 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Репликация данных
Нужные данные в нужном месте в нужное время
Цели репликации данных
Как правило, по мере расширения любого предприятия быстро возникает необходимость иметь несколько центров обработки данных. Обычно оптимальным решением таких задач, как быстрое реагирование на запросы клиентов, обеспечение надежной «цепочки поставок» и взаимодействия между сотрудниками, является размещение информации там, где она используется. Следовательно, необходимо обеспечить доступность одной и той же информации в нескольких местах (офисах), возможно, находящихся далеко друг от друга. Чтобы одна и та же информация была доступна в нескольких офисах организации, необходимо реплицировать (публиковать) данные в эти офисы. Прайс-листы, спецификации продукции, Web-страницы и другие подобные данные зачастую требуется реплицировать во все офисы предприятия. Очевидно, что для нормального функционирования организации большое значение имеет идентичность этих данных в любом из ее офисов. Поэтому любые изменения данных должны вноситься одновременно (быть синхронизированными) во всех офисах.
Репликация данных также часто проводится с целью извлечения информации для ее анализа
(mining). По мере развития предприятия объем накопленных данных о его деятельности (исторических данных) неизбежно растет. Исторические данные можно хранить в хранилищах данных и извлекать их для анализа тенденций, результаты которого можно использовать при планировании и для других целей. Хотя извлечение данных для анализа дает очень полезные результаты, оно требует выполнения огромного количества операций вводавывода. Как правило, извлечение онлайновых данных предприятия оказывает сильное влияние на выполнение текущих операций. Чтобы избежать этого неблагоприятного влияния, онлайновые данные можно реплицировать на отдельный сервер, служащий хранилищем данных. Данные, помещенные в такое хранилище, можно затем извлекать для анализа, не прерывая выполнение операций над рабочей копией данных.
Третьей, и едва ли не самой важной, причиной репликации данных является обеспечение возможности их восстановления после аварий. По мере расширения предприятия экономические и социальные последствия события, приводящего к выходу из строя центра данных, становятся все более тяжелыми. Очевидно, что для нормального функционирования предприятия необходимо обеспечить быстрое восстановление его работоспособности после пожара, наводнения, акта вандализма, отказа электрической сети, сбоя в программном обеспечении и других событий, которые могут полностью вывести из строя его центр данных. Наличие актуальной копии рабочих данных в месте, не затронутом воздействием аварии, обеспечит предприятию возможность быстро восстановить свою деятельность, тогда как в обратной ситуации деятельность предприятия может оказаться полностью свернутой из-за аварии.
Сущность репликации данных
Является ли целью репликации данных их публикация в другие офисы, извлечение для анализа или восстановление после аварий, сущность репликации не изменяется. Репликация позволяет обеспечить доступность рабочих данных в режиме онлайн в одном или нескольких офисах, удаленных от основного центра данных, а также поддерживать их копии идентичными исходным базам данных, которые используются для управления бизнесом (синхронизация баз данных).
Технологии репликации данных компании VERITAS
Репликация позволяет синхронизировать одну или несколько вторичных копий данных предприятия с основной или исходной копией, обрабатываемой приложениями. Компания VERITAS предлагает технологии репликации, которые позволяют обеспечить идентичность копий и исходных данных (синхронизацию данных) при следующих способах копирования:
- Из исходной файловой системы в одну или несколько целевых файловых систем на разных компьютерах.
- Из исходной группы томов на одну или несколько целевых групп томов на разных компьютерах.
Репликаторы файловых систем и групп томов поддерживают целостность процесса репликации даже в случае выхода из строя сети или системы. При этом обеспечивается надлежащая производительность.
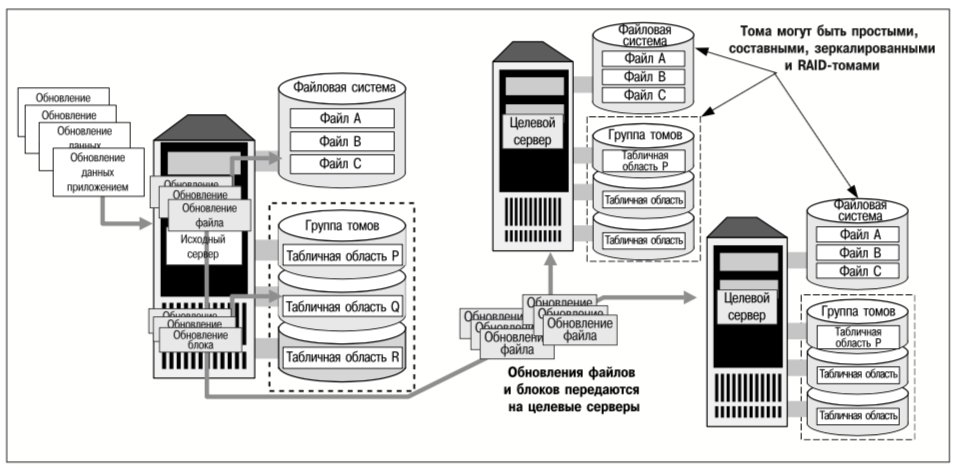
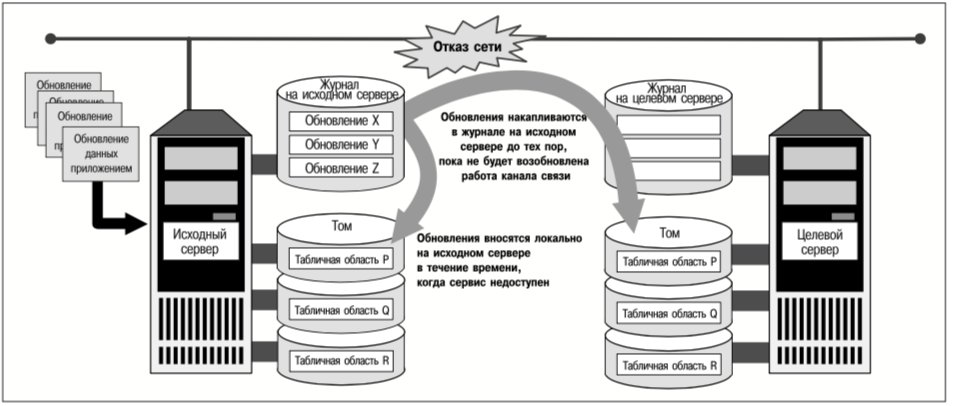
Как показано на рис. 1, приложения выполняются на исходном сервере и обновляют как файлы в файловой системе, так и таблицы БД, хранимые на группе томов (в файлах-контейнерах или на «сырых» устройствах). И реплики файловой системы, и реплики группы томов поддерживаются на двух целевых серверах. На рис. 1 проиллюстрированы три ключевых момента процесса репликации:
- Можно реплицировать либо файловые системы, либо группы томов (содержащие одну или несколько файловых систем). Репликация файловых систем целесообразна в случае большого количества файлов, которые являются неотъемлемой частью сложных бизнес-приложений. Репликация групп томов, как правило, больше подходит для баз данных, хранимых в небольшом количестве крупных файлов, которые, возможно, находятся в нескольких файловых системах на одном или нескольких томах.
- Репликация – это операция типа «один ко многим». Для каждой реплицируемой файловой системы или группы томов существует единственный источник (исходный сервер) и одно или несколько мест назначения (целевые серверы). Исходный сервер обеспечивает доступ приложений к данным для чтения/записи. Реплики файловых систем можно монтировать (подключать) для их использования приложениями и во время выполнения репликации. Реплики групп томов не могут использоваться приложениями, если процесс репликации еще не завершен.
- Для репликации применяются стандартные аппаратные компоненты и сетевые соединения. Чтобы реплицировать данные, не требуется никакого специального оборудования, и нет необходимости в выделении отдельных каналов связи для этой операции (хотя компания VERITAS рекомендует выделять такие каналы в тех случаях, когда пропускная способность и скорость реакции приложений имеют решающее значение). Исходные и вторичные реплики данных необязательно должны храниться на идентичных дисках или томах, но реплицируемые тома должны иметь одинаковую полезную емкость.
В «стеке» доступа к данным и управления ими (см. JetInfo No2) средства репликации находятся либо на уровне файловой системы, либо на уровне диспетчера томов. Реплицируемыми объектами являются либо файловые системы, либо тома, поэтому все базовые средства компании VERITAS, в том числе средства повышения доступности (например, зеркалирование) и производительности (например, Quick I/O for Databases), можно использовать в сочетании с репликацией данных как на исходном сервере, так и на целевых серверах.
Предлагаемые VERITAS программные продукты позволяют проводить репликацию на основе заданных правил (политики). Чтобы удовлетворить требованиям конкретных предприятий, системные администраторы могут определить политику репликации, включая следующие ее параметры:
- Какие файловые системы или группы томов исходного сервера необходимо реплицировать.
- Какие файловые системы или тома целевых серверов являются объектами назначения для репликации.
- Какой должна быть частота синхронизации вторичных копий с исходной.
- Какой должна быть реакция на временные отказы сети и сбои целевых серверов.
После того как политика задана, репликация выполняется автоматически, не требуя вмешательства системного администратора до тех пор, пока не произойдет какое-либо чрезвычайное событие, например, авария такого масштаба, что для восстановления системы потребуется использование реплики данных.
Хотя операции репликации файловых систем и групп томов преследуют одну и ту же основную цель – обеспечение идентичности данных на нескольких компьютерах – между ними существуют определенные различия, которые обусловлены, прежде всего, характером реплицируемых объектов. Учитывая эти различия, можно выбрать оптимальный тип репликации в каждом конкретном случае. В последующих разделах репликация файловых систем и групп томов описывается более подробно.
Репликация файловых систем
Средства репликации файловых систем, реализованные в продукте VERITAS File Replicator (VFR), позволяют реплицировать обновления файлов независимо от физического и логического местонахождения данных. Содержимое файла в реплицируемой файловой системе идентично на исходном и целевом серверах, но не гарантировано, что файлы исходного и целевого серверов хранятся в одних и тех же местах тома или диска.
Репликация файловых систем выполняется синхронно. Это значит, что операции записи данных приложением на исходный сервер считаются незавершенными до тех пор, пока эти данные не будут также записаны на все целевые серверы. Механизм синхронной репликации рассматривается в следующем разделе. Следует отметить, что запись данных приложением в реплицируемые файловые системы по сети может потребовать значительно большего времени, чем их запись в локальные файловые системы. Поэтому репликация файловых систем не подходит для приложений с очень высокой частотой обновления данных или критическими требованиями ко времени реакции приложений.
Поскольку в результате репликации файловых систем данные на целевых серверах всегда являются актуальными, их исходные и вторичные копии никогда не отличаются друг от друга более чем на текущую операцию ввода-вывода. Поэтому нет необходимости вести журнал обновлений, который может быть использован для восстановления данных после сбоя канала связи или целевого сервера. Это позволяет свести к минимуму дополнительные операции ввода-вывода, но порождает и такой недостаток как потеря связи между исходным и целевым серверами, что потребует полной ресинхронизации этих серверов после восстановления связи.
После восстановления вышедшей из строя сети, исходный и целевой серверы должны определить, идентичны ли на них копии реплицируемых файлов. Для этого независимо вычисляется контрольная сумма для каждого файла. Если контрольные суммы для файла на двух серверах не совпадают, то версия файла на целевом сервере заменяется копией с исходного сервера.
По сравнению с восстановлением по журналу репликации, который предоставляет информацию о том, какие данные обновлялись в момент отказа, восстановление путем сравнения контрольных сумм может потребовать много времени. Из-за того, что принят этот метод, средство репликации файловых систем приобретает такой недостаток, как длительное время восстановления после аварии, однако, он компенсируется тем, что непроизводительные затраты во время нормальной работы сведены к минимуму. Поэтому репликацию файловых систем оптимально использовать в наиболее надежных сетях, где отказы, требующие ресинхронизации после восстановления связи, происходят редко.
Репликация файловых систем обладает еще одним достоинством: поскольку о реплицируемых информационных объектах имеются достаточно полные сведения (например, известно, используется ли данный файл), репликация файловых систем может быть двунаправленной.
Приложения на целевом сервере могут обращаться к файлам в реплицированной файловой системе. При определенных условиях файлы, измененные приложениями на целевом сервере, могут быть реплицированы на исходный сервер. Этого нельзя сделать в случае репликации групп томов, которая является строго однонаправленным процессом и не позволяет использовать данные целевого сервера во время репликации.
Репликация групп томов
При репликации групп томов, реализуемой продуктом VERITAS Volume Replicator (VVR), все блоки, записанные на группе томов исходного сервера, реплицируются на тома одного или нескольких целевых серверов независимо от содержания реплицируемых данных. При репликации томов не различаются обновления данных приложениями, обновления метаданных файлов и обновления карты свободного дискового пространства.
Поскольку нет контекстной связи файловых систем и приложений с репликацией группы томов, возможна асинхронная репликация данных между исходным и целевым серверами. Механизм асинхронной репликации рассматривается в следующих разделах. По отношению к приложениям основными преимуществами этого механизма являются обеспечение более высокой производительности приложений и быстрое восстановление после отказов сети.
VERITAS Volume Replicator, запущенный на исходном сервере, регистрирует каждое изменение, вносимое в реплицируемую группу томов, прежде чем переслать его на целевые серверы. При отказе сети исходный сервер продолжает регистрировать обновления реплицируемых групп томов локально. После восстановления сети те обновления, которые были зарегистрированы во время ее простоя, пересылаются на целевые серверы. Поэтому репликация групп томов – это оптимальный вариант для тех случаев, когда сеть, соединяющая исходный и целевой серверы, не является абсолютно надежной.
Характер репликации групп томов не позволяет приложениям на целевом сервере использовать реплицируемые данные во время процесса репликации. Таким образом, этот способ репликации наиболее подходит для применения в следующих случаях:
- Публикация данных. Некоторые организации хранят данные на центральном (исходном) сервере и публикуют их для использования на нескольких целевых серверах. Web-страницы, прайс-листы, спецификации продукции и другие документы, используемые в различных офисах предприятия, – вот характерные примеры данных, для которых используется репликация этого типа.
- Восстановление после аварий. Если авария в основном центре данных (где находятся исходные серверы) полностью выводит его из строя, работа может продолжаться в резервном центре данных, т.е. в месте расположения целевых серверов, которое находится достаточно далеко от основного центра данных. (Например, в сейсмоопасном районе такой резервный центр данных должен находиться дальше от основного, чем в случае сейсмически безопасного района). Группы томов исходного сервера можно реплицировать в резервный центр данных. Если на исходном сервере произойдет авария, то приложения можно быстро перезапустить в резервном центре данных, а для возобновления обработки будут использованы актуальные реплики данных.
В этих вышеописанных случаях реплики данных целевого сервера используются после завершения процесса репликации, а не во время его выполнения.
Синхронная репликация
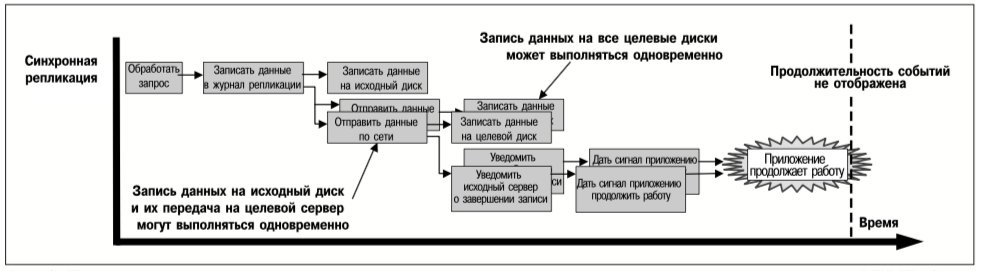
Говорят, что реплицированная группа томов целевого сервера является актуальной, если ее содержимое идентично содержимому томов исходного сервера. Для того, чтобы целевая группа томов была постоянно актуальной, все обновления данных приложениями необходимо синхронно реплицировать на все целевые серверы. Каждое такое обновление необходимо записать как на исходные тома, так и на соответствующие целевые тома, и только после этого приложение сможет продолжить работу. (Это – единственный режим работы VERITAS File Replicator).
Абсолютно синхронная репликация может привести к тому, что время реагирования приложения окажется неприемлемо большим. VERITAS Volume Replicator использует оптимизацию для уменьшения времени реакции приложений, не создавая при этом возможности для нарушения целостности синхронно реплицированных данных. Операция записи данных приложением на том, синхронно реплицируемый с помощью VERITAS Volume Replicator, считается завершенной после того, как эта операция
- зарегистрирована (т.е. занесена в журнал) на исходном сервере;
- передана на все целевые серверы, а исходный сервер получил подтверждения ее приема от всех целевых серверов.
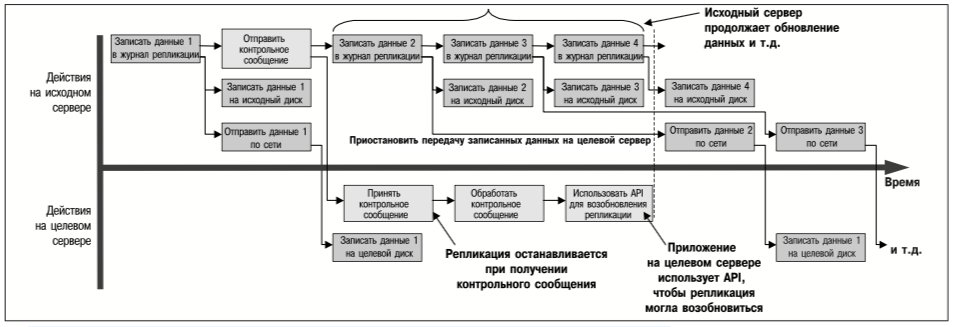
На рис. 2 показана последовательность действий по данному алгоритму репликации, причем указаны операции, которые могут выполняться одновременно. По сравнению с записью данных на локальный не реплицированный том, запись на синхронно реплицированный том требует большего времени, а задержка определяется следующими факторами:
- временем на регистрацию в локальном журнале (прежде всего – временем на выполнение операций ввода-вывода на диск);
- временем на передачу и подтверждение сообщения, которое необходимо наиболее удаленному (по времени прохождения сообщений) целевому серверу.
Как следует из рис. 2, оптимизация заключается в том, что приложениям не требуется ожидать выполнения операций ввода-вывода на диске целевого сервера. Применение алгоритма репликации, представленного на рис. 2, позволяет защитить данные от потери в случае:
- аварии на исходном сервере, в результате которой его восстановление невозможно, тогда можно использовать реплики данных, существующие на каждом целевом сервере, а также
- отказа целевого сервера или канала связи, тогда, поскольку все изменения регистрируются в журнале на исходном сервере, их можно внести после восстановления работоспособности целевого сервера или канала связи.
Однако, и при такой оптимизации повышение частоты обновлений данных приложения, кратковременная перегрузка сети или просто наличие большого количества целевых серверов может сделать синхронную репликацию неприемлемой при необходимости обеспечить определенную производительность приложений. В таких случаях используется асинхронная репликация данных. Программный продукт VERITAS Volume Replicator поддерживает этот механизм репликации.
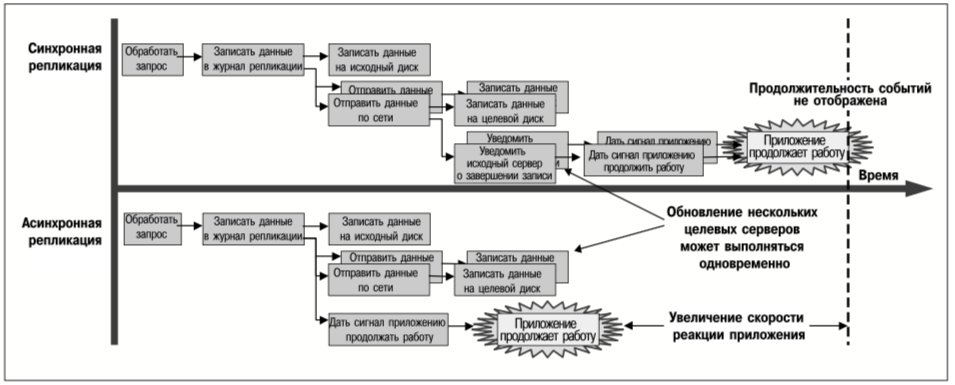
Асинхронная репликация
При асинхронной репликации выполнение приложений продолжится, как только их запросы на запись данных будут зарегистрированы в журнале на исходном сервере. Передача и запись данных на тома целевых серверов происходят асинхронно, обычно после того, как приложение уведомлено о завершении операции записи его данных. На рис. 3 показано различие в скорости реакции приложения при синхронной и асинхронной репликации.
Как следует из рис. 3, асинхронная репликация позволяет уменьшить задержку или суммарное время выполнения запроса приложения на запись данных. Однако, более важное следствие асинхронной репликации состоит в том, что кратковременные перегрузки сети не приостанавливают выполнение приложений и не приводят к отказам в обработке запросов на запись данных. Работа приложений, записывающих данные на асинхронно реплицируемые тома, не замедляется и не приостанавливается вследствие перегрузки сети, потому что они выполняются независимо от работы канала связи и целевого сервера.
VERITAS Volume Replicator пересылает на целевые серверы обновления данных томов, сохраненные в журнале регистрации на исходном сервере, по мере того, как это позволяет загрузка сети и целевых серверов. Если перегрузка сети возникает нечасто и ненадолго, то после нормализации нагрузки данные на целевых серверах будут обновлены, т.е. в этом случае реплики на целевых серверах поддерживаются в актуальном состоянии. Если же сеть перегружена постоянно, то объем информации о еще не реплицированных записях (что регистрируется в журнале на исходном сервере) возрастает, и выполнение приложений, в конечном счете, приостановится. Асинхронная репликация позволяет легко преодолеть кратковременную перегрузку сети, но не является средством для увеличения пропускной способности сети в случаях, когда в установившемся режиме пропускная способность сети недостаточна.
Асинхронная репликация имеет следующие преимущества:
- Более быстрая реакция приложений (по сравнению с синхронной репликацией).
- Допустимость кратковременных перегрузок сети.
- Быстрое восстановление данных после выхода из строя целевого сервера или отказа сети.
Недостаток асинхронной репликации заключается в том, что возможны короткие промежутки времени, в течение которых данные на целевых томах не обновляются, следовательно, реплики до некоторой степени утрачивают актуальность. Если в тот момент, когда на тома-реплики еще не записаны последние обновления, выйдет из строя целевой сервер или откажет канал связи, то после восстановления работоспособности этого оборудования из журнала исходного сервера пересылается информация об обновлениях за время простоя, реплики обновляются и их актуальность восстанавливается. Однако, если в это время на исходном сервере случится авария, после которой его работоспособность нельзя будет восстановить, содержимое журнала обновления может оказаться утраченным, и в этом случае на целевом сервере можно восстановить только несколько устаревшие данные.
Чтобы предотвратить значительные потери данных в случае возникновения описанной выше ситуации, системный администратор может установить допустимый предел «неактуальности» реплики (т.е. указать максимальное количество операций записи, на которое реплика на целевом сервере может «отставать» от данных на исходном сервере). В случае превышения этого предела выполнение операций записи данных приложениями на исходном сервере приостанавливается (сигнал о завершении операции не подается) до тех пор, пока количество неотправленных обновлений не станет меньше установленного предельного значения. Таким образом, можно гарантировать, что при любых обстоятельствах реплицированные данные будут отличаться от исходных не более чем на указанное в качестве предела количество операций записи.
Хотя при асинхронной репликации не гарантируется полная непротиворечивость данных, этот метод часто используется потому, что он позволяет обеспечить необходимую производительность. Как кратковременная перегрузка, связанная с обновлением данных, так и сильная загруженность сети, вызванная другими причинами, могут увеличить время реакции приложений до неприемлемых значений. Асинхронная репликация позволяет сократить время реакции приложений, так как в этом случае приложения могут продолжать работу, не ожидая завершения большинства операций, необходимых для удаленной репликации данных, следовательно, время реакции приложений уменьшается на величину, равную времени выполнения таких операций репликации. Именно это свойство может оказаться решающим при выборе практически эффективного способа репликации.
Использование реплицированных томов
При репликации томов диспетчер репликации (replication manager) не имеет информации о содержимом обновляемых блоков: хранятся ли в них данные файлов, метаданные файловой системы, страницы баз данных или другие объекты. Без такой информации диспетчер репликации не может определить состояние файловых систем и баз данных на целевых серверах. Поэтому репликация групп томов является строго однонаправленным процессом: блоки копируются с исходного сервера на один или несколько целевых, но не наоборот. Кроме того, данные с реплицированных томов целевых серверов нельзя использовать, если процесс репликации продолжается.
Комбинированные методы восстановления
Если в системе, где используется асинхронная репликация, происходит такая авария, из-за которой невозможно восстановить работоспособность исходного сервера, данные на томах целевых серверов могут оказаться несколько устаревшими. В момент аварии некоторые обновления, уже полностью обработанные на исходном сервере, возможно, еще передавались по сети или только были зарегистрированы в журнале исходного сервера для последующей передачи. Такие обновления не отражаются в базе данных целевого сервера, которая используется для восстановления после аварии. Как правило, в подобных случаях для восстановления данных необходимо применять комбинированные методы, в которых используются функции более высокого уровня (например, журналы баз данных).
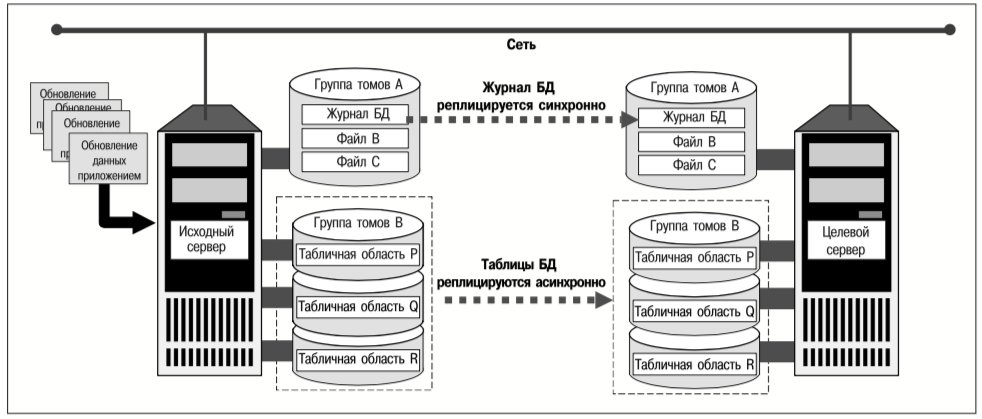
Например, табличные области БД можно хранить в файлах-контейнерах в файловых системах, созданных на томах реплицированной группы. Группу томов можно реплицировать асинхронно, чтобы обеспечить приемлемую производительность. В то же время файл, содержащий журнал базы данных, может принадлежать файловой системе, которая синхронно реплицируется на тома другой группы. Таким образом, хотя авария на исходном сервере может привести к потере обновлений таблиц во время передачи этих обновлений, журнал восстановления, необходимый для создания текущей реплики базы данных на целевом сервере, не будет затронут аварией и останется актуальным на целевом сервере. Поскольку этот журнал реплицируется синхронно, в нем отражаются все изменения базы данных, даже если они еще не были внесены в образ самой базы данных. Поэтому БД целевых серверов можно восстановить путем воспроизведения актуального журнала. На рис. 4 представлена описанная выше схема комбинированной репликации.
Аварии и отказы: сравнительный анализ
Выше уже упоминалось о том, как важна репликация данных для восстановления систем после аварий. С помощью актуальных удаленных реплик критических данных предприятие может быстро восстановить свою работоспособность после аварии. Наличие актуальных данных на удаленном сервере – это одно из самых важных условий бесперебойной работы предприятия, но не единственное такое условие. Если принять во внимание ряд других факторов, например, кадровые, коммуникационные и транспортные аспекты, то оказывается, что перенос деятельности из основного центра данных в резервный целесообразен только в случае действительно серьезной аварии. Как правило, оптимальным является устранение системных сбоев и отказов устройств хранения данных локально, без вовлечения в разрешение этих проблем удаленных резервных центров данных.
- Зеркалирование или RAID-технологии с автоматическим использованием запасного диска (automatic sparing) являются оптимальными решениями для преодоления отказов устройств хранения данных.
- Кластеризация с автоматическим переключением выполнения приложений на другие серверы (эта технология рассматривается в следующей главе) – это решение позволяет устранить последствия системных сбоев, в результате которых повреждения центра данных незначительны и он сохраняет функциональность.
Важной составной частью всякой стратегии восстановления данных предприятия после аварий должны быть объективные критерии, позволяющие различать следующие события:
- Отказы локальных устройств и систем, которые можно устранить локально.
- Кратковременные отказы каналов связи или целевых серверов, которые могут временно прервать репликацию данных.
- Серьезные аварии, после которых необходимо перенести производственную деятельность в резервный центр данных, а также надлежащим образом реагировать на каждое из них.
Отказы сети, а также сбои в работе как исходного, так и целевого сервера могут прервать процесс репликации томов. Журналы репликации являются тем механизмом, который после устранения неисправностей позволяет восстановить данные, ресинхронизировать их и возобновить репликацию, когда все необходимые для этого средства снова станут доступными. Обновления хранятся в журнале репликации на исходном сервере до тех пор, пока не станет возможным переслать их на целевые серверы. Журналы репликации на целевых серверах используются в том случае, если из-за аварии на исходном сервере необходимо перенести выполнение приложений на один из целевых серверов, т.е. создать новый исходный сервер.
Обмен контрольными сообщениями при репликации
VERITAS Volume Replicator поддерживает механизм обмена периодическими контрольными сообщениями (heartbeats) между исходным сервером и каждым из целевых серверов. Такой обмен сообщениями гарантирует, что обе стороны, участвующие в репликации данных, будут знать о состоянии соединения в любой момент времени независимо от того, существует ли в данный момент трафик операций ввода-вывода приложения или нет. Это позволяет обнаруживать отказы канала связи с упреждением, а не в тот момент, когда приложения попытаются записать данные на реплицированные тома.
Репликация и восстанавливаемость данных
VERITAS Volume Replicator учитывает порядок записи блоков между исходным и целевыми серверами. Это гарантирует, что поверх актуальных обновлений не будут записаны более старые обновления тех же блоков, поступившие позже из-за обстоятельств, связанных с загрузкой сети. Сохранение порядка записи также необходимо при восстановлении данных после аварий, например, чтобы предотвратить замену актуальных данных, записанных до аварии, более старыми копиями в процессе восстановления.
Репликация и непротиворечивость БД
Если в базе данных не имеется
- незавершенных транзакций и
- не записанных на диск данных в ее кэше,
то говорят, что ее образ на диске является непротиворечивым с точки зрения транзакций, и представляет собой объект, годный для резервного копирования или восстановления данных после аварии. Другие приложения и диспетчеры данных (data managers) также имеют свои собственные уникальные критерии непротиворечивости данных, которые VERITAS Volume Replicator выявить не в состоянии. Поскольку требования к непротиворечивости данных зависят от приложения, то в состав VERITAS Volume Replicator включены программные интерфейсы (API) для внутреннего контроля (in-band control), которые позволяют зарегистрированным на исходном сервере приложениям в определенные моменты передавать в потоке реплицируемых данных сообщения на целевые серверы. Приложение на исходном сервере может использовать эти API для передачи контрольного сообщения на целевые серверы, когда произойдет какое-либо важное для приложения событие (например, окончание рабочего дня). На рис. 6 приведена схема применения внутреннего контроля в процессе репликации.
Контрольные сообщения фактически «замораживают» репликацию на целевых серверах. Данные на целевых серверах «замораживаются» в том состоянии, которое они имели на исходном сервере в момент ввода контрольного сообщения в поток реплицируемых данных. Зарегистрированное приложение на каждом целевом сервере принимает контрольное сообщение, обрабатывает его и вызывает соответствующий API, чтобы возобновить репликацию, как представлено на схеме, приведенной на рис. 6.
Взаимное восстановление данных после аварий
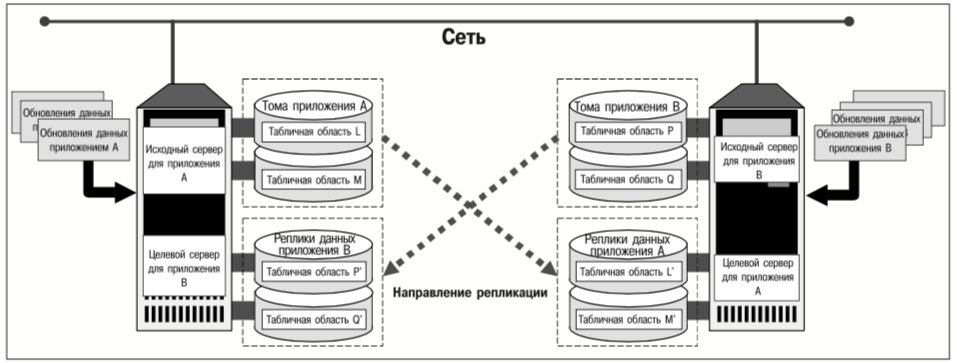
Роль конкретного сервера в процессе репликации (является он исходным или целевым) определяется для каждой реплицируемой группы томов или файловой системы. Например, вполне возможна ситуация, когда сервер является исходным для одной реплицируемой группы томов и целевым для другой. На рис. 7 показано, как такую ситуацию можно использовать для взаимного восстановления данных после аварий.
Система, изображенная на рис. 7, включает в себя серверы, выделенные для приложений A и B. Данные приложения A реплицируются на группу томов, которая находится на сервере приложения B, и наоборот. Если один из этих двух серверов выйдет из строя, то его приложение можно будет запустить на работоспособном сервере с актуальными данными.
Если предприятие расширяется и устанавливает выделенные сервера приложений, целесообразно рассматривать взаимное восстановление данных на основе технологии репликации как часть стратегии расширения. При минимальных капиталовложениях в:
- устройства данных, хранения для реплицированных
- увеличение производительности серверов и объёмов памяти для выполнения репликации данных и обеспечения надлежащей производительности приложений в случае переключения их выполнения на другие серверы, а также
- сеть с пропускной способностью, достаточной для передачи потока реплицируемых данных в дополнение к обычному рабочему трафику, предприятие обеспечит себе быстрое возобновление функционирования в полном объеме в случае, если авария выведет из строя весь центр данных.
Кластеризация
Обеспечение доступности бизнес-приложений
Обработка данных предприятия
Ранее рассматривалось управление онлайновыми данными предприятия и устройствами их хранения и было показано, что базовые технологии компании VERITAS (VERITAS Foundation) обеспечивают высокую доступность данных, производительность доступа к которым может масштабироваться в соответствии с растущими потребностями бизнеса. Однако, для успешной деятельности предприятия недостаточно только иметь данные в режиме онлайн. Необходимо также иметь высоко доступную систему обработки этих данных. Предприятие должно решить следующие проблемы:
- Как обеспечить непрерывное функционирование прикладного сервиса даже в случае отказа систем или выхода из строя центра обработки данных?
- Как повысить производительность приложений по мере расширения предприятия и увеличения нагрузки на его вычислительные ресурсы?
- Как осуществить централизованное управление большим количеством систем при разумных затратах?
Продукт VERITAS Cluster Server обеспечивает решение этих проблем. Кластеризация позволяет координировать выполнение приложений на нескольких серверах как для повышения их доступности, так и для обеспечения их масштабируемости.
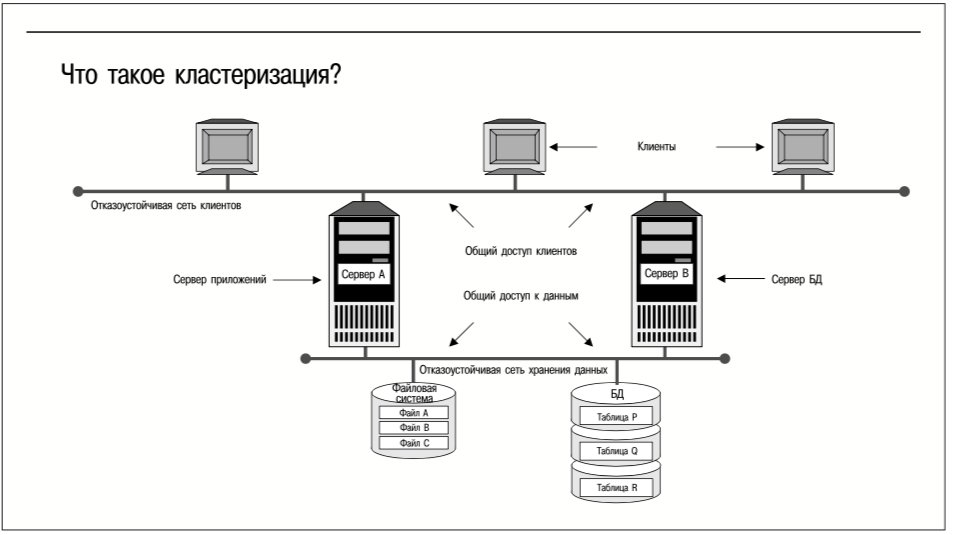
Что такое кластеризация?
В широком смысле слова кластер – это любой набор соединенных между собой компьютеров, работа которых координируется для получения какого-либо полезного эффекта. На рис. 8 представлены основные свойства кластеров. Кластеризация чаще всего используется для повышения доступности приложений и обеспечения их масштабируемости. Некоторые технологии кластеризации также обеспечивают единый образ системы, что позволяет централизованно управлять большим количеством компьютеров как единой системой из единой точки управления.
Зачем использовать кластеры?
Привлекательность кластеризации для пользователей компьютеров обусловлена тем, что кластеры потенциально способны решить некоторые давние проблемы, связанные с обработкой информации:
- В случае выхода сервера из строя или отказа приложения другой сервер из того же кластера может взять на себя эту рабочую нагрузку, поскольку все серверы в кластере соединены с одними и теми же устройствами хранения данных и клиентами.
- Если выйдет из строя сетевое соединение, клиенты могут использовать альтернативные маршруты для получения доступа к данным и продолжения своей работы.
- Если потребности приложения в ресурсах становятся слишком большими для существующих серверов, можно подключить дополнительные серверы и перераспределить рабочую нагрузку между большим количеством серверов.
- Несмотря на увеличение количества кластеризованных серверов в центре обработки данных, управление системой во многом остается централизованным, что позволяет не увеличивать штат системных администраторов, а значит, не увеличивать затраты.
- Если центр обработки данных полностью выйдет из строя, удаленные компьютеры, включенные в кластер этого центра, могут взять на себя его рабочую нагрузку и возобновить обработку информации, используя реплику онлайновых данных.
Все перечисленные преимущества можно реализовать в той или иной степени с помощью технологии кластеризации. Программный продукт VERITAS Cluster Server (VCS) поддерживает до 32 соединенных между собой серверов, работающих под управлением ОС Solaris, HP-UX или Windows NT как связанная система, взаимно защищая запущенные на них приложения от отказов. В сочетании с программными продуктами VERITAS SANPoint Volume Manager и File System программный продукт VERITAS Cluster Server образует пакет SANPoint Foundation HA. Эта технология кластеризации компании VERITAS позволяет нескольким копиям приложения выполняться параллельно на разных серверах, в результате чего суммарная производительность превышает производительность любого отдельного сервера.
Приложения и кластеры
Поскольку кластеризация существенно повышает эффективность работы приложений, рассмотрение этой технологии целесообразно начать с объяснения того, что VCS рассматривает приложение как сервис, предоставляемый группой взаимосвязанных системных ресурсов. Например, прикладной сервис обслуживания Web-страниц может состоять из следующих компонентов:
- дисков, на которых хранятся обслуживаемые Web-страницы;
- тома, созданного на основе этих дисков;
- файловой системы, использующей этот том;
- базы данных, табличные области которой являются файлами в этой файловой системе, а записи содержат указатели на страницы;
- платы сетевого интерфейса, используемой для экспорта Web-сервиса;
- одного или нескольких IP-адресов, связанных с данной платой (платами) сетевого интерфейса;
- прикладной программы и связанных с ней библиотек.
Для VCS существуют два важных аспекта такого представления прикладного сервиса в виде совокупности ресурсов:
- Чтобы какой-либо сервис выполнялся на определенном сервере, последнему должны быть до-ступны все ресурсы, необходимые для данного сервиса.
- Составляющие сервис ресурсы являются взаимозависимыми; это означает, что для начала работы одних ресурсов (например, файловой системы) необходимо, чтобы уже функционировали другие ресурсы (например, тома).
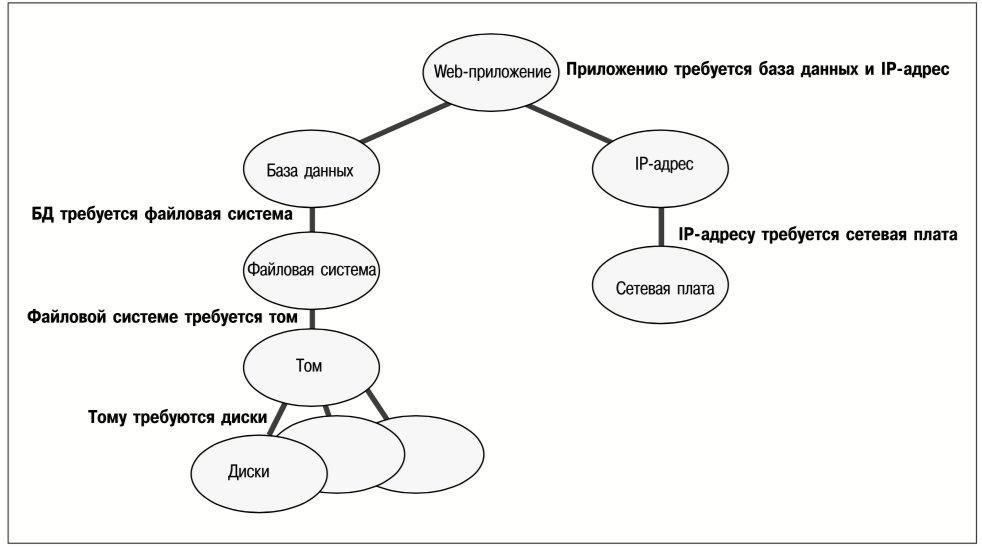
VERITAS Cluster Server представляет ресурсы, входящие в состав сервиса, в виде графа, на котором узлы изображают ресурсы, а соединяющие их линии – зависимости. На рис. 9 приведен граф зависимостей между ресурсами для вышеописанного прикладного Web-сервиса.
На рис. 9 нижние (дочерние) узлы представляют ресурсы, необходимые для функционирования ресурсов, изображенных в верхнем (родительском) узле. Так, например, для функционирования тома необходимо, чтобы были доступны ресурсы дисков; для файловой системы необходимо, чтобы том был активен и т. д.
Важно отметить, что граф зависимости ресурсов, изображенный на рис. 9, состоит из двух независимых поддеревьев ресурсов: вершиной одного является база данных, а другого – IP-адрес для связи с клиентами. Web-приложению требуется как база данных, так и связь с клиентами; а в остальном эти два поддерева являются независимыми друг от друга.
Запуск и останов ресурсов
VCS поддерживает как язык описания, так и графический интерфейс для задания графов зависимостей между ресурсами. Демон (резидентная программа) VCS для контроля и мониторинга кластера называется HAD (High Availability Daemon), он использует результирующие графы при запуске и останове прикладных сервисов. Дочерние ресурсы должны быть активными, только при этом условии можно будет запустить их родительские ресурсы. Демон HAD запускает сервис, активизируя (переводя в режим онлайн) ресурсы, представленные концевыми узлами на графе зависимостей ресурсов этого сервиса. Как видно из рис. 9, диски и сетевую плату можно активизировать одновременно, потому что они не зависят друг от друга. Как только диски будут переведены в режим онлайн, можно активизировать том; как только сетевая плата будет переведена в режим онлайн, можно активизировать IP-адрес; и т. д. Родительский ресурс можно активизировать только после того, как все необходимые ему дочерние ресурсы будут переведены в режим онлайн. Так, Web-приложение, представленное на рис. 9, не может быть запущено до тех пор, пока не будут активизированы база данных и IP-адрес.
Аналогично, при останове сервиса демон HAD начинает с вершины графа. В примере, приведенном на рис. 9, он сначала деактивирует Webприложение, затем базу данных и IP-адрес (параллельно) и т. д.
Группы ресурсов VCS, которые рассматривались до сих пор, известны как failover группы. В каждый момент времени ресурсы из такой группы могут находиться в режиме онлайн только на одном кластерном сервере. На двух серверах нельзя одновременно запустить прикладной сервис, предоставляемый такой группой ресурсов, и обрабатывать одни и те же данные.
Демон HAD также распознает взаимозависимости между сервисами. Например, может потребоваться запрет на одновременную работу двух каких-либо сервисов, как в случае тестовой и рабочей версий одного и того же приложения. Такие связи можно выразить с помощью графов зависимостей между группами ресурсов, на которых указываются зависимости между сервисами. Демон HAD учитывает эти зависимости. Например, HAD можно сконфигурировать так, чтобы не допустить одновременной работы тестовой и рабочей версий приложения.
Чтобы обеспечить масштабирование приложений, демон HAD поддерживает также группы параллельных ресурсов. Ресурсы, составляющие такую группу, могут находиться в режиме онлайн на нескольких серверах одновременно. Это позволяет приложениям, требования которых превышают возможности одного сервера, работать в виде нескольких копий, каждая на отдельном сервере. В случае группы параллельных ресурсов приложение отвечает за координацию одновременных обращений нескольких его копий, работающих на нескольких серверах кластера, к совместно используемым данным. Программные продукты SANPoint Volume Manager и File System поддерживают масштабируемость приложений, разрешая томам и файловым системам находиться в режиме онлайн по отношению к нескольким серверам одновременно.
Управление ресурсами кластера
Для управления различными типами ресурсов необходимо выполнение различных действий. Например, для активизации SCSI-диска требуется выполнение команды spin-up, тогда как для активизации базы данных Oracle – запуск процесса СУБД Oracle, а значит выполнение соответствующей команды (или команд) startup. С точки зрения демона HAD достигается один и тот же результат – ресурс становится доступным для использования. Однако, выполняемые при этом действия совершенно разные. VERITAS Cluster Server успешно обрабатывает управляющие команды, несмотря на их разнообразие, поскольку в этой программе реализован надежный способ обработки, который также предоставляет разработчикам приложений и аппаратного обеспечения возможность интегрировать новые типы ресурсов в этот продукт.
Каждый тип ресурсов, поддерживаемый в кластере VCS, связан с каким-либо агентом. Агентом называется инсталлированная программа, которая зарегистрирована демоном HAD. Агент VCS имеет три метода или три точки входа, в которых его можно вызвать:
- Метод онлайн, вызываемый HAD, когда требуется активизировать ресурс.
- Метод оффлайн, вызываемый HAD, когда требуется деактивировать ресурс.
- Метод мониторинга, вызываемый HAD, когда требуется проверить рабочее состояние ресурса.
HAD вызывает методы агента ресурса в надлежащей последовательности для запуска и останова прикладных сервисов, для переноса выполнения прикладного сервиса на другой сервер в случае отказа (в сущности, перенос – это останов сервиса на одном сервере и его немедленный запуск на альтернативном сервере) и для мониторинга состояния ресурса. Каждый метод агента характеризуется набором параметров, называемых атрибутами, значения которых задаются в процессе конфигурирования и передаются методу при его вызове демоном HAD.
Поскольку агенты ресурсов кластеров VCS имеют простую структуру, разработка агентов для поддержки дополнительных типов ресурсов является сравнительно простой задачей. Например, в состав продукта VERITAS Database Edition for Oracle входят агенты, которые позволяют включить базы данных Oracle в ресурсы кластера.
Компоненты кластера и его конфигурация
Используя описанную выше архитектуру прикладного сервиса, VERITAS Cluster Server реализует отказоустойчивую среду выполнения приложений, в которой клиентам обеспечивается практически постоянный доступ к приложениям даже в случае выхода из строя целой системы. Аппаратные компоненты, входящие в состав кластера, представлены на рис. 10.
В состав кластера VCS может входить от 2 до 32 соединенных между собой серверов, на которых работает программное обеспечение VERITAS Cluster Server. Все серверы, объединенные в кластер, должны иметь доступ к одним и тем же клиентам, что обеспечивает принципиальную возможность предоставления любого клиентского сервиса, предлагаемого кластером, не одним, а несколькими серверами. В кластере должна быть выделенная сеть (private network), соединяющая серверы – узлы кластера, чтобы сетевой трафик общей ЛВС не оказывал влияние на коммуникацию внутри кластера.
Хотя можно создать такие кластеры, в которых связи между устройствами хранения данных и серверами будут неполными (т.е. не все серверы будут соединены со всеми устройствами хранения), в наиболее практичных и управляемых кластерных конфигурациях используются сети хранения данных (SAN), что обеспечивает полные физические связи между устройствами хранения и серверами.
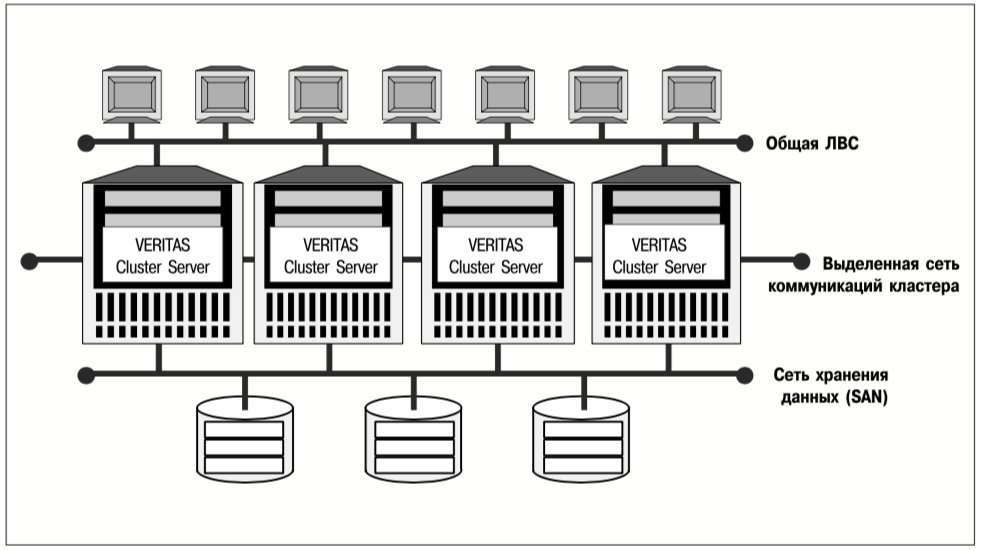
Компоненты VCS
На каждом сервере, являющемся узлом кластера, работают некоторые или все шесть основных функциональных компонентов VCS:
- Демон HAD или ядро кластера (cluster engine), выполняемый в реальном времени процесс, который отслеживает состояние всех копий VCS в кластере, а также управляет изменениями этого состояния (например, переносом выполнения приложения с отказавшего на альтернативный сервер) в соответствии с политиками изменения состояния кластера и управления кластером.
- Модуль коммуникаций, использующий специализированные отказоустойчивые протоколы с малой задержкой для взаимодействия с другими копиями VCS и непрерывного отслеживания состояния связи внутри кластера.
- Транслятор, который читает графы зависимости ресурсов, выраженные на языке конфигурации VCS, и интерпретирует их для демона HAD.
- Оценщик нагрузки, который оценивает нагрузку на серверы, что позволяет копиям HAD выделить серверы для прикладных сервисов так, чтобы создаваемая приложениями нагрузка оптимально распределилась между ресурсами кластера.
- Агенты для ресурсов каждого типа, представленного в кластере.
- Интерфейс системного администрирования – в виде командной строки и графический.
Соединения внутри кластера
Копии VCS взаимодействуют друг с другом через два или более отдельных физических соединения, хотя бы одно из которых должно быть выделенным (зарезервированным для передачи сообщений VCS). В некоторых конфигурациях для связи между различными копиями VCS можно использовать общий раздел диска
Наличие нескольких выделенных соединений позволяет частично решить общую проблему кластеризации – неспособность сервера отличить отказ взаимодействующего с ним другого сервера от отказа (единственного) канала связи между ними. Когда невозможно отличить отказ сервера от отказа канала связи, кластерный сервер не может инициировать процесс переноса выполнения приложения на альтернативный сервер. Если бы это произошло, оказалась бы возможной ситуация, когда два или больше серверов, которые не могут взаимодействовать между собой, запускают один и тот же прикладной сервис для обработки одних и тех же данных. В случае возникновения этой ситуации искажение данных неизбежно почти при любом дальнейшем развитии событий.
Соединения с клиентами и устройствами хранения данных в кластерах
Для удобства управления необходимо, чтобы серверы, составляющие кластер VCS, были подключены к общей ЛВС и могли обращаться к одним и тем же устройствам хранения данных. Кластеры, в которых устройства хранения данных подключены к общей для узлов кластера SCSI-шине, как правило, включают в себя не более четырех серверов, потому что применяемая в SCSI-шине схема арбитража с фиксированным приоритетом обычно приводит к перегрузке (starvation) шины, если к ней подключено более четырех инициаторов операций ввода-вывода (серверов). Кроме того, SCSI-шина позволяет соединить между собой максимум 16 устройств (компьютеров, дисков, накопителей на магнитной ленте и RAIDмассивов). Подключение дополнительных серверов к кластеру с общей SCSI-шиной уменьшает количество адресуемых устройств хранения данных, то есть у кластера с общей SCSI-шиной имеется свойство, прямо противоположное масштабированию.
Сети хранения данных (SAN), построенные по технологии Fibre Channel (FC), позволяют частично устранить указанный недостаток общей SCSI-шины. Протокол Fibre Channel Arbitrated Loop позволяет подключить до 126 узлов (устройств с портами стандарта Fibre Channel), при этом допустимы любые комбинации компьютеров, подсистем и устройств хранения данных.
Теоретически протокол Switched Fabric позволяет соединить между собой 224 устройств (хотя на практике сети хранения данных, работающие по протоколу Switched Fabric, обычно соединяют между собой не более 200 устройств), что фактически решает такую проблему кластеризации, как подключение большого количества устройств хранения данных.
Устройства хранения данных для кластеров
В принципе для хранения данных кластера можно использовать любой тип устройств хранения, допускающих подключение к нескольким узлам, в том числе диски, подключаемые напрямую. Однако, целью кластеризации является обеспечение надежной и масштабируемой обработки данных. Поэтому для обеспечения максимальной доступности всей системы оптимальным является применение отказоустойчивых или высоко доступных подсистем хранения данных с несколькими путями доступа к узлам кластера. На практике большинство кластеров конфигурируют с использованием отказоустойчивых внешних RAID-массивов того или иного типа. Агенты VERITAS Cluster Server имеются для всех основных типов RAID-массивов.
Применение кластеров
Перенос выполнения приложений в случае отказа
Одним из самых важных применений кластерной технологии является повышение доступности прикладных сервисов. Прикладной сервис может выйти из строя вследствие отказа критически важного ресурса (например, прикладной программы, адаптера, соединяющего сервер с данными, и т. д.) или отказа сервера, на котором работает это приложение. Какова бы ни была причина отказа, демон HAD VCS, обнаружив его (по отсутствию отслеживаемых периодических контрольных сообщений группы ресурсов, составляющих сервис), инициирует процесс переноса выполнения приложения на другой сервер, т.е. запуск приложения на другом сервере.
Каскадный перенос выполнения приложений в случае отказа
По существу, при конфигурировании кластера VCS администратор составляет для каждого из прикладных сервисов упорядоченный список серверов, которым разрешается выполнять данный сервис. Так определяется каскадный перенос выполнения приложений в случае отказов. Если физическая конфигурация позволяет, то каждый из серверов кластера можно назначить в качестве разрешенного для данной группы сервисов. Пусть в кластере, изображенном на рис. 11, некоторый прикладной сервис S разрешено выполнять на серверах A, B и C (в указанном порядке серверов). Если сервер A работоспособен в момент запуска приложения S, оно выполняется на этом сервере. Если сервер A выйдет из строя, то VCS перезапустит группу ресурсов сервиса S на сервере B. Если сервер B выйдет из строя до того, как будет восстановлена работоспособность сервера A, то VCS перезапускает группу ресурсов сервиса S на сервере C. Если ни один из серверов A, B и C не работоспособен, приложение S не выполняется, поскольку сервер D не был указан в качестве разрешенного сервера для прикладного сервиса S.
Подключение устройств хранения данных и перенос выполнения приложений в случае отказа
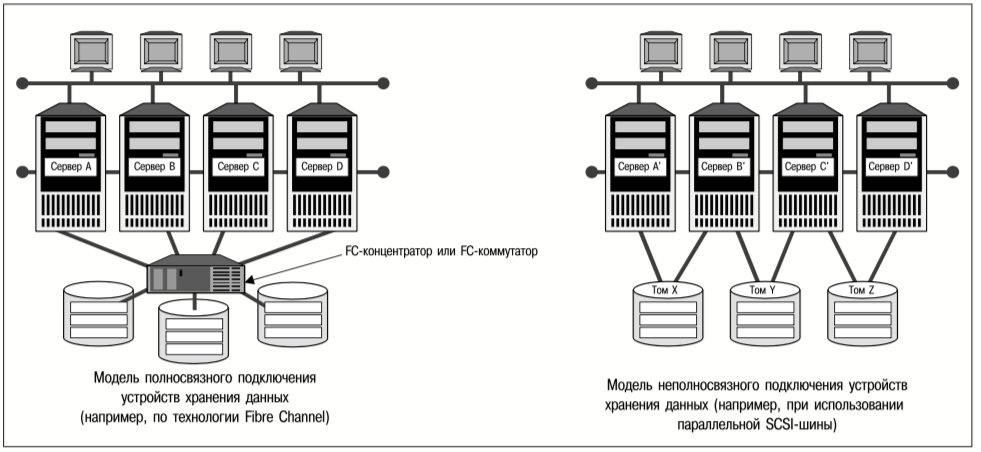
Для того, чтобы прикладной сервис мог выполняться на некотором сервере, последний должен иметь доступ ко всем ресурсам указанного сервиса. Ограниченный доступ к устройствам хранения данных и программному обеспечению приводит к ограничению выбора серверов, на которых могут выполняться те или иные сервисы. Устройства хранения данных могут не иметь прямых соединений со всеми серверами кластера. На рис. 11 приведены примеры неполносвязного и полносвязного (обеспечивается через SAN) подключения устройств хранения в кластере.
- При полносвязном подключении устройств хранения данных каждый сервер в кластере имеет прямые физические соединения со всеми устройствами хранения в этом кластере.
- При неполносвязном подключении устройств хранения данных не все серверы имеют прямые соединения со всеми устройствами хранения.
В аппаратной конфигурации с полносвязным подключением устройств хранения данных любой сервер кластера можно назначить в качестве альтернативного для любой группы прикладных сервисов. Так, в кластере, изображенном слева на рис. 11, выполнение прикладного сервиса, обычно запускаемого на сервере A, можно перенести в случае отказа на серверы B, С и D в указанном или любом другом порядке. В кластере же, изображенном справа на рис. 11, выполнение прикладного сервиса, обычно запускаемого на сервере A’, можно перенести в случае отказа на сервер B’, но не на другие серверы, потому что они не имеют доступа к данным и программному обеспечению этого сервиса.
Аналогично, выполнение прикладного сервиса, обычно запускаемого на сервере B’, можно перенести в случае отказа на сервер A’, при условии, что ресурсы этого сервиса используют только том X или зависят только от этого тома. Если же все ресурсы рассматриваемого сервиса используют только том Y или зависят только от этого тома, то выполнение сервиса в случае отказа можно перенести на сервер C’. Но если ресурсы данного прикладного сервиса используют как том X, так и том Y или зависят от обоих томов, то выполнение этого сервиса нельзя перенести на альтернативный сервер в случае отказа.
Этот пример показывает, насколько внимательным должен быть системный администратор при конфигурировании кластеров в тех случаях, когда имеющиеся аппаратные средства обеспечивают только неполносвязное подключение устройств хранения данных. Аппаратное решение, обеспечивающее полносвязное подключение устройств хранения данных (например, через SAN), гораздо предпочтительнее в связи с его гибкостью, управляемостью и возможностью расширения.
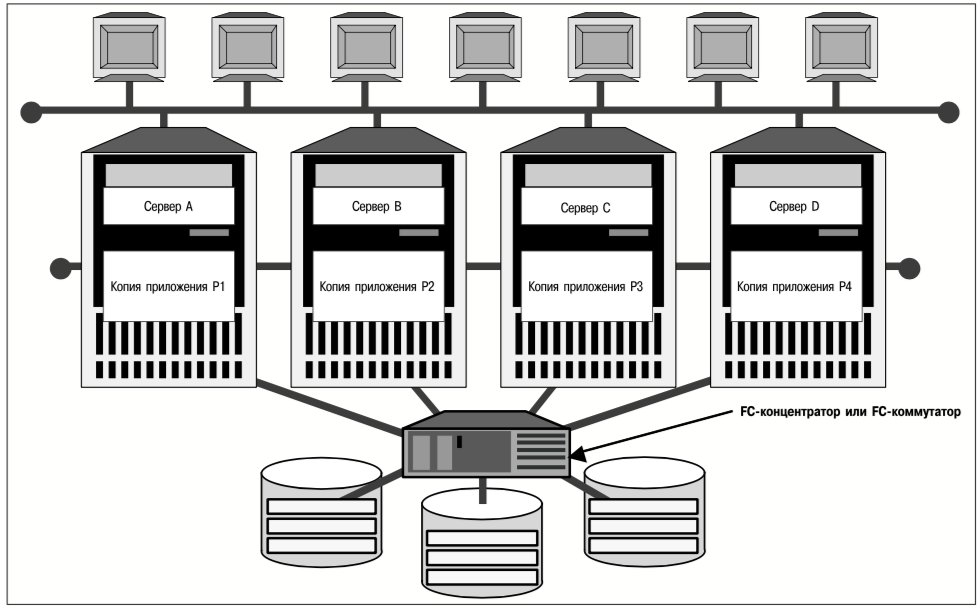
Масштабируемость приложений
Используя группы параллельных ресурсов сервиса, VCS может поддерживать одновременное выполнение прикладного сервиса на нескольких серверах. На рис. 12 представлен кластер, сконфигурированный для одновременного выполнения параллельного приложения на нескольких серверах.
Изображенный на рис. 12 кластер выполняет на каждом из своих четырех серверов копию прикладного сервиса P. Демон HAD распознает группы параллельных ресурсов сервиса и автоматически запускает все четыре копии приложения при инициализации кластера. Во многих реализациях технологии параллельных групп сервисов каждая копия приложения обрабатывает свою собственную копию данных, то есть не происходит совместное использование файловой системы или тома. Такой сценарий особенно популярен для масштабируемых Web-сервисов. Если же необходимо обеспечить совместное использование данных несколькими копиями приложения, как это подразумевается на рис. 12, то в самом приложении или в его менеджере данных должен быть предусмотрен механизм для исключения воздействий нескольких копий приложения друг на друга. Volume Manager и File System, компоненты пакета VERITAS SANPoint Foundation HA, предназначенные для работы в кластере, представляют собой один из таких механизмов. В последующих разделах рассматривается вопрос о совместном использовании данных в кластерах.
Модели данных кластера
Если ресурсы прикладного сервиса принадлежат к failover группе, то только серверу, на котором выполняется это приложение, предоставляется доступ к его данным. В случае отказа сервера и переноса выполнения этого приложения, управление его данными переходит к альтернативному серверу, но два или больше серверов никогда не получают доступ к одним и тем же данным одновременно. В сущности, многие технологии кластеризации не поддерживают одновременный доступ к данным. Для описания кластеров, в которых не поддерживается параллельный доступ к данным для нескольких серверов, часто используется термин «кластер без общих ресурсов» (shared-nothing cluster).
Недостатки кластеров без общих ресурсов
Возможности кластеров без общих ресурсов вполне достаточны для реализации переноса выполнения приложений с отказавшего на альтернативный сервер. Кроме того, как уже отмечалось выше, кластеры этого типа можно использовать для выполнения приложений, копиям которых не требуется одновременный доступ к одним и тем же данным (примером такого приложения является Web-сервис). Однако, существует гораздо более широкий класс приложений, которые обрабатывают транзакции посредством обновления файлов или баз данных. Поскольку эти приложения, в сущности, ведут записи, крайне важно, чтобы каждой копии такого приложения были доступны для чтения и записи одни и те же данные, благодаря чему все обновления немедленно становятся «видимыми» для любой из копий приложения. Для масштабирования подобных приложений с помощью кластерной технологии необходимо, чтобы кластер обеспечил нескольким серверам возможность одновременно монтировать одну и ту же файловую систему или открывать одну и ту же базу данных. Кроме того, необходимо, чтобы копии приложения, выполняемые на разных серверах такого кластера, могли читать и записывать данные в совместно используемой файловой системе или базе данных, но при этом была исключена возможность получения неправильных результатов из-за одновременного доступа нескольких копий приложения к этим данным.
Проблемы одновременного доступа к данным
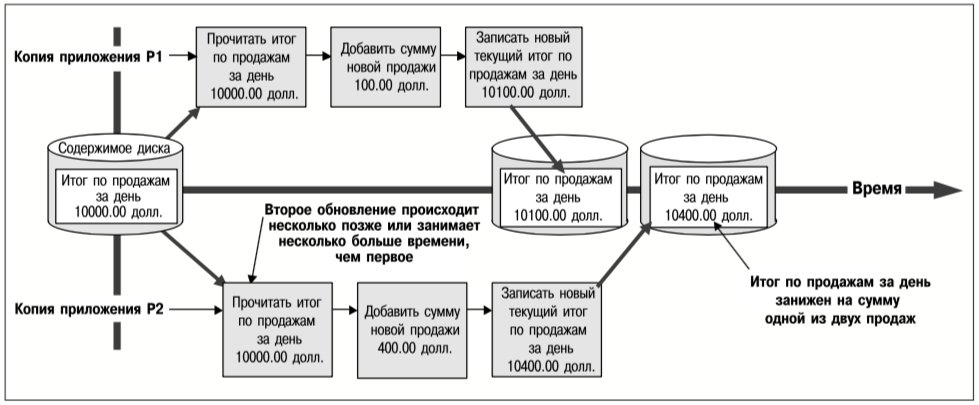
Некоординированный одновременный доступ к данным нескольких приложений может привести к различным видам искажения данных. Предположим, например, что приложение онлайновых продаж обновляет текущую итоговую сумму по операциям продаж за день. Всякий раз, когда осуществляется продажа, считывается текущий итог по продажам за день, к нему прибавляется сумма новой продажи и результат записывается обратно на устройство хранения данных. На рис. 13 представлен один из возможных сценариев, когда две и более копий этого приложения, работающих на разных серверах кластера, могут привести к искажению итоговой суммы продаж за день.
Проблема искажения данных, пример которой приведен на рис. 13, возникает из-за того, что копии приложения, запущенные на двух серверах, «не знают» о существовании друг друга. Когда копия P2 считывает итоговую сумму продаж за день, она не знает, что копия P1 уже прочитала это значение и поместила его в свой кэш с целью обновления. Чтобы обработка данных была корректной, последовательности операций чтение-изменение-перезапись, выполняемые каждой из копий приложения, должны быть неделимыми. Это означает, что каждая такая последовательность обновления должна выполняться как единое целое, т.е. во время ее выполнения над записью итоговой суммы по продажам за день не может быть выполнена ни одна не входящая в эту последовательность операция.
Если бы копии приложения, вносящие указанные изменения, выполнялись на одном и том же компьютере, то для корректной работы приложения потребовалась бы файловая система или СУБД, которые поддерживают одновременную работу нескольких программ записи. Такие менеджеры данных включают в себя менеджеры блокировок, которые временно запрещают доступ к группам байтов в файле или к записям в БД, чтобы предотвратить их одновременное обновление несколькими процессами.
Если процессы, представленные на рис. 13, выполняются на разных компьютерах, необходим распределенный менеджер блокировок. Тогда как локальный менеджер блокировок записывает информацию блокировки в структуры памяти, копии распределенного менеджера блокировок на каждом из совместно работающих компьютеров обмениваются между собой сообщениями о том, какие объекты данных заблокированы или разблокированы. Несколько копий файловой системы, работающих на отдельных компьютерах и использующих распределенный менеджер блокировок для координации обращений к данным, в совокупности называются распределенной или кластерной файловой системой. СУБД, подобные Oracle Parallel Server, поддерживают аналогичные функциональные возможности с помощью своих собственных распределенных менеджеров блокировок, специально предназначенных для блокировки объектов базы данных.
Управление данными с помощью пакета SANPoint Foundation HA
Volume Manager и File System, компоненты пакета VERITAS SANPoint Foundation HA, поддерживают одновременный доступ нескольких узлов кластера к объектам тома и файловой системы соответственно.
Еще раз об управлении томами
Как уже отмечалось раньше, том – это набор дисков под общим управлением, который файловыми системами и базами данных рассматривается как один или несколько дископодобных объектов, имеющих требуемые характеристики производительности ввода-вывода и доступности. Volume Manager выполняет две функции:
- Преобразует каждый запрос на чтение или запись данных тома в одну или несколько команд ввода-вывода диска, выдает эти команды и управляет результирующим потоком данных.
- Реализует алгоритмы зеркалирования или RAID-технологий, что позволяет защитить данные от потери при отказе диска.
Volume Manager не ограничивает доступ к области тома, содержащей пользовательские данные. Любому приложению или менеджеру данных, которые могут получить от операционной системы право на доступ к тому, разрешается считывать или записывать любой блок в области пользовательских данных этого тома. Собственно, Volume Manager обеспечивает сопровождение каждой операции записи на том всеми необходимыми командами ввода-вывода, чтобы поддержать отказоустойчивость тома (например, каждая запись данных на зеркалированный том преобразуется в команду записи на каждый из дисков тома), а также сохранить непротиворечивость состояния тома – составляющих его дисков или их частей.
Управление томами на одном сервере
В системе с единственным сервером через Volume Manager проходит каждый запрос на вводвывод и каждая операция управления. Это позволяет Volume Manager поддерживать целостность томов, например, путем обеспечения обработки запросов на чтение и запись в перекрывающиеся области блоков в таком порядке, который сохраняет дископодобную семантику. Приведем другой пример. Когда администратор дает команду увеличить объем тома, Volume Manager выделяет дополнительные устройства хранения и обновляет избыточные структуры данных на дисках, которые описывают том таким образом, что его можно восстановить после выхода системы из строя. Благодаря этому обеспечивается непротиворечивость тома в каждый момент выполнения команды его расширения.
Управление томами в кластерах
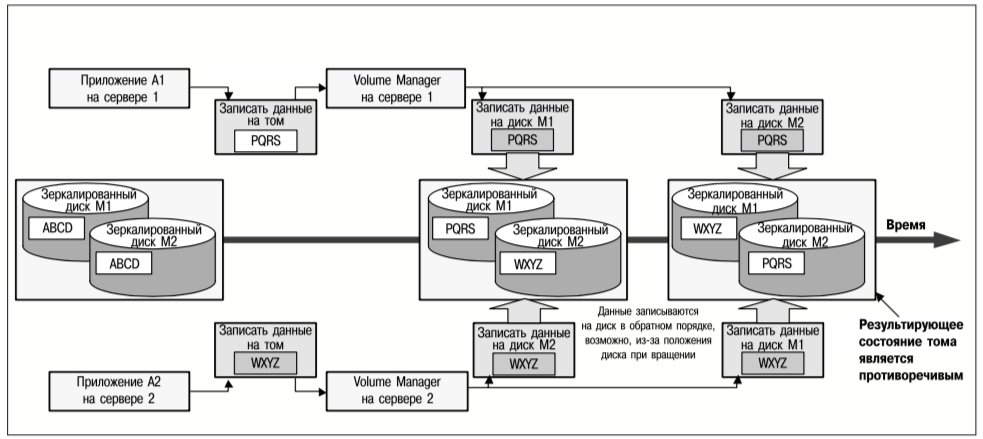
Когда том становится доступным для нескольких серверов, входящих в состав кластера, необходимо сохранить указанную непротиворечивость. Так, например, когда два приложения дают некоординированные команды записи данных на перекрывающиеся области блоков тома, любая из них может выполниться первой, как и в случае диска, но том должен всегда отражать результат операций записи, как это бы сделал диск. Недопустимо, чтобы зеркалированный том стал внутренне противоречивым из-за того, что операции записи на составляющие его диски выполняются в различном порядке, как показано на рис. 14.
На рис. 14 представлены операции записи данных двух приложений, запущенных на отдельных серверах кластера, в одну и ту же область блоков зеркалированного тома. Копия Volume Manager на каждом сервере преобразует команды записи на том в команды записи на каждый из составляющих его дисков. Если обе копии Volume Manager не будут координировать свои действия, то порядок выполнения команд записи на диск может привести к тому, что содержимое тома станет противоречивым.
Аналогично, если два сервера пытаются изменить конфигурацию тома (например, увеличить его объем), то необходимо тщательно координировать обновления метаданных на дисках, чтобы ситуации, подобные изображенным на рис. 13 и 14, не возникли с метаданными тома.
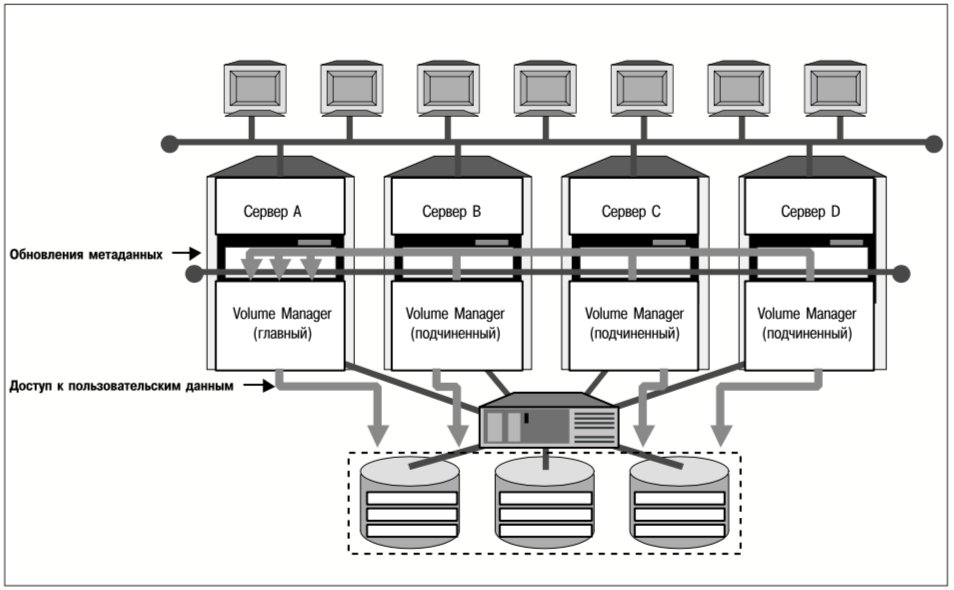
Volume Manager, входящий в состав пакета VERITAS SANPoint Foundation HA, использует архитектуру «главный-подчиненный» (master-slave) для решения указанной проблемы и обеспечения согласованного доступа к онлайн-томам для всех серверов кластера, как показано на рис. 15.
В кластере, где работает пакет SANPoint Foundation HA, один из серверов назначается главным для каждой из групп кластерных томов (набора дисков, управляемых Volume Manager как единое целое). Изменение метаданных тома можно инициировать с любого сервера, но все такие изменения выполняются копией Volume Manager на главном сервере соответствующей группы томов. Главный сервер блокирует доступ к группе томов всякий раз, когда необходимо обновить метаданные, поэтому все серверы из данного кластера обрабатывают запросы на доступ к пользовательским данным, всегда используя одинаковый образ метаданных тома.
Разумеется, главная копия Volume Manager может стать единственной точкой отказа, если сервер, на котором она запущена, выйдет из строя. Если это произойдет в кластере, где работает пакет SANPoint Foundation HA, то подчиненные копии Volume Manager согласуют между собой назначение нового главного сервера, и работа возобновится с меньшим количеством серверов. В настоящее время Volume Manager пакета SANPoint Foundation HA поддерживает до четырех серверов в кластере, а в будущем планируется реализация более крупных конфигураций.
Кластерная файловая система пакета SANPoint Foundation HA
Проблемы, связанные с доступом нескольких серверов к одной файловой системе, совершенно аналогичны проблемам диспетчера томов. Обновления метаданных необходимо координировать, чтобы все серверы из кластера имели непротиворечивое представление о файловой системе. При этом необходимо обеспечить семантику чтения и записи данных, как у файловой системы, на одном сервере. Подобно Volume Manager, программный продукт File System, входящий в состав пакета SANPoint Foundation HA, использует архитектуру «главныйподчиненный», обеспечивая непротиворечивое представление о файлах максимум для четырех кластерных серверов.
В типичной системе метаданные файловой системы изменяются гораздо чаще, чем метаданные тома. В кластере, где работает пакет SANPoint Foundation HA, приложения, выполняемые на любом сервере, могут создавать, расширять и удалять файлы и каталоги. Фактические обновления метаданных на дисках, представляющие собой выполнение указанных запросов, производятся главной копией File System. Все подчиненные копии File System используют внутренние кластерные соединения для передачи своих запросов на обновление метаданных главной копии, которая их и выполняет. Таким образом, гарантируется целостность метаданных файловой системы.
Файловые системы должны также воспроизводить дископодобную семантику при записи пользовательских данных. В кластерной среде это означает, что если одновременные запросы на запись данных, поступающие от двух серверов, изменяют перекрывающиеся области блоков, результат после их выполнения будет отражать запрос любого из серверов, но может не отражать некоторые части обоих запросов. Фактически это означает, что если сервер записывает данные в область блоков, она должна быть заблокирована на время выполнения операции записи. Пакет SANPoint Foundation HA включает в себя менеджер блокировок, который позволяет копиям File System, работающим на разных серверах, блокировать доступ к областям блоков тома, поэтому копии File System могут сохранять такую же семантику записи данных, как файловые системы на одном сервере.
Важное отличие файловой системы от диспетчера томов состоит в том, что в файловой системе производительность операций ввода-вывода частично обеспечивается за счет кэширования данных в памяти сервера; данные помещаются в кэш либо потому, что они могут потребоваться в будущем, либо просто для оптимизации выполнения операций ввода-вывода. В кластерной среде это создает проблему обеспечения согласованности – предоставление одного и того же образа данных файловой системы всем серверам кластера. Например, если в кэше сервера A имеется блок файловых данных, а сервер B обновляет этот блок на диске, то содержимое кэша сервера A становится недействительным. Сервер A должен каким-либо образом «узнать» о том, что если ему необходимо предоставить указанный блок данных приложению, то следует взять с диска новое содержимое блока, поскольку образ в кэше уже недействителен.
Для решения проблемы обеспечения согласованности кэша используется механизм менеджера блокировок пакета SANPoint Foundation HA. Когда один из серверов рассылает сообщение о своем намерении заблокировать какой-либо блок для обновления, другие серверы кластера, имеющие копии указанного блока в своем кэше, на основании этого сообщения признают свои копии недействительными и берут обновленные данные с диска, если необходимо предоставить их приложениям.
Важность кластеров серверов, совместно использующих данные
Диспетчеры томов и файловые системы, предназначенные для работы в кластере, значительно расширяют область применения кластерной технологии к проблемам информационных технологий (ИТ), для решения которых ресурсов одного сервера недостаточно. В принципе возможно реализовать параллельные прикладные сервисы без обеспечения доступа кластерных серверов к одним и тем же данным и устройствам их хранения. Однако, такие приложения либо по своей природе не должны требовать доступа к одним и тем же данным (например, Web-серверы «только для чтения»), либо должны быть разработаны так, чтобы каждая копия приложения обновляла свои собственные копии данных, причем действия приложений необходимо периодически согласовывать. Очевидно, что приложения «только для чтения» позволяют решить лишь ограниченный класс проблем, стоящих перед предприятием; а приложения, которые должны периодически согласовывать свои базы данных, по своей сути не являются постоянно доступными.
Предназначенные для работы в кластере диспетчеры томов и файловые системы, подобные тем, что входят в состав пакета SANPoint Foundation HA, решают указанную проблему. Эти компоненты дают возможность нескольким копиям приложения иметь одновременный доступ к одним и тем же объектам данных, что позволяет широкому классу традиционных приложений обработки транзакций, составляющих большинство средств обработки информации, работать на уровне производительности, превышающем производительность отдельного сервера.
Масштабируемость и доступность
Кроме того, кластер, позволяющий масштабировать приложения посредством выполнения нескольких их копий на разных серверах, можно сконфигурировать таким образом, чтобы обеспечить высокую доступность этих приложений. Хотя группы параллельных ресурсов не перезапускаются на альтернативных серверах подобно failover группам ресурсов, постоянный доступ приложений можно обеспечить просто посредством перенаправления клиентских запросов на альтернативную копию приложения. Клиентские запросы часто направляются аппаратными или программными средствами распределения нагрузки, такими, как Network Load Balancer (NLB) компании Microsoft для Windows-серверов или маршрутизатор распределения нагрузки Local Director компании Cisco. Если средство распределения нагрузки установлено, в случае отказа одного из серверов приложений клиентские запросы распределяются между остальными серверами кластера.
Кластеры и сети хранения данных
Как уже отмечалось выше, кластеры являются наиболее гибкими и управляемыми в том случае, если их устройства хранения подключены к сети хранения данных (SAN), которая обеспечивает полносвязное и прямое соединение устройств хранения данных с серверами, входящими в кластер. Соединяя все серверы кластера со всеми устройствами хранения данных, SAN повышает гибкость кластеров, позволяет реализовать параллельное выполнение групп прикладных сервисов и делает возможным каскадный перенос выполнения приложений на альтернативные серверы в случае отказа (см. выше) для обеспечения их сверхвысокой доступности.
Возможности SAN
На многих предприятиях SAN охватывает все устройства хранения, имеющиеся в центре обработки данных. В таких центрах несколько кластеров серверов можно подключить к общему пулу устройств хранения данных. На рис. 16 представлен центр обработки данных, в котором кластеры P и Q, включающие в себя по два сервера, соединены с общим пулом устройств хранения данных, через SAN.
Возможность установить соединения между всеми устройствами хранения в центре обработки данных позволяет с помощью простых операций управления использовать ресурсы устройств хранения данных в любом месте, где они необходимы. Когда все устройства хранения физически соединены со всеми серверами, имеющимися в центре обработки данных, избыточную емкость запоминающих устройств на одном сервере или в одном кластере можно предоставить для использования другому серверу или кластеру, не проводя физического реконфигурирования устройств. Большинство операционных систем поддерживают такое перемещение и в тех случаях, когда соответствующие серверы находятся в режиме онлайн, т.е. для использования только что выделенных ресурсов не требуется перезагрузка серверов. Вместо применения пула устройств хранения данных переполнения (an overflow storage pool) для каждого сервера, который позволяет удовлетворить экстренные потребности сервера в дисковой памяти, можно использовать единый пул, который способен удовлетворить потребности целого центра обработки данных. Чем больше центр обработки данных, тем больше экономия ресурсов.
Технические проблемы SAN
Хотя SAN значительно повышает гибкость устройств хранения данных и позволяет существенно сократить капитальные затраты, для использования её возможностей в полном объеме необходимо решить определенные технические проблемы. В современных концепциях разработки операционных систем устройства хранения рассматриваются как «легко обнаруживаемые» периферийные устройства, управляемые сервером, к которому они подключены. Реализация в современных операционных системах таких принципов, как:
- сетеподобное соединение устройств хранения данных, при котором огромное адресное пространство делает задачу обнаружения устройств хранения нетривиальной для операционных систем;
- динамический переход управления устройствами хранения от одного сервера к другому в большинстве случаев является достаточно сложной задачей.
Управление SAN
К настоящему времени разработчики и производители устройств хранения данных и средств для объединения их в сеть нашли решение проблем, связанных с обнаружением устройств хранения и управлением ими. Разработчики подсистем хранения данных обеспечивают в своих продуктах возможность маскирования логических номеров устройств (LUN), что позволяет связать диски и массивы с путя-
ми доступа к конкретным серверам. Разработчики инфраструктуры SAN встраивают в свои продукты средства разбиения SAN на «зоны», что предотвращает получение доступа к устройствам хранения одного сервера или кластера другим сервером. Операции управления позволяют изменить связи между устройствами хранения и серверами, а также перемещать устройства из одной зоны в другую.
Ограничения покомпонентного управления SAN
Средства управления компонентами SAN позволяют в определенной мере реализовать потенциальные возможности SAN, но у таких средств имеется следующий недостаток: поскольку они разрабатываются и предоставляются производителями компонентов, то, как правило, предназначены для компонентов, выпускаемых именно этим производителем. Так, средства управления от производителя коммутаторов стандарта Fibre Channel обычно позволяют управлять коммутаторами только этого производителя, но не другими устройствами такого типа. Эта ситуация противоречит современной открытой концепции разработки технологии SAN.
Еще один недостаток – пользовательские интерфейсы, которыми каждый производитель комплектует свои средства управления компонентами SAN. Хотя такие интерфейсы, как правило, оптимальны для конкретных продуктов данного поставщика, с точки зрения пользователя каждый дополнительный интерфейс для управления компонентами означает, что необходимо установить, освоить и поддерживать еще один программный продукт. Пользователи заинтересованы в том, чтобы отдельных средств управления компонентами было как можно меньше, и чтобы они были единообразными.
Программный пакет VERITAS SANPoint Control
Приняв во внимание возможности, которые открывает использование SAN в крупных центрах обработки данных, компания VERITAS разработала архитектуру «шина управления» («management bus»), позволяющую управлять разнообразными компонентами SAN с помощью ряда средств управления. Такая архитектура лежит в основе программного продукта VERITAS SANPoint Control, который представляет собой пакет средств управления SAN. В настоящее время в пакет SANPoint Control включены средства для обнаружения устройств хранения данных и адаптеров, а также для разбиения SAN на зоны. Перечисленные средства предназначены для инфраструктур SAN, состоящих из соединенных между собой коммутаторов, выпущенных любым крупным производителем этого аппаратного обеспечения. FC-адаптеры и RAIDмассивы в ближайшем будущем тоже войдут в число элементов SAN, которыми можно управлять с помощью пакета SANPoint Control.
Пакет SANPoint Control включает в себя абстрактные модели для каждого типа управляемых им устройств. Эти модели адаптируются в соответствии с возможностями конкретных устройств; адаптацию выполняют программные модули, называемые провайдерами (providers), которые устанавливают соответствие между функциональностью для управления устройствами и абстрактными моделями SANPoint Control. Провайдеры реализуются компанией VERITAS самостоятельно или при участии производителей компонентов SAN, что позволяет максимально ускорить выпуск на рынок этих программных модулей и максимально расширить круг адаптируемых ими устройств.
Глобальные кластеры и восстановление после аварий
Электронный бизнес приобретает глобальный характер в своей сфере деятельности гораздо быстрее, чем традиционный. По мере глобализации бизнеса задача обеспечения постоянной доступности становится еще более сложной:
- Высокая доступность приложений, которую обеспечивают кластеры, недостаточна: в случае аварии масштаба предприятия и выхода из строя целого кластера высока вероятность того, что окажется невозможным восстановить функционирование предприятия электронного бизнеса.
- Если на предприятии вся деятельность по обработке данных сосредоточена в единственном центре обработки данных, то некоторые из клиентов такого предприятия неизбежно окажутся «далеко» от приложений в смысле времени прохождения сообщений, что приведет к увеличению времени отклика на запросы подобных клиентов и уязвимости предприятия перед «локальными» конкурентами.
- Управление глобальными процессами обработки информации может стать чрезмерно дорогостоящим, а в быстро изменяющейся среде электронного бизнеса – совершенно невозможным.
Управление глобальными кластерами
Компания VERITAS объединила технологию кластеризации VCS, средства репликации данных и мощный инструментарий управления в программном продукте Global Cluster Manager (GCM), который позволяет решить перечисленные выше проблемы глобальной обработки информации.
GCM группирует кластеры VCS в сайты (sites) и устанавливает связи между ними с помощью средств администрирования, в результате создается глобальный вычислительный ресурс, управляемый из единого центра. GCM состоит из следующих компонентов:
- Механизм определения кластерных событий, которые автоматически инициируют заданную политику глобального управления, например, перемещение выполнения группы прикладных сервисов с одного кластера на другой в случае аварии.
- Гибкая схема проверки состояния, позволяющая администраторам использовать встроенный механизм обмена контрольными сообщениями для проверки состояния системы или определять собственные механизмы обмена сообщениями, которые лучше соответствуют различным конфигурациям и приложениям.
- Агент сервера доменных имен (DNS), который позволяет установить соответствие между символическими сетевыми именами и IP-адресами в различных подсетях, что обеспечивает возможность глобального переноса выполнения сервисов на другие серверы в случае отказа.
- Интерфейс управления на основе Web-навигатора, который позволяет осуществлять глобальное управление системой из любой точки сети.
На рис. 17 изображены два сайта, обозначенные как Сайт I и Сайт II. Сайт GCM представляет собой набор соединенных между собой кластеров, причем по крайней мере один из этих кластеров является для данного сайта главным (site master); весь набор кластеров (сайт) подключен к остальной части глобальной системы кластеров. Программное обеспечение главного кластера сайта GCM можно сконфигурировать как группу прикладных сервисов VCS таким образом, чтобы отказы серверов обнаруживались и обрабатывались локально с помощью средств, предусмотренных в VCS. На рис. 17 сервер C-2 кластера C является главным для Сайта I, а сервер E-2 – главным для Сайта II. В глобальной системе кластеров информация о VCS-копиях на сайте передается через главный сервер.
Один из главных серверов (тот, имя которого является первым при сортировке) определяется как глобальный главный сервер. Глобальный главный сервер VCS – это единственный сервер, который дает команды GCM, предотвращая тем самым избыточные команды в глобальных сетях, где время задержки изменяется в весьма широких пределах. Если глобальный главный сервер VCS выйдет из строя, то остальные серверы автоматически согласовывают назначение альтернативного главного сервера, что позволяет восстановить работоспособность VCS после отказов.
Каждый из кластеров VCS, входящий в состав глобальной системы кластеров GCM, работает в соответствии с обычной VCS-политикой проверки состояния и аварийного переноса выполнения приложений, которая определяется администраторами VCS. Политика GCM является надстройкой над политикой VCS, что позволяет реализовать:
- Удаленное управление кластерами, благодаря чему с одной консоли можно управлять разбросанными по всему миру кластерами, между которыми установлены соединения.
- Обмен контрольными сообщениями между сайтами с помощью механизма «ping», который встроен в программный продукт GCM, или других механизмов, соответствующих сетевым средствам или приложениям, благодаря чему можно обнаружить выход из строя целого сайта.
- Управляемую событиями политику, благодаря чему можно перемещать группы прикладных сервисов между кластерами или сайтами, чтобы обеспечить как восстановление приложений после аварий, так и плановое перемещение выполнения приложений в соответствии с определенным графиком.
Применение Global Cluster Manager для восстановления систем после аварий
В сочетании со средствами репликации данных глобальная кластерная система GCM позволяет автоматически восстанавливать сайты после аварий. На рис. 18 представлен сценарий восстановления систем после аварии, в котором сочетаются репликация данных и глобальная кластеризация.
Изображенные на рис. 18 кластеры P и Q находятся далеко друг от друга. Данные из тома X кластера P реплицируются на том Y кластера Q через глобальную вычислительную сеть. Группа прикладных сервисов P1 может выполняться на любом из серверов кластера P, а в случае отказа этого сервера их выполнение можно перенести с помощью механизмов VCS на любой другой сервер этого кластера.
Аналогично, группа прикладных сервисов Q1 может выполняться на любом из серверов кластера Q, а в случае отказа этого сервера их выполнение можно перенести с помощью механизмов VCS на любой другой сервер этого кластера. Приложение Q1 может состоять из следующих компонентов:
- сценарий для остановки репликации, отключения тома Y как вспомогательной реплики данных и его повторного монтирования как локального тома чтения/записи для использования приложением;
- сценарий или программа для проверки целостности всех используемых приложением данных, которую необходимо провести до того, как можно будет перезапустить образы приложения P1;
- файлы программ, используемые прикладным сервисом P1.
Оба рассмотренных VCS-кластера входят в состав глобальной кластерной системы GCM. Главные серверы сайтов обмениваются между собой периодическими контрольными сообщениями для проверки состояния GCM-кластера. (Независимо от этого в каждом из кластеров его серверы обмениваются между собой контрольными сообщения для проверки состояния данного VCS-кластера). Механизмы GCM начинают действовать тогда, когда происходит сбой в обмене контрольными GCMсообщениями между двумя сайтами, что указывает на отказ всего сайта. В этом случае в соответствии с заданной политикой GCM начнется выполнение группы прикладных сервисов Q1. Агент DNS GCM вступает во взаимодействие с DNS-сервером сети, чтобы переназначить доменные имена приложения IP-адресам кластера Q.
Для оптимизации использования ресурсов обычно применяются схемы взаимного переноса выполнения приложений на альтернативные серверы в случае отказа, подобные описанной выше (глава о репликации, раздел «Взаимное восстановление данных после аварий»).
«Следуя за Солнцем»
В глобальном электронном бизнесе пик активности перемещается по регионам циклически, в соответствии с наступлением рабочих часов в данном регионе. Когда рабочий день заканчивается в Нью-Йорке, в Калифорнии – вторая половина дня. Когда работа прекращается в Калифорнии, в Азии только начинается очередной рабочий день. Выяснилось, что электронный бизнес наиболее эффективен в тех случаях, когда информация обрабатывается «недалеко» от клиента в смысле времени передачи данных по сети. Электронный бизнес сталкивается со следующей проблемой: как поддерживать единое согласованное глобальное хранилище информации в режиме онлайн, обеспечивая при этом обработку «максимально близко» к клиентам, которые наиболее активны в данный момент?
Использование программного продукта GCM в сочетании с репликацией данных дает ответ на этот вопрос. Те же механизмы, которые используются для реализации вышеописанного сценария автоматического восстановления систем после аварий, можно настроить посредством политики так, чтобы они приводились в действие в назначенный момент времени. В результате, основное место обработки данных будет перемещаться по расположенным в различных часовых поясах центрам данных предприятия, как бы «следуя за Солнцем». Когда тот или иной сайт берет на себя обработку данных приложений, он реконфигурирует процесс репликации. При этом он становится основным («исходным») центром обработки данных, а другие центры – резервными («целевыми») центрами обработки данных. Таким образом, при условии кратковременных простоев для перезапуска приложения и реконфигурирования репликации, обработка данных глобального электронного бизнеса может перемещаться по центрам обработки данных, которые находятся в различных регионах.
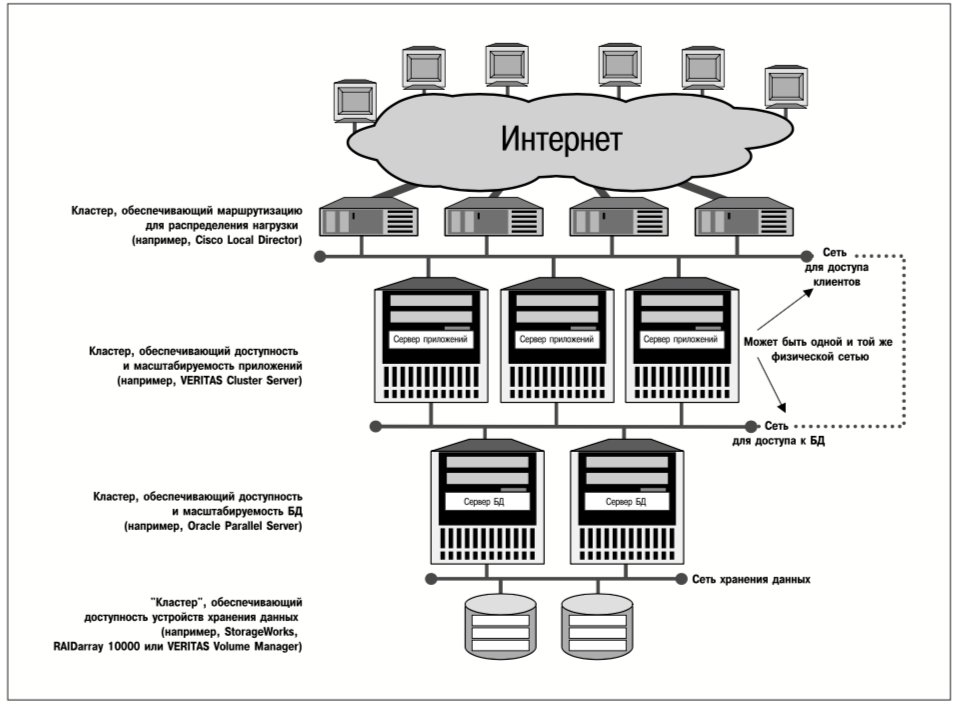
Кластеризация в контексте информационных систем электронного бизнеса
Требования доступности и масштабируемости, предъявляемые электронным бизнесом, привели к разработке широкого спектра решений. В большинстве этих решений в той или иной форме применяется технология кластеризации, и почти все крупные системы электронного бизнеса пользуются преимуществами кластеризации на нескольких уровнях. На рис. 19 представлена система с кластеризацией на трех уровнях (хотя в принципе в ней можно выделить и четыре уровня).
Запросы клиентов, поступающие в систему, представленную на рис. 19, принимаются группой взаимодействующих сетевых маршрутизаторов, которые используют технологию распределения нагрузки для распределения запросов между несколькими одинаковыми серверами приложений. Технология маршрутизации для распределения нагрузки также обеспечивает возможность переназначения сетевого адреса в случае отказа маршрутизатора.
Как видно из рис. 19, на прикладном уровне параллельные группы VCS-сервисов обеспечивают масштабируемость приложений, т.е. выполнение их на нескольких серверах. Если сервер приложения выходит из строя, то в соответствии с технологией распределения нагрузки его рабочая нагрузка перераспределяется между оставшимися серверами. С помощью технологии SANPoint Foundation HA (она описана в разделе «Управление данными с помощью пакета SANPoint Foundation HA») серверы приложений могут координировать доступ приложений к одной или нескольким общим файловым системам.
Альтернативой является координация совместного доступа к данным на третьем уровне иерархии обработки данных (т.е. на уровне серверов баз данных), например, с помощью Oracle Parallel Server. Копии Oracle Parallel Server фактически образуют кластер, координирующий обработку запросов на доступ к данным, которые поступают из различных источников (от кластера серверов приложений), несколькими серверами баз данных, что гарантирует непротиворечивость базы данных.
Наконец, в системах такого масштаба и сложности наличие отказоустойчивых масштабируемых подсистем хранения данных обычно рассматривается как необходимость. Для таких подсистем характерны сложное координирование операций ввода-вывода, наличие зеркалированного кэша, а также средств повышения производительности оборудования и переключения контроллеров в случае отказа. Поэтому целесообразно рассматривать эти подсистемы как кластеры устройств хранения данных. При условии подключения к сети SAN и в сочетании с централизованным управлением томами и технологией репликации данных, отказоустойчивые подсистемы хранения данных обеспечивают надежную и масштабируемую среду хранения данных.
Системы, подобные изображенной на рис. 19, являются сложными, однако, они обеспечивают именно ту масштабируемую и высокодоступную обработку данных в среде «клиент – сервер», которая критически важна для электронного бизнеса при его переходе из начальной стадии в стадию предприятия глобального масштаба.
Защита данных
Эффективная защита информационных ресурсов
Защита данных предприятия
Поскольку онлайновые данные являются основным ресурсом электронного бизнеса, они должны быть защищены от потери или разрушения, что бы ни случилось. Предприятия защищают свои данные для того, чтобы:
- максимально быстро возобновлять функционирование после отказа сервера, приложения, устройства хранения, программного обеспечения или центра обработки данных, а также в случае ошибок при эксплуатации;
- данные можно было перемещать туда, где они нужны и тогда, когда они нужны предприятию;
- были удовлетворены нормативные требования и требования политики предприятия к сохранению записей.
Как уже подчеркивалось, главная цель ИТподразделений предприятия состоит в обеспечении доступности онлайновых данных для партнеров. Поэтому защита данных в контексте электронного бизнеса означает достижение вышеуказанных целей в среде онлайновых баз данных, работающих по схеме 24х7.
Сущность защиты данных
По существу, защита данных состоит в создании копий критически важных объектов данных:
- создании резервных и архивных копий онлайновых БД, а также вспомогательных данных, хранимых в файловых системах (например, HTMLфайлов, сценариев, файлов программ и т. д.);
- перемещении электронных архивов из центров обработки данных в защищенные хранилища;
- репликации данных из мест их создания в места их использования;
- перемещении данных из мест, где они использу-ются реже, в места, где они используются чаще; и т. д.
За кажущейся простотой операции копирования объектов данных стоят серьезные технические задачи:
- разработка и реализация политики, позволяющей перемещать данные туда, где они нужны и тогда, когда они нужны, даже в случае возникновения ошибок и отказов;
- слежение за местонахождением данных, например, отслеживание того, на каких лентах размещены те или иные резервные копии и где находятся эти ленты;
- гарантирование внутренней непротиворечивости наборов объектов данных при их копировании;
- минимизация времени простоя сервиса, когда объекты данных недоступны для приложений в связи с их копированием;
- определение момента, когда изменения политики управления принесут пользу, например, когда создание резервных копий следует делать чаще, или когда копии рабочих данных следует реплицировать в региональные офисы, чтобы уменьшить сетевой трафик.
Предлагаемые компанией VERITAS технологии резервного копирования, управления иерархической памятью (HSM) и оптимизации системы хранения помогают ИТ-подразделениям предприятия решить перечисленные выше проблемы защиты данных.
Резервное копирование – основа защиты данных
Главным в любой архитектуре защиты данных является резервное копирование (РК). Резервная копия представляет собой копию определенного набора данных, в идеальном случае резервная копия полностью соответствует состоянию оригинала в данный момент времени. (Существуют методы «нечеткого» (fuzzy) резервного копирования файлов и баз данных, когда создаются копии изменяющихся данных с ограниченными гарантиями актуальности и непротиворечивости. Такие копии можно использовать для восстановления БД после отказов, но их применение в качестве долговременных записей бизнес-операций ограничено). В хорошо налаженной информационной системе резервные копии хранятся отдельно от соответствующих рабочих данных, обычно на магнитных лентах или других съемных носителях информации. Поэтому они могут уцелеть в случае разрушения или повреждения рабочих БД. Резервные копии можно:
- Хранить в центре обработки данных, поэтому если выход из строя устройства хранения, системы или приложения или ошибка при эксплуатации приведут к разрушению критически важных онлайновых данных, предприятие сможет восстановить свои рабочие записи со сравнительно недавнего момента времени. Имея копию на тот момент, можно с помощью журналов баз данных восстановить (практически) последнее состояние рабочих данных.
- Перемещать в одно или несколько альтернативных мест, чтобы обеспечить аналогичную защиту данных от различных аварий, которые могут вывести из строя целый центр данных. Имея актуальные резервные копии своих рабочих баз данных, предприятие сможет возобновить свою работу почти сразу после того, как станут доступными альтернативные вычислительные ресурсы.
- Сделать неизменяемыми (например, скопировать на СD-ROM), чтобы обеспечить долговременное хранение рабочих записей в соответствии с нормативными требованиями и требованиями политики предприятия, когда какие-либо данные больше не требуются в режиме онлайн.
Кажущаяся простота резервного копирования
По своей сути резервное копирование – это простая операция. Системный администратор решает, какие данные критически важны для работы предприятия, составляет расписание, согласно которому резервные копии можно создать с минимальным воздействием на выполнение информационных сервисов, и использует программу-утилиту резервного копирования для создания копий. Резервные копии хранятся в безопасном месте, чтобы ими можно было воспользоваться, когда потребуется восстановить данные после аварии. Таким образом, принцип резервного копирования действительно прост. Трудности заключаются в деталях:
- Определенное количество серверов. В крупных центрах обработки данных системные администраторы должны создавать резервные копии данных с большого количества серверов различных типов. Это требует выполнения и контроля большого объема работ, а также определенных навыков и опыта, специфических для каждой из используемых платформ.
- Надежное выполнение. Системные администраторы должны обеспечить реальное создание резервных копий. В сложном и загруженном центре обработки данных рабочие перегрузки могут сделать эту задачу более сложной, чем она кажется, потому что потребность в резервной копии не возникает до тех пор, пока не случится какая-либо авария. Загруженные работой системные операторы иногда пренебрегают задачами, которые не требуют немедленного решения.
- Ошибки из-за неправильного обращения с носителями информации. По мере развития предприятия количество магнитных лент или других носителей резервных копий неизбежно увеличивается. Резервные копии могут быть разрушены, утеряны или перезаписаны, особенно в тех случаях, когда с ними работают люди.
- Выполнение в условиях стресса. Ситуация, когда из-за потери онлайновых данных требуется восстановление с резервной копии, всегда является стрессовой. Когда нечасто применяемые процедуры восстановления выполняются в условиях спешки и стресса, чтобы как можно скорее вернуть приложения в режим онлайн, вполне возможно неправильно истолковать инструкции, загрузить не тот носитель или отменить защитные меры, а в результате восстановление данных чрезмерно затягивается или даже ока-зывается невозможным.
Технология резервного копирования, используемая в программном продукте VERITAS Database Edition for Oracle, называется NetBackup. Помимо минимизации воздействия резервного копирования на выполнение обычных информационных сервисов, NetBackup обеспечивает защиту от процедурных ошибок, которые могут снизить функциональную надежность резервного копирования.
Компоненты архитектуры резервного копирования данных предприятия
Чтобы понять предлагаемую компанией VERITAS технологию резервного копирования, целесообразно разделить этот процесс на основные функциональные элементы. На рис. 20 показана функциональная архитектура резервного копирования данных предприятия.
На рис. 20 представлены четыре основных функциональных компонента системы резервного копирования данных предприятия:
- Клиент системы резервного копирования (называемый также просто клиентом): компьютерная система, данные из которой подлежат резервному копированию. Этот термин может вызвать путаницу, потому что клиентами резервного копирования обычно являются файловые серверы, а также серверы приложений и баз данных. Термин «клиент резервного копирования» также используется для обозначения программного компонента, который считывает данные из онлайновых устройств хранения и отправляет их на сервер резервного копирования (см. ниже).
- Серверы резервного копирования (называемые также просто серверами): системы, которые копируют данные и регистрируют выполненные операции. По технологии компании VERITAS серверы резервного копирования подразделяются на два типа:
- Сервер управления системой резервного копирования (Master-сервер) планирует операции резервного копирования и восстановления, а также ведет каталог резервных копий. Программный компонент сервера управления резервным копированием, выполняющий эти функции, называется менеджером резервного копирования.
- Сервер копирования резервируемых данных (Media-сервер) копирует данные по командам Master-сервера. К серверам копирования резервируемых данных подключаются устройства хранения резервных копий (см. ниже).
- Устройства хранения резервных копий (называемые также просто устройствами хранения): накопители на лентах, магнитные или оптические диски, управляемые Media-сервером.
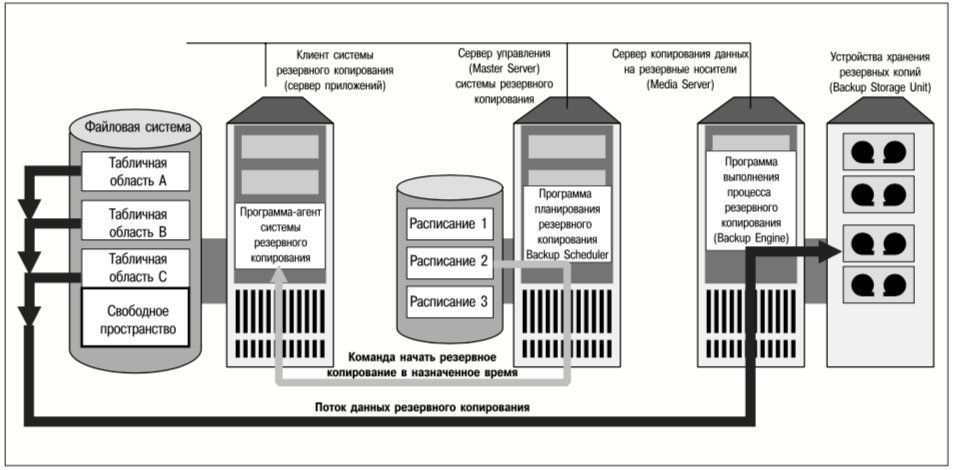
Для успешного создания резервных копий необходимо трехстороннее взаимодействие между клиентом, Master-сервером и Media-сервером:
- Клиент отправляет список файлов, подлежащих резервному копированию, на Master-сервер, а данные со своих онлайновых томов – на Mediaсервер.
- Менеджер резервного копирования инициирует и контролирует выполнение заданий резервного копирования в соответствии с заданным расписанием.
- Media-сервер выбирает одно или несколько устройств хранения, выбирает и загружает носители информации, принимает данные от клиента по сети и записывает их на носители резервных копий.
Аналогично, для восстановления данных с резервной копии:
- Когда клиент делает запрос на восстановление данных, менеджер резервного копирования идентифицирует Media-сервер, контролирующий нужную резервную копию, и дает ему команду на выполнение операции восстановления.
- Media-сервер находит и подключает магнитную ленту или другой носитель с данными, подлежащими восстановлению, и отправляет эти данные клиенту, от которого поступил запрос на восстановление.
- Клиент резервного копирования принимает данные от Media-сервера и записывает их в локальную файловую систему.
Масштабирование операций резервного копирования
В небольших системах, например, на недавно организованном предприятии, все три функции резервного копирования обычно выполняются сервером приложений. Благодаря предлагаемой VERITAS модульной архитектуре, каждую функцию можно перенести на специализированный сервер при увеличении объема операций или изменении требований, не нарушая ранее определенных процедур резервного копирования. На рис. 21 приведена схема масштабирования архитектуры резервного копирования.
Преимущества масштабируемой архитектуры резервного копирования становятся еще более явными, когда предприятие расширяется или возникает необходимость в обработке распределенных операций. На рис. 22 показано, как по мере роста объема обрабатываемых операций предприятия может расширяться масштабируемая архитектура резервного копирования.
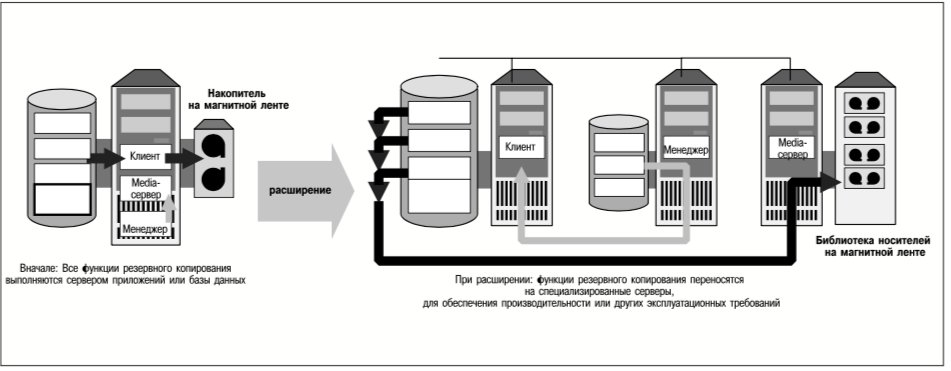
Рис. 22 иллюстрирует два основных преимущества масштабируемой архитектуры резервного копирования:
- Централизованное управление. Master-сервер хранит расписания резервного копирования и каталоги данных для всех имеющихся на предприятии серверов приложений. Наличие одной точки управления означает, что единственная административная группа может управлять операциями резервного копирования целого распределенного предприятия. Агент VCS позволяет конфигурировать Master-сервер NetBackup как группу высокодоступных прикладных сервисов.
- Масштабирование и совместное использование ресурсов. Media-серверы носителей можно добавлять в систему резервного копирования предприятия по мере необходимости. Накопители на магнитной ленте, особенно в составе роботизированных библиотек носителей, являются дорогостоящими ресурсами с невысокой производительностью. Их совместное использование несколькими серверами приложений весьма эффективно с экономической точки зрения.
Распределенная архитектура, подобная изображенной на рис. 22, позволяет свести к минимуму затраты на администрирование и обеспечивает оптимальное использование дорогостоящих аппаратных ресурсов, но за счет интенсивного сетевого трафика. В программном продукте NetBackup применяется ряд методов, с помощью которых воздействие резервного копирования на онлайновые операции сводится к минимуму. Однако, при этом неизбежно будут складываться ситуации, когда большие объемы данных необходимо будет перемещать с клиента на сервер резервного копирования в неподходящее время. При разработке архитектуры резервного копирования для распределенных центров обработки данных необходимо оценить воздействие распределенного резервного копирования на локальный сетевой трафик (пример приведен на рис. 22) и выбрать один из следующих вариантов:
- трафик резервного копирования и трафик приложений идет по одной сети;
- используется выделенная для резервного копирования сеть, построенная по технологии Ethernet или Fibre Channel;
- применяется локализованное резервное копирование, когда в качестве Media-серверов используются некоторые или все серверы приложений.
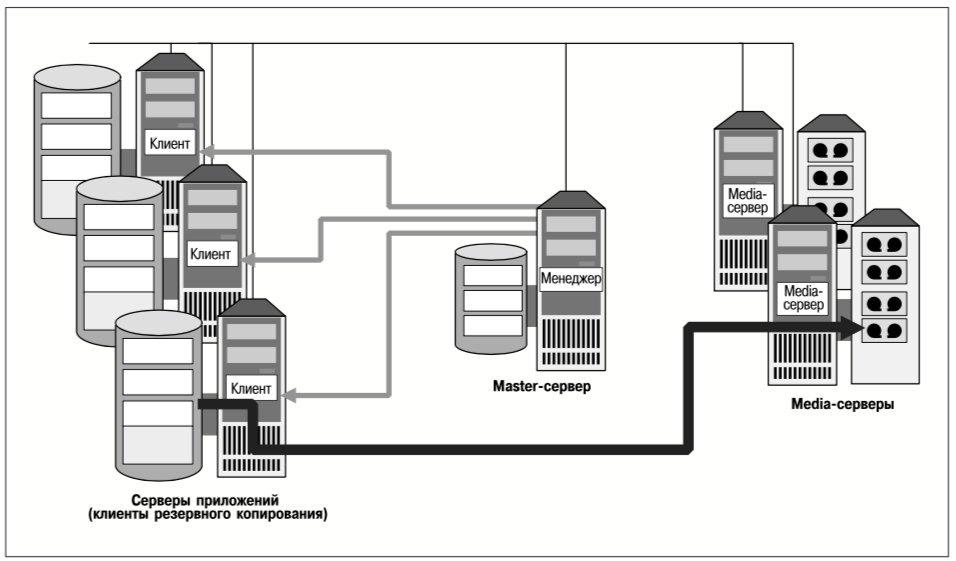
Политика резервного копирования
С одной стороны, регулярно должны создаваться резервные копии большого и постоянно растущего объема данных, необходимых для работы предприятия. С другой стороны, резервное копирование – это операция, интенсивно использующая вычислительные ресурсы, поэтому возникает естественное желание свести к минимуму воздействие резервного копирования на функционирование предприятия. Системные администраторы находят компромисс между двумя этими противоречащими друг другу целями в политике резервного копирования. Политика резервного копирования – это набор правил, которые указывают:
- Какие данные подлежат резервному копированию.
- Когда создавать резервные копии данных.
- Где создавать резервные копии данных.
Далее описано, как компоненты программного продукта VERITAS NetBackup автоматически реализуют заданную системными администраторами политику резервного копирования.
Какие объекты данных подлежат резервному копированию
Чтобы решить, какие данные подлежат резервному копированию, необходимо знать как политику предприятия, так и особенности функционирования его компьютерной системы. Наиболее эффективная политика резервного копирования позволяет различать редко изменяемые и часто изменяемые данные и создавать резервные копии первых реже, чем вторых.
Указать, какие данные подлежат резервному копированию, можно в виде списка файлов. Для больших или особенно активно используемых файловых систем более подходящее решение, как правило, указать, что надлежит проводить резервное копирование всего содержимого, одного или нескольких деревьев каталогов. В этом случае отпадает необходимость отслеживания добавления и удаления файлов в спецификации политики резервного копирования.
Спецификации резервного копирования могут быть еще более сложными. Например, файловые системы ОС UNIX часто подключаются в точках монтирования, подчиненных корневому каталогу /root. Чтобы проводить резервное копирование (как правило, редко изменяемого) корневого каталога по расписанию, отличному от расписания для подчиненных файловых систем, необходимо исключить из числа копируемых каталоги, представляющие точки монтирования. Продукт NetBackup поддерживает списки исключений, позволяющие исключить указанный список файлов или каталогов из спецификации данных для резервного копирования.
Когда создавать резервные копии
Чтобы решить, когда создавать резервные копии данных, также необходимо знать особенности функционирования предприятия и его компьютерной системы. Системные администраторы должны найти оптимальное сочетание таких факторов, как приемлемый максимальный срок хранения резервных копий (этот фактор определяет максимальную продолжительность периода обновления данных, за который они должны восстанавливаться не с помощью резервных копий, а другими средствами) и воздействие на работу системы, которое оказывает резервное копирование, потребляя ее ресурсы.
Если не принимать во внимание потребление ресурсов, то очевидной политикой резервного копирования будет постоянное копирование всех онлайновых данных – каждого файла целиком всякий раз, когда он изменяется. Однако, учитывать потребление ресурсов системы необходимо. Для постоянного резервного копирования требуется значительная производительность обработки данных, ввода-вывода и сети, а также большие объемы памяти для хранения данных и каталогов, что неблагоприятно сказывается как на стоимости системы, так и на производительности онлайновых приложений. Поэтому обычно составляется расписание резервного копирования, что позволяет минимизировать воздействие на онлайновые приложения. Для предприятий, функционирование которых имеет циклический характер с выраженными периодами активности и бездействия, расписание составляется так, чтобы резервные копии создавались в период бездействия. Однако, в современных условиях функционирование предприятий (например, электронного бизнеса) становится непрерывным, т.е. регулярных периодов бездействия больше не существует. Поэтому необходимо найти способы минимизировать потребление ресурсов резервным копированием, чтобы обеспечить возможность «сосуществования» резервного копирования и онлайновых приложений.
Где создавать резервные копии данных
На первый взгляд вопрос о том, где создавать резервные копии данных, кажется простым. Клиент резервного копирования представляет собой источник данных. Местом назначения является один из серверов носителей (или, возможно, несколько). Выбор сервера носителей может зависеть от рабочего цикла предприятия, доступности оборудования и других факторов. Master-cервер NetBackup отслеживает выполнение заданий резервного копирования на каждом клиенте и выбирает Media-сервер, который получит данные для резервного копирования, исходя из пригодности серверов, их относительной загрузки и доступности устройства резервного копирования.
Как правило, сервер носителей NetBackup выбирает конкретное устройство (устройства) резервного копирования для выполнения задания в соответствии с политикой, установленной системным администратором. Устройства резервного копирования можно организовать в группы. Каждое плановое задание резервного копирования связывается с одной группой устройств. Для выполнения конкретного задания резервного копирования Media-сервер NetBackup может выбрать любое доступное устройство (устройства) из соответствующей группы.
Управление носителями резервных копий (магнитными лентами или оптическими дисками) осуществляется аналогично. Имеющиеся носители организуются в пулы, а каждое плановое задание резервного копирования связывается с пулом носителей. Media-сервер NetBackup выбирает доступные носители из связанного с заданием пула по алгоритму, обеспечивающему равномерное использование носителей (и, следовательно, их равномерный износ). Кроме того, Media-сервер хранит расписания чистки и замены носителей, а также отслеживает их местоположение.
Классы NetBackup
В NetBackup на основе параметров политики резервного копирования (таких как допустимые Media-серверы, типы носителей, группы устройств), списков файлов или каталогов и информации из расписания выделяются классы резервного копирования. Класс резервного копирования (класс) также включает в себя именованный набор объектов данных, именованный набор клиентов резервного копирования, расписание резервного копирования и ряд других атрибутов, например, приоритет по отношению к другим классам. Master-сервер резервного копирования управляет определенными в системе классами, взаимодействуя с клиентами и Media-серверами для инициирования и отслеживания создания плановых резервных копий.
Полное и инкрементальное резервное копирование
В большинстве систем лишь небольшая часть онлайновых данных изменяется за время между последовательными операциями резервного копирования. В системах, ориентированных на работу с файлами, изменяется только небольшой процент файлов. Технология инкрементального резервного копирования использует это, чтобы минимизировать ресурсы, необходимые для резервного копирования. Инкрементальная резервная копия – это копия только тех объектов данных, которые изменились с момента последнего резервного копирования. Агент резервного копирования использует метаданные файловой системы, чтобы определить, какие файлы изменились, и копирует только эти файлы. Рис. 23 иллюстрирует различие между полным и инкрементальным резервным копированием.
Инкрементальное резервное копирование не заменяет полное, а только дополняет его. Инкрементальная резервная копия содержит данные, измененные с того момента, для которого существует полная резервная копия. Чтобы восстановить содержимое файловой системы из инкрементальных копий, необходимо сначала в качестве базиса (baseline) восстановить данные из полной резервной копии. Затем восстанавливаются инкрементальные копии, причем в порядке их создания (сначала самые старые), что заменяет в базисе устаревшие файлы на измененные (обновленные). Инкрементальное резервное копирование позволяет реже выполнять полное резервное копирование, для проведения которого требуется значительное время.
Если в большой файловой системе с момента последнего резервного копирования изменились лишь немногие файлы, это означает, что необходимо создать резервные копии только небольшой части данных. Обычно для создания инкрементальных резервных копий требуется гораздо меньше времени (иногда – на несколько порядков), а значит, этот вид резервного копирования меньше воздействует на онлайновые приложения, чем создание полных резервных копий.
Когда используется политика инкрементального резервного копирования, Master-сервер NetBackup регистрирует последовательность создания полных и инкрементальных резервных копий. Чтобы восстановить отдельные файлы, Master-сервер идентифицирует резервную копию, содержащую последнюю версию файла. Чтобы восстановить всю файловую систему, Master-сервер помогает системному администратору в правильном порядке подключить магнитные ленты для необходимых операций полного и инкрементального восстановления.
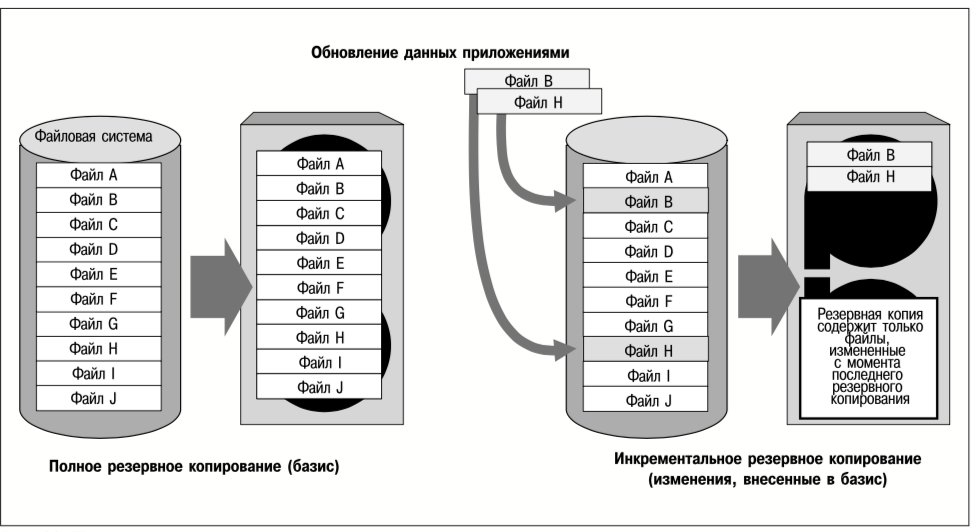
Воздействие инкрементального резервного копирования
Master-серверы NetBackup ведут онлайновые каталоги, в которых указывается местонахождение каждой версии каждой резервной копии файла. Поэтому процедуры для восстановления отдельного файла примерно одинаковы независимо от того, используются инкрементальные резервные копии или нет – необходимо определить местонахождение магнитной ленты, содержащей файл, и подключить ее, а NetBackup должен определить местонахождение файла и скопировать его.
Однако, восстановление целой файловой системы из инкрементальных резервных копий является более сложной задачей. Необходимо сначала восстановить базисную полную резервную копию, а затем инкрементальные резервные копии в порядке их создания (начиная с самой старой). При этом может потребоваться большее вмешательство человека в выбор решений и манипулирование носителями, чем было бы желательно. На рис. 24 приводится схема восстановления целой файловой системы из полной и инкрементальных резервных копий.
Обычно в расписании предусматривается сравнительно нечастое (например, еженедельное) полное резервное копирование в периоды пони-
женной активности (например, в выходные дни) и более частое (например, ежедневное) инкрементальное резервное копирование.
Реализация такой политики приводит к меньшему воздействию на функционирование системы, чем в случае политики, предусматривающей только полное резервное копирование, потому что при создании ежедневных инкрементальных копий копируется лишь небольшой объем данных. Однако, при этом неизбежно увеличивается время восстановления и требуется больше операций манипулирования носителями.
Различные типы инкрементального резервного копирования
Существуют два типа инкрементального резервного копирования. Дифференциальная резервная копия содержит копии всех файлов, измененных с момента последнего резервного копирования любого типа. Следовательно, в случае политики, предусматривающей создание еженедельных полных резервных копий и ежедневных дифференциальных резервных копий, восстановление возможно более актуальной файловой системы выполняется путем восстановления последней полной резервной копии, а затем всех дифференциальных резервных копий в порядке их создания, начиная с самой старой. Чем ближе к концу недели проводится восстановление, тем больше операций инкрементального восстановления необходимо будет выполнить, и тем больше времени займет процесс восстановления.
Кумулятивная резервная копия – это копия всех файлов, измененных с момента последнего полного резервного копирования. Чтобы восстановить файловую систему из кумулятивных резервных копий, требуются только самая свежая полная
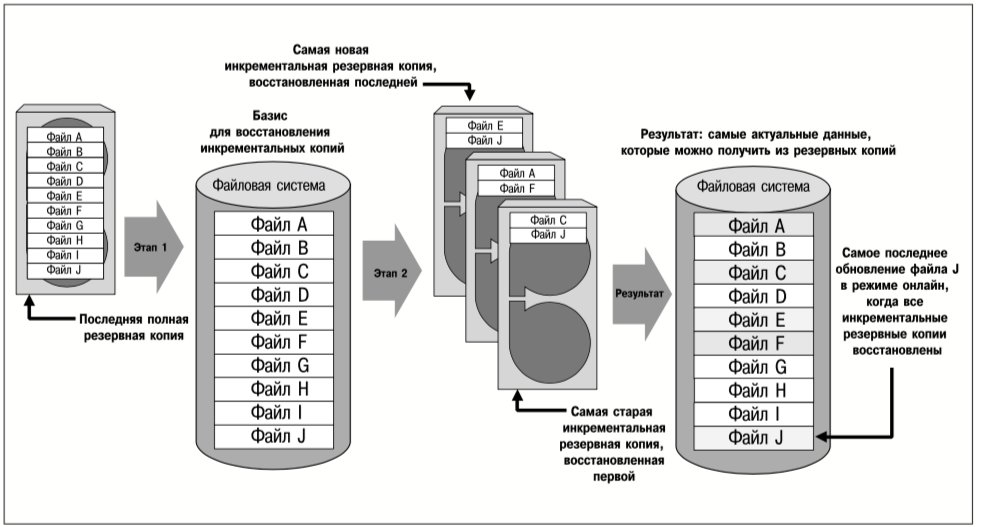
Кумулятивная резервная копия – это копия всех файлов, измененных с момента последнего полного резервного копирования. Чтобы восстановить файловую систему из кумулятивных резервных копий, требуются только самая свежая полная и самая свежая кумулятивная резервные копии. Файловые системы восстанавливаются проще и быстрее, однако, увеличивается время, необходимое для резервного копирования: чем больше времени прошло с момента последнего полного резервного копирования, тем дольше создается кумулятивная резервная копия.
Полное, кумулятивное и дифференциальное резервное копирование можно сочетать, чтобы сбалансировать такие факторы, как воздействие резервного копирования на функционирование системы и время, необходимое для восстановления целой файловой системы или базы данных. В табл. 1 приводится расписание, в котором полное, дифференциальное и кумулятивное резервное копирование скомбинированы так, чтобы сбалансировать время резервного копирования и сложность восстановления. В этом сценарии максимальное количество резервных копий, необходимых для восстановления самых актуальных данных, равно четырем (для восстановления данных на момент времени после субботы используется дифференциальная инкрементальная резервная копия).
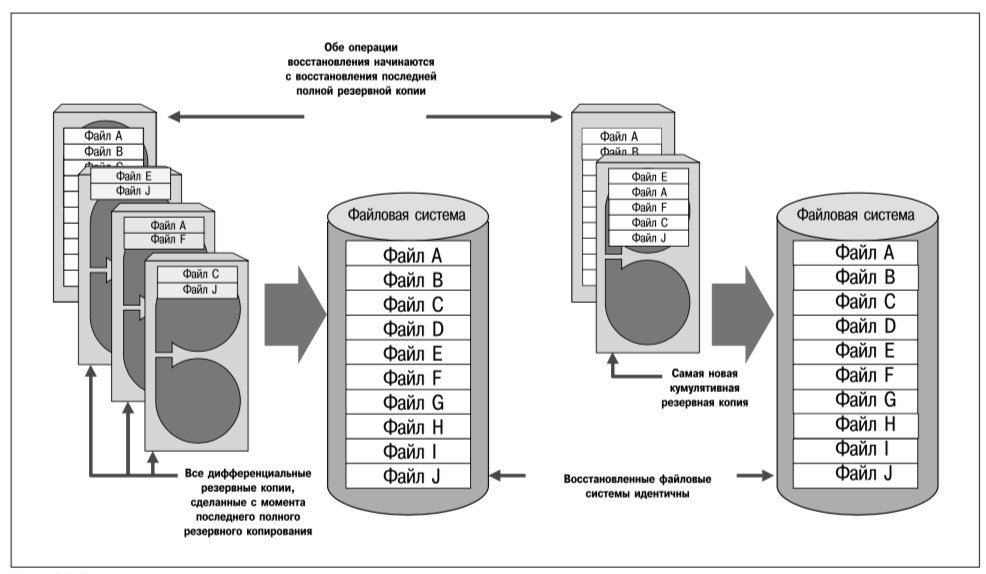
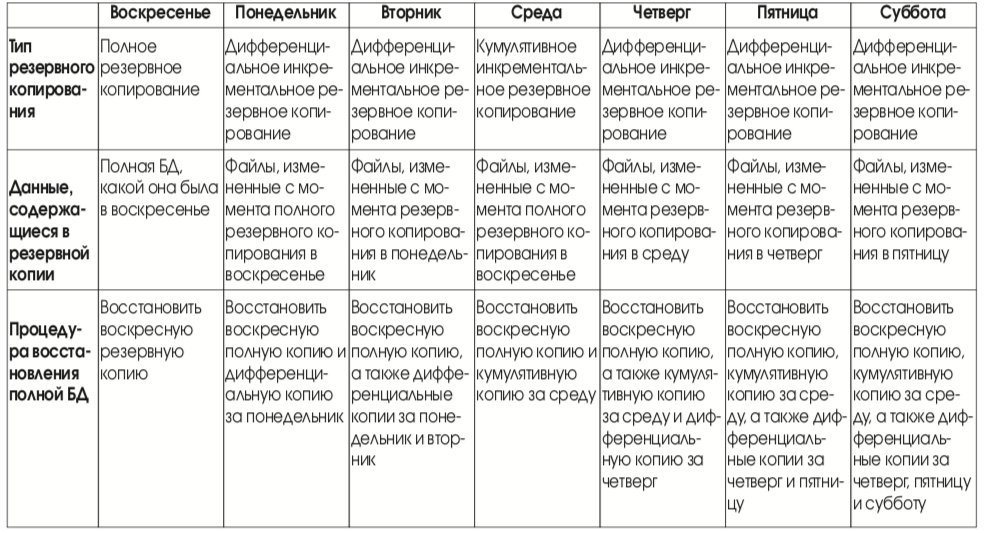
NetBackup позволяет системным администраторам составлять расписания автоматического резервного копирования, подобные приведенному в таблице 1. При наличии роботизированных библиотек магнитных лент плановое резервное копирование можно полностью автоматизировать. Если в классе NetBackup определена политика резервного копирования, больше не требуется никакого вмешательства ни со стороны системного администратора, ни со стороны оператора системы.
Резервное копирование и базы данных
Разработчики СУБД традиционно встраивают в свои продукты средства, которые позволяют создавать резервные копии, соответствующие состоянию базы данных на определенный момент времени (point in time backups). Хотя конкретные механизмы, используемые разными разработчиками, отличаются в деталях, технология такого резервного копирования похожа на технологию «моментальных снимков» файловой системы, описанную в JetInfo No2 (поэтому по аналогии такие резервные копии можно назвать моментальными). Работу базы данных необходимо приостановить на короткое время, чтобы инициировать резервное копирование. Когда процесс резервного копирования инициирован, работа базы данных возобновляется. Каждое изменение, вносимое приложением в объект базы данных во время резервного копирования, приводит к сохранению копии предыдущего содержимого объекта. При запросе на чтение данных от программы резервного копирования возвращаются эти предшествующие образы. (При запросе на чтение данных от любой другой программы возвращается текущее содержимое объекта).
В созданной таким образом резервной копии будет находиться содержимое базы данных на тот момент, когда было инициировано резервное копирование. Этот метод, часто называемый «горячим» резервным копированием баз данных, является общепринятым и широко используется. Программный продукт VERITAS Database Edition for Oracle интегрирует составление расписаний NetBackup и СУБД Oracle, что обеспечивает возможность приостановки работы базы данных для инициирования ее «горячего» резервного копирования. Однако, это увеличивает в базе данных активность ввода-вывода, как из-за самого резервного копирования, так и из-за хранения предшествующих образов объектов базы данных.
Storage Checkpoints и резервное копирование
Программный продукт NetBackup может также создать непротиворечивую «моментальную» резервную копию онлайновой базы данных при минимальных непроизводительных потерях благодаря примененной в VERITAS File System технологии Storage Checkpoints. Объекты, которые создаются при применении технологии Storage Checkpoints (они тоже называются storage checkpoint), функционально идентичны моментальным снимкам файловой системы. Каждый объект storage checkpoint представляет «моментальный» образ одной или нескольких файловых систем, содержащих в себе базу данных. Чтобы минимизировать объем необходимого пространства, технология Storage Checkpoints использует метод копирования при записи (см. JetInfo No2). Объекты storage checkpoint отличаются от моментальных снимков тем, что:
- они представляют собой постоянные объекты (т.е. существуют и после перезагрузки);
- используют собственный пул свободного пространства файловой системы;
- доступ к ним может получить только программа NetBackup.
Создание объектов storage checkpoint следует инициировать в тот момент, когда база данных не используется и имеет внутренне непротиворечивый образ на диске. В такие моменты не выполняется никаких транзакций, а все кэшированные данные отражены на диске.
Программный продукт VERITAS Database Edition for Oracle взаимодействует с СУБД Oracle, чтобы обеспечить непротиворечивость объекта storage checkpoint. Создание объекта storage checkpoint начинается с запроса к СУБД Oracle на кратковременный останов базы данных. Когда СУБД сообщает, что база данных остановлена, инициируется создание объекта storage checkpoint для файловой системы. После инициирования этого процесса, что занимает несколько секунд, СУБД Oracle перезапускает базу данных для использования приложениями.
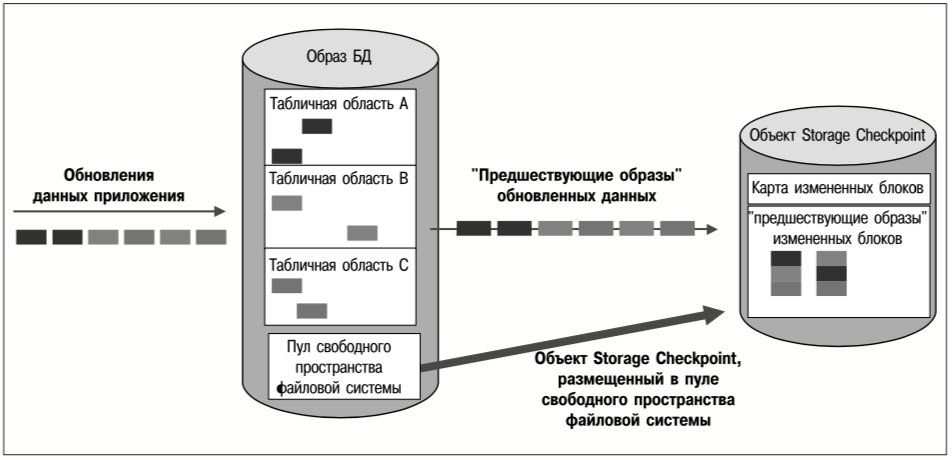
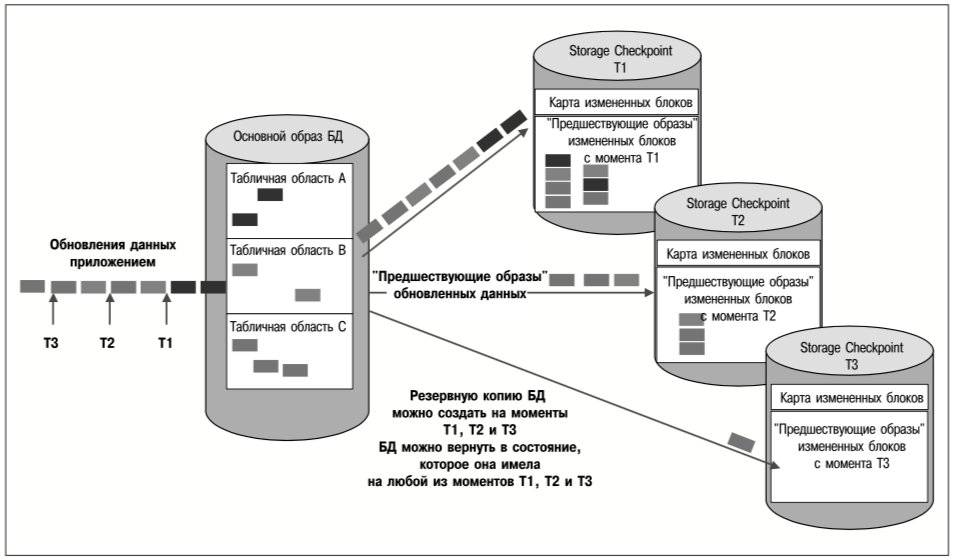
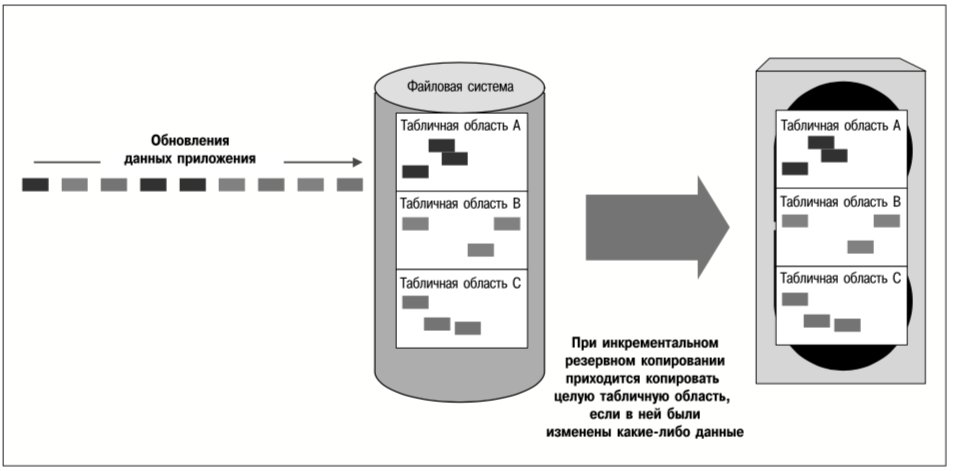
Вначале объекты storage checkpoint занимают очень мало места в памяти – достаточный объём для хранения карты измененных блоков файловой системы, содержащей в себе базу данных. По мере того, как приложения делают записи в базу данных, выделяются блоки для объекта storage checkpoint, в них копируются предшествующие образы обновленных данных, а карта измененных блоков обновляется.
Технология Storage Checkpoints практически сводит к нулю временное окно, необходимое для резервного копирования базы данных. Как полные, так и инкрементальные резервные копии базы данных можно получить из объекта storage checkpoint. Кроме того, поскольку NetBackup считывает данные из одних объектов файловой системы (объектов storage checkpoint), а приложения баз данных – из других, устраняется один из источников перегрузки системы ввода-вывода при резервном копировании.
Программный продукт VERITAS File System может одновременно поддерживать несколько объектов storage checkpoint, как представлено на рис. 27. Хотя при обновлении данных каждый объект storage checkpoint использует и память, и ресурсы ввода-вывода, такое использование технологии Storage Checkpoints обеспечивает администраторам возможность выбора из нескольких резервных копий. Кроме того, в программный продукт VERITAS Database Edition for Oracle включена утилита, которая записывает предшествующие образы измененных блоков из объекта storage checkpoint обратно в основной образ базы данных. Это средство можно применять как к целым БД, так и к отдельным табличным областям или файлам для «отката» базы данных или табличной области в состояние, соответствующее моменту создания объекта storage checkpoint. Такая возможность полезна, например, когда ошибка приложения обнаруживается не сразу, а только через какой-то период времени, в течение которого база данных работала.
Поскольку для объектов storage checkpoint используется свободное пространство файловой системы, наличие множества таких объектов может привести к неожиданным отказам при выделении памяти. Чтобы не допустить отказов, файловая система удаляет объекты storage checkpoint, когда иначе невозможно выделить требуемое пространство. Альтернативой этому варианту может служить сценарий, который будет выполняться, если объем свободного пространства файловой системы станет меньше заданного значения. По этому сценарию может выполняться любое количество корректирующих операций, таких как расширение файловой системы (и соответствующего тома) или удаление объектов storage checkpoint, которые больше не нужны.
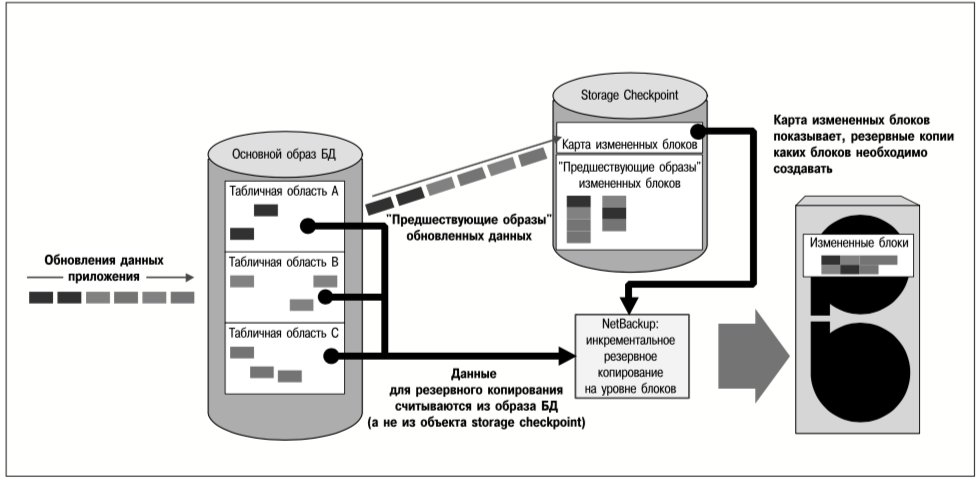
Инкрементальное резервное копирование на уровне блоков
Будучи очень удобным средством для создания резервных копий файловых систем, ни дифференциальное, ни кумулятивное инкрементальное резервное копирование далеко не оптимально для баз данных. Данные в типичной базе данных хранятся в нескольких больших файлах-контейнерах, причем большинство или все эти файлы часто изменяются (правда, незначительно) в процессе использования базы данных. Таким образом, весьма вероятно, что инкрементальная копия, при создании которой копируется каждый измененный файл полностью, будет включать в себя все табличные области базы данных, даже если с момента последнего резервного копирования была изменена только незначительная часть данных.
Однако, можно воспользоваться картой измененных блоков, которая имеется в объекте storage checkpoint, чтобы идентифицировать блоки базы данных, измененные с момента создания этого объекта. С помощью технологии Storage Checkpoints программный продукт VERITAS File System может управлять специальными объектами storage checkpoint, не содержащими данных (dataless storage checkpoint); в таких объектах карта измененных блоков обновляется, но предшествующий образ не записывается. Программный продукт NetBackup может воспользоваться картами измененных блоков, которые принадлежат объектам storage checkpoint, не содержащим данных, для создания инкрементальной резервной копии на уровне блоков. На рис. 29 представлена схема инкрементального резервного копирования на уровне блоков.
Инкрементальная резервная копия на уровне блоков хранит содержимое только тех блоков базы данных, которые изменены с момента создания объекта storage checkpoint. Если за это время обновлена только небольшая часть базы данных, объем инкрементальной резервной копии на уровне блоков, соответственно, невелик. По сравнению с полным резервным копированием базы данных инкрементальное копирование на уровне блоков занимает очень мало времени, использует очень небольшой объем на накопителях и не требует большой пропускной способности подсистемы ввода-вывода.
Подобно инкрементальным резервным копиям файловой системы, инкрементальные резервные копии баз данных на уровне блоков создаются относительно базисной полной резервной копии. Для восстановления базы данных из инкрементальных копий на уровне блоков необходимо восстановить полную резервную копию, воссоздающую образ файловой системы, относительно которого получена самая старая инкрементальная резервная копия на уровне блоков.
Значительно уменьшая воздействие на работу системы отдельного процесса резервного копирования, инкрементальное резервное копирование на уровне блоков позволяет системным администраторам планировать более частое резервное копирование. Частое создание резервных копий позволяет не только снизить требования к ресурсам (пропускной способности и объему накопителей), но также восстанавливать базы данных в состояние на моменты времени, более близкие к моментам отказа.
Как и в случае инкрементальных резервных копий файловой системы, снижение требований к ресурсам при инкрементальном резервном копировании на уровне блоков достигается за счет повышения сложности восстановления данных. Masterсервер NetBackup отслеживает инкрементальные копии на уровне блоков и помогает системным администраторам правильно провести инкрементальное восстановление базы данных.
Другие возможности NetBackup
Мультиплексированные резервные копии
В распределенной среде, пример которой приведен на рис. 22, скорость выполнения задания по резервному копированию может зависеть от нескольких факторов:
- Загрузка клиентов. Если сервер приложений занят выполнением других заданий, это может помешать клиентскому программному обеспечению получить доступ к данным достаточно быстро для того, чтобы поддержать загруженность канала передачи данных резервного копирования.
- Загрузка сети. Если в сети идет интенсивный трафик приложений, это может помешать клиенту резервного копирования переслать данные достаточно быстро для того, чтобы поддержать загруженность сервера резервного копирования или накопителя на магнитной ленте.
- Загрузка сервера резервного копирования. Сервер резервного копирования может быть слишком загружен одновременным выполнением нескольких заданий по резервному копированию (или другой работой, если он также является сервером приложений), чтобы поддержать загруженность накопителей на магнитной ленте.
- Скорость передачи данных накопителей на магнитной ленте. Производительность накопителей на магнитной ленте значительно понижается, если данные не передаются достаточно быстро, чтобы обеспечить потоковый (streaming) режим работы этих устройств (т.е. режим, при котором лента движется, а данные записываются). Наличие небольшой «паузы» в потоке данных, поступающем на такой накопитель, может привести к гораздо большему перерыву в потоке данных, чем при переустановке накопителя.
Кроме того, важно принять во внимание эффективность использования носителей. Емкость больших кассет магнитной ленты обычно в 2-4 раза превышает емкость дисков. Если на предприятии принята политика частого создания инкрементальных резервных копий, в результате будет получаться множество небольших по объему резервных копий. Каждая резервная копия может занимать только небольшую часть магнитной ленты. Из-за неполного использования емкости носителей, во-первых, требуются затраты на дополнительные носители, во-вторых, избыточно большие библиотеки носителей увеличивают общую стоимость системы хранения и, в-третьих, в таких библиотеках повышается вероятность ошибок из-за неправильного обращения с носителями.
Программный продукт NetBackup позволяет минимизировать негативное воздействие изменения производительности передачи данных резервного копирования и способствует эффективному использованию носителей благодаря предусмотренной в нем возможности мультиплексирования или чередования блоков данных от нескольких заданий резервного копирования на одной магнитной ленте.
Системный администратор может позволить одновременно выполняемым заданиям резервного копирования совместно использовать один и тот же участок носителя, причем количество таких параллельных заданий может достигать 32. Подобная политика позволяет компенсировать медленное поступление данных от клиентов, загруженность сетей, а также несовпадение по быстродействию между сетью и накопителями на магнитной ленте. При чередовании нескольких потоков данных резервного копирования блоки каждого потока помечаются идентификатором задания и записываются на ленту в порядке поступления на сервер резервного копирования.
При возрастании объема данных, поступающих на сервер резервного копирования, эффективность потокового режима записи данных на ленту повышается, что приводит к увеличению производительности всей системы резервного копирования. Поскольку данные от нескольких заданий записываются на одну и ту же ленту, повышается эффективность использования носителей. Если требуется восстановить отдельный файл или файловую систему из резервной копии с чередованием потоков, Media-сервер фильтрует блоки, считанные с носителя резервной копии. При этом пользователи не знают о том, что на носителе их резервные копии представляют собой чередующиеся фрагменты.
Параллельные потоки данных резервного копирования
В системах с высокопроизводительными сетями и онлайновыми томами выполнение больших заданий на резервное копирование можно ускорить посредством одновременной записи данных на несколько лент. Такой подход может оказаться эффективным, например, в тех случаях, когда полные резервные копии больших баз данных создаются из моментальных снимков. Каждое задание на резервное копирование в каждый момент времени обрабатывает один файл. Однако, при условии, что файлы-контейнеры моментального снимка базы данных разделены на отдельные группы резервных файлов и запланировано одновременное выполнение соответствующих заданий на резервное копирование, несколько потоков данных резервного копирования могут быть активными в одно и то же время, используя для передачи данных разные сетевые каналы, если они доступны. В зависимости от относительного быстродействия клиента, сети, сервера и накопителя на магнитной ленте может оказаться целесообразным направить выполнение параллельных заданий на разные накопители или мультиплексировать их на одну ленту.
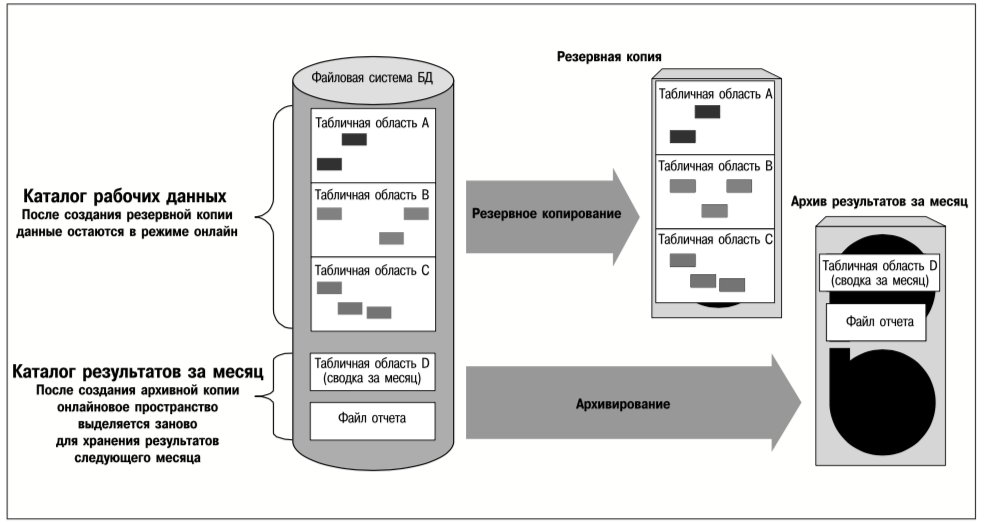
Другие варианты резервного копирования
Хотя резервное копирование по технологии Storage Checkpoints является предпочтительным, программный пакет VERITAS Foundation поддерживает два других метода резервного копирования баз данных, которые не требуют, чтобы во время резервного копирования база данных находилась в нерабочем состоянии:
- Моментальный снимок файловой системы (см. JetInfo No2) может служить основой для непротиворечивой резервной копии базы данных. Резервную копию на основе моментального снимка файловой системы, инициированного в момент неактивного состояния базы данных, можно создать с помощью любой программы резервного копирования. Этот метод использует минимальное количество ресурсов ввода-вывода и может оказаться оптимальным для создания незапланированных резервных копий или в других ситуациях, когда нельзя использовать плановое резервное копирование по технологии Storage Checkpoints. Поскольку моментальные снимки не сохраняются после перезагрузки системы, в случае аварии во время создания резервной копии по моментальному снимку обычно требуется повторный запуск процесса резервного копирования после восстановления системы.
- Зеркалированные тома также можно рассматривать как моментальные снимки – одну зеркальную копию можно выделить из соответствующего тома, пока хранящаяся на нем база данных находится в неактивном состоянии. Выделенную зеркальную копию можно смонтировать и, как в случае с моментальными снимками файловой системы, воспользоваться любой программой резервного копирования. Моментальные снимки томов недешевы, так как требуют значительных объемов дисковой памяти, но это единственный метод резервного копирования, который обеспечивает защиту от отказа дисков. Более того, этот метод защищает от отказа дисков также и онлайновые данные, поскольку VERITAS Volume Manager поддерживает зеркалированные тома с тремя и более идентичными копиями данных, одна из которых выделяется для резервного копирования.
Архивы
По мере развития предприятия объем ретроспективных данных постоянно растет. Ежемесячные, квартальные и годовые итоговые отчеты, учетные записи о продажах, производстве, поставке и обслуживании, а также другие данные необходимо сохранять, но, как правило, не обязательно в режиме онлайн. С помощью программного продукта NetBackup такие данные можно заархивировать. Операции архивирования функционально идентичны операциям резервного копирования. Выбранные данные копируются на резервные носители по предварительно составленному расписанию и регистрируются в каталоге, чтобы их можно было найти впоследствии. Однако, архивирование отличается от резервного копирования тем, что после успешного завершения задания на архивирование (включая проверку копии путем ее повторного чтения и сравнения, если это задано системным администратором), онлайновые копии заархивированных файлов уничтожаются, что позволяет использовать освободившееся пространство для других целей.
На рис. 30 представлена файловая система, в которой онлайновые табличные области базы данных занимают один каталог, а ежемесячные сводки и отчеты – другой. Составляется расписание регулярного резервного копирования онлайнового каталога с помощью средств, рассмотренных в предыдущих разделах. Данные из каталога результатов за месяц нужны пользователям и приложениям только в течение ограниченного периода, но их необходимо сохранять дольше, как требуют нормы законодательства или принятая политика предприятия. Поэтому составляется расписание регулярного архивирования каталога, содержащего результаты за месяц. После копирования этих данных на архивные носители онлайновые файлы уничтожаются, а освободившееся в результате пространство можно использовать, например, для хранения результатов за следующий месяц. При наличии роботизированных библиотек архивирование можно автоматизировать до такой степени, что вмешательство системного администратора или оператора потребуется только в нештатной ситуации.
Еще одно отличие архивов от резервных копий заключается в том, что для архивов не назначается срок хранения. Создавая резервную копию, NetBackup по умолчанию устанавливает срок ее хранения. По истечении срока хранения предполагается, что данная резервная копия недействительна, и, следовательно, носитель, на котором она размещается, можно использовать для других целей. Архивы же рассматриваются как постоянно хранимые записи, поэтому срок хранения для них не назначается.
Оптимальное использование ресурсов хранения: система управления иерархической памятью
После того как предприятие поработает некоторое время, часть его онлайновых данных, естественно, будет использоваться нечасто. Записи о продажах и услугах, спецификации снятых с производства продуктов, списки персонала и т.п. подвержены естественному старению. Многие типы данных в электронном бизнесе имеют естественный период активного использования, по истечении которого их хранение в режиме онлайн становится экономически нецелесообразным. Тем не менее, по нормам законодательства или по причинам, подсказанным практикой предприятия, такие данные все еще имеют определенную ценность, и их необходимо хранить, зачастую в течение нескольких лет.
Хранение нечасто используемых объектов данных в режиме онлайн сказывается на производительности. Если база данных увеличивается в объеме в основном за счет ретроспективных записей, то время доступа к дискам возрастает, а поиск требует больше времени. При этом производительность понизится. Если нечасто используемые объекты данных можно было бы переместить на отдельные тома или перевести в режим оффлайн, то производительность в режиме онлайн повысилась бы.
Как и в случае резервного копирования, принцип переноса (migration) редко используемых объектов данных на недорогие полуавтономные или автономные устройства хранения прост, трудности заключаются в деталях. Обычно имеется слишком много объектов данных слишком многих типов в слишком многих местах, чтобы человек мог вручную управлять процессом их систематического переноса. Необходимо основанное на политике автоматизированное средство прозрачного перемещения объектов данных между активными онлайновыми и неактивными, более дешевыми устройствами хранения, такими, как накопители на магнитной ленте или оптические диски.
Программный продукт VERITAS Storage Migrator
Программный продукт VERITAS Storage Migrator обеспечивает на основании заданной политики автоматический перенос неактивных объектов данных. Этот продукт представляет собой реализацию концепции управления иерархической памятью (HSM – hierarchical storage management). Управление иерархической памятью основано на предположении о том, что технологии хранения данных образуют иерархию цен и производительности – заплатив больше, можно получить устройство хранения (память), которое предоставит данные быстрее за счет его большей пропускной способности и/или меньшего времени ожидания доступа. В левой части рис. 31 представлена такая иерархия цены и производительности для технологий хранения данных. На вершине иерархии находится полупроводниковая память, которая стоит весьма дорого, но обеспечивает почти мгновенный доступ к данным. Вниз по иерархии стоимость памяти в расчете на хранимый бит уменьшается, но доступ к данным и их передача занимают больше времени.
Иерархия применения систем хранения, представленная в правой части рис. 31, описывает мотивацию применения HSM. После того как предприятие проработает некоторое время, обычно обнаруживается, что его данные можно классифицировать следующим образом:
- Активные: часто используемые в повседневной работе.
- Последние ретроспективные: реже используемые, но все еще достаточно важные данные, чтобы хранить их в режиме онлайн.
- Архивные: должны быть сохранены, но используются только в исключительных случаях.
Для некоторых предприятий может также оказаться полезным в соответствии со своими потребностями ввести дополнительные градации в иерархии применения систем хранения. Например, может оказаться, что удобнее хранить архивы выписанных счетов на оптических дисках, поскольку в таких архивах обычно обращаются к отдельным записям для ответов на запросы клиентов. В то же время архивные записи продаж, возможно, лучше хранить на магнитной ленте, потому что к ним обычно обращаются как к единому целому, чтобы извлечь данные для анализа.
Таким образом, с практической точки зрения система HSM полезна не только для минимизации средних затрат предприятия на систему хранения данных, но и для разделения объектов данных по способам и частоте их использования, что позволяет оптимизировать производительность доступа.
Программный продукт VERITAS Storage Migrator поддерживает весь спектр технологий хранения данных. Файлы, массивы магнитных дисков, различные накопители на магнитных лентах, оптические диски и удаленные ftp-узлы – все эти устройства поддерживаются как классы памяти. Допускается, чтобы программные продукты Storage Migrator и NetBackup совместно использовали накопители на оптических дисках и магнитных лентах, а также пулы носителей информации, поэтому один набор устройств, один набор пулов носителей и один набор административных правил и процедур может использоваться как в системе резервного копирования, так и в системе HSM.
Реализация функций HSM в Storage Migrator
Программный продукт VERITAS Storage Migrator позволяет переносить объекты данных в управляемые файловые системы и из них. Перенос данных отличается от резервного копирования и архивирования тем, что он функционально прозрачен для пользователей (хотя они могут заметить, что тот или иной файл перенесен). У пользователей создается впечатление, что перенесенные файлы находятся в своих исходных каталогах. При обращении приложения к перенесенному файлу Storage Migrator кэширует файл, перемещая его из места, куда он был перенесен, обратно в исходную («домашнюю» – home) файловую систему. Пользователь может заметить задержку при обращении к файлу, но команды консоли и прикладные программные интерфейсы (APIs) будут функционировать так, как будто бы файл находится в режиме онлайн. Кэшированный файл, к которому обращались пользователь или приложение, не рассматривается как перенесенный и снова подпадает под действие политики переноса для его «домашней» файловой системы. Если такой файл неактивен в течение заданного времени, он снова переносится из «домашней» файловой системы или, если файл не изменен, просто удаляется из нее.
Перенос файлов обычно осуществляется в два этапа:
- Когда какой-либо файл удовлетворяет критерию переноса (неактивен в течение заданного времени), Storage Migrator перемещает его логически из «домашнего» каталога в каталог «pre-migration» и добавляет в рабочий список для копирования на назначенный сервер (серверы) томов Storage Migrator. Файл копируется в место назначения, однако, его «оригинал» остается в режиме онлайн на исходном физическом местонахождении до тех пор, пока объем доступного пространства в «домашней» файловой системе не снизится до минимально допустимого порога. (Такие файлы, уже скопированные в место назначения согласно политике переноса, но еще доступные онлайн, называют файлами «pre-migrated»).
- Когда общий объем свободного пространства в управляемой файловой системе упадет ниже заданного уровня (т.е. объем выделенного (allocated) пространства превысит максимальное допустимое значение), «оригиналы» файлов «premigrated» будут уничтожены (удалены из своего исходного местоположения). При этом в каталоге остаются записи, указывающие на одно или несколько мест назначения, куда были перенесены эти файлы.
Таким образом, до того момента, пока не возникнет реальной необходимости в занимаемом ими пространстве, перенесенные файлы будут оставаться в своих «домашних» файловых системах, и обращение к ним не будет оказывать влияния на производительность. Файлы «premigrated», к которым обращаются приложения, остаются в режиме онлайн до тех пор, пока опять не пробудут неактивными в течение заданного «времени старения».
Политика Storage Migrator
Программный продукт Storage Migrator обеспечивает гибкое управление политикой переноса файлов. Для каждой управляемой файловой системы системный администратор может назначить:
- Порог доступного пространства, при котором Storage Migrator запускает и останавливает процесс переноса файлов. Когда объем свободного пространства в управляемой файловой системе упадет ниже заданного порога, Storage Migrator освободит пространство, занимаемое файлами «pre-migrated», а также при необходимости перенесет дополнительные файлы, чтобы обеспечить требуемый объем свободного пространства.
- Критерии, используемые для выбора отдельных файлов, подлежащих переносу.
- Критерии, используемые для выбора отдельных файлов, подлежащих уничтожению.
- Количество мест назначения и носитель для каждого переносимого файла, степень параллелизма операций переноса, а также предпочтительную копию для восстановления файла при обращении к нему.Иерархию переноса или количество уровней переноса.
- Некоторые полномочия по управлению политикой переноса файлов администраторы могут делегировать пользователям, позволяя им назначать:
- Конкретные файлы для «pre-migration», переноса, уничтожения, а также не подлежащие переносу.
- Зависимости между теми файлами, которые следует переносить и восстанавливать как группу;
- Перенесенные файлы, которые следует считывать без кэширования.
Такая комбинация политики файловой системы и индивидуального пользовательского управления позволяет системному администратору оптимизировать производительность системы хранения и использование ресурсов, обеспечивая при этом выполнение практически любых требований конкретного предприятия.
Частичное кэширование и фрагменты файлов
Для увеличения исходной скорости реакции при обращении приложения к перенесенному файлу программный продукт Storage Migrator поддерживает частичное кэширование. Как только восстановлена часть перенесенного файла, достаточная для того, чтобы кэшированные блоки смогли удовлетворить запрос приложения на чтение, дается подтверждение приложению о готовности файла, даже если весь файл еще не помещен в кэш.
Многие приложения, особенно утилиты управления данными, просматривают первые несколько байтов большого количества файлов. Это может оказаться крайне неудобным в случае перенесенных файлов, которые все еще входят в каталоги, но чье содержимое хранится в другом месте, возможно, даже в режиме оффлайн. Чтобы предотвратить бесполезное кэширование файлов, а также увеличить исходную скорость реакции при открытии файла для реального доступа, при переносе файла Storage Migrator может оставить в «домашней» файловой системе определяемый системным администратором фрагмент (slice) содержимого каждого перенесенного файла.
Система HSM и базы данных
HSM напоминает резервное копирование еще в одном отношении. Поскольку базы данных обычно размещаются в нескольких файлах, к которым часто осуществляются обращения, практически невозможно задать приемлемую политику для переноса файлов, где хранятся табличные области базы данных. Однако, ретроспективные данные можно переместить из базы данных следующим способом: с помощью указанных пользователем приложений или сценариев фильтрации извлечь строки с ретроспективными данными из таблиц и экспортировать их в файлы, которые будут подлежать переносу в соответствии с политикой HSM.

