяют выполнять автоматизированное тестирование. В определенное время по расписанию можно запускать виртуальные машины в изолированной среде и по заранее заданным алгоритмам проверять, действительно ли данные восстановились, доступно ли приложение, консистентно ли оно, отвечает ли на нужные запросы. Таким способом администраторов можно избавить от долгой рутинной работы.
Пятое — прозрачность системы резервного копирования. Описанный комплексный подход предполагает построение сложной системы с применением множества технологий от разных производителей. Задача сделать эту систему действительно работоспособной, заложить в нее возможность дальнейших изменений и масштабирования, нетривиальна, и решить ее можно двумя способами:
- Первый способ — при условии, что заказчик достаточно компетентен сам и хочет взять эту систему себе в эксплуатацию. Tут мы как интегратор помогаем выстроить все необходимые процессы, создать регламентную базу, разработать все необходимые инструкции и планы, чтоб ИТ-департамент заказчика дальше мог самостоятельно развивать и эксплуатировать систему в нужном русле. А дальше передать всю эту практическую базу регламентов и заданий заказчику в виде работающей системы бизнес-процессов.
- Второй способ, когда заказчик не уверен, что сможет поддерживать систему СРК постоянно в боевом состоянии, выходом будет передача системы на частичный либо полный аутсорсинг. И у нас есть такие клиенты, которые успешно пользуются данной услугой, постоянно наращивая и требования SLA, и масштабы вовлеченности нас как ИТ-аутсорсера.
К сожалению, пока нет универсального рецепта, который позволил бы решить проблему восстановления данных в текущих условиях постоянного роста и усложнения систем. Только совокупность вышеописанных решений и системный подход позволят компаниям восстанавливать данные в сроки, которые требует бизнес.

