 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
О повышении производительности BI-системы с помощью кластерного решения
Проекты внедрения BI-систем, как правило, инициируются небольшой группой ключевых бизнес-пользователей и изначально представляют собой локальные работы. Но они имеют свойство в дальнейшем разрастаться до огромного количества аналитических отчетов разной степени детализации и масштабов сотен и тысяч пользователей. Помимо стандартной конфигурации в виде сервера с отчетами и доступом через тонкий/толстый клиент, компании «ставят» и мобильные приложения, и сложные системы разграничения прав доступа. В чем причина подобных разрастаний BI-проектов?
Как только первые пользователи начинают эксплуатировать аналитическую систему, новость о ее появлении расходится по всей компании. Поступают новые заказы на отчетность от различных департаментов, и требования к функционалу BI-платформы стремительно разрастаются. Проходит несколько месяцев, и вычислительной мощности в виде одного сервера, являющегося минимальной конфигурацией для стартового решения, перестает хватать. Необходимо перестраивать архитектуру системы: анализируя темпы роста требований к производительности, формировать оптимальную серверную конфигурацию.
Самый оптимальный вариант решения проблемы с производительностью системы – переход к кластерной конфигурации. Именно его мы реализовали для одного из крупных российских ритейлеров. Компания внедрила систему отчетности, построенную на платформе QlikView. Изначально под нее был заложен 1 сервер, на котором с 3–4 отчетами работали 4–5 пользователей. Постепенно число и тех, и других увеличивалось. Сейчас система насчитывает 25 отчетов, с ними одновременно работает до 40 пользователей. При этом в каждый отчет входят 7–12 таблиц справочников по 1 млн строк и 1 таблица фактов с 1 млрд строк. Задача проведения in-memory вычислений на одном сервере с таким количеством данных невыполнима, поэтому мы совместно с компанией решили перевести систему на кластерную конфигурацию. Сейчас она включает в себя 12 серверов.
Налево пойдешь, направо пойдешь
Кластер для BI-решения призван решать задачу повышения общей производительности системы. Обеспечение отказоустойчивости в данном случае является задачей второго приоритета, так как BI-решения не являются бизнес-критичными системами.
При создании кластера для BI-системы могут быть использованы 2 подхода. Первый подразумевает построение классического кластерного решения. В этом случае управление распределением (балансировкой) нагрузки между серверами осуществляет операционная система. Желательно, чтобы серверы были идентичны по техническим характеристикам, а еще лучше, чтобы были они относились к линейке одного производителя. Для BI-системы такое решение выглядит как один мощный сервер с большим количеством процессоров и оперативной памяти. Немаловажными «дополнениями» являются система резервного копирования (СРК) и модель здоровья. СРК позволяет восстановить данные из копии в случае аварии на стороне хранилища, а модель здоровья дает возможность своевременно отслеживать общее состояние системы и каждого из узлов.
Классические кластеры делятся на 2 вида по надежности:
- асимметричный: в кластере всегда присутствует резервный сервер, который в случае выхода из строя любого из узлов заменяет его;
- симметричный: все серверы работают с разными приложениями, в случае выхода из строя любого из узлов нагрузка перераспределяется между остальными узлами.
Второй подход – это «виртуальный» кластер. В этом случае BI-система связывает серверы в единую сеть и распределяет нагрузку между ними. Виртуальные кластеры всегда асимметричны и требуют ручного подключения резервного сервера в аварийном случае. При этом такие системы гораздо проще в настройке и обладают более гибкими возможностями в части конфигурирования по сравнению с классическими кластерами.
То есть в «BI-кластере» BI-система распределяет нагрузку по серверам, входящим в кластер. Данный процесс управляется только балансировщиком нагрузки BI-системы, операционные системы серверов не играют никакой роли в этом процессе (как это было бы при создании классического кластера).
В качестве примера виртуального кластера можно рассмотреть аналитическую систему на платформе QlikView, предназначенную для анализа большого объема данных (см. рис. 1).
Рис. 1. Кластерная архитектура BI-системы на платформе QlikView
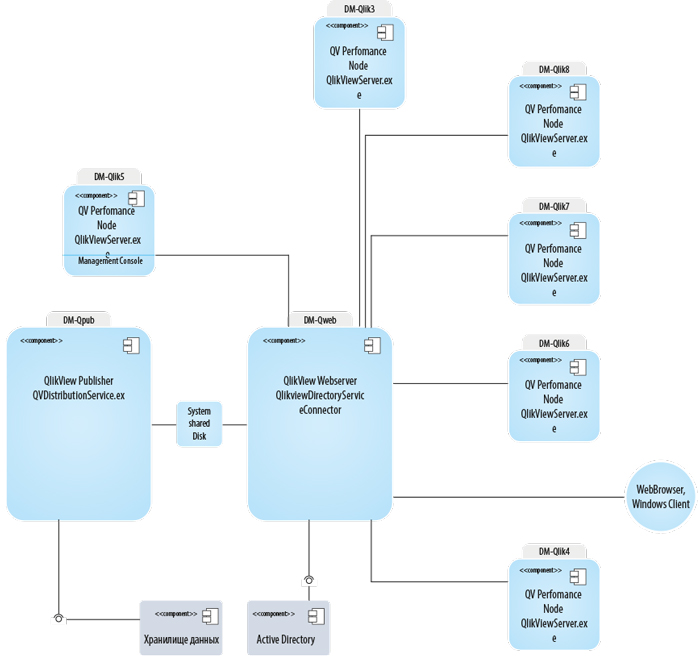
В роли основных нагрузочных узлов выступают высокопроизводительные серверы DM-Qlik3, DM-Qlik4 и т.д. Их количество ограничивается только лицензией платформы, которую при необходимости всегда можно расширить.
В роли балансировщика нагрузки и точки доступа пользователей выступает небольшой виртуальный сервер DM-Qweb. Настройки платформы позволяют варьировать конфигурацию балансировщика нагрузки и распределение пользователей между серверами.
Сервер обновлений (DM-Qpub) отвечает за подключение к хранилищу данных, их дальнейшую обработку и загрузку в конечное приложение.
Перечислим ключевые показатели, которые необходимо учитывать при построении кластерных систем:
- производительность системы;
- возможность переноса нагрузки между узлами;
- одновременный доступ узлов к хранилищу данных;
- время восстановления работоспособности при авариях;
- скорость СРК;
- возможность мониторинга состояния системы (наличие модели здоровья).
Для расчета оптимальной конфигурации кластерного решения необходимо четко расставить приоритеты этих показателей, исходя из потребностей компании, ведь все параметры кластера взаимосвязаны. Например, увеличение производительности системы может привести к ухудшению степени ее готовности. Также при прогнозировании потребления ресурсов кластера следует учитывать рост и возможное изменение потребностей в ближайшем будущем (на 1–2 года вперед).
Таким образом, задача повышения производительности небольших и в то же время стремительно развивающихся BI-систем может быть «закрыта» путем перехода с одиночного сервера к кластерной конфигурации. Главное в этом деле – приоритизировать основные параметры производительности, детально продумать архитектуру, правильно настроить систему и спрогнозировать ее дальнейшее развитие.

