 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
- Увеличение числа пользователей.
- Увеличение скорости передачи до гигабит в секунду.
- Появление новых приложений, генерирующих интенсивные потоки данных.
- Повышение требований к качеству сетевого сервиса со стороны перспективных приложений.
- Непредсказуемость распределения потоков данных, преобладание связей по принципу “каждый с каждым”.
- Увеличение числа функций, выполняемых маршрутизаторами (фильтрация, шифрование, протоколирование и т.п.).
В то же время, важность маршрутизаторов не только не уменьшается, но, напротив, постоянно растет (это подтверждает, в частности, последний из перечисленных выше пунктов). Только при использовании маршрутизаторов удается обеспечить масштабируемость сетевой архитектуры, поддержку виртуальных локальных сетей, разграничение межсетевого доступа.
Современные сетевые технологии (как и информационные технологии вообще) развиваются чрезвычайно быстрыми темпами. Это значит, что даже если в какой-то момент удалось выполнить текущие требования к сети, состояние равновесия продлится недолго. Маршрутизаторы отличаются весьма высокой стоимостью, поэтому любая их модификация, не говоря уже о замене, становится серьезной финансовой проблемой.
В табл. 1 приведена статистика работы сети крупной американской компании, подтверждающая высказанные выше положения. Данные взяты из [3].
В настоящем обзоре мы рассмотрим методы решения проблемы эффективной и экономичной маршрутизации, предлагаемые ведущими компаниями, – 3Com Corporation, Bay Networks, Cabletron Systems, Cascade Communications, Cisco Systems, Ipsilon Networks, Neo Networks, Torrent Networking Technologies.

2. Методы повышения эффективности маршрутизации
2.1. Постановка задачи маршрутизации
В классической постановке задача маршрутизации подразделяется на следующие подзадачи:
- управление таблицами маршрутизации, то есть их создание и поддержание в актуальном состоянии;
- определение маршрута для каждого входящего сетевого пакета, то есть выяснение номера выходного порта и MAC-адреса следующего элемента маршрута (следующего маршрутизатора или оконечной системы) по целевому адресу сетевого уровня;
- перенаправление каждого пакета, то есть замена целевого MAC-адреса на адрес следующего элемента маршрута, уменьшение на единицу поля TTL (Time to Live – оставшееся время жизни пакета), пересчет контрольной суммы заголовка и передача пакета в выходной порт;
- применение к каждому пакету дополнительных сервисов (поддержка классов обслуживания, разграничение межсетевого доступа, учет и т.д.).
Управление таблицами маршрутизации – это периодически активизирующийся фоновый процесс, регламентируемый стандартными протоколами (такими как RIP, OSPF, BGP). Обычно его реализуют программно на универсальных микропроцессорах.
Определение маршрута сетевых пакетов – центральная и самая сложная функция маршрутизаторов. Проблема состоит в том, что в таблице маршрутизации хранятся не сетевые адреса (размер такой таблицы был бы слишком велик), а маршруты, представляющие собой совокупности адресов с общим началом.
Соответственно, в таблице ищется самый длинный подходящий префикс. В принципе методы поиска такого рода известны давно (см., например, [2, с. 502]), они основаны на использовании бинарных деревьев. К сожалению, эти методы сложны для аппаратной реализации; только в последнее время появились соответствующие заказные микросхемы. Кроме того, требуется много обращений к памяти – порядка логарифма от размера таблицы маршрутизации. Если в таблице хранятся сотни тысяч маршрутов, то на каждый пакет затрачивается около 20 обращений к памяти. Все это отрицательно сказывается на быстродействии или приводит к необходимости установки больших объемов дорогостоящей статической памяти.
В современной постановке задача определения маршрута является еще более сложной. Вопервых, увеличивается длина сетевого адреса (в IPv6 под номер сети отводится 64 бита). Во-вторых, при выборе маршрута целесообразно учитывать не только целевой, но и исходный адрес, а также информацию транспортного и, быть может, более высоких уровней (например, для того, чтобы обеспечить поддержку классов обслуживания).
После того, как определен маршрут пакета, выполняется перенаправление последнего. Это более простая, на также довольно неприятная задача. Здесь сложности связаны не только с изменением полей в заголовке пакета, но и с возможностью появления узких мест при передаче пакета из входного в выходной порт. В современных маршрутизаторах преобразование заголовков выполняется при поддержке заказных микросхем, а при передаче пакета используются схемы буферизации различной степени сложности.
Формально дополнительные сервисы не относятся к числу основных функций маршрутизаторов, но фактически они прочно вошли в стандартный репертуар. Некоторые из сервисов (например, шифрование пакетов “на лету”) предъявляют очень высокие требования к быстродействию маршрутизаторов.
Попытаемся оценить пропускную способность, необходимую современным маршрутизаторам. Ее можно измерять в переданных битах в секунду и в маршрутизированных пакетах в секунду. Если иметь в виду поддержку гигабитных скоростей, то суммарная пропускная способность должна составлять порядка 1-10 Гбит/с и выше. Для получения оценки в пакетах в секунду воспользуемся результатами измерения характеристик пакетов в Интернет [20]). Согласно этим результатам, средняя длина пакетов составляет 2000 бит и имеет тенденцию к увеличению. Значит, для обеспечения суммарной пропускной способности 10 Гбит/с необходимо маршрутизировать 5 миллионов пакетов в секунду.
Это на порядок больше производительности старших моделей традиционных маршрутизаторов (см. [3]).
Еще одна характеристика маршрутизатора – величина задержки пакета. Обычно она измеряется промежутком времени между поступлением во входной порт последнего бита пакета и появлением первого бита на выходе. Для нормальной работы современных потоковых приложений желательно, чтобы время задержки составляло порядка 10-100 мкс и оставалось относительно стабильным вне зависимости от активности других приложений.
2.2. Классификация методов повышения эффективности маршрутизации
Методы повышения эффективности маршрутизации можно подразделить на следующие категории:
- Повышение производительности микросхем, используемых в маршрутизаторах. Такой подход позволяет ускорить выполнение каждой из четырех подзадач маршрутизации (см. предыдущий пункт). Особенно важно применение заказных микросхем, обслуживающих процесс определения маршрутов.
- Распараллеливание обработки потоков данных. Распараллеливание может носить различный характер. При распараллеливании между подзадачами разные аппаратные компоненты отвечают за управление таблицами маршрутизации, за определение маршрутов и т.д. При распараллеливании между совокупностями пакетов происходит одновременная обработка нескольких пакетов в разных устройствах. Обычно такое распараллеливание реализуют на уровне интерфейсных модулей, то есть каждый модуль независимо выполняет определение маршрута, перенаправление и применение дополнительных сервисов. Наконец, может применяться конвейеризация обработки отдельных пакетов.
- Оптимизация программных компонентов маршрутизаторов. Такая оптимизация направлена в первую очередь на ускорение поиска в таблице маршрутизации за счет реализации новых алгоритмов или за счет применения схем с кэшированием, когда поиск самого длинного подходящего префикса в большой таблице маршрутизации заменяется поиском ключа фиксированной длины в таблице меньших размеров.
- Применение протоколов, упрощающих маршрутизацию. Этот подход также направлен в первую очередь на ускорение определения маршрута, однако здесь в работу маршрутизатора вносится нестандартность, связанная с поддержкой новых протоколов.
- Применение протоколов, позволяющих избежать маршрутизации. Это наиболее радикальный путь, меняющий саму постановку задачи маршрутизации.
Необходимо отметить, что эволюция сетевых технологий не только создает новые проблемы, но и снимает или смягчает старые. Фактически сейчас под маршрутизацией понимают исключительно IP-маршрутизацию. Доля других сетевых протоколов (в том числе IPX) под натиском Интернет/Интранет быстро сокращается. Думается, мало кого в России огорчит отсутствие прогресса в обслуживании протоколов SNA или AppleTalk. Ориентация на IP – общая черта, присущая всем рассматриваемым далее решениям. Нуждающиеся в поддержке других протоколов могут рассчитывать на то, что после установки быстрых и относительно недорогих IP-маршрутизаторов нагрузка на традиционные многопротокольные маршрутизаторы существенно уменьшится, что также можно считать решением проблем.
Число протоколов, которые реально необходимо поддерживать, уменьшается не только на сетевом (третьем), но и на канальном (втором) уровне эталонной семиуровневой модели. Фактически два протокола – Ethernet и ATM – обслуживают весь доступный диапазон скоростей, обеспечивая единый формат пакетов (ячеек). Это также упрощает реализацию высокопроизводительных маршрутизаторов и удешевляет их.
2.3. Повышение производительности микросхем, используемых в маршрутизаторах
Практически все производители маршрутизаторов применяют в своих продуктах специально разработанные заказные микросхемы. Считается, что при программной реализации маршрутизации на базе универсальных RISC-процессоров не удастся поднять производительность выше миллиона пакетов в секунду [3].
Как правило, повышение производительности микросхем используется в сочетании с другими мерами. Так, компания Neo Networks в маршрутизаторе StreamProcessor 2400 [10] встроила в заказные микросхемы около 1000 RISC-процессоров. Это позволило применить подходы, характерные для архитектур с массовым параллелизмом, когда вычислительная мощь поддерживает сложные программные решения.
Компания Torrent Networking Technologies использует заказные микросхемы в совокупности с новым алгоритмом поиска в таблице маршрутизации, уменьшающим число обращений к памяти [12]. В результате появляется возможность отказаться от схем с кэшированием, гарантируя гигабитные скорости маршрутизации независимо от характера трафика.
2.4. Распараллеливание обработки потоков данных
С заказными микросхемами или без них, без распараллеливания обработки потоков данных, поступающих в маршрутизатор через многочисленные интерфейсы с многомегабитными или гигабитными скоростями, не обойтись. Представляется естественным размещение маршрутизирующих микросхем на интерфейсных модулях, поскольку при этом достигается масштабируемость по отношению к наращиванию числа интерфейсов и увеличению суммарных потоков данных. Именно так поступила компания Bay Networks в семействе маршрутизирующих коммутаторов Accelar [6] и корпорация 3Com в коммутаторе третьего уровня CoreBuilder 3500 [8]. Для быстрого перемещения пакетов между входным и выходным интерфейсами применяются аппаратные решения, разработанные для высокопроизводительных коммутаторов.
2.5. Оптимизация программных компонентов маршрутизаторов
В последние 2-3 года внедрение коммутаторов позволило существенно поднять пропускную способность локальных сетей, повысить качество сетевого сервиса. К сожалению, маршрутизация существенно сложнее, чем коммутация на уровне 2 эталонной семиуровневой модели взаимодействия открытых систем. Во-первых, приходится анализировать большее число полей в заголовках пакетов. Во-вторых, обработка адреса получателя является более сложной (в таблице маршрутизации нужно найти максимально длинный префикс, входящий в адрес получателя). В-третьих, необходимо применить правила фильтрации, модифицировать учетную информацию, поставить пакет в выходную очередь в соответствии с его приоритетом. В-четвертых, нужно произвести изменение некоторых полей пакета (изменить адрес уровня доступа к среде передачи и уменьшить оставшееся время жизни – поле TTL). Наконец, приходится обмениваться информацией с другими маршрутизаторами. Столь сложные действия могут и должны стать объектом оптимизации.
Основная идея оптимизации, пропагандируемая в первую очередь компанией Cisco Systems и развиваемая ею в рамках технологии NetFlow Switching [14], состоит в том, чтобы от обработки сетевых пакетов как независимых сущностей перейти к действиям с потоками данных.
Потоки данных выявляются с привлечением информации транспортного уровня, после чего поиск в таблице маршрутизации (равно как и действия по фильтрации) производится только для первого пакета потока. Последующие пакеты потока перенаправляются после быстрого поиска в небольшом кэше.
Отметим, что данная оптимизация является естественной основой для разделения функций между центральным модулем, занимающимся управлением таблицами маршрутизации и определением маршрутов, и интерфейсными модулями, осуществляющими перенаправление. Очевидно, работа интерфейсных модулей может быть распараллелена. Кроме того, при перенаправлении можно использовать технологии, отработанные в коммутаторах (перенаправление со скоростью среды передачи – их основная функция).
2.6. Применение протоколов, упрощающих маршрутизацию
На идее кэширования основываются и попытки упростить маршрутизацию за счет привлечения новых протоколов. Тэговая коммутация (Tag Switching), предложенная компанией Cisco Systems [15] и внесенная в качестве проекта стандарта в рабочую группу IETF по многопротокольной меточной коммутации (MPLS), ориентирована на крупных поставщиков Интернет-услуг и операторов связи, контролирующих области концентрации Интернет-трафика. Маршрутизаторы, входящие в такие области, ассоциируют тэги (небольшого) фиксированного размера с имеющимися маршрутами. Когда с периферии сети в область концентрации поступает пакет, на основе анализа целевого адреса к нему добавляется тэг, обеспечивающий в дальнейшем быстрое определение маршрута (просмотр небольшой таблицы тэгов фиксированного размера произвести проще, чем поиск максимального совпадающего префикса в длинной таблице маршрутизации). На выходе из области концентрации тэг удаляется и определение маршрута вновь выполняется обычным образом. Подчеркнем, что тэговая коммутация не зависит от протоколов более низкого уровня (с передачей ячеек или кадров, с установлением виртуальных соединений или без такового).
Технология IP Navigator компании Cascade Communications [19] также рассчитана на крупных поставщиков Интернет-услуг. Ее идея состоит в том, чтобы сделать области концентрации IPтрафика коммутируемыми, сосредоточив маршрутизацию на периферии областей. Опираясь на предложенные компанией технологии Virtual Network Navigator (VNN) и Multipoint-to-Point Tunneling, входной периферийный маршрутизатор анализирует целевой IP-адрес пакета и перенаправляет его сразу на выходной маршрутизатор области (через ряд промежуточных коммутаторов). Важно отметить, что при этом обеспечиваются не только высокая пропускная способность и малые задержки, но и поддержка классов обслуживания.
Технология IP-коммутации (IP Switching), развиваемая компанией Ipsilon Networks [21], основана на модификации программного обеспечения IP-маршрутизаторов и ATM-коммутаторов и их “спаривании”, в результате которого маршрутизатор берет на себя функции контроллера, управляющего коммутатором с помощью протокола General Switch Management Protocol (GSMP). Как и в технологии NetFlow Switching, по первым IPпакетам выявляются потоки данных, отображаемые на локальные ATM-соединения. При общении между IP-коммутаторами используется предложенный компанией протокол управления потоками (Ipsilon Flow Management Protocol, IFMP).
Подчеркнем, что технология IP Switching не предусматривает установления обычных для ATM “сквозных” виртуальных соединений. Вместо этого соседние устройства “локально” договариваются между собой о коммутации IP-потоков.
2.7. Применение протоколов, позволяющих избежать маршрутизации
Избежать маршрутизации можно в тех случаях, когда между взаимодействующими узлами локальной сети, входящими, быть может, в различные IP-подсети, существует путь, обслуживаемый коммутаторами.
Идея технологии Fast IP, предложенной корпорацией 3Com [17], состоит в том, чтобы взаимодействующие узлы обменялись адресами уровня доступа к среде передачи (MAC-адресами) и использовали их в дальнейшем общении. Первые пакеты при пересечении границ подсетей обычным образом проходят через маршрутизаторы, зато дальнейшие обслуживаются коммутаторами или по крайней мере меньшим числом маршрутизаторов.
Для полноценной реализации этой идеи требуется поддержка целого ряда новых протоколов, но основным является Next Hop Resolution Protocol (NHRP) – протокол выяснения инициатором сетевого взаимодействия MAC-адреса партнера по общению, требующий повышенного интеллекта не от маршрутизаторов, а от сетевых карт и базового программного обеспечения компьютеров. Иными словами, здесь модернизируется не ядро, а периферия сетей.
Компания Cabletron Systems предложила свою архитектуру больших коммутируемых сетей – SecureFast [22]. По замыслу компании такие сети должны быть более эффективными и управляемыми, чем сети, построенные на традиционных маршрутизаторах. Встроенное программное обеспечение коммутаторов, поддерживающих технологию SecureFast, и дополнительный продукт – VLAN Manager – обеспечивают работу сервиса виртуальной маршрутизации (Virtual Routing Service). При этом выбор пути между взаимодействующими узлами сети и перемещение сетевых пакетов между ними происходит без участия маршрутизаторов. Устанавливаются соединения, связывающие оконечные системы. По выражению компании, происходит эмуляция ATM для сетей, основанных на передаче пакетов.
Отметим, что благодаря использованию собственного протокола Virtual Link State Protocol (VLSP), коммутаторы SecureFast способны поддерживать топологии с избыточными связями, что снимает ограничения, характерные для алгоритма остовного дерева. В результате может быть повышена надежность работы сети, обеспечена более высокая суммарная пропускная способность и балансировка нагрузки между каналами. Отметим также, что архитектура SecureFast не ограничена рамками IP-протокола; поддерживаются и другие сетевые протоколы, например, IPX.
В последующих разделах мы детально опишем существующие реализации упомянутых выше концепций, но перед этим мы сформулируем критерии оценки новых маршрутизаторов.
2.8. Критерии оценки новых маршрутизаторов
Можно выделить следующие критерии, применимые к оценке современных высокопроизводительных маршрутизаторов.
- Эффективность. Имеется в виду способность осуществлять маршрутизацию трафика, поступающего одновременно через несколько портов, со скоростью среды передачи (которая уже в ближайшем будущем станет гигабитной) и с небольшой задержкой (порядка 10 – 100 микросекунд). Дополнительные функции, реализуемые маршрутизатором (фильтрация, протоколирование и т.п.), не должны заметно снижать эффективность его работы. Кроме того, разброс в задержках пакетов должен быть минимальным.
- Поддержка классов обслуживания. Взрывной трафик, возникающий, например, при пересылке файлов, не должен нарушать передачу в реальном времени потоковых данных (аудио, видео и т.п.). Маршрутизаторы должны обеспечивать требуемое качество обслуживания на всем пути между оконечными системами.
- Масштабируемость сети. Сетевая конфигурация, складывающаяся в результате использования маршрутизаторов, должна быть управляемой и, главное, масштабируемой по числу узлов и по объемам потоков данных.
- Область применения. Требования к маршрутизаторам, используемым в корпоративных и магистральных сетях, существенно различны. Различаются протоколы канального уровня, которые необходимо поддерживать, объем и характер обслуживаемого трафика, функции протоколирования, меры безопасности и т.п.
- Совместимость с существующей сетевой инфраструктурой. Маршрутизатор должен поддерживать употребительные протоколы, среду передачи, быть совместимым с существующими системами сетевого управления и диагностическими средствами.
- Совместимость с продуктами других производителей. Это стандартное требование к компонентам открытых систем. Применительно к маршрутизаторам оно накладывает ограничение на использование собственных (не ставших общепринятым стандартом) сетевых протоколов.
- Минимизация масштаба изменений, необходимых для эффективной работы нового оборудования. Если установка нового маршрутизатора влечет за собой перестройку значительной части сети, это фактически повышает стоимость и снижает надежность работы сетевой инфраструктуры, что нежелательно.
В свете сформулированных критериев наиболее практичным является повышение производительности маршрутизаторов аппаратными средствами (создание более производительных заказных микросхем, распараллеливание обработки сетевых пакетов). Программная оптимизация в этом смысле менее надежна, так как эффект от ее использования зависит от характера трафика, а производительность маршрутизатора при большом числе поддерживаемых функций может оказаться недостаточной.
Стандартизация и поддержка новых протоколов, упрощающих маршрутизацию или позволяющих избежать ее, хороша как долгосрочная стратегия, к которой, однако, пользователям следует относиться с осторожностью. Как правило, для решения каждой проблемы предлагается несколько конкурирующих решений (в данном случае – различные протоколы) и не всегда можно заранее предсказать победителя. Если для внедрения новшеств требуется перестраивать всю сеть (а так обычно и бывает), цена ошибки может оказаться чрезвычайно высокой.
3. Маршрутизирующие коммутаторы Accelar компании Bay Networks
Компания Bay Networks, по-видимому, единственная среди крупных производителей активного сетевого оборудования, сосредоточилась исключительно на повышении производительности аппаратных компонентов маршрутизаторов. На первый взгляд, такое решение кажется очевидным и самым простым. В мире универсальных компьютеров все так и поступают; изобретение изощренных алгоритмов и хитрых методов оптимизации осталось в прошлом, в золотом веке программирования. Однако и у аппаратной мощи есть пределы, особенно если принимать во внимание стоимость изделия. Только в самое последнее время успехи в разработке заказных микросхем позволили создать маршрутизаторы, способные поддерживать гигабитные скорости потоков данных при микросекундных задержках. Правда, речь идет только об IP-маршрутизации; другие протоколы сетевого уровня “по старинке” обслуживаются унаследованными устройствами.
Ноый класс сетевого оборудования, называемый компанией маршрутизирующими коммутаторами, реализован в рамках семейства Accelar. По историческим причинам семейство включает два вида моделей с несколько отличающейся архитектурой – Accelar 1000 [4] и Accelar 100 [5]. Эти модели мы и рассмотрим далее.
3.1. Маршрутизирующие коммутаторы Accelar 1200
Маршрутизирующие коммутаторы Accelar 1200 предназначены для использования в корпоративных Ethernet-сетях (10/100/1000 Мбит/с). Они состоят из модулей двух видов:
- процессорные модули;
- модули ввода/вывода.
Аппаратная схема Accelar 1200 приведена на рис. 1.
Обычно устанавливается один процессорный модуль; второй может быть добавлен, если требуется обеспечить высокую готовность. На процессорном модуле располагаются собственно процессор (Power PC) и так называемое кремниевое коммутирующее устройство (Silicon Switch Fabric, SSF). Процессор обслуживает протоколы маршрутизации (RIP, RIPv2, OSPF, DVMRP – Distance Vector Multicast Routing Protocol) и поддерживает таблицу маршрутизации, которая хранится в разделяемой памяти.
На модулях ввода/вывода располагаются заказные микросхемы определения адреса (Address Resolution Unit, ARU). В локальной памяти модуля они формируют собственный кэш (рассчитанный на 24000 адресов), извлекая информацию из общей таблицы. При перенаправлении пакетов применяются правила фильтрации и назначения приоритетов. Последние могут быть основаны на номерах физических портов ввода/вывода, идентификаторе виртуальной локальной сети, группе вещания или потоке в смысле протокола резервирования ресурсов (Resource reSerVation Protocol, RSVP).
Микросхемы ARU функционируют независимо друг от друга и от центрального процессора, что является естественной основой параллелизма при маршрутизации пакетов и поддержке правил фильтрации и назначения приоритетов.
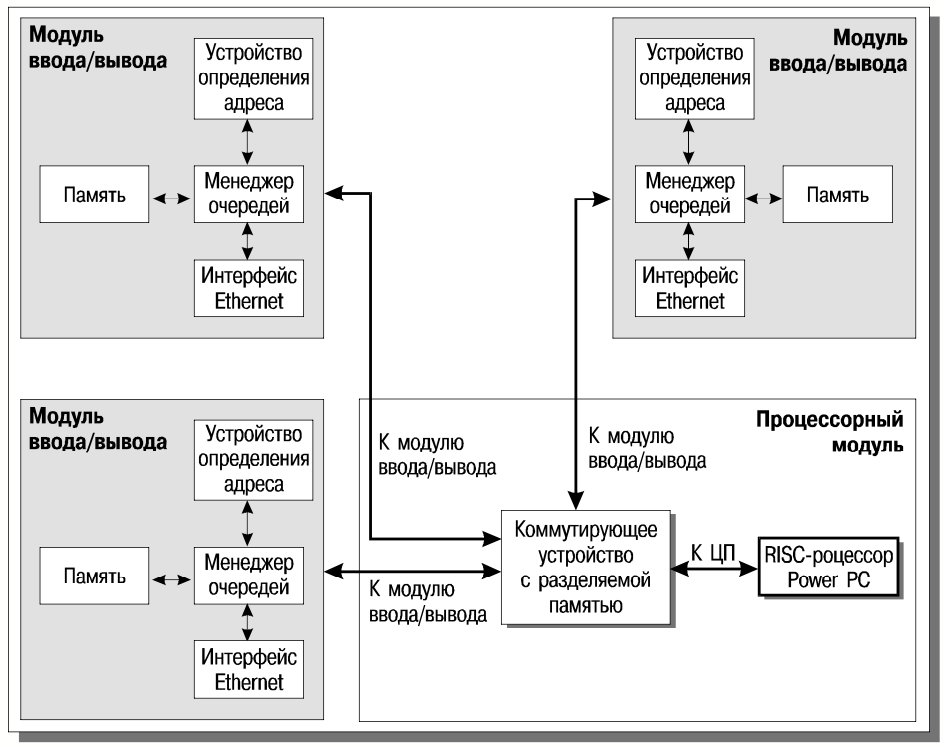
Доставка сетевых пакетов из входного модуля в выходной производится коммутирующим устройством, обладающим достаточной производительностью для одновременного обслуживания всех модулей.
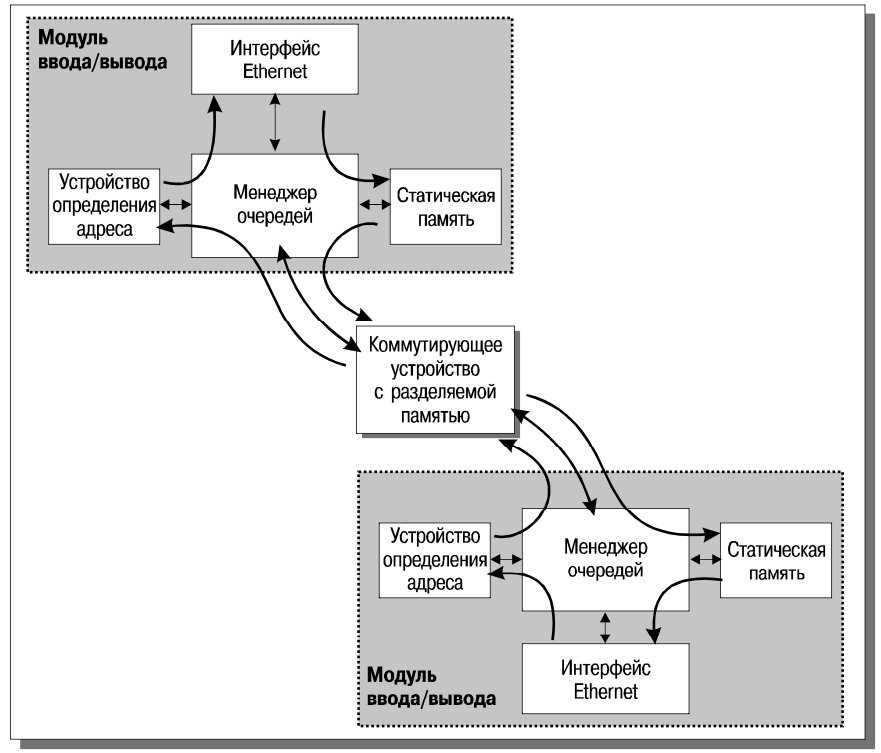
Рассмотрим процессы поиска в таблице маршрутизации и перенаправления пакетов более подробно. Сначала остановимся на обработке одноадресного (unicast) пакета. Микросхема ARU проверяет целостность сетевого пакета, перевычисляя контрольную сумму, по целевому адресу определяет выходной порт и, при необходимости, изменяет такие поля, как MAC-адрес и время жизни (TTL). Затем создается внутренний заголовок, содержащий номера входного и выходного портов и приоритет пакета. После этого менеджер очередей делит пакет на ячейки и записывает их во входную очередь коммутирующего устройства (SSF). SSF перемещает ячейки в очередь выходного порта. В зависимости от бита приоритетности во внутреннем заголовке пакет буферизуется в приоритетной или обычной очереди; последняя обслуживается модулем вывода только тогда, когда приоритетная очередь пуста.
При обработке многоадресных (multicast) пакетов во внутренний заголовок помещается метка группы вещания, ссылающаяся на списки выходных модулей и выходных портов. С помощью этой информации коммутирующее устройство перемещает пакет в соответствующие выходные очереди. Таким образом, Accelar 1200 поддерживает не только несколько уровней качества обслуживания, но и разные очереди для одноадресных и многоадресных пакетов. Все это позволяет гарантировать необходимое качество обслуживания потоков данных, чувствительных к задержкам, вне зависимости от уровня фоновой активности.
Широковещательные (broadcast) пакеты обрабатываются аналогично многоадресным и перенаправляются на все порты, обслуживающие виртуальную сеть, в которую входит отправитель.
Рис. 2 иллюстрирует процесс маршрутизации пакетов в Accelar 1200. Подчеркнем, что все сетевые пакеты обрабатываются независимо друг от друга, то есть не делается попыток выделения каких-либо потоков. Иными словами, имеет место абсолютно “честная”, но очень быстрая IP-маршрутизация.
Гарантированная суммарная пропускная способность Accelar 1200 – 7 Гбит/с, скорость маршрутизации – 7 миллионов пакетов в секунду, задержка на пакет – менее 10 мкс. На сегодняшний день это очень высокие показатели, подтверждающие правомерность подхода, основанного на наращивании производительности аппаратуры маршрутизаторов. Важно отметить, что Accelar 1200 не только на порядок быстрее, но и на порядок дешевле традиционных маршрутизаторов.
Accelar 1200 прост в обращении. Первоначально он может быть установлен как обычный коммутатор; со временем часть или все порты можно перевести в режим маршрутизации. Для администрирования Accelar 1200 поставляется специализированное приложение; впрочем, можно воспользоваться и универсальной системой Optivity.
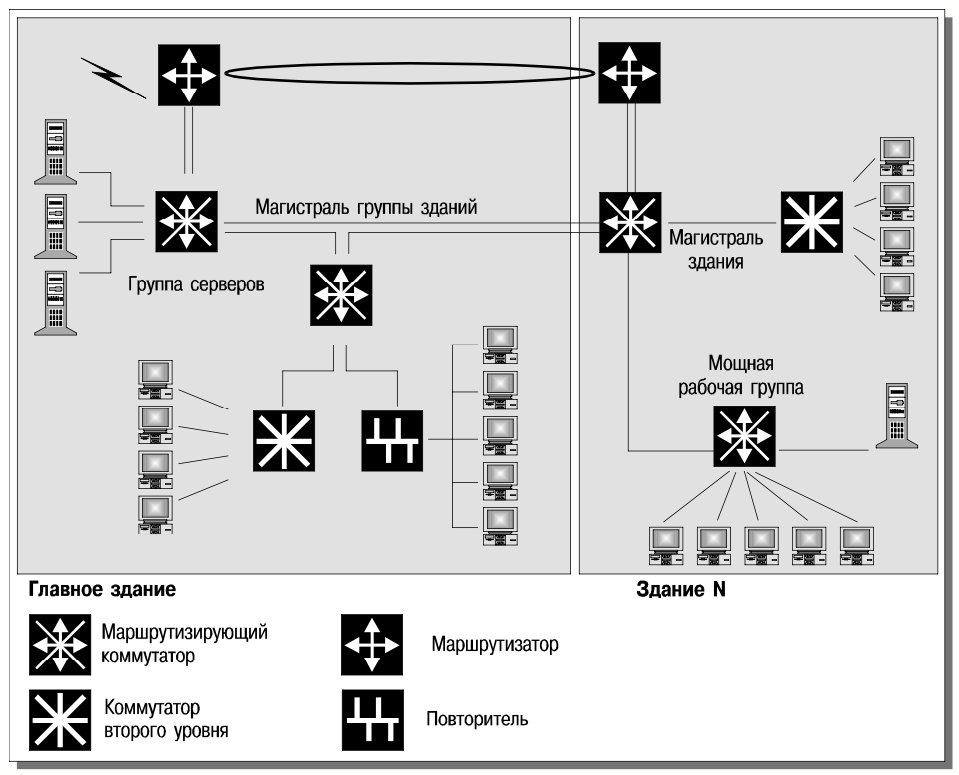
На рис. 3 приведены возможные варианты использования маршрутизирующих коммутаторов Accelar 1200 в корпоративной сети. Имеется в виду поддержка мощных рабочих групп, а также маршрутизация в магистральных сетях отдельных зданий или группы зданий.
Применение маршрутизирующих коммутаторов класса Accelar 1200 позволяет снять традиционное противоречие между масштабируемостью сети и ее пропускной способностью. Отпадает необходимость в разного рода приемах, позволяющих обходить маршрутизаторы (включение серверов и мощных пользователей в одну подсеть и т.п.). Сеть можно строить более регулярным образом, что повышает надежность и облегчает администрирование. При этом отсутствуют негативные побочные эффекты, связанные с проблемой поддержки новых протоколов или с несовместимостью с продуктами других производителей.
3.2. Маршрутизирующие коммутаторы Accelar 100
Идейно модели Accelar 1200 и 100 близки, однако в реализации имеются существенные различия, касающиеся построения модулей и организации их параллельной работы.
Accelar 100 (см. рис. 4) состоит из процессорного модуля (с микропроцессором Motorola 68060, 33 МГц) и нескольких коммутационных модулей (в роли коммутационного процессора выступает MIPS R5000, 180 МГц). Модули связаны между собой двумя независимыми шинами – управляющей и коммутационной; пропускная способность каждой – 1.2 Гбит/с.
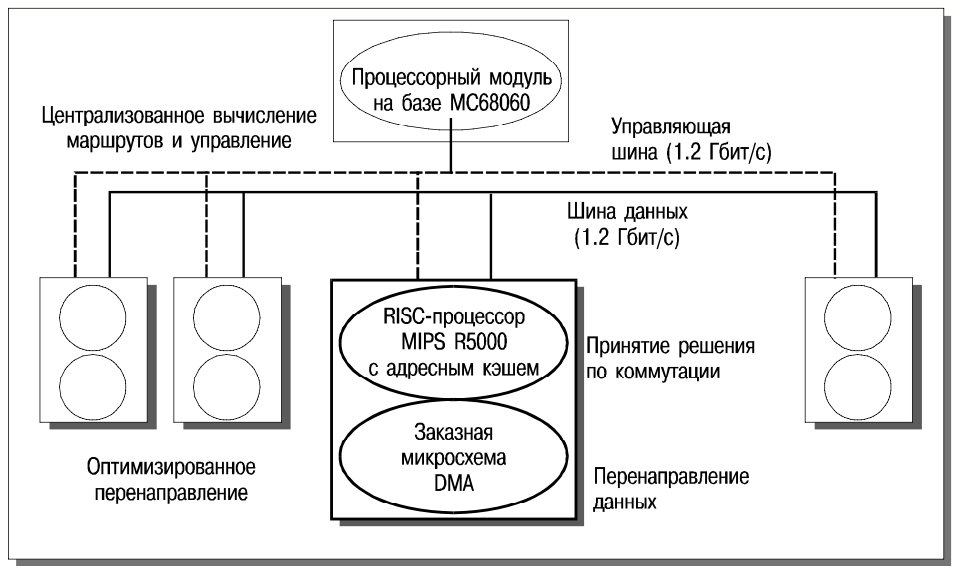
Процессорный модуль выясняет топологию сети и заполняет адресные таблицы коммутационных модулей. Уникальной чертой Accelar 100 является поддержка режима самообучения, при котором в процессе работы в режиме коммутации путем прослушивания IP-трафика обеспечивается автоматическое выяснение адресов доступных IP-устройств. После формирования адресных таблиц Accelar 100 может быть переведен в режим маршрутизации; при этом пакеты с неизвестными IP-адресами и не-IP-пакеты будут переадресовываться на существующий подразумеваемый маршрутизатор.
Видимо, впервые подход “plug and play” оказался распространенным на маршрутизаторы. Процессоры коммутационных модулей принимают решения по коммутации/маршрутизации, а передача пакетов между входным и выходным модулями выполняется с использованием устройств прямого доступа к памяти (DMA) при поддержке заказных микросхем.
По сравнению с моделью 1200, Accelar 100 обладает меньшей функциональностью и производительностью. Он выполняет только маршрутизацию сетевых пакетов; все дополнительные сервисы (фильтрация, учет и т.п.) остаются за обычными маршрутизаторами. На момент написания статьи Accelar 100 не поддерживал Gigabit Ethernet. Скорость маршрутизации составляет 1 миллион пакетов в секунду, минимальные задержки (по данным компании) не превышают 50 мкс. По результатам тестирования в испытательной лаборатории журнала Data Commucations средняя величина задержки оказалась равной 245 мкс (см. [25]).
4. Технология FIRE корпорации 3Com
Технология гибких интеллектуальных маршрутизирующих устройств (Flexible Intelligent Routing Engine, FIRE, см. [7]) корпорации 3Com по сути аналогична подходу, реализованному компанией Bay Networks в семействе маршрутизирующих коммутаторов Accelar. Разумеется, в этом нет ничего удивительного, поскольку речь идет о довольно очевидных вещах – применении мощных заказных микросхем и распараллеливании (а также конвейеризации) обработки пакетов, то есть о подходах, апробированных в высокопроизводительных коммутаторах.
Согласно терминологии корпорации 3Com, технология FIRE реализуется в коммутаторах третьего уровня (Layer 3 Switch). На момент написания статьи наиболее продвинутым среди них был CoreBuilder 3500, рассчитанный на использование в локальных сетях среднего размера.
Его мы и рассмотрим.
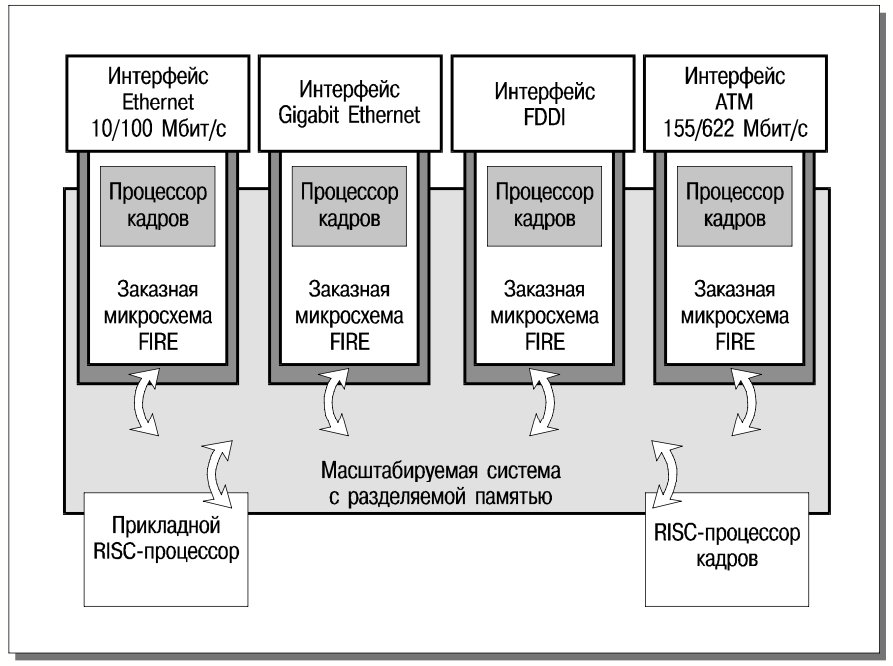
Рис. 5 иллюстрирует аппаратную организацию коммутатора третьего уровня CoreBuilder 3500. По-видимому, наиболее примечательным отличием от маршрутизирующих коммутаторов семейства Accelar является сочетание физической распределенности оперативной памяти с ее глобальной разделяемостью. Такое решение автоматически обеспечивает масштабируемость при добавлении новых интерфейсных модулей и способствует повышению эффективности при реализации фирменной технологии распределенной конвейеризации пакетов (Distributed Packet Pipelining, DPP), поскольку отпадает необходимость в многочисленных копированиях из одной области памяти в другую.
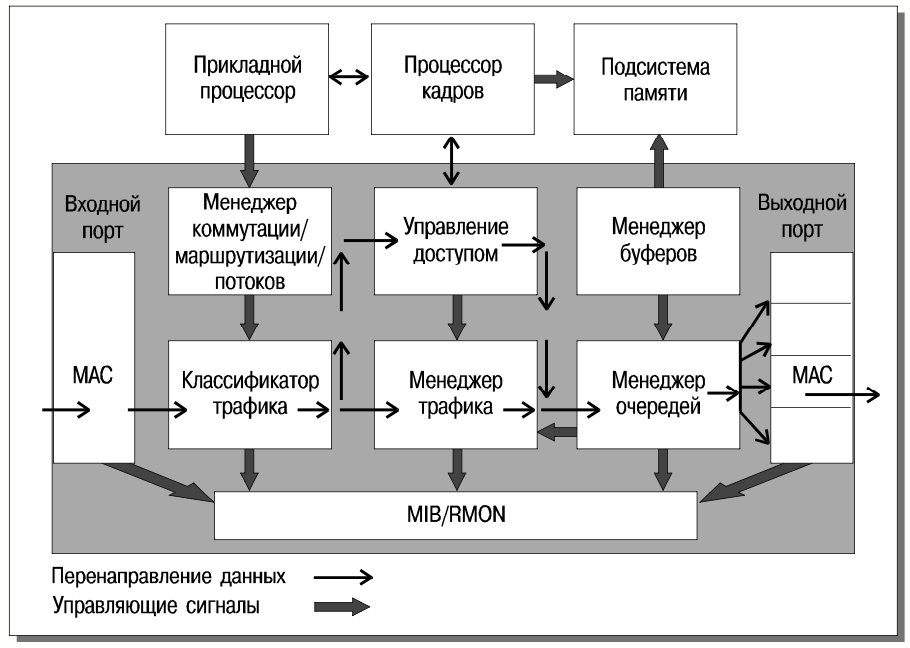
Сам DPP-конвейер выполняет следующие операции:
- проверяет целостность пакета;
- регистрирует информацию для соответствующих баз (MIB), в том числе для систем удаленного мониторинга (RMON);
- определяет принадлежность к виртуальным локальным сетям;
- разделяет коммутируемые и маршрутизируемые пакеты;
- классифицирует потоки данных;
- определяет применимость правил, касающихся качества обслуживания;
- применяет фильтры;
- модифицирует маршрутизируемые пакеты;
- устанавливает приоритет пакета;
- передает пакет.
Рис. 6 иллюстрирует функционирование описанного выше конвейера.
Сочетание в FIRE-продуктах универсальных процессоров (i960) и программируемых заказных микросхем позволяет добиться высокой производительности при сохранении практически неограниченной гибкости. Многие усовершенствования (такие, например, как поддержка IP версии 6) могут быть реализованы за счет обновления встроенного программного обеспечения. CoreBuilder 3500 выделяется своей многопротокольностью и в плане предоставляемых интерфейсов (поставляются или объявлены интерфейсы для 10/100/1000 Мбит/с Ethernet, 155/622 Мбит/с ATM, FDDI), так и в плане поддерживаемых сетевых протоколов (IP, IPX, AppleTalk). Разумеется, поддерживаются стандартные протоколы маршрутизации (RIP, OSPF, DVMRP).
Обратим внимание на наличие в FIRE-архитектуре двух RISC-процессоров. Прикладной процессор обеспечивает поддержку протоколов второго и третьего уровней. Процессор кадров выполняет специфические действия, связанные с перенаправлением пакетов переменной длины. По мнению специалистов корпорации 3Com, выделенный процессор кадров абсолютно необходим для высокопроизводительных многопротокольных маршрутизаторов.
Производительность у CoreBuilder 3500 достаточно высока. Тестирование, проведенное Tolly Group (см. [9]), зафиксировало скорость маршрутизации, превышающую 3.5 миллиона пакетов в секунду. По данным корпорации 3Com, средние задержки находятся в диапазоне 15-30 мкс.
Поддержка классов обслуживания обеспечивается механизмом приоритетов. С каждым выходным портом ассоциируются очереди с четырьмя уровнями приоритетов. Дисциплина “честного взвешенного” обслуживания гарантирует, что пакеты из более приоритетных очередей будут отправляться чаще, однако и низкоприоритетные очереди не останутся без внимания. Для загруженных сетей подобный алгоритм планирования является оптимальным.
В технологии FIRE предусмотрены средства для автоматического назначения приоритетов потокам данных, что упрощает работу администраторов сетей. Приоритет может определяться протоколом (IP, IPX, AppleTalk), одноили многоадресностью пакетов, номерами используемых TCP-портов, метками в смысле протокола 802.1p.
Кроме того, поддерживается протокол динамического резервирования полосы пропускания RSVP. Интересно отметить, что с точки зрения информационной безопасности механизмы управления полосой пропускания, предусмотренные технологией FIRE, можно рассматривать как обобщение фильтрации. Выразительная сила языка классификации потоков данных по сути та же, что и при задании правил фильтрации, однако можно задать не только нулевую, но и небольшую положительную ширину полосы пропускания. В результате определенные действия будут возможны, но в ограниченном количестве.
Еще одна особенность технологии FIRE, связанная с информационной безопасностью, состоит в обеспечении высокой доступности. Процессоры и заказные микросхемы, помимо выполнения своих основных функций, контролируют состояние друг друга и при необходимости инициируют перезагрузку. Программные компоненты хранятся в защищенной от записи памяти, что предотвращает нарушение их целостности. От такой распространенной угрозы, как выход из строя отдельного порта или канала, защищает механизм объединения каналов (trunking). Впрочем, эта последняя возможность сейчас относится к числу стандартных.
5. Технологии компаний Neo Networks и Torrent Networking Technologies
5.1. StreamProcessor 2400 компании Neo Networks
Компания Neo Networks, основываясь на прогрессе в области заказных микросхем, реализовала далеко идущее обобщение традиционных схем маршрутизации [11]. В маршрутизаторах StreamProcessor 2400 перенаправление пакетов выполняется не на основе поиска в таблице маршрутизации, а в процессе применения совокупности правил, которые могут оперировать с любыми полями пакетов. Строго говоря, StreamProcessor 2400 является “безуровневым” устройством или, что то же, устройством, способным оперировать на всех уровнях эталонной модели ISO/OSI. В результате StreamProcessor 2400 может одновременно выполнять функции мостов, коммутаторов и маршрутизаторов, а также устройств более высокого уровня вплоть до прикладного.
Разумеется, в стандартный комплект StreamProcessor 2400 входят базы правил, обеспечивающие функциональность традиционных многопротокольных маршрутизаторов. (Общая база размером в миллион элементов позволяет хранить не только правила, но и маршруты, MACадреса, метки виртуальных сетей.) Администраторы сетей могут дописывать свои правила, обеспечивающие маршрутизацию и/или фильтрацию трафика по сколь угодно сложным критериям.
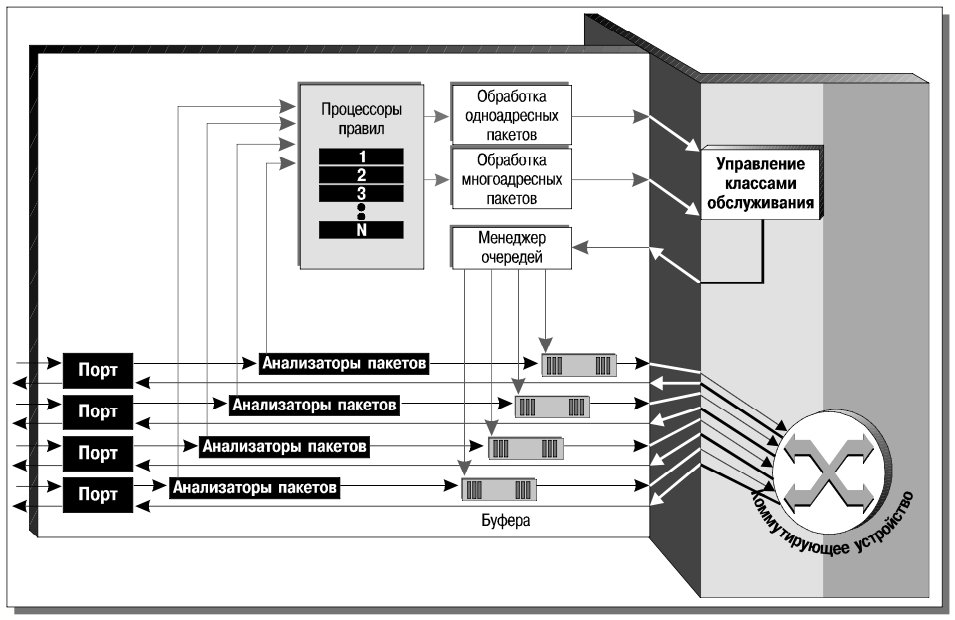
С аппаратной точки зрения StreamProcessor 2400 представляет собой системный блок на 16 слотов, предназначенных для интерфейсных модулей (рис. 7). В самом системном блоке располагаются коммутирующее устройство с пропускной способностью 512 Гбит/с и устройство поддержки классов обслуживания. Остальные функциональные блоки (анализаторы пакетов, процессоры правил, менеджеры очередей, буфера) помещены на интерфейсные модули, содержащие порты Gigabit Ethernet (4 или 8) или 4 порта OC-48 (2.4 Гбит/с). Согласно утверждениям компании, StreamProcessor 2400 способен маршрутизировать более 400 миллионов пакетов (кадров, ячеек) в секунду.
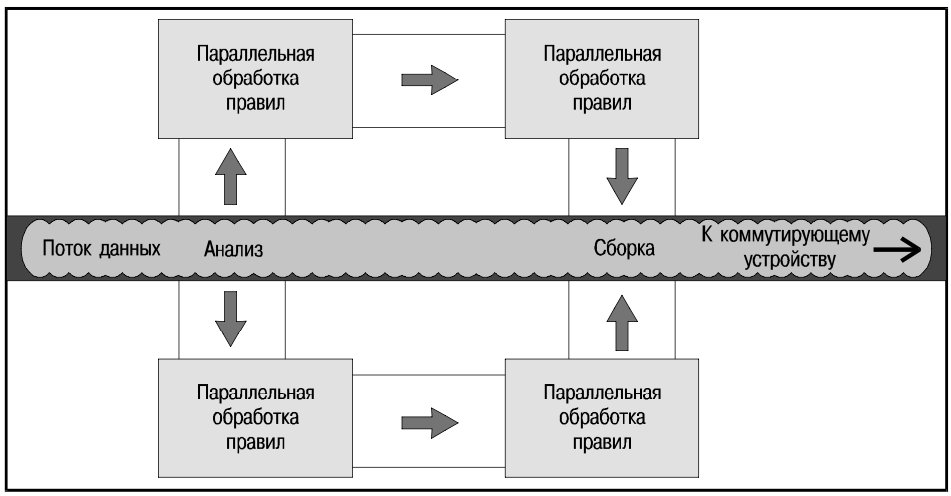
Для реализации параллельной обработки каждый пакет размножается и поступает сразу в несколько процессоров правил; на выходе результаты работы процессоров объединяются (рис. 8). В процессе обработки не только определяется информация, необходимая для перенаправления, но и выполняется классификация пакетов для поддержки классов обслуживания. Отметим, что одноадресные и многоадресные пакеты перенаправляются раздельно.
Большинство RISC-процессоров (900) встроены в заказные микросхемы и представляют собой недорогие устройства с тактовой частотой 56 МГц. Остальные 128 процессоров являются стандартными. Это позволило удержать стоимость системы с массовым параллелизмом в разумных пределах (примерно 2500 долларов на порт). Тем не менее, представляется, что на сегодняшний день технология компании Neo Networks является слишком большим шагом вперед и мощные возможности по формированию и применению базы правил окажутся в значительной степени невостребованными.
5.2. Маршрутизатор IP9000 компании Torrent Networking Technologies
Молодая компания Torrent Networking Technologies сделала ставку на более прозаическое, но чрезвычайно важное усовершенствование – новый алгоритм поиска в таблице маршрутизации при поддержке заказных микросхем. Это позволило отказаться от схем с кэшированием, эффективность которых зависит от характера трафика, и осуществлять “честный” поиск в таблице маршрутизации размером до 200 тысяч элементов, гарантируя суммарную пропускную способность 20 Гбит/с. Согласно утверждениям компании, скорость маршрутизации составляет более 20 миллионов пакетов в секунду, максимальная задержка на пакет – 25 мкс (см. [13]).
Новый алгоритм поиска получил название ASIK (по первым буквам фамилий авторов). Его детали не раскрываются, однако можно предположить, что он основан на использовании деревьев с более высоким коэффициентом разветвления, чем 2. Тем самым достигается уменьшение числа обращений к памяти и, следовательно, ускорение просмотра таблиц маршрутизации.
Еще одной принципиальной новинкой в IP9000 является классификация пакетов данных на потоки и независимая обработка каждого потока. Поток характеризуется адресами сетевого уровня и номерами портов транспортного уровня. Для каждого потока можно специфицировать 3 дисциплины обслуживания:
- гарантированная полоса пропускания;
- обслуживание “по мере возможности” без ограничений на полосу пропускания;
- обслуживание “по мере возможности” с ограниченной полосой пропускания.
Для каждого потока поддерживается своя выходная очередь. Такая реализация является более надежной, чем фиксированное число приоритетов и соответствующих им очередей, поскольку взрывной трафик в одном потоке не сможет уменьшить долю обслуживаемых пакетов из других потоков.
Функциональная схема маршрутизатора IP9000 приведена на рис. 9. IP9000 выпускается в двух вариантах, с конструктивом на 8 и 16 слотов. Логически IP9000 состоит из устройств трех видов:
- процессор маршрутизации;
- коммутирующее устройство;
- интерфейсные модули.
Процессор маршрутизации (это отдельное устройство, соединенное с маршрутизатором линией Fast Ethernet) обеспечивает управление таблицами маршрутизации и обслуживает интерфейс с администратором. Коммутирующее устройство перемещает пакеты, поддерживая отдельную очередь для каждого потока. Интерфейсные модули, помимо сетевых портов (Fast Ethernet, Gigabit Ethernet, ATM OC-3 155 Мбит/с), содержат заказные микросхемы для поиска в таблице маршрутизации по алгоритму ASIK (каждый порт располагает полной копией таблицы). По результатам поиска выполняются классификация пакетов по потокам и преобразования заголовков (также с помощью заказных микросхем), после чего пакеты передаются коммутирующему устройству.
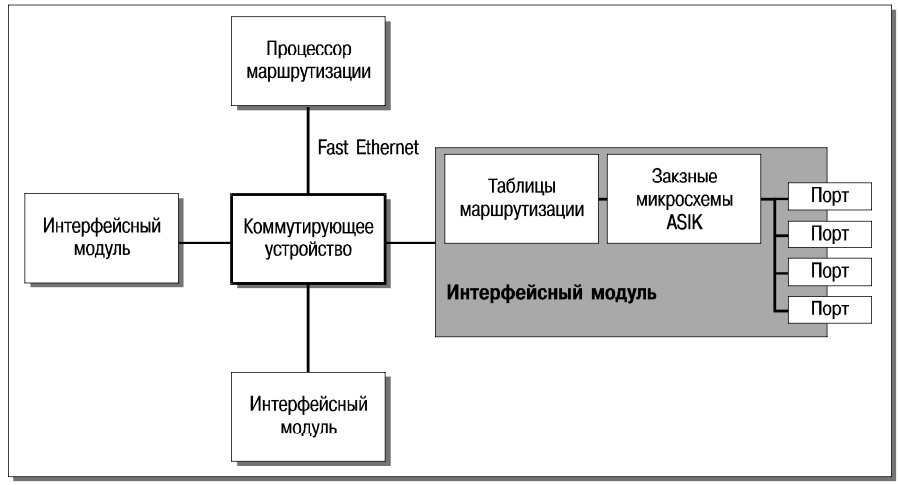
Таким образом, в IP9000 реализовано распараллеливание как между подзадачами маршрутизации, так и внутри подзадач поиска в таблице маршрутизации и перенаправления пакетов. Кроме того, поиск и перенаправление оптимизированы с помощью заказных микросхем. IP9000 можно назвать “гигабитным маршрутизатором без компромиссов”, поскольку он естественным образом масштабируется при установке дополнительных интерфейсных модулей, гарантируя маршрутизацию с гигабитными скоростями, малые задержки и поддержку классов обслуживания.
6. Две технологии компании Cisco Systems
6.1. Технология NetFlow Switching
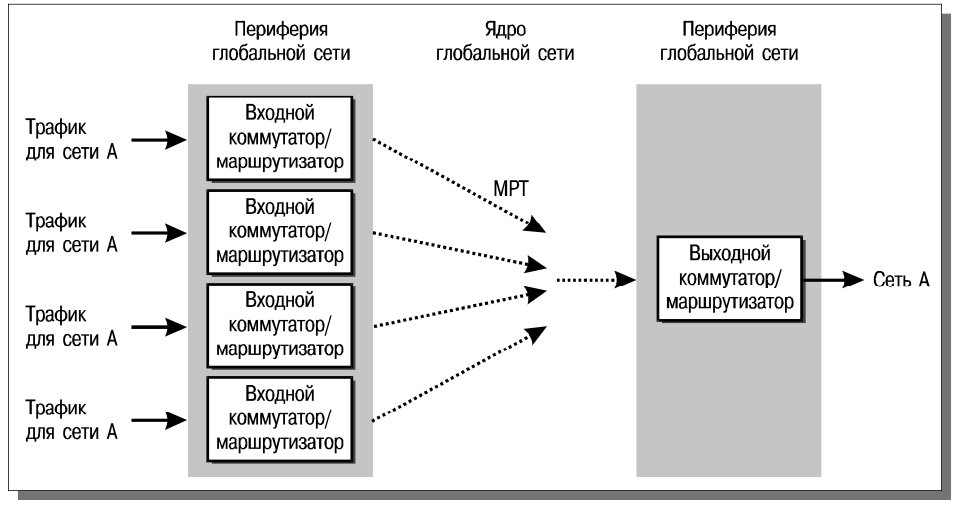
В основе технологии NetFlow Switching компании Cisco Systems лежит идея программной оптимизации межсетевой операционной системы
Cisco IOS, используемой в маршрутизаторах. Если попытаться анализировать сетевые пакеты не независимо, а объединить родственные пакеты в потоки, можно значительно быстрее выполнять перенаправление и применять дополнительные сервисы, такие как разграничение межсетевого доступа или учет трафика.
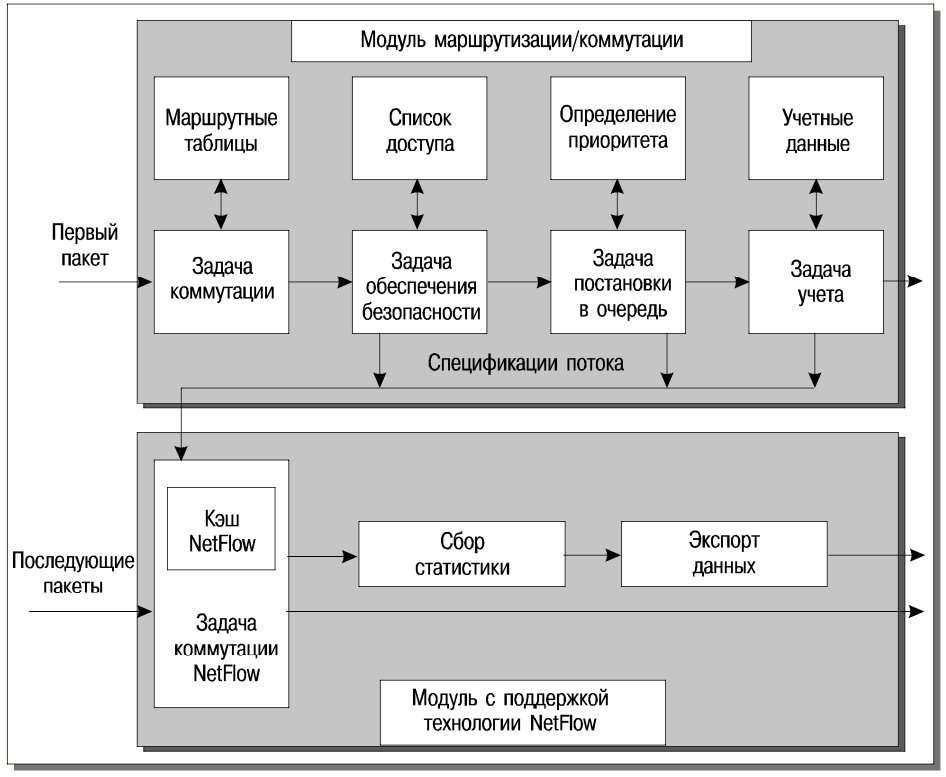
При применении технологии NetFlow Switching обычная для маршрутизаторов обработка выполняется только для первого пакета потока. Поток определяется как совокупность пакетов с фиксированными:
- исходным и целевым IP-адресами;
- исходным и целевым номерами портов транспортного уровня;
- типом протокола;
- типом сервиса;
- входным интерфейсом.
По первому пакету определяется маршрут, проверяется вхождение в список управления доступом и выясняется набор дополнительных сервисов, которые необходимо применять к этому и всем последующим пакетам потока. Эта информация помещается в кэш, операции с которым (при поддержке мощных заказных микросхем) выполняются значительно быстрее, чем при обычной маршрутизации. Схема обработки сетевых пакетов в технологии NetFlow Switching представлена на рис. 10.
Оптимизация, выполняемая в технологии NetFlow Switching, направлена на то, чтобы для обычных сетей с коммутацией пакетов промоделировать режим с коммутацией соединений. Подчеркнем, однако, что здесь “поток” существует только внутри одного маршрутизатора; не делается попыток сквозной (из конца в конец) установки соединения. Соответственно, не возникает и потребности в каких-либо новых протоколах, равно как и проблем интероперабельности.
Технология NetFlow Switching поддерживается, например, в маршрутизаторах для локальных сетей Catalyst 5500. Согласно утверждениям компании, эти маршрутизаторы в соответствующей комплектации могут перенаправлять десятки миллионов пакетов в секунду, достигая суммарной пропускной способности 50 Гбит/с (см. [16]). По результатам тестирования в испытательной лаборатории журнала Data Commucations Catalyst 5500 показал хотя и не рекордные, но вполне достойные результаты. Так, средняя величина задержки сетевых пакетов составила 174 мкс (см. [25]).
Несомненно, для сколько-нибудь продолжительных потоков данных технология NetFlow Switching действительно является оптимизацией, не только повышающей пропускную способность, но и уменьшающей задержки пакетов (всех, кроме первого в потоке). Администратор может более свободно применять дополнительные сервисы, не опасаясь деградации производительности.
6.2. Технология Tag Switching
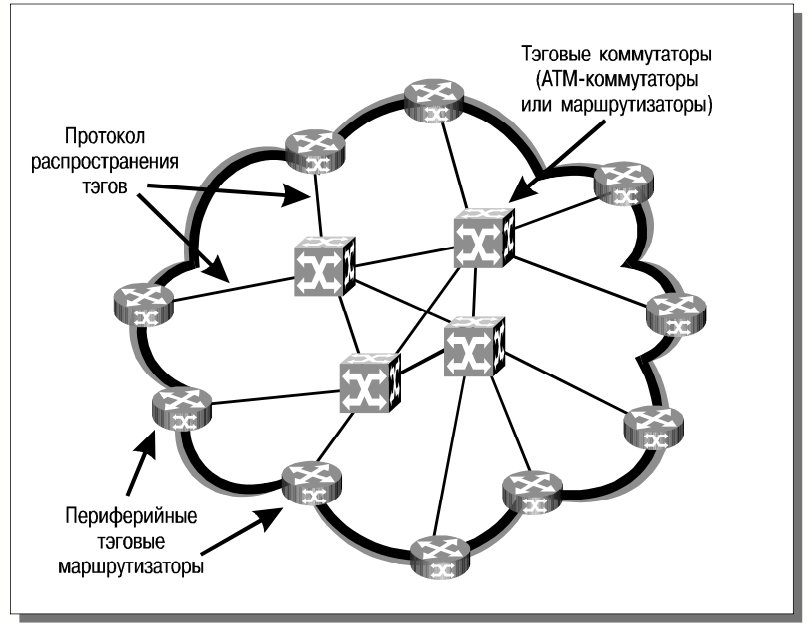
Как уже указывалось (см. выше раздел “Применение протоколов, упрощающих маршрутизацию”), идея технологии Tag Switching состоит в том, чтобы в областях концентрации трафика заменить поиск в таблице маршрутизации более простым действием – перенаправлением пакетов на основе анализа тэгов небольшого фиксированного размера. Компания Cisco Systems предлагает следующие компоненты для организации сетей с тэговой коммутацией (см. рис. 11):
- периферийные тэговые маршрутизаторы;
- тэговые коммутаторы, составляющие ядро сети;
- протокол распространения тэгов (Tag Distribution Protocol, TDP).
Работа сети с тэговой коммутацией выглядит следующим образом:
- Сначала периферийные тэговые маршрутизаторы и тэговые коммутаторы, работающие в режиме обычных маршрутизаторов и применяющие обычные протоколы (OSPF, BGP – Border Gateway Protocol, протокол обмена информацией между маршрутизаторами, входящими в разные области управления) выясняют топологию сети и строят взаимно согласованные таблицы маршрутизации.
- Затем на основе таблиц маршрутизации строятся информационные базы тэгов (Tag Information Base, TIB). Тэги ассоциируются с маршрутами или группами маршрутов для перенаправления пакетов. С помощью протокола TDP происходит взаимное согласование информационных баз соседних устройств (маршрутизаторов и/или коммутаторов).
- После этого периферийный тэговый маршрутизатор, получив пакет извне, анализирует сетевой заголовок, применяет необходимые сервисы сетевого уровня, выбирает маршрут, добавляет к пакету соответствующий маршруту тэг и направляет пакет тэговому коммутатору.
- Тэговый коммутатор, получив пакет, анализирует тэг и перенаправляет пакет дальше. Подчеркнем, что тэговому коммутатору не нужно анализировать сетевой заголовок пакета.
- На выходе из сети периферийный маршрутизатор приводит пакет “к нормальному виду”, удаляя тэг и обычным образом выполняя маршрутизацию.
Рассмотрим подробнее три взаимосвязанных вопроса – устройство тэговой информационной базы, процессы поиска в таблице тэгов и перенаправления пакетов тэговыми коммутаторами, а также функционирование протокола распространения тэгов.
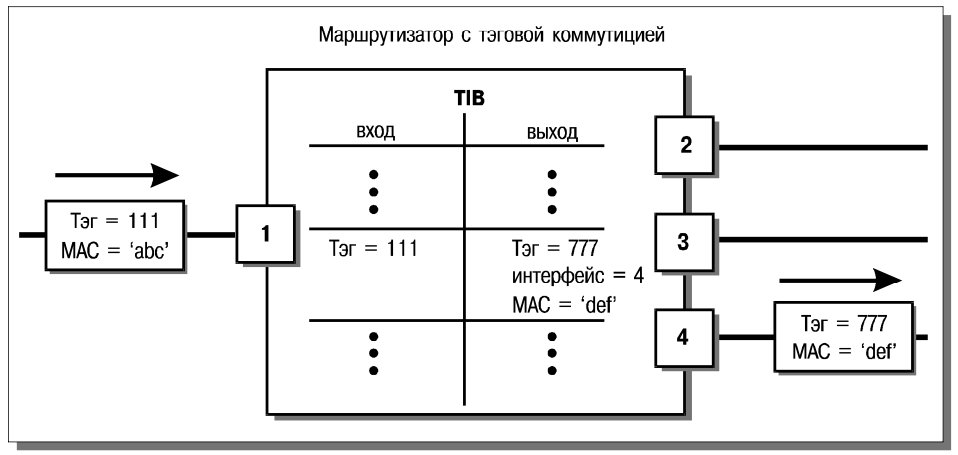
Каждая запись тэговой базы содержит по крайней мере четыре поля:
- входной тэг;
- выходной тэг;
- выходной порт;
- выходной MAC-адрес.
Когда коммутатор получает пакет, он ищет в базе запись, содержащую соответствующий входной тэг. Если такая запись существует, происходит модификация пакета (подставляются выходные тэг и MAC-адрес), после чего пакет отправляется в выходной порт. Рис. 12 иллюстрирует процесс тэговой коммутации.
В TIB-базе могут содержаться и многоадресные записи, используемые при перенаправлении multicast-пакетов.
Таким образом, при каждой коммутации тэг, содержащийся в пакете, меняется (в терминологии компании Cisco Systems это называется “label swapping” – смена меток), а для функционирования сети достаточно согласованной трактовки тэгов соседними устройствами (не нужно создавать и поддерживать глобальную таблицу соответствия тэгов и маршрутов). Более точно, достаточно, чтобы коммутатор или маршрутизатор правильно понимал тэги, помещаемые в пакеты устройствами, находящимися “вверх по течению” потоков данных. Эту задачу решает протокол TDP.
В соответствии с протоколом TDP, тэги могут распространяться вниз и вверх по течению. Одно устройство передает другому назначенный по своему усмотрению тэг (входной при передаче вверх и выходной при передаче вниз по течению) и связанный с ним сетевой адресный префикс. Если распространение идет вверх по течению, устройство-получатель заносит этот тэг в качестве выходного в запись TIB-базы, соответствующую переданному префиксу. При распространении вниз полученный тэг становится входным.
Такова, в несколько упрощенном виде, схема работы сети с тэговой коммутацией.
Для реализации предложенной технологии, по замыслу компании Cisco Systems, достаточно модернизации программного обеспечения существующих маршрутизаторов и ATM-коммутаторов. Например, речь может идти о маршрутизаторах семейства Cisco 7500 и коммутаторах Cisco StrataCom BPX.
Действительно, каждое из устройств делает совсем немного нестандартных действий (не считая поддержки протокола TDP). Так, маршрутизатор может поместить добавляемый тэг в заголовок сетевого уровня (поле метки потока в IPv6), в заголовок канального уровня (поле VCI ATM-ячейки) или между заголовками; рассмотренная в предыдущем разделе технология NetFlow Switching способна обеспечить эффективность этого процесса. Коммутаторы должны вести себя вполне в духе ATM (только без накладных расходов на установление соединений).
На самом деле ситуация несколько сложнее. Если в тэговый коммутатор поступит пакет с неизвестных тэгом, его (пакет) придется “честно” маршрутизировать, к чему коммутатор должен быть готов. Далее, если в сеть с тэговой коммутацией входит целая иерархия областей управления, придется добавлять к пакетам стек тэгов, выполняя над ним соответствующие операции на границах областей. Все это может заметно усложнить маршрутизаторы и коммутаторы и снизить эффективность их работы.
Механизм тэговой коммутации изначально задуман как исключительно гибкое средство, поэтому дисциплина назначения тэгов не фиксируется. Возможность ассоциирования тэгов с группами маршрутов (а не с IP-потоками) позволяет удержать размер тэга в разумных пределах, избегая “меточного взрыва”. Далее, кроме адресной информации, тэг может, например, специфицировать класс обслуживания, к которому пакет принадлежит. Правда, такая гибкость, помимо очевидных достоинств, порождает и не менее очевидные проблем интероперабельности.
Видимо, только практический опыт способен подтвердить или опровергнуть идеи, положенные в основу тэговой коммутации, хотя у столь крупной компании, как Cisco Systems, несомненно, найдется немало веских аргументов в поддержку технологии Tag Switching.
7. Технология IP Navigator компании Cascade Communications
Cascade Communications, недавно приобретенная компанией Ascend Communications, является одним из ведущих производителей оборудования Frame Relay и ATM. Естественно, это отразилось на подходе компании к решению проблем, стоящих перед крупными поставщиками Интернет-услуг и операторами связи. Технология IP Navigator, развиваемая в Cascade Communications уже несколько лет, предусматривает в первую очередь устранение недостатков, присущих коммутаторам (трудности с масштабированием сети, большие задержки при установлении виртуальных соединений) путем применения подходов, отработанных в маршрутизаторах.
В технологии IP Navigator, на периферии областей концентрации трафика располагаются маршрутизаторы, а внутри областей – коммутаторы (рис. 13). Маршрутизаторы обеспечивают подключение пользовательских сетей. Когда в такой маршрутизатор поступает IP-пакет, устанавливается новое виртуальное соединение с выходным маршрутизатором, обслуживающим соответствующие IP-адреса, или определяется идентификатор существующего соединения. Поступивший пакет и последующие пакеты IP-потока (если маршрутизатор умеет группировать пакеты в потоки) передаются по этому соединению через ряд промежуточных коммутаторов. В результате оказывается, что в “облаке с IP-навигацией” пакеты проходят только через два маршрутизатора. Это гарантирует высокую пропускную способность и малые задержки, а также поддержку классов обслуживания.
Чтобы обеспечить масштабируемость коммутируемых сетей, компания Cascade Communications предложила технологию Virtual Network Navigator (VNN), которая в духе протоколов маршрутизации предусматривает автоматический сбор и актуализацию информации о топологии сети, пропускной способности и загруженности каналов. По заявкам других подсистем (одной из которых является IP Navigator) VNN устанавливает виртуальные соединения с заданной полосой пропускания. Если соединение с требуемыми характеристиками установить невозможно, заказчик получает отказ. Это избавляет каналы связи от перегрузки, а существующие соединения – от деградации характеристик.
Задача установления виртуального соединения при прямолинейном подходе является вычислительно сложной, поскольку между N узлами может существовать N2 связей. Чтобы избавиться от квадратичного перебора и связанных с ним задержек, компания Cascade Communications предложила технологию Multipoint-to-Point Tunneling (MPT). Идея состоит в том, чтобы предварительно для каждого узла построить дерево узлов сети, доступных за 1, 2, ... шагов (рис. 14). Можно считать, что мы выпускаем из узла волну (или широковещательный пакет, если пользоваться сетевыми аналогиями) и следим за ее (его) распространением. Когда возникает необходимость установить виртуальное соединение между узлами A и B, берется MPT-дерево узла B, в нем находится узел A и выполняется подъем в корень (B).
Получается, что мы идем навстречу волне, за распространением которой следили при построении MPT-дерева. Очевидно, затрачиваемое при этом время по порядку величины не превосходит O(N).
Наверное, идеи, аналогичные MPT-технологии, приходили в голову всякому, кто, играя в “Lines”, хоть раз задумывался о том, как фишки находят путь из начальной клетки в конечную, минуя занятые поля. Тем не менее, в области Frame Relay и ATM это считается новым словом, которым компания Cascade Communications гордится.
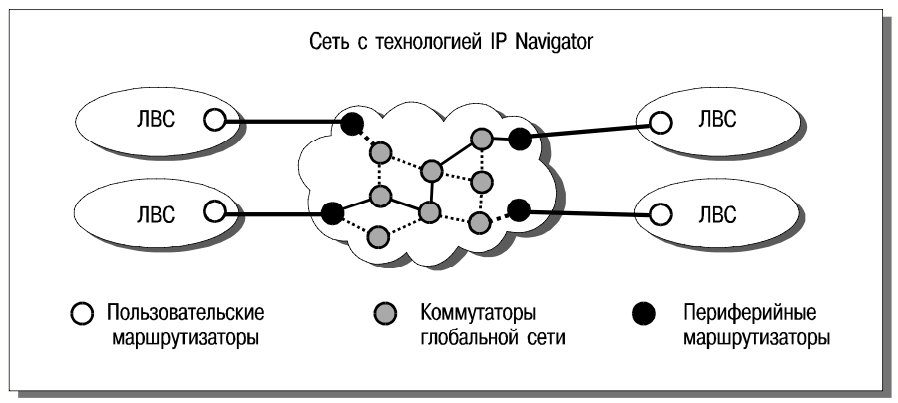
Для реализации технологии IP Navigator достаточно выполнить модернизацию программного обеспечения маршрутизаторов и коммутаторов. В существующих мультисервисных коммутаторах CBX 500 такая модернизация уже выполнена. Отметим, что эти коммутаторы поддерживают IP-маршрутизацию, причем перенаправлением пакетов занимаются интерфейсные модули. Тем самым обеспечивается высокая производительность и масштабируемость.
Технология IP Navigator относится в первую очередь к довольно специфической области мощного оборудования Frame Relay и ATM (периферийные маршрутизаторы играют подчиненную роль). Стремясь усилить рыночные позиции, компания Ascend Communications сотрудничает с поставщиками смежных технологий – корпорацией 3Com и компанией Ipsilon Networks. В результате могут родиться сквозные решения, обслуживающие все этапы взаимодействия оконечных систем, но это будет требовать стандартизации еще большего числа собственных протоколов.
8. Технология IP Switching компании Ipsilon Networks
Молодая компания Ipsilon Networks, образованная в 1994 году, начала свою деятельность с анализа ситуации в области высокопроизводительной маршрутизации. Специалисты компании опубликовали ряд статей (см. 20, 21]), в которых они обосновывали необходимость сочетания устойчивости, простоты и “локальности”, присущих IP, с эффективностью и предсказуемостью ATM. Для реализации этой идеи и была предложена технология IP-коммутации (IP Switching).
Основные компоненты IP-коммутатора показаны на рис. 15. Это контроллер IP-коммутатора (далее для краткости называемый просто контроллером), ATM-коммутатор и два протокола – общий протокол управления ATM-коммутатором (General Switch Management Protocol, GSMP) и протокол управления потоками (Ipsilon Flow Management Protocol, IFMP).
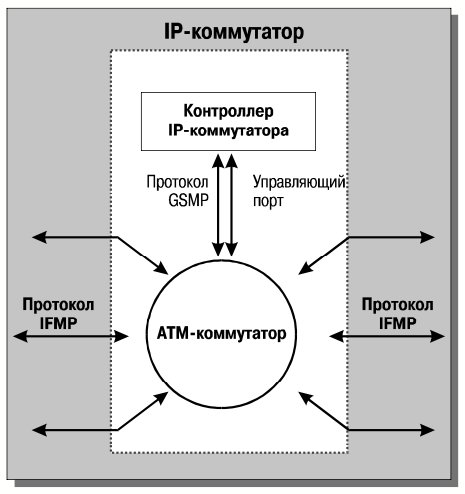
Контроллер можно представлять себе как маршрутизатор с дополнительным программным обеспечением для поддержки протоколов GSMP и IFMP (в первоначальных модельных конфигурациях в роли контроллера выступал обычный компьютер с процессором Pentium Pro и ATM-интерфейсом). В свою очередь, из ATM-коммутатора изымается стандартное программное обеспечение, лежащее над уровнем AAL-5, то есть удаляются сервисы эмуляции локальной сети и настройки адресов, а также поддержка протоколов маршрутизации и ATM-управления.
Вместо этого встраивается “ведомая” часть протокола GSMP, служащего для воздействия на аппаратуру ATMкоммутатора со стороны контроллера. Наконец, протокол IFMP используется для связи контроллера с соседними IP-коммутаторами (точнее, с их контроллерами).
По замыслу авторов технологии, контроллер, помимо выполнения функций обычного маршрутизатора, должен выявлять IP-потоки (в терминологии компании – проводить классификацию потоков) и с помощью соседних устройств “опускать” их (потоков) обработку со своего уровня на уровень аппаратуры ATM-коммутатора. Считается, что это позволит поднять примерно на половину десятичного порядка пропускную способность, минимизировать задержки и обеспечить поддержку классов обслуживания.
Рассмотрим подробнее, как функционирует IP-коммутатор. На первой фазе обычным для IP образом определяется топология сети, запоминается информация о соседних устройствах. В каждом физическом канале выделяется подразумеваемый виртуальный канал, используемый для передачи маршрутизируемого трафика и для взаимодействия контроллеров. Когда по этому подразумеваемому каналу поступает IP-пакет (точнее, составляющие его ATM-ячейки), он собирается и передается контроллеру через управляющий порт. Контроллер производит IP-маршрутизацию и перенаправляет пакет (через тот же управляющий порт и затем через выходной порт ATM-коммутатора) следующему IP-коммутатору (рис. 16).
Одновременно с маршрутизацией контроллер производит классификацию пакетов, оценивая, являются ли они началом потока. Технология IP Switching предусматривает два вида потоков: межкомпьютерные (для всех пакетов потока общими являются IP-адреса) и прикладные (кроме адресов, общими должны быть транспортный протокол и номера портов). Общие для всех пакетов потока поля заголовка в совокупности образуют идентификатор потока.
Как подсказывает здравый смысл и анализ статистической информации, целесообразно трактовать как поток взаимодействие по таким протоколам, как FTP и HTTP, но не DNS-запросы. Хотя локальность (отсутствие глобальной информации о состоянии устройств и каналов, отсутствие сквозных виртуальных соединений) – одно из основных свойств технологии IP-Switching, предполагается, что классификация потоков производится всеми IP-коммутаторами по единым принципам (важность этого положения будет ясна из дальнейшего изложения).
После того, как поток выявлен, контроллер выполняет три действия:
- Запрашивает у ATM-коммутатора номера свободных виртуальных каналов для физического порта, через который поступил пакет (номер A), и для управляющего порта (номер Z).
- Передает ATM-коммутатору GSMP-сообщение, предписывающее направлять ячейки, поступившие по виртуальному каналу A, в виртуальный канал управляющего порта Z.
- Передает соседнему IP-коммутатору, находящемуся “вверх по течению” выявленного IPпотока, IFMP-сообщение о перенаправлении. Это сообщение содержит идентификатор потока, номер виртуального канала A и время действия перенаправления. Сообщение предписывает направлять пакеты потока по виртуальному каналу A.
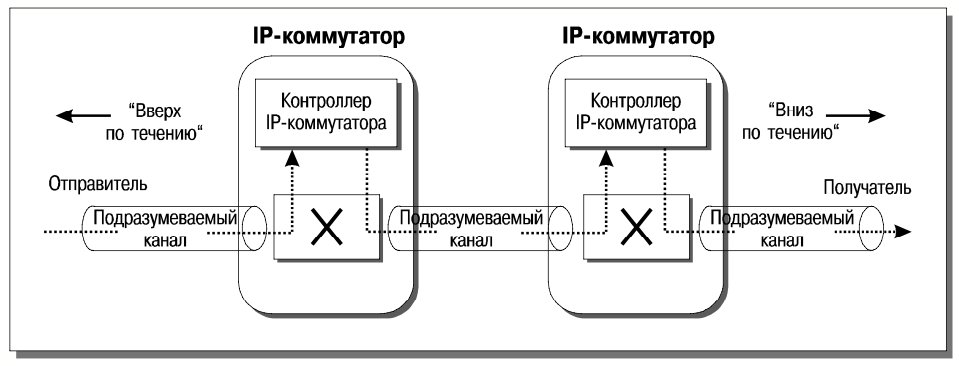
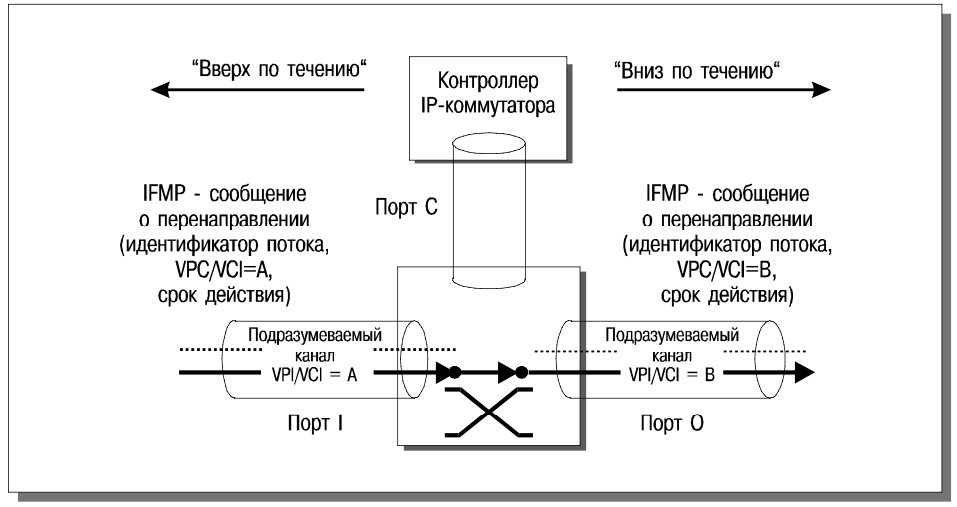
В результате этих действий контроллер будет получать пакеты потока через виртуальный канал Z, что, как и в технологии NetFlow, позволит быстро найти в кэше необходимую информацию и перенаправить пакет дальше. Данное состояние, однако, является промежуточным. В силу единообразия политики классификации потоков можно надеяться, что практически одновременно рассматриваемый IP-коммутатор получит сообщение о перенаправлении от соседа “снизу по течению”. Пусть это сообщение, пришедшее через выходной порт, содержит номер виртуального канала B. Тогда контроллер даст ATM-коммутатору команду перенаправлять ячейки из виртуального канала A входного порта в виртуальный канал B выходного порта. Это и есть цель технологии IP Switching – локальными средствами добиться перемещения IP-потоков на уровень аппаратуры ATM-коммутатора (рис. 17).
Такова в упрощенном виде схема работы IPкоммутатора.
Идеи, положенные в основу технологии IP Switching, кажутся очень привлекательными, однако их реализация сопряжена с рядом проблем. Как всегда в гибридных устройствах, сложности возникают на стыке. Во-первых, “опускание” IPпотока может произойти в момент, когда часть ячеек, составляющих IP-пакет, уже передана в контроллер, то есть пакет окажется испорченным. Во-вторых, первые коммутируемые ячейки могут обогнать последние маршрутизированные пакеты. В третьих, не ясно, насколько быстро весь поток на всем протяжении своего следования переместится на уровень ATM-аппаратуры и насколько стабильными будут в этот период задержки и качество обслуживания. Конечно, протокол IP достаточно устойчив, чтобы нейтрализовать последствия потери и переупорядочения пакетов, но как это скажется на эффективности? Результаты моделирования, приведенные в статьях [20, 21], не кажутся убедительными, поскольку они получены для отдельного коммутатора, а в многозвенной цепочке все определяет самое медленное и “некачественное” звено, которое к тому же будет перемещаться.
Еще одним сложным вопросом является безопасность технологии IP Switching. Когда весь поток переместится на уровень ATM-аппаратуры, перестанут работать имеющиеся в маршрутизаторах средства фильтрации. Злоумышленник сможет изменить некоторые поля передаваемых пакетов, а ATM-коммутаторы этого не заметят. Чтобы уменьшить риск, предусмотрено удаление из коммутируемых пакетов полей, составляющих идентификатор потока (эти поля можно однозначно восстановить на приемном конце). Тем не менее, для межкомпьютерных потоков остается возможность смены номеров портов, что представляет серьезную опасность. На практике это означает, что в каком-то месте IP-поток должен проходить не через IP-коммутатор, а через “честный” межсетевой экран, поскольку меры безопасности, предпринимаемые на начальном этапе сетевого взаимодействия, оказываются заведомо недостаточными.
Трудно сказать, как сложится судьба технологии IP Switching, однако ее концептуальная основа кажется спорной.
9. Технология Fast IP корпорации 3Com
“Кто что охраняет, тот это и имеет.” Эту простую истину взяла на вооружение корпорация 3Com, конек которой – сетевые карты. Для решения проблем маршрутизации специалисты 3Com разработали протокол, реализуемый программным обеспечением сетевых карт, а не маршрутизаторами или коммутаторами.
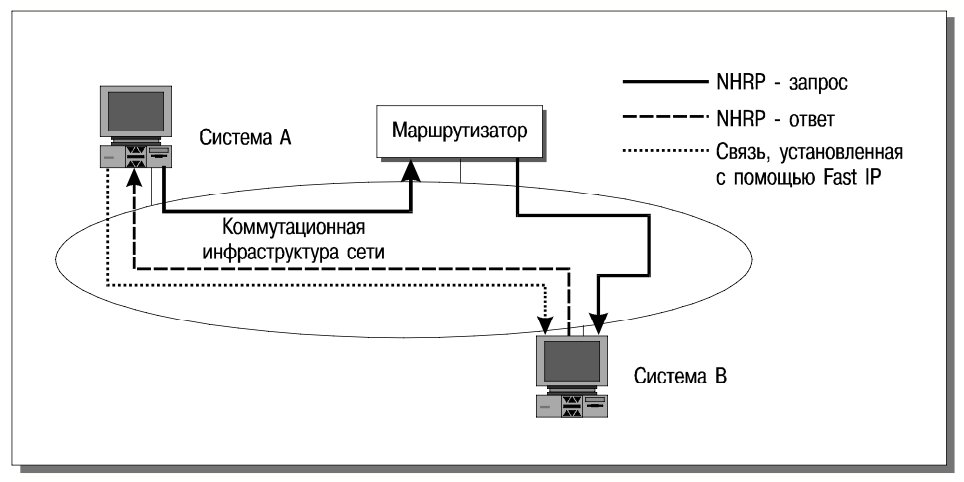
Этот протокол, представленный в качестве проекта в IETF, получил название Next Hop Resolution Protocol (NHRP, протокол определения ближайшего адресата). Он работает следующим образом. Пусть оконечная система A желает начать сетевое взаимодействие с системой B, входящей в ту же физическую сеть, но принадлежащую другой IP-подсети или виртуальной локальной сети, так что обычный путь от A к B пролегает через маршрутизатор. Система A стандартным образом начинает IP-взаимодействие, одновременно направляя B NHRP-запрос, содержащий MAC-адрес A. Этот запрос также проходит через маршрутизатор и достигает B. Получив запрос, система B извлекает MAC-адрес A и направляет по нему NHRP-ответ. Этот ответ доходит до A, минуя маршрутизаторы (мы предполагаем, что такой путь существует). Теперь A также узнает MAC-адрес B и может им воспользоваться (рис. 18).
Программное обеспечение, реализующее протокол NHRP, встраивается между уровнем драйвера сетевой карты и IP-уровнем. Корпорация 3Com предлагает такое обеспечение не только для своих карт, но и для карт других производителей (первоначально для операционных систем MS Windows 95/NT). Примечательно, что в феврале 1997 года компания IBM объявила о поддержке протокола NHRP в сетевых картах своих компьютеров, в том числе серверов.
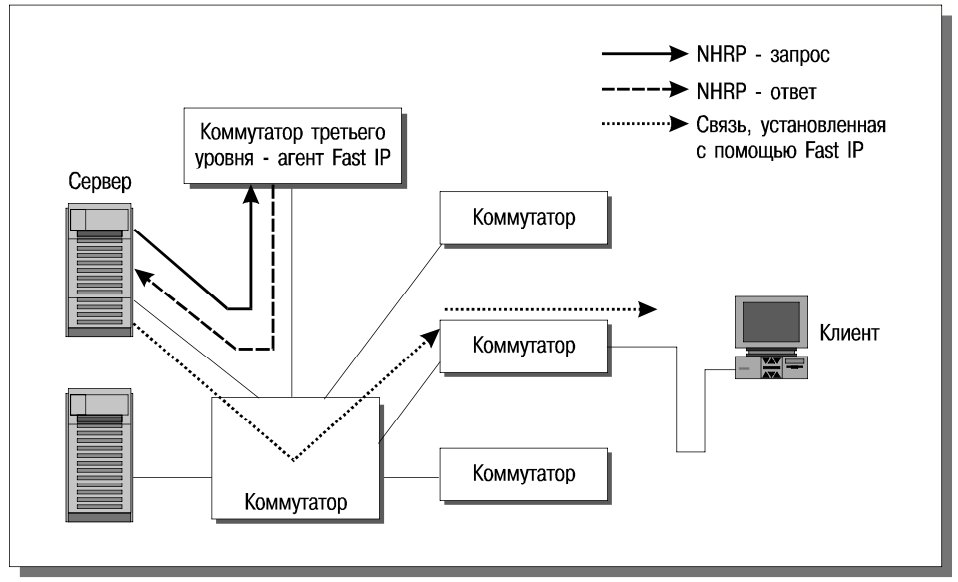
Если по какой-либо причине администратор сети может установить программное обеспечение Fast IP (FIP) только на часть систем (например, на серверные системы), то для поддержки протокола NHRP можно воспользоваться маршрутизаторами в роли агентов Fast IP (рис. 19). Здесь клиентская система не может ответить на NHRP-запрос, поскольку на ней нет необходимого программного обеспечения, зато за нее это может сделать маршрутизатор (при условии, что он понимает протокол NHRP, а клиентская система находится в “зоне прямой видимости”). В такой конфигурации технология Fast IP будет работать не на полную мощность – пакеты от клиента к серверу пойдут обычным, маршрутизируемым путем, однако потоки данных от серверов к клиентам, составляющие основную часть трафика, проследуют в обход маршрутизаторов.
Технология Fast IP не претендует на решение всех проблем, прямо или косвенно связанных с маршрутизацией. Так, масштабируемость коммутируемых сетей должна обеспечиваться какими-то другими средствами, а использующиеся для межсетевого экранирования маршрутизаторы должны уметь фильтровать NHRP-запросы. Тем не менее, Fast IP представляется важным оптимизирующим дополнением к механизму виртуальных локальных сетей, связь между которыми осуществляют маршрутизаторы.
10. Технология SecureFast компании Cabletron Systems
Если корпорация 3Com пытается решить сетевые проблемы, действуя на периферии, то компания Cabletron Systems, напротив, оставляет оконечные системы без изменений, реализуя все инновации в активном сетевом оборудовании, а именно в коммутаторах.
Технология SecureFast достаточно многогранна. Ее основные идеи были описаны выше, в разделе “Применение протоколов, позволяющих избежать маршрутизации”. Здесь мы остановимся на одном, на наш взгляд, наиболее важном аспекте – взаимодействии IP-хостов в сетях SecureFast [23].
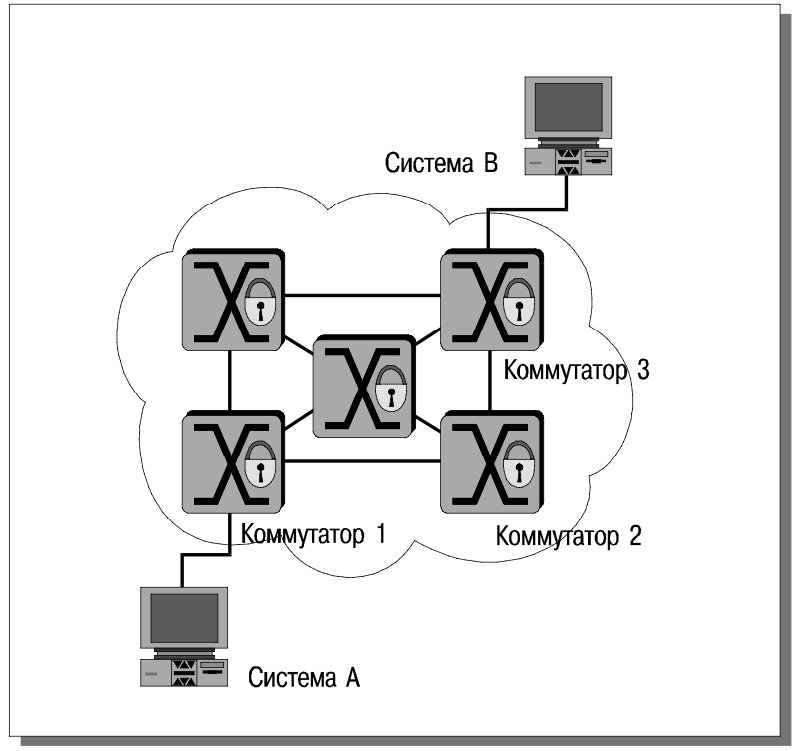
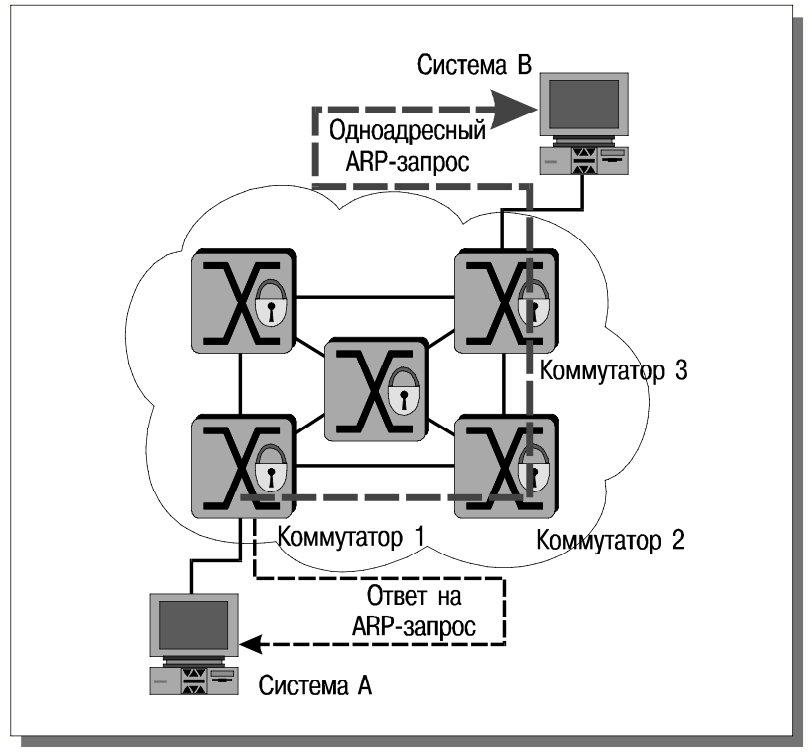
Идея состоит в том, чтобы установить виртуальное соединение между коммутаторами, к которым подключены взаимодействующие системы (на рис. 20 – между коммутаторами 1 и 3). Процесс установления соединения устроен следующим образом.
Все IP-хосты в сети SecureFast должны считать, что они входят в одну IP-(под)сеть. Добиться этого можно разными способами, например, сконфигурировав каждый хост как подразумеваемый шлюз для самого себя. В результате, когда хост A захочет начать взаимодействие с хостом B, он пошлет широковещательный ARP-запрос для выяснения MAC-адреса B. Коммутатор 1, перехватив этот запрос, возьмет на себя поиск адреса B. Сначала он поищет его в собственном каталоге (поддержка службы каталогов – составная часть технологии SecureFast), затем воспользуется помощью других коммутаторов. Естественно, до начала обслуживания оконечных систем коммутаторы выясняют топологию сети. Для этого применяется собственная разработка компании – протокол Switch Neighbor Discovery and Maintenance (SNDM, протокол выяснения и поддержки смежности коммутаторов). Для оперативного отслеживания состояния каналов используется еще один собственный протокол – Virtual Link State Protocol (VLSP, протокол отслеживания состояния виртуальных каналов), построенный в духе OSPF.
Итак, в конце концов коммутатор 1 узнает MAC-адрес B. Одновременно он определит путь от A до B. Чтобы закончить установление соединения, коммутатор 1 пошлет системе A ответ на ARP-запрос (от имени хоста B), а также направит B первоначальный ARP-запрос A (рис. 21), чтобы обе взаимодействующие оконечные системы узнали MAC-адреса друг друга.
При установленном соединении коммутатор помнит соответствующие входной и выходной интерфейсы. Идентификатором соединения служит пара (исходный адрес, целевой адрес), возможно, с добавлением номеров портов транспортного уровня или иной информации. С точки зрения оконечной системы происходит взаимодействие в рамках локальной сети, коммутаторы работают исключительно на уровне 2, без преобразования заголовков пакетов второго уровня. Логику работы сети SecureFast можно выразить фразой “один раз маршрутизировать (хотя это не совсем маршрутизация), потом коммутировать”.
Технология SecureFast поддерживается в семействе высокопроизводительных многопротокольных коммутаторов SmartSwitch [24]. Так, модель SmartSwitch 6000 обладает суммарной пропускной способностью 2 миллиона пакетов в секунду. Такую скорость обеспечивает параллельная работа пяти интерфейсных модулей, каждый из которых снабжен заказной микросхемой и универсальным процессором i960.
Видимо, компания Cabletron Systems лидирует почислуновыхсобственныхпротоколов. Ксожалению, такое лидерство является скорее недостатком, чем достоинством. То, что спецификации всех протоколов переданы в IETF для всеобщего ознакомления, еще не значит, что они будут утверждены в качестве стандартов и получат широкую поддержку. До тех пор сети SecureFast будут оставаться специфическими Cabletron-облаками, которые, конечно, могут взаимодействовать с маршрутизаторами других производителей, но внутри состоят исключительно из оборудования компании Cabletron Systems.
11. Заключение
Мы рассмотрели целый ряд подходов к проблеме маршрутизации, имеющих различные области применения и разную степень новизны. Некоторые из описанных технологий не вписываются в существующие представления о сетях и представляют собой принципиально новые подходы к построению сетей. Другие, напротив, разработаны для плавной адаптации существующей инфраструктуры к новым условиям эксплуатации. Какие же подходы и технологии предпочесть? Какое оборудование выбрать?
На наш взгляд, наиболее естественным и практичным является подход, связанный с повышением производительности компонентов маршрутизаторов и распараллеливанием их работы при сохранении традиционных протоколов маршрутизации. Кроме рассмотренных продуктов Accelar и Corebuilder, данное направление поддержано в весьма продвинутых маршрутизирующих модулях 3LS компании Madge Networks (точнее, ее подразделения LANNET) и маршрутизаторах семейства NetIron компании Foundry Networks [25]. Модуль 3LS способен маршрутизировать миллион пакетов в секунду, а NetIron – 7 миллионов. При этом задержки составляют порядка 10 мкс. К этой же группе можно отнести маршрутизаторы StreamProcessor 2400 и IP9000. В перспективных разработках компаний Pluris [26] и NetCore Systems планка производительности поднимается еще выше, до терабитных скоростей. Так что у метода “грубой силы” остается масса резервов, особенно если учесть прогресс в области проектирования и изготовления заказных микросхем.
Менее бесспорным выглядит эффект оптимизации, основанной на идее кэширования.
Насколько велико “рабочее множество” используемых сетевых адресов? Не приведет ли частая “подкачка” в кэш к деградации производительности? Каков должен быть оптимальный размер кэша и насколько он стабилен на протяжении жизненного цикла сети? Только на практике можно получить ответы на эти и аналогичные вопросы, но каждый ли согласится с ролью подопытного?
Все подходы, связанные с упрощением или устранением маршрутизации, нуждаются, помимо практической проверки, в тщательном теоретическом анализе, особенно с точки зрения масштабируемости и информационной безопасности. Как поведет себя большая система? Нет ли у злоумышленника возможности менять поля сетевых пакетов после установления виртуального соединения? Вопросов такого рода много, и до получения исчерпывающего ответа на них едва ли стоит доверяться новым технологиям. Кроме того, целесообразно проследить за ходом стандартизации новых протоколов, так как от этого решающим образом зависит судьба использующих их продуктов.
12. Литература
1. Архитектура персональных сетей (материал компании Bay Networks). – Jet Info, 1997, 8.
2. Кнут Д. Искусство программирования для ЭВМ. Т. 3. Сортировка и поиск. – М.: Мир, 1978.
3. Routing Switch. White Paper. – Bay Networks, 1997. 4.Routing Switches. Accelar 1000 Family. White Paper. – Bay Networks, 1997.
5. Routing Switches. Accelar 100. White Paper. – Bay Networks, 1997.
6. Routing Switch Technology. White Paper. – Bay Networks, 1997.
7. Ciampa R. Flexible Intelligent Routing Engine (FIRE). The Third-Generation Layer 3 Switching Architecture from 3Com. – 3Com Corporation, 1997.
8. CoreBuilder 3500. Layer 3 High-Function Switch. – 3Com Corporation, 1997.
9. CoreBuilder 3500 Layer 3 High-Function Switch Fast Ethernet Switching/Routing Throughput. – 3Com Corporation, 1997.
10. Roberts E. The Softer Side of Routing. – Data Commucations, Jan. 1998.
11. StreamProcessor 2400. – Neo Networks, 1997.
12. The IP9000 Gigabit Router Architecture. Technical Paper. – Torrent Networking Technologies, 1997.
13.Torrent IP9000 Gigabit Router. Product Backgrounder. – Torrent Networking Technologies, 1997.
14. NetFlow Switching Overview. – Cisco Systems,
15. Scaling the Internet With Tag Switching. White Paper. – Cisco Systems, 1997.
16.Catalyst Supervisor Engine III. Data Sheet. – Cisco Systems, 1998.
17. Semeria C. Next-Generation Routing for Enterprise Networks: 3Com’s Fast IP, Cisco’s Netflow Switching, Ipsilon’s IP Switching, and Cabletron’s Secure Fast. – 3Com Corporation, 1997.
18.Semeria C. Next-Generation Routing for ISPs: Cascade’s IP Navigator and Cisco’s Tag Switching. – 3Com Corporation, 1997.
19. IP Navigator. White Paper. – Cascade Communications, 1996.
20. Newman P., Minshall G., Lyon T., Huston L. (Ipsilon Networks). IP Switching and Gigabit Routers. – IEEE Communications Magazine, Jan. 1997.
21. Newman P., Minshall G., Lyon T. (Ipsilon Networks). IP Switching: ATM under IP. – IEEE/ACM Transactions on Networking, Aug. 1997.
22.SecureFast Virtual Networking. Function and Structure. – Cabletron Systems, 1997.
23. IP Host Communication in Bridged, Routed and SecureFast Networks. – Cabletron Systems, 1997.
24. SmartSwitch 6000 – A high-performance, economical switching chassis for the wiring closet supporting up to five interface modules. – Cabletron Systems, 1997.
25. Mandewille R., Newman D. Multilayer Switches. In the Beginning. – Data Commucations Magazine, Nov. 1997.
26. Pluris Massively Parallel Routing. White Paper. – Pluris Inc., 1997.

