Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Случилось так, что представление о СУБД сложилось у большинства отечественных пользователей на основе опыта использования систем на платформе персональных компьютеров, таких как FoxBASE, Paradox, Clipper, dBASE, Clarion и т.д.
Причины такой популярности можно усмотреть как в широком распространении персональных компьютеров в бывшем СССР, так и в относительной простоте и легкости изучения и освоения самих СУБД. Свою роль сыграли и практически неограниченные возможности нелегального копирования программного обеспечения.
Начало активного использования персональных СУБД в нашей стране по времени совпадает с началом бума персональных компьютеров (1986-87 гг.), который сегодня, к счастью, постепенно спадает. За это время на их основе создано множество программ и выросло целое поколение разработчиков, ориентированных на них в своей профессиональной деятельности. Широкое распространение получили наивные представления о том, что персональный компьютер (и его программное обеспечение, в том числе и СУБД) представляет собой универсальное средство автоматизации, пригодное для использования в любых сферах человеческой деятельности, от самых простых до самых сложных.
Эти представления, в свою очередь, объясняются как общей низкой технологической культурой в сфере информатизации, так и психологическими факторами, такими как тенденция к упрощению и стремление копировать техническое решение соседа, совершенно не вникая в детали. Широкое распространение персональных СУБД, сопровождавшееся несколько односторонним освещением проблем обработки данных в компьютерной прессе, отвлекло внимание пользователей от СУБД более высокого класса. Это — многопользовательские профессиональные СУБД, которые и были изначально ориентированы на решение сложных технологических проблем, возникающих в большинстве средних и крупных предприятий и учреждений.
В результате возникла парадоксальная ситуация, когда персональные СУБД используются для автоматизации таких задач (например, в финансовой сфере), которые априори требуют инструментальных средств с совершенно иными функциональными возможностями и идейным багажом.
К счастью, положение дел начало меняться к лучшему. В настоящее время большинство средних и крупных государственных и коммерческих организаций постепенно отказываются от использования только персональных компьютеров и начинают всерьез задумываться о создании действительно открытых и распределенных информационных систем на мощной компьютерной платформе. Переломным в этом смысле стал 1994 год, в течение которого в нашей стране можно было наблюдать взрыв интереса к многопользовательским СУБД. Сегодня, видимо, нет серьезных факторов, сдерживающих распространение таких систем, если не считать скромные финансовые возможности многих организаций и слабую информированность пользователей в технологической сфере.
Однако сам по себе переход к многопользовательским СУБД — это не просто освоение новой системы. Он представляет собой качественный технологический скачок, требующий не только чисто технических, но и административных, кадровых, финансовых и других решений. Один из ключевых вопросов такого перехода — какими критериями руководствоваться при выборе профессиональной СУБД в качестве основы для создания информационной системы современной организации, осознавая тот факт, что такой выбор определяет перспективы ее деятельности не на один-два года, но на срок в 10-15 и более лет. Если данный цикл статей поможет хоть в какой-то степени найти ответ на этот вопрос, я сочту свою задачу выполненной.
Мне хотелось бы поблагодарить всех, кто принимал участие в работе над статьями. Я особенно признателен Владимиру Елисееву, многочисленные консультации с ним помогли мне сформулировать основные концепции и изложить их максимально просто. Огромную помощь в работе оказал Григорий Барон, сделавший ряд ценных замечаний практически по всем важнейшим темам. Я хотел бы также выразить признательность фирмам Computer Associates, Informix Software и Novell за любезно предоставленные технические материалы, которые были использованы при подготовке статей.
Вполне отдавая себе отчет в том, что ряд утверждений в статьях носит спорный характер, я буду благодарен за любые критические замечания в свой адрес и готов обсуждать их в свободной дискуссии.
Важнейшая задача компьютерных систем — хранение и обработка данных. Для ее решения были предприняты усилия, которые привели к появлению в конце 60-х — начале 70-х годов специализированного программного обеспечения — систем управления базами данных (database management systems). СУБД позволяют структурировать, систематизировать и организовать данные для их компьютерного хранения и обработки. Невозможно представить себе деятельность современного предприятия или учреждения без использования профессиональных СУБД. Несомненно, они составляют фундамент информационной деятельности во всех сферах — начиная с производства и заканчивая финансами и телекоммуникациями.
Приступая к обсуждению проблем СУБД, необходимо прежде всего договориться о терминологии. Это и является задачей Разд. Реляционная база данных — основные понятия. В нем очень кратко рассматриваются основные понятия и определения, среди которых — база данных, сущности, атрибуты, связи. Основное внимание уделено реляционной модели данных и главным ее понятиям — таблица, столбец, строка, первичный ключ, внешний ключ, отношение, индекс. Очень сжато обсуждается язык SQL (Structured Query Language).
Сердцевиной, центральным компонентом любой СУБД является сервер базы данных. Его техническое качество в решающей степени определяет главные характеристики системы, такие как производительность, надежность, безопасность и т.д. В то же время богатство и разнообразие возможностей, заложенных в механизм его функционирования, сильно сказываются на эффективности разработки прикладных программ. Модель взаимодействия "клиент-сервер", эволюция сервера БД, основные его возможности и тенденции обсуждаются в Разд. Сервер базы данных.
Сервер БД является неотъемлемым компонентом модели взаимодействия "клиент-сервер", которая стала фактическим стандартом архитектуры современных СУБД и одним из этапов их развития от систем с централизованной архитектурой и систем с файловым сервером. В то же время в рамках модели "клиент-сервер" претерпела изменения парадигма взаимодействия клиента и сервера. Эволюция сервера БД происходила от архитектуры "по одному серверу для каждого клиента" к многопотоковой, мультисерверной архитектуре.
Одна из главных тенденций развития серверов БД — усиление их активной роли в модели взаимодействия "клиент-сервер". Эта идея — не каприз разработчиков, не технический изыск и не упражнение для ума. Она была вызвана к жизни реальными практическими задачами, возникающими в самых различных областях информационной деятельности человека. Традиционное же решение этих задач в системах с пассивным сервером было громоздким и неэффективным и не удовлетворяло современным требованиям. Аргументы в пользу активного сервера БД — предмет второй части Разд. Сервер базы данных, где обсуждаются потребности реальной жизни, недостатки традиционных систем, новые подходы, позволяющие их преодолеть, и конкретные механизмы, в которых они находят свое воплощение.
В Разд. Обработка распределенных данных рассматриваются текущее состояние и перспективы распределенных баз данных. Вводится понятие распределенной БД, обсуждаются основные принципы обработки распределенных данных. Технология "клиент-сервер" невозможна без учета важнейших требований, в числе которых прозрачность расположения и прозрачность сети, автоматическое преобразование форматов данных и автоматическая трансляция кодов, организация доступа к неоднородным базам данных, автоматическая двухфазная фиксация транзакций, оптимизация распределенных запросов, поддержка словаря распределенных данных. Наряду с технологией распределенного хранения данных обсуждается активно развивающаяся в последнее время технология тиражирования данных.
Ввиду особой важности, обсуждение проблем обработки транзакций вынесено в Разд. Обработка транзакций. Там же рассматривается сравнительно новая тема — менеджеры транзакций.
В последнее время проблема безопасности в СУБД выдвинулась на первый план. Это — обширная тема, требующая особого обсуждения. В Разд. Средства защиты данных в СУБД затрагиваются лишь традиционные методы защиты данных в СУБД и современная концепция многоуровневой безопасности в базах данных.
В заключении приводятся соображения, которые могут оказаться полезными при проектировании и реализации информационной системы на основе современной профессиональной СУБД.
Обращаясь к истории развития и совершенствования систем управления базами данных, можно условно выделить три основных этапа. Начальный этап был связан с созданием первого поколения СУБД, опиравшихся на иерархическую и сетевую модели данных (на основе спецификаций CODASYL). По времени он совпал с периодом, когда на рынке вычислительной техники доминировали большие ЭВМ (mainframe), например, система IBM 360/370, которые в совокупности с СУБД первого поколения составили аппаратно-программную платформу больших информационных систем.
К сожалению, СУБД первого поколения были в подавляющем большинстве закрытыми системами: отсутствовал стандарт внешних интерфейсов, не обеспечивалась переносимость прикладных программ. Они не обладали средствами автоматизации программирования и (по современным меркам) имели массу других недостатков. Кроме того, они были очень дороги. В то же время СУБД первого поколения оказались весьма долговечными: разработанное на их основе программное обеспечение используется и по нынешний день, а большие ЭВМ по-прежнему хранят огромные массивы актуальной информации.
С созданием реляционной модели данных был начат новый этап в эволюции СУБД. Простота и гибкость модели привлекли к ней внимание разработчиков и снискали ей множество сторонников. Несмотря на некоторые недостатки (у кого их нет?), реляционная модель данных стала доминирующей. Условно эту группу систем можно назвать "вторым поколением СУБД". Его характеризовали две основные особенности — реляционная модель данных и язык запросов SQL (Structured Query Language). Представители второго поколения в настоящее время еще сохраняют определенную популярность среди производителей СУБД, в большинстве своем развившись в системы третьего поколения, к которому и относятся современные СУБД.
Для них характерны использование идей объектно-ориентированного подхода, управления распределенными базами данных, активного сервера БД, языков программирования четвертого поколения, фрагментации и параллельной обработки запросов, технологии тиражирования данных, многопотоковой архитектуры и других революционных достижений в области обработки данных. СУБД третьего поколения — это сложные многофункциональные программные системы, работающие в открытой распределенной среде. Они уже сегодня доступны для использования в деловой сфере и выступают не просто в качестве технических и научных решений, но как завершенные продукты, предоставляющие разработчикам мощные средства управления данными и богатый инструментарий для создания прикладных программ и систем.
На эволюции СУБД сильно сказался процесс перехода от больших ЭВМ к открытым распределенным системам на компьютерах RISC-архитектуры. По темпам развития RISC-компьютеры за последнее десятилетие существенно превзошли большие ЭВМ. Причинами того, что более половины обладателей больших ЭВМ заявили о намерении в ближайшее время отказаться от них в пользу открытых систем, послужили три фактора. Во-первых, цена RISC-компьютеров значительно ниже цены больших ЭВМ, и эта разница постоянно растет. Во-вторых, по функциональным возможностям RISC-компьютеры превзошли большие ЭВМ. В третьих, фактически сравнялась их производительность. Кроме того, архитектура систем на основе RISC-компьютеров оказалась более простой, гибкой и мобильной, а сфера их использования — значительно шире области применения больших ЭВМ.
Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название DownSizing. Этот процесс оказал огромное влияние на развитие архитектур СУБД и поставил перед их разработчиками ряд сложных проблем. Главная проблема состояла в технологической сложности перехода от централизованного управления данными на одном компьютере и СУБД, использовавшей собственные модели, форматы представления данных и языки доступа к данным и т.д., к распределенной обработке данных в неоднородной вычислительной среде, состоящей из соединенных в глобальную сеть компьютеров различных моделей и производителей.
В то же время происходил встречный процесс — UpSizing. Бурное развитие персональных компьютеров, появление локальных сетей также оказали серьезное влияние на эволюцию СУБД. Высокие темпы роста производительности и функциональных возможностей PC привлекли внимание разработчиков профессиональных СУБД, что привело к их активному распространению на платформе настольных систем.
Сегодня возобладала тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам. Она получила название RightSizing (помещение ровно в тот размер, который необходим).
Реляционная база данных — основные понятия
Часто, говоря о базе данных, имеют в виду просто некоторое автоматизированное хранилище данных. Такое представление не вполне корректно. Почему это так, будет показано ниже.
Действительно, в узком смысле слова, база данных — это некоторый набор данных, необходимых для работы (актуальные данные). Однако данные — это абстракция; никто никогда не видел "просто данные"; они не возникают и не существуют сами по себе. Данные суть отражение объектов реального мира. Пусть, например, требуется хранить сведения о деталях, поступивших на склад. Как объект реального мира — деталь — будет отображена в базе данных? Для того, чтобы ответить на этот вопрос, необходимо знать, какие признаки или стороны детали будут актуальны, необходимы для работы. Среди них могут быть название детали, ее вес, размеры, цвет, дата изготовления, материал, из которого она сделана и т.д. В традиционной терминологии объекты реального мира, сведения о которых хранятся в базе данных, называются сущностями — entities (пусть это слово не пугает читателя — это общепринятый термин), а их актуальные признаки — атрибутами (attributes).
Каждый признак конкретного объекта есть значение атрибута. Так, деталь "двигатель" имеет значение атрибута "вес", равное "50", что отражает тот факт, что данный двигатель весит 50 килограммов.
Было бы ошибкой считать, что в базе данных отражаются только физические объекты. Она способна вобрать в себя сведения об абстракциях, процессах, явлениях — то есть обо всем, с чем сталкивается человек в своей деятельности. Так, например, в базе данных можно хранить информацию о заказах на поставку деталей на склад (хотя он — не физический объект, а процесс). Атрибутами сущности "заказ" будут название поставляемой детали, количество деталей, название поставщика, срок поставки и т.д.
Объекты реального мира связаны друг с другом множеством сложных зависимостей, которые необходимо учитывать в информационной деятельности. Например, детали на склад поставляются их производителями. Следовательно, в число атрибутов детали необходимо включить атрибут "название фирмы-производителя". Однако этого недостаточно, так как могут понадобиться дополнительные сведения о производителе конкретной детали — его адрес, номер телефона и т.д. Значит, база данных должна содержать не только информацию о деталях и заказах на поставку, но и сведения об их производителях. Более того, база данных должна отражать связи между деталями и производителями (каждая деталь выпускается конкретным производителем) и между заказами и деталями (каждый заказ оформляется на конкретную деталь). Отметим, что в базе данных нужно хранить только актуальные, значимые связи.
Таким образом, в широком смысле слова база данных — это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области. В дальнейшем мы будем исходить из этого определения, уточняя его по ходу изложения.
Реляционная модель данных
Итак, мы получили представление о том, что хранится в базе данных. Теперь необходимо понять, как сущности, атрибуты и связи отображаются на структуры данных. Это определяется моделью данных.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят об иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня — вне конкуренции. Они стали фактическим промышленным стандартом, и поэтому отечественному пользователю придется столкнуться в своей практике именно с реляционной СУБД. Кратко рассмотрим реляционную модель данных, не вникая в ее детали.
Она была разработана Коддом еще в 1969-70 годах на основе математической теории отношений и опирается на систему понятий, важнейшими из которых являются таблица, отношение, строка, столбец, первичный ключ, внешний ключ.
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка — конкретный объект. Так, таблица Деталь содержит сведения о всех деталях, хранящихся на складе, а ее строки являются наборами значений атрибутов конкретных деталей. Каждый столбец таблицы — это совокупность значений конкретного атрибута объекта. Так, столбец Материал представляет собой множество значений "Сталь", "Олово", "Цинк", "Никель" и т.д. В столбце Количество содержатся целые неотрицательные числа. Значения в столбце Вес — вещественные числа, равные весу детали в килограммах.
Эти значения не появляются из воздуха. Они выбираются из множества всех возможных значений атрибута объекта, которое называется доменом (domain). Так, значения в столбце материал выбираются из множества имен всех возможных материалов — пластмасс, древесины, металлов и т.д. Следовательно, в столбце Материал принципиально невозможно появление значения, которого нет в соответствующем домене, например, "вода" или "песок".
Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы (Рис. 1). Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец; столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от столбцов, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено.
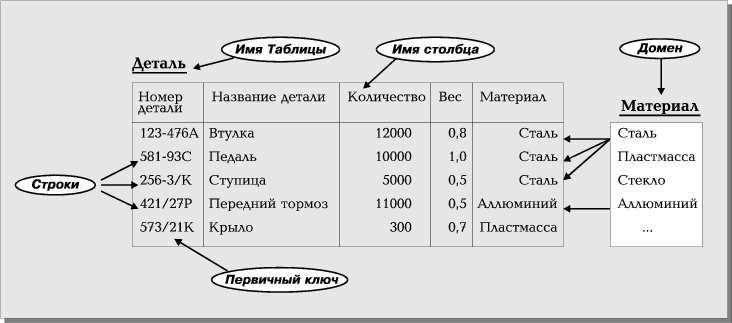
Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции — среди них не существует "первой", "второй", "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). В таблице Деталь первичный ключ — это столбец Номер детали. В нашем примере каждая деталь на складе имеет единственный номер, по которому из таблицы Деталь извлекается необходимая информация. Следовательно, в этой таблице первичный ключ — это столбец Номер детали. В этом столбце значения не могут дублироваться — в таблице Деталь не должно быть строк, имеющих одно и то же значение в столбце Номер детали. Если таблица удовлетворяет этому требованию, она называется отношением (relation).
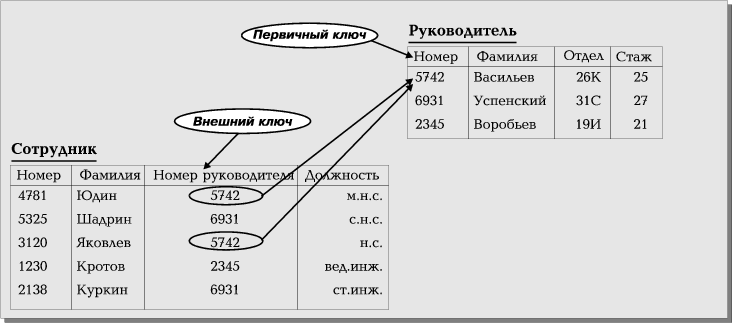
Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами (foreign key). Рассмотрим пример, в котором база данных хранит информацию о рядовых служащих (таблица Служащий) и руководителях (таблица Руководитель) в некоторой организации (Рис. 2). Первичный ключ таблицы Руководитель — столбец Номер (например, табельный номер). Столбец Фамилия не может выполнять роль первичного ключа, так как в одной организации могут работать два руководителя с одинаковыми фамилиями. Любой служащий подчинен единственному руководителю, что должно быть отражено в базе данных. Таблица Служащий содержит столбец Номер руководителя, и значения в этом столбце выбираются из столбца Номер таблицы Руководитель (см. Рис. 2). Столбец Номер Руководителя является внешним ключом в таблице Служащий.
Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют "данные о данных", например, описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary).
Помимо таблиц, в базе данных могут храниться и другие объекты, такие как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с базой данных.
Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity).
Для того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например, целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Ограничения целостности реализуются с помощью специальных средств, о которых речь пойдет в Разд. Сервер базы данных.
Язык SQL
Сами по себе данные в компьютерной форме не представляют интерес для пользователя, если отсутствуют средства доступа к ним. Доступ к данным осуществляется в виде запросов к базе данных, которые формулируются на стандартном языке запросов. Сегодня для большинства СУБД таким языком является SQL.
Появление и развития этого языка как средства описания доступа к базе данных связано с созданием теории реляционных баз данных. Прообраз языка SQL возник в 1970 году в рамках научно-исследовательского проекта System/R, работа над которым велась в лаборатории Санта-Тереза фирмы IBM. Ныне SQL — это стандарт интерфейса с реляционными СУБД. Популярность его настолько велика, что разработчики нереляционных СУБД (например, Adabas), снабжают свои системы SQL-интерейсом.
Язык SQL имеет официальный стандарт — ANSI/ISO. Большинство разработчиков СУБД придерживаются этого стандарта, однако часто расширяют его для реализации новых возможностей обработки данных. Новые механизмы управления данными, которые будут описаны в Разд. Сервер базы данных, могут быть использованы только через специальные операторы SQL, в общем случае не включенные в стандарт языка.
SQL не является языком программирования в традиционном представлении. На нем пишутся не программы, а запросы к базе данных. Поэтому SQL — декларативный язык. Это означает, что с его помощью можно сформулировать, что необходимо получить, но нельзя указать, как это следует сделать. В частности, в отличие от процедурных языков программирования (Си, Паскаль, Ада), в языке SQL отсутствуют такие операторы, как if-then-else, for, while и т.д.
Мы не будем подробно рассматривать синтаксис языка. Коснемся его лишь в той мере, которая необходима для понимания простых примеров. С их помощью будут проиллюстрированы наиболее интересные механизмы обработки данных.
Запрос на языке SQL состоит из одного или нескольких операторов, следующих один за другим и разделенных точкой с запятой. Ниже в Таб. 1 перечислены наиболее важные операторы, которые входят в стандарт ANSI/ISO SQL.

В запросах на языке SQL используются имена, которые однозначно идентифицируют объекты базы данных. В частности это — имя таблицы (Деталь), имя столбца (Название), а также имена других объектов в базе, которые относятся к дополнительным типам (например, имена процедур и правил), о которых речь пойдет в Разд. Сервер базы данных. Наряду с простыми, используются также сложные имена — например, квалификационное имя столбца (qualified column name) определяет имя столбца и имя таблицы, которой он принадлежит (Деталь.Вес). Для простоты в примерах имена будут записаны на русском языке, хотя на практике этого делать не рекомендуется.
Каждый столбец в любой таблице хранит данные определенных типов. Различают базовые типы данных — строки символов фиксированной длины, целые и вещественные числа, и дополнительные типы данных — строки символов переменной длины, денежные единицы, дату и время, логические данные (два значения — "ИСТИНА" и "ЛОЖЬ"). В языке SQL можно использовать числовые, строковые, символьные константы и константы типа "дата" и "время".
Рассмотрим несколько примеров.
Запрос "определить количество деталей на складе для всех типов деталей" реализуется следующим образом:
SELECT Название, Количество
FROM Деталь;
Результатом запроса будет таблица с двумя столбцами — Название и Количество, которые взяты из исходной таблицы Деталь. По сути, этот запрос позволяет получить вертикальную проекцию исходной таблицы (более строго, вертикальное подмножество множества строк таблицы). Из всех строк таблицы Деталь образуются строки, которые включают значения, взятые из двух столбцов — Название и Количество.
Запрос "какие детали, изготовленные из стали, хранятся на складе?", сформулированный на языке SQL, выглядит так:
SELECT *
FROM Деталь
WHERE Материал = 'Сталь';
Результатом этого запроса также будет таблица, содержащая только те строки исходной таблицы, которые имеют в столбце Материал значение 'Сталь'. Этот запрос позволяет получить горизонтальную проекцию таблицы Деталь (звездочка в операторе SELECT означает выбор всех столбцов из таблицы).
Запрос "определить название и количество деталей на складе, которые изготовлены из пластмассы и весят меньше пяти килограммов" будет записан следующим образом:
SELECT Название, Количество
FROM Деталь
WHERE Материал = 'Пластмасса'
AND Вес < 5;
Результат запроса — таблица из двух столбцов — Название, Количество, которая содержит название и число деталей, изготовленных из пластмассы и весящих менее 5 кг. По сути, операция выборки является операцией образования сначала горизонтальной проекции (найти все строки таблицы Деталь, у которых Материал = 'Пластмасса' и Вес < 5), а затем вертикальной проекции (извлечь Название и Количество из выбранных ранее строк).
Одним из средств, обеспечивающих быстрый доступ к таблицам, являются индексы. Индекс — это структура базы данных, представляющая собой указатель на конкретную строку таблицы. Индекс базы данных используется так же, как индексный указатель в книге. Он содержит значения, взятые из одного или нескольких столбцов конкретной строки таблицы, и ссылку на эту строку. Значения в индексе упорядочены, что позволяет СУБД выполнять быстрый поиск в таблице.
Допустим, что сформулирован запрос к базе данных Склад:
SELECT Название Количество, Материал
FROM Деталь
WHERE Номер = 'Т145-А8';
Если индексов для данной таблицы не существует, то для выполнения этого запроса СУБД должна просмотреть всю таблицу Деталь, последовательно выбирая из нее строки и проверяя для каждой из них условие выбора. Для больших таблиц такой запрос будет выполняться очень долго.
Если же был предварительно создан индекс по столбцу Номер таблицы Деталь, то время поиска в таблице будет сокращено до минимума. Индекс будет содержать значения из столбца Номер и ссылку на строку с этим значением в таблице Деталь. При выполнении запроса СУБД вначале найдет в индексе значение 'Т145-А8' (и сделает это быстро, так как индекс упорядочен, а его строки невелики), а затем по ссылке в индексе определит физическое расположение искомой строки.
Индекс создается оператором SQL CREATE INDEX (СОЗДАТЬ ИНДЕКС). В данном примере оператор
CREATE UNIQUE INDEX Индекс детали
ON Деталь (Номер);
позволит создать индекс с именем "Индекс детали" по столбцу Номер таблицы Деталь.
Для пользователя СУБД интерес представляют не отдельные операторы языка SQL, а некоторая их последовательность, оформленная как единое целое и имеющая смысл с его точки зрения. Каждая такая последовательность операторов языка SQL реализует определенное действие над базой данных. Оно осуществляется за несколько шагов, на каждом из которых над таблицами базы данных выполняются некоторые операции. Так, в банковской системе перевод некоторой суммы с краткосрочного счета на долгосрочный выполняется в несколько операций. Среди них — снятие суммы с краткосрочного счета, зачисление на долгосрочный счет.
Если в процессе выполнения этого действия произойдет сбой, например, когда первая операция будет выполнена, а вторая — нет, то деньги будут потеряны. Следовательно, любое действие над базой данных должно быть выполнено целиком, или не выполняться вовсе. Такое действие получило название транзакции.
Обработка транзакций опирается на журнал, который используется для отката транзакций и восстановления состояния базы данных. Более подробно о транзакциях будет сказано в Разд. Обработка транзакций.
Завершая обсуждение языка SQL, еще раз подчеркнем, что это — язык запросов. На нем нельзя написать сколько-нибудь сложную прикладную программу, которая работает с базой данных. Для этой цели в современных СУБД используется язык четвертого поколения (Forth Generation Language — 4GL), обладающий как основными возможностями процедурных языков третьего поколения (3GL), таких как Си, Паскаль, Ада, так и возможностью встроить в текст программы операторы SQL, а также средствами управления интерфейсом пользователя (меню, формами, вводом пользователя и т.д.). Сегодня язык 4GL — это один из фактических стандартов средств разработки приложений, работающих с базами данных.
Сервер базы данных
Современная СУБД должна удовлетворять целому ряду требований, важнейшее среди которых — высокопроизводительный интеллектуальный сервер базы данных. Ниже мы рассмотрим основные тенденции его развития и обсудим конкретные механизмы, в которых они находят свое воплощение. Будут затронуты модели технологии "клиент-сервер", определено место сервера БД в этих моделях, и кратко описаны важнейшие механизмы сервера БД — процедуры, правила (триггеры), события. Последние будут проиллюстрированы примерами, в которых использован диалект SQL, принятый в СУБД Ingres.
Технология и модели "клиент-сервер"
"Клиент-сервер" — это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других, назначение, играет определенную роль. Некоторые компьютеры в сети владеют и распоряжаются информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере или файл-сервере и т.д.
В сети один и тот же компьютер может выполнять как роль клиента, так и роль сервера. Например, в информационной системе, включающей персональные компьютеры, большую ЭВМ и мини-компьютер под управлением UNIX, последний может выступать как в качестве сервера базы данных, обслуживая запросы от клиентов — персональных компьютеров, так и в качестве клиента, направляя запросы большой ЭВМ.
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа рассматривается в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных — SQL-клиентом.
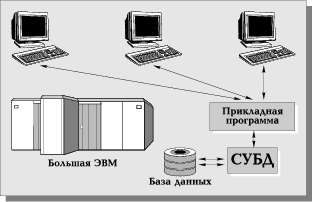
Первоначально СУБД имели централизованную архитектуру (Рис. 3). В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей. Все процессы, связанные с обработкой данных: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т.д., выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой больших ЭВМ и мини-компьютеров и адекватно отражают все их преимущества и недостатки. Однако нас будет больше интересовать современное состояние многопользовательских СУБД, для которых архитектура "клиент-сервер" стала фактическим стандартом.
Для более четкого представления о ее особенностях необходимо рассмотреть несколько моделей технологии "клиент-сервер", что и будет сделано ниже.
Если предполагается, что проектируемая информационная система (ИС) будет построена по технологии "клиент-сервер", то это означает, что прикладные программы, реализованные в ее рамках, будут иметь распределенный характер. Иными словами, часть функций прикладной программы (или, проще, приложения) будет реализована в программе-клиенте, другая — в программе-сервере, причем для их взаимодействия будет определен некоторый протокол.
Основной принцип технологии "клиент-сервер" заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу. Первая группа — это функции ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т.д.).
К третьей группе относятся фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т.д.). Наконец, функции четвертой группы — служебные, играющие роль связок между функциями первых трех групп.
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
- компонент представления, реализующий функции первой группы;
- прикладной компонент, поддерживающий функции второй группы;
- компонент доступа к информационным ресурсам, поддерживающий функции третьей группы,
а также вводятся и уточняются соглашения о способах их взаимодействия (протокол взаимодействия).
Различия в реализациях технологии "клиент-сервер" определяются четырьмя факторами. Во-первых, тем, в какие виды программного обеспечения интегрирован каждый из этих компонентов. Во-вторых, тем, какие механизмы программного обеспечения используются для реализации функций всех четырех групп. В-третьих — как логические компоненты распределяются между компьютерами в сети. В-четвертых, какие механизмы используются для связи компонентов между собой.
Выделяются четыре подхода, реализованные в следующих моделях:
- модель файлового сервера (File Server — FS);
- модель доступа к удаленным данным (Remote Data Access — RDA);
- модель севера базы данных (DataBase Server — DBS);
- модель сервера приложений (Application Server — AS).
FS-модель является базовой для локальных сетей персональных компьютеров. Некоторое время назад она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPRO, Clipper, Clarion, Paradox и т.д. Суть модели проста и всем известна. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (то есть к файлам). На других компьютерах в сети функционирует приложение, в кодах которого совмещены компонент представления и прикладной компонент (Рис. 4). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
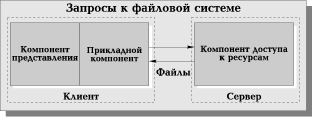
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипулирования данными ("данные — это файлы"), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т.д. Собственно, перечисленное не есть недостатки, но — следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают в том случае, когда FS-модель используют не по назначению — например, пытаются интерпретировать как модель сервера базы данных. Место FS-модели в иерархии моделей "клиент-сервер" — это место модели файлового сервера и ничего более.
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных) или вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — API).
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия и возвращает клиенту результат, оформленный как блок данных (Рис. 5). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. Далее будет показано, что такое распределение обязанностей между клиентами и сервером базы данных — не догма: сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
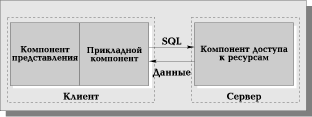
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Прежде всего, перенос компонента представления и прикладного компонента на компьютеры-клиенты существенно разгружает сервер БД, минимизируя общее число процессов операционной системы. Сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций. Это становится возможным благодаря отказу от терминалов и оснащению рабочих мест компьютерами, которые обладают собственными локальными вычислительными ресурсами, полностью используемыми программами переднего плана. С другой стороны, резко уменьшается загрузка сети, так как по ней передаются от клиента к серверу не запросы на ввод-вывод (как в системах с файловым сервером), а запросы на языке SQL, а их объем существенно меньше.
Основное достоинство RDA-модели заключается в унификации интерфейса "клиент-сервер" в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обеим сторонам. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором речь шла выше. Поэтому было бы целесообразно использовать его не только в качестве средства доступа к данным, но и как стандарта общения клиента и сервера.
Такое общение можно сравнить с беседой нескольких человек, когда один отвечает на вопросы остальных (вопросы задаются одновременно). Причем делает это он так быстро, что время ожидания ответа приближается к нулевому. Высокая скорость общения достигается прежде всего за счет четкой формулировки вопроса, так что спрашивающему и отвечающему не нужно дополнительных консультаций по сути вопроса. Беседующие обмениваются несколькими короткими фразами, которые трактуются ими однозначно — ничего не нужно уточнять.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные функции).
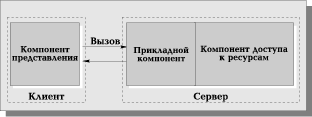
Наряду с RDA-моделью все большую популярность приобретает перспективная DBS-модель (Рис. 6). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур — средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, то есть ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как Си или Паскаль. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используется смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции выполняются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая работает на компьютере-клиенте (RDA-модель). Так или иначе, современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей, либо их разумное сочетание.
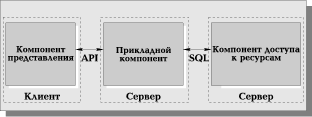
В AS-модели (Рис. 7) процесс, выполняющийся на компьютере-клиенте, отвечает, обычно за интерфейс с пользователем (то есть реализует функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — AC). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции и называется сервером приложения (Application Server — AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов — базы данных, очереди, почтовые службы и др.
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором - интегрируется в компонент доступа к информационным ресурсам. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors — TPM), или, проще, мониторов транзакций, которые выделяются как особый вид программного обеспечения. Мониторы транзакций - предмет Разд. Обработка транзакций.
В заключение отметим, что часто, говоря о сервере базы данных, подразумевают как компьютер, так и программное обеспечение — ядро СУБД. При описании архитектуры "клиент-сервер" под сервером базы данных мы имели в виду компьютер. Ниже сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
Эволюция серверов баз данных
В период создания первых СУБД технология "клиент-сервер" только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим.
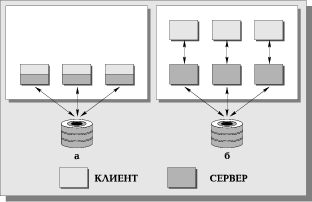
Чтобы понять суть проблемы, рассмотрим эволюцию серверов баз данных. Первое время доминировала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе (Рис. 8). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме "один-к-одному" (Рис. 8), то есть сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу — революционный шаг, позволяющий, в частности, поместить сервер на одну Машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (Рис. 9). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
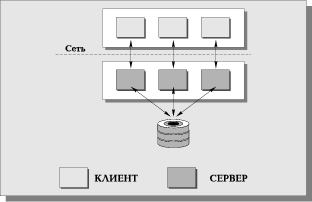
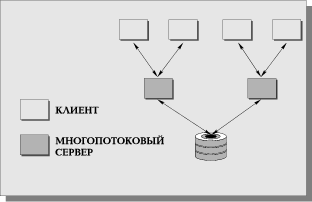
Проблемы, возникающие в модели "один-к-одному", решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (Рис. 10). Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой (multi-threaded).
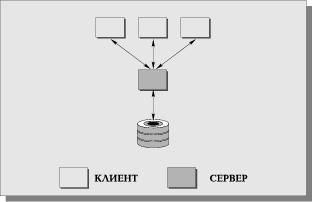
Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей. С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что сильно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой "один-к-одному" будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобиться только один сервер.
Однако такое решение привносит новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
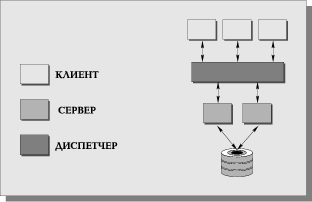
В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальный сервер (virtual server) (Рис. 11), который теряет право монопольною распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием "клиент-сервер". Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, во-вторых, серверы становятся равноправными — невозможно устанавливать приоритеты для обслуживания запросов.
Подобная организация взаимодействия "клиент-сервер" является аналогом банка, где имеется несколько окон кассиров, и банковский служащий (диспетчер), направляет каждого вновь пришедшего посетителя (клиент) к свободному кассиру (актуальный сервер). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако, как только появляются посетители с высшим приоритетом (которые должны обслуживаться в специальном окне), возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эта возможность не поддерживается архитектурой систем с диспетчеризацией.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если два эти условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture), представленной на Рис. 12.