Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Как правильно строить защиту больших данных?
Какие ИБ-проблемы есть у Hadoop?
Существует ли универсальная пилюля от всех уязвимостей Big Data?
Вокруг термина Big Data идет множество споров. На мой взгляд, за ним скрываются два понятия: «объем» и «технологии». Большой объем данных без эффективной обработки — это свалка, а использование технологий без должного количества информации бессмысленно.
Hadoop — одно из самых распространенных и активно развивающихся решений для работы с Big Data. Это платформа с открытым исходным кодом, в основе которой лежит распределенная файловая система. Поверх нее функционируют различные сервисы для обработки информации. Hadoop позволяет реализовывать распределенные вычисления и хранение данных. На действительно больших объемах информации — десятках и сотнях терабайт — платформа работает эффективнее классических реляционных БД.
У большинства крупных заказчиков решение Hadoop либо уже есть, либо скоро появится. В основном используются сборки от трех вендоров: американской компании Cloudera, вошедшего в ее состав разработчика Hortonworks и российского производителя Arenadata.
ИБ-проблемы Hadoop и методы их решения
По умолчанию в Hadoop отключена аутентификация пользователей. Сегодня поисковик Shodan выдает около 900 публично доступных сервисов HDFS (распределенная файловая система Hadoop) без какой-либо аутентификации. Среди результатов поиска можно найти даже такие примеры, как почти 500 ТБ общедоступных данных (см. рис. 1).
На первый взгляд может показаться, что разграничение прав все-таки присутствует и получить доступ к данным мы не можем (см. рис. 2).
Но это ограничение можно легко обойти, если представиться системным пользователем (см. рис. 3).
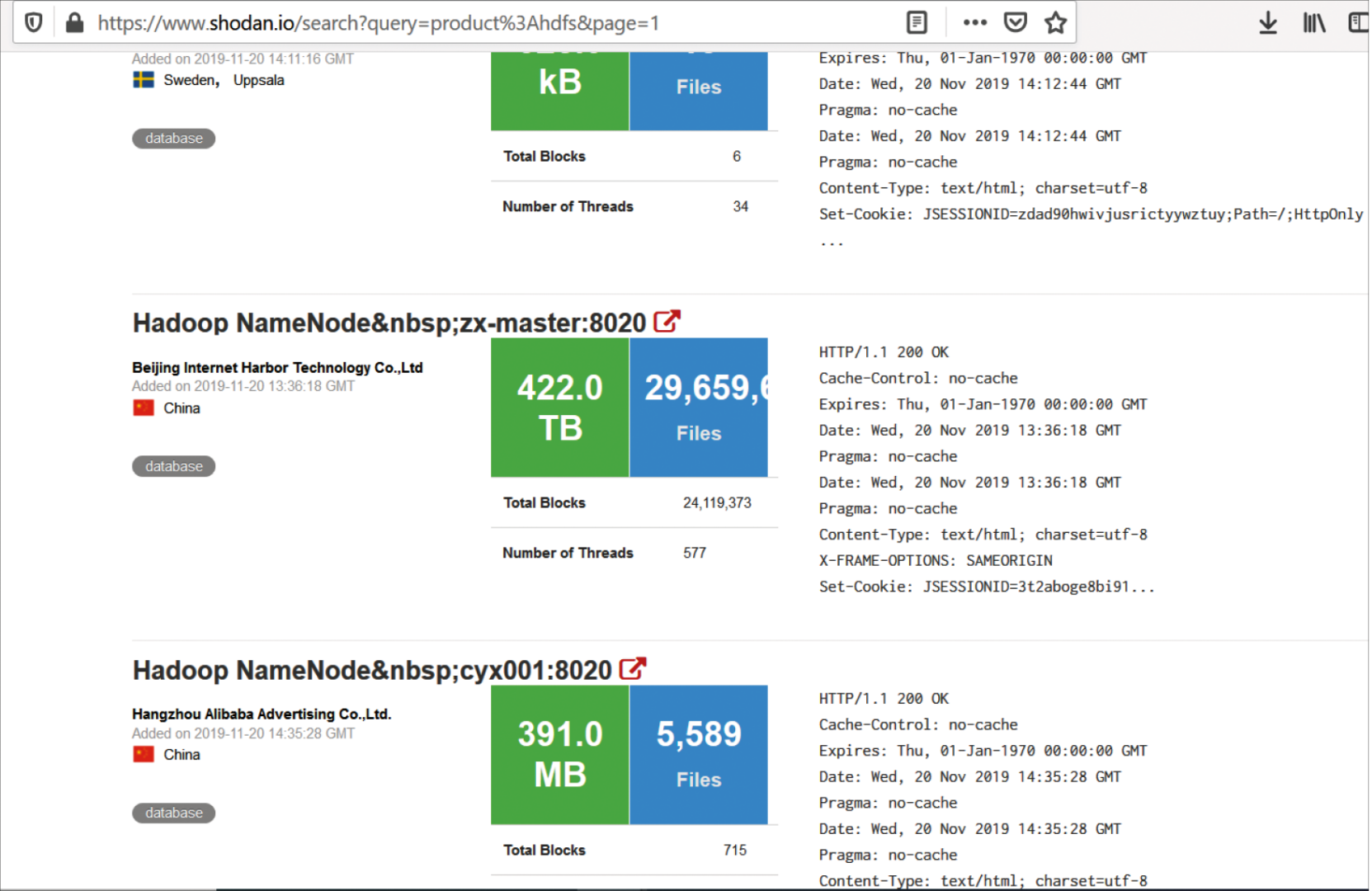
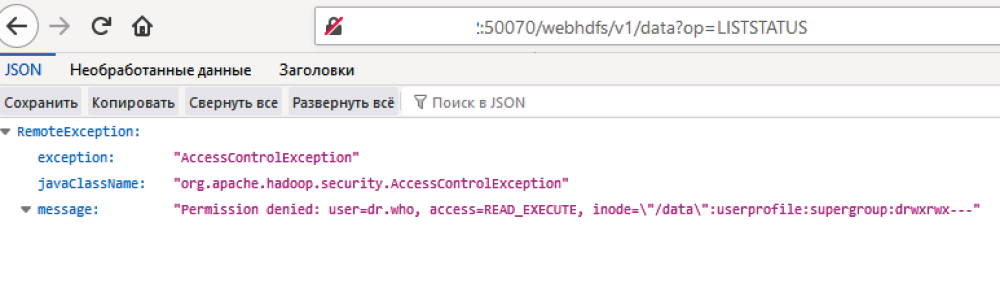
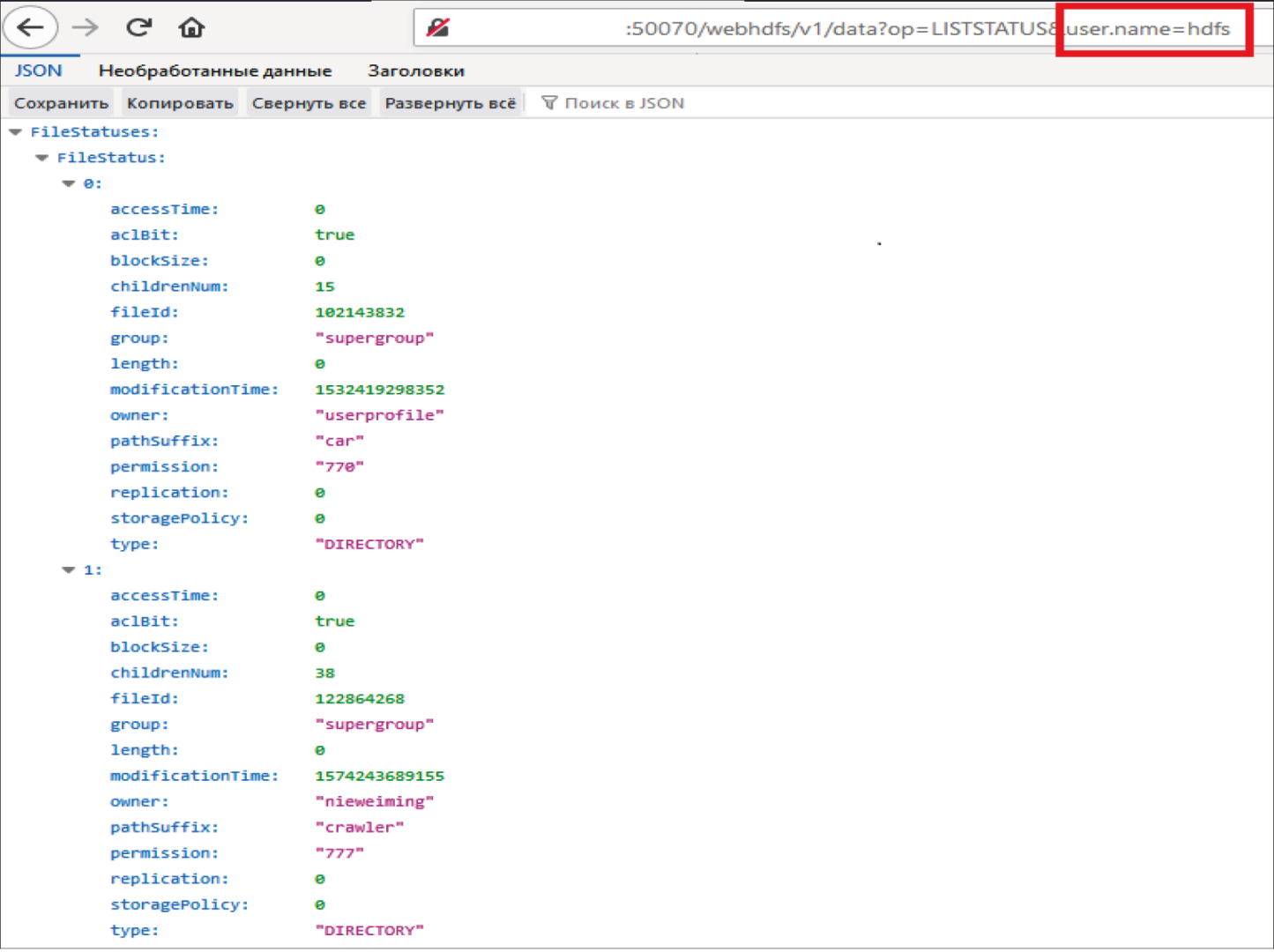
Из-за отсутствия аутентификации злоумышленники могут получить доступ к данным компании, представившись системным пользователем. Эта проблема решается либо настройкой аутентификации отдельно для каждого сервиса, либо включением Kerberos для кластера целиком (керберизацией). Последний вариант значительно удобнее, но практика показывает, что не на всех инсталляциях процесс проходит гладко. Мы столкнулись с такой проблемой на проекте для одного из российских промышленных предприятий. Попытки керберизации кластера заканчивались безуспешно, поэтому мы включили механизм аутентификации отдельно для каждого используемого сервиса.
Многие сервисы Hadoop по умолчанию работают без SSL. Проблема особенно актуальна, когда данные выходят за пределы защищенного контура компании (если он вообще существует). Решается она очевидным образом — включением SSL для каждого сервиса.
Еще одна ИБ-проблема — отсутствие защищенного контура у кластера Hadoop. Так, у платформы полно точек входа, данные поступают из множества систем, поэтому она представляет собой лакомый кусочек для злоумышленников. Если не ограничить поток пользователей (например, средствами межсетевого экранирования), вполне возможна утечка. Другой вариант — организация единой точки входа в систему встроенными средствами Hadoop. Но если у вас нет защищенного контура, это не сработает.
Слишком широкие права доступа пользователей (администраторов, разработчиков, датамайнеров, представителей бизнеса и т.д.) тоже создают сложности. Но это не лишние пользователи, которых можно просто отсечь, — специалисты должны продолжать работать, иначе бизнес встанет.
Вопрос прав доступа часто вскрывает в компании большой пласт проблем, напрямую не связанных с Big Data. Это непонимание бизнес-задач подразделений и перечня данных, к которым им действительно необходим доступ; отсутствие или плохая работа механизмов классификации и обезличивания информации; нехватка контроля действий администраторов. Решить все эти проблемы исключительно средствами Hadoop или только за счет наложенных средств защиты не удастся. Нужно менять либо создавать определенные процессы внутри организации (как минимум реализовать классификацию данных).
Универсальной «пилюли», способной решить все ИБ-проблемы Hadoop, к сожалению, не существует. Нужно использовать и встроенные, и наложенные средства защиты.
Кейс
Проблема
В одном из банков мы решали ИБ-задачу на стыке проблем защиты контура и разграничения прав доступа пользователей. Тестовая инсталляция Hadoop содержала продуктивные данные, и они поступали с задержкой в несколько недель. Но за это время информация не теряла актуальности и оставалась критичной для бизнеса. При этом обезличивание не применялось, а в тестовом контуре, помимо кластера Hadoop, находились и другие системы. Соответственно, компрометация любого из серверов могла привести к утечке данных из Hadoop.
Решение
Мы рекомендовали выделить тестовый кластер в отдельный VLAN и использовать механизмы обезличивания данных как в тестовых системах-источниках, так и в самом Hadoop.
Безопасность Big Data
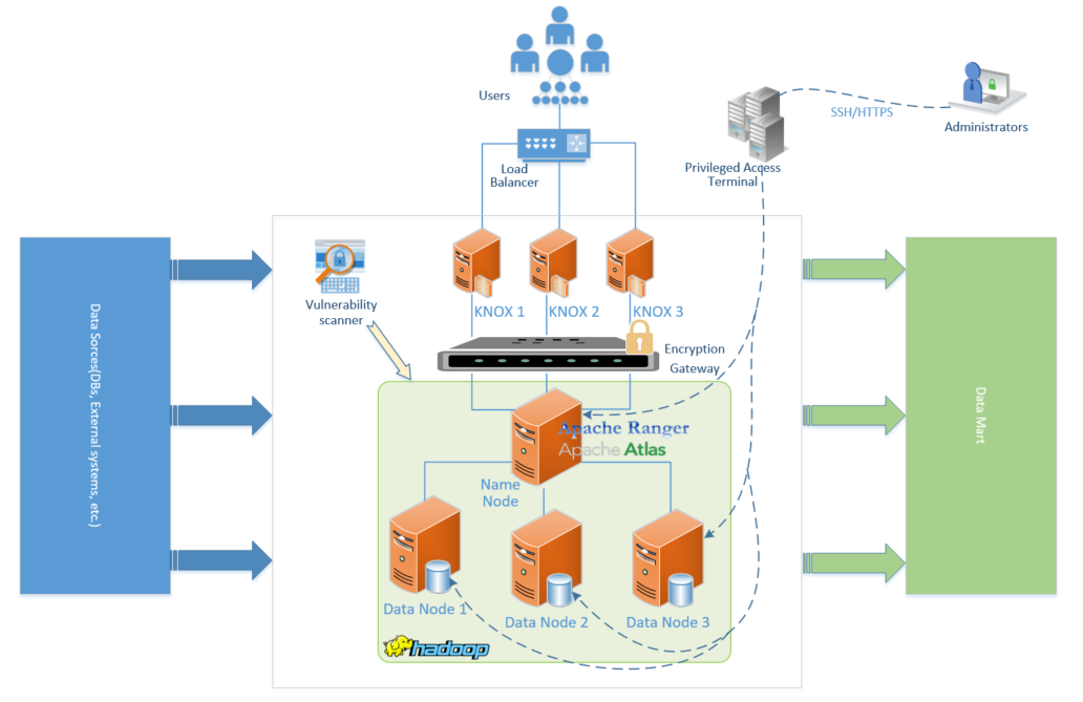
Начинаем с инфраструктуры
01
Формируем защищенный контур с помощью межсетевого экрана.
02
Организуем доступ пользователей к сервисам Hadoop через Apache KNOX. Это встроенное средство защиты, обеспечивающее единый прокси для сервисов платформы.
03
Сканируем инфраструктуру и установленное на серверах ПО при помощи сканеров уязвимостей.
04
Контролируем доступ и действия администраторов на уровне операционной системы через решения класса PIM/PUM/PAM. Как минимум, целесообразно записывать сессию администратора.
Движемся к защите данных
01
Шифруем данные на уровне распределенной файловой системы встроенными средствами защиты Hadoop.
02
Организуем разграничение доступа к данным с помощью Apache Ranger. Это средство защиты, которое встраивается плагином в каждый сервис Hadoop. Оно позволяет определить привилегии доступа каждого пользователя и проаудировать действия, которые проводились с конкретными данными. Как показывает практика, не все заказчики сразу готовы приступить к разграничению доступа, особенно если Hadoop раньше работал без этого механизма. В таких случаях лучше начать с аудита, оценить текущую ситуацию и постепенно переходить к созданию правил.
03
Проводим мониторинг активности пользователей Hadoop при обращении к данным. Можно сделать это и средствами Apache Ranger, но в нем достаточно топорная отчетность (всего один вариант отчета без каких-либо глубоких настроек). Еще хуже обстоит ситуация с интеграцией с системами мониторинга событий ИБ и отправкой уведомлений: штатные средства интеграции фактически отсутствуют. Гораздо более удачный вариант — решения класса Database Activity Monitoring (DAM). Среди их преимуществ можно отметить более гибкую отчетность, возможности интеграции с другими системами и интерфейс управления политиками безопасности.
04
Маркируем и тегируем данные средствами Apache Atlas. В дальнейшем теги можно использовать в политиках Ranger, что существенно упрощает процесс разграничения доступа. Вместо нескольких сотен и даже тысяч объектов мы получаем считанное число тегов. Инструмент не предполагает какой-либо встроенной автоматизации, но у него есть API. Так, на одном промышленном предприятии мы размечали объекты в Excel (благо их было не слишком много) и передавали результаты в Atlas по API. Это позволило сократить число ручных операций в Atlas.
05
Выполняем шифрование, маскирование или токенизацию данных. Это, пожалуй, лучшее, что может произойти с ними, поскольку метод защищает данные вне зависимости от того, кто и откуда к ним обращается. Если большому числу пользователей, например разработчикам или датамайнерам, требуется работать с разнообразной информацией, ограничивать их политиками доступа нельзя. Критичные данные нужно зашифровать или замаскировать, чтобы избежать утечки через этот канал. При этом важно как можно раньше определить, каким пользователям действительно нужно видеть те или иные данные с точки зрения их бизнес-задач, — без этого весь процесс теряет смысл.
Если собрать все средства защиты вместе, выглядеть это будет примерно так (см. рис. 4).