 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Активный сервер
Идея активного интеллектуального сервера БД возникла не сама по себе — она стала ответом на задачи реальной жизни. В Разд. Реляционная база данных — основные понятия было сформулировано общее представление о базах данных. Однако вдумчивый читатель может его расширить. Действительно, объекты реального мира, помимо непосредственных, прямых связей, имеют друг с другом иные, более сложные причинно-следственные связи; они динамичны, находятся в постоянном изменении. Эти связи и процессы должны каким-то образом отражаться в базе данных, если мы имеем в виду не статичное хранилище, а информационную модель части реального мира. Иными словами, в базе, помимо собственно данных и непосредственных связей между ними, должны храниться знания о данных, а она сама должна адекватно отражать процессы, происходящие в реальном мире. Следовательно, необходимо иметь средства хранения и управления такой информацией.
Актуальные задачи
Указанные выше требования выливаются в решение следующих задач.
Во-первых, необходимо, чтобы база данных в любой момент времени правильно отражала состояние предметной области — данные должны быть взаимно непротиворечивыми. Пусть, например, база данных Кадры хранит сведения о рядовых сотрудниках, отделах, в которых они работают, и их руководителях. Нужно учесть следующие правила: каждый сотрудник должен быть подчинен реальному руководителю; если руководитель уволился, то все его сотрудники переходят в подчинение другому, а отдел реорганизуется; во главе каждого отдела должен стоять реальный руководитель; если отдел сокращен, то его руководитель переводится в резерв на выдвижение и т.д.
Во-вторых, база данных должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Завод может нормально работать только в том случае, если на складе имеется достаточный запас деталей определенной номенклатуры. Следовательно, как только количество деталей некоторого типа станет меньше минимально допустимого, завод должен докупить их в нужном количестве.
В-третьих, необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений, и адекватная реакция на них. Например, в автоматизированной системе управления производством датчики контролируют температуру инструмента; она периодически передается в базу данных и там сохраняется; как только температура инструмента превышает максимально допустимое значение, он отключается.
В-четвертых, необходимо, чтобы возникновение некоторой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы. Многие программы требуют оперативного оповещения о всех происходящих в базе данных изменениях. Так, в системах автоматизированного управления производством необходимо моментально уведомлять программы о любых изменениях параметров технологических процессов, когда последние хранятся в базе данных. Почтовая служба требует оперативного уведомления получателя, как только получено новое сообщение. Брокер на бирже должен немедленно получать сообщение об изменении цены акций, поскольку промедление в несколько секунд грозит большими потерями.
Оповещение о возникновении определенного состояния базы данных и изменениях в ней может потребоваться в любом учреждении для контроля прохождения документов. Если документ, который должен быть просмотрен и последовательно завизирован несколькими руководителями, хранится в базе данных, то каждый из них в свою очередь будет оперативно уведомлен о поступлении документа ему на подпись.
Важная проблема СУБД — контроль типов данных. В Разд. Реляционная база данных — основные понятия уже говорилось о том, что в базе данных каждый столбец в любой таблице содержит данные некоторых типов. Тип данных определяется при создании таблицы. Каждому столбцу присваивается один из стандартных типов данных, разрешенных в СУБД. Тогда получается, что в базе данных можно хранить только данные стандартных типов — числа, целые и вещественные, строки символов, данные типа "дата", "время" и "денежная единица" — репертуар реальной СУБД ограничен именно этими типами данных. Как же быть с нестандартными данными? Ведь в реальной жизни требуется хранить и обрабатывать данные в значительно более широком диапазоне — плоскостные и пространственные координаты, единицы различных метрик, пятидневные недели (рабочая неделя, в которой сразу после пятницы следует понедельник), дроби, не говоря уже о графических изображениях.
Традиционные подходы
До недавнего времени функции управления знаниями оставались за границами возможностей реляционных СУБД или были очень ограничены.
Традиционно знания о предметной области включались непосредственно в прикладные программы, для чего использовались возможности процедурных языков программирования. В подавляющем большинстве случаев этот подход преобладает и сейчас.
Рассмотрим, например, базу данных Склад, хранящую информацию о наличии деталей на заводском складе. Прикладная программа Складской Учет обеспечивает учет уже существующих и вновь поступающих деталей. В ее функции входит просмотр содержимого базы данных, добавление информации о новых деталях, замена снятых с производства деталей на новые и т.д. В программе реализованы некоторые правила, например "В любой момент времени количество деталей типа втулка не должно быть меньше 1000" (ситуация со втулками на производстве всегда напряженная). Нетрудно видеть, что это правило должно применяться только в том случае, когда количество втулок уменьшается. Нужно проверить: не уменьшилось ли оно настолько, что стало меньше 1000? Если это произошло, то нужно срочно направить на завод-изготовитель письмо с просьбой отгрузить нужное количество втулок. Разумеется, это следует сделать, если только письмо уже не было направлено ранее.
Для того, чтобы это правило применялось, программа должна периодически, через определенные интервалы времени, опрашивать значение в столбце Количество таблицы Деталь для всех строк, которые удовлетворяют условию Деталь.Название='Втулка'. Если это значение становится меньше 1000, программа должна послать письмо на завод-изготовитель.
Фрагмент программы будет выглядеть так (для иллюстрации используется процедурное расширение Ingres SQL):
...
SELECT Количество, Номер_поставщика
FROM Деталь
WHERE Название = 'Втулка';
IF (Количество < 1000)
THEN
BEGIN
SELECT Адрес_поставщика
FROM Поставщик
WHERE Номер = Номер_поставщика;
Послать письмо (Адрес_поставщика);
END
...
В чем заключаются недостатки такого подхода?
Во-первых, реализация правил перегружает прикладную программу и усложняет ее написание и понимание. Во-вторых, и это более существенный недостаток, когда изменяется само правило, изменения должны быть отражены в тексте программы. В тех же случаях, когда правила изменяются кардинальным образом, разработчику приходится пересматривать логику выполнения программы и практически переписывать ее заново.
Было бы удобно оставить за прикладными программами только базовые алгоритмы управления данными, а часто меняющиеся правила, которые действуют во внешнем мире, вынести за рамки программ и оформить каким-то иным способом. В противном случае разработчиков ждут неприятные сюрпризы.
Рассмотрим для примера прикладную банковскую систему. При ее создании разработчики в алгоритмах управления данными учли те правила финансовой деятельности, которые диктовались действующим законодательством. Предположим теперь, что законы претерпели некоторые изменения (что в наше время происходит слишком часто!). Естественно, эти изменения должны быть немедленно отражены и в алгоритмах управления данными, что повлечет за собой необходимость модификации всех прикладных программ, составляющих информационную систему.
Само по себе это представляет огромную работу — нужно исправить и отладить программы, откомпилировать и собрать их, внести изменения в документацию и переобучить персонал.
С другой стороны, правила, о которых идет речь, не должны противоречить друг другу. Когда их реализует группа разработчиков, нет никаких гарантий взаимной непротиворечивости правил. Фактически правила должен формулировать и контролировать один человек — администратор базы данных. В традиционном же подходе практически невозможно обеспечить централизованный контроль за взаимным соответствием правил, если они разбросаны по многим программам, и, что более важно для коммерческих организаций, практически невозможно проконтролировать преднамеренное искажение правил программистами.
Таким образом, включение правил в прикладные программы, когда серверу отводится пассивная роль поставщика и хранителя данных, а вся интеллектуальная часть реализуется в программе, представляет собой устаревшую технологию. Она чревата большими накладными расходами при изменении правил и не обеспечивает централизованного контроля за их непротиворечивостью. Нетрудно видеть, что эта технология имеет в своей основе столь популярную ныне RDA-модель (о ней речь шла выше).
Традиционное решение задач контроля за состоянием базы данных и уведомления прикладных программ о всех происходящих в ней событиях опирается на механизмы опроса (polling) прикладными программами базы данных, которому присущи следующие недостатки.
Прикладная программа не может непрерывно опрашивать базу данных, так как это приведет к перегрузке сервера бесполезными запросами. Опрос производится через интервалы времени, которые определяет программист. Следовательно, если в базе данных происходят какие-либо изменения, то они обнаруживаются не сразу, а через некоторый промежуток времени. Именно поэтому традиционное решение не обеспечивает оперативного оповещения, между тем как в прикладных программах, работающих в реальном времени, это требование является ключевым. Постоянный опрос базы данных сильно сказывается на производительности системы — программы, опрашивающие базу данных, перегружают своими запросами сервер и сеть. Громоздкие конструкции в тексте программ, реализующие опрос, серьезно затрудняют ее написание и понимание.
Другим важным требованием реальной жизни является синхронизация работы нескольких программ, обращающихся к базе данных. Рассмотрим пример. Финансовая система завода должна отслеживать поступление платежей за продукцию на некоторый счет. Как только деньги поступили (все знают, насколько это важное событие — "пришли деньги"!), все прикладные программы, включенные в финансовую систему, должны быть оповещены об этом событии. После этого каждая из них может предпринять некоторые действия. Так, программа Отгрузка Продукции должна найти в базе данных соответствующий заказ, определить номенклатуру заказанной продукции, ее количество, сроки поставки, сформировать и послать на склад готовой продукции заказ на отгрузку, распечатать сопроводительные документы — то есть подготовить продукцию к отправке. Программа Бухгалтерия, в частности, должна по дате поступления денег определить, просрочен ли платеж, и, если это так, начислить штраф. Все эти действия активизируются событием в базе данных — поступлением денег на счет (в терминах реляционной СУБД это означает добавление новой строки в таблицу Платежи). Работа всех программ синхронизируется этим событием.
Традиционное решение проблемы синхронизации программ обеспечивается стандартными средствами многозадачной операционной системы. Однако такая синхронизация может быть связана с изменениями, происходящими в базе данных, только посредством постоянного опроса таблицы Платежи. Недостатки такого подхода очевидны — в нем взаимосвязь программ обеспечивается на уровне операционной системы, тогда как эту функцию безусловно должна выполнять СУБД. Кроме того, приходится привлекать программы опроса, недостатки которого мы уже обсуждали.
Общепринятый способ преодоления ограничения на типы данных в СУБД заключается в приведении данных новых типов к стандартным. Как правило, данные новых типов рассматриваются как целые или вещественные числа, или как строки символов.
Рассмотрим пример. В ряде стран, в том числе и в США, для измерения длин наряду с метрической системой используются также футы и дюймы. Правила выполнения арифметических операций в этой системе отличны от десятичной. Так, три фута одиннадцать дюймов плюс один дюйм равно четырем футам ( 3'11'' + 1'' = 4'). Стандартный набор типов данных не позволяет определить данные в этой системе и оперировать с ними. Они должны быть преобразованы в вещественные числа с плавающей точкой, то есть представлены соответственно как 3.91666 (три фута одиннадцать дюймов) и 0.08333 (один дюйм). Выполнив операцию сложения (3.91666 + 0.08333=3.99999) мы убедимся, что такое представление приводит к потере точности (ведь результат должен быть равен четырем!).
Следовательно, прямое приведение новых типов данных к стандартным чревато ошибками — необходимо их преобразование в данные стандартных типов. Функции преобразования данных должны взять на себя прикладные программы (больше некому). В результате получается весьма громоздкая схема. Программа извлекает из базы данные новых типов, представленные как стандартные, преобразует и обрабатывает их, затем вновь преобразует и передает серверу для хранения. Сервер в обработке данных новых типов при такой схеме участия не принимает — ведь он рассматривает их как стандартные и будет обрабатывать как стандартные (и тогда возникнут ошибки!).
Сегодня, например, для отечественных банков стала актуальной проблема больших чисел. Масштаб расчетов настолько возрос, что в некоторых итоговых операциях фигурируют суммы, которые превосходят разрядную сетку для целых чисел. Поэтому в программах приходится выполнять преобразование целых чисел в строки и наоборот, что отнюдь не упрощает их логику. Хранение и обработка больших целых как вещественных приводит к потере точности, что в финансовой системе недопустимо.
Как мы увидим ниже, решение проблемы заключается в определении нового типа данных "большие целые". Как только это сделано, сервер базы данных начинает "понимать" новый тип данных и выполнять над ним все операции, характерные для целых чисел.
Другое важнейшее требование к современным СУБД состоит в возможности хранения неструктурированных объектов большого объема (Binary Large OBjects — BLOB). Отвечая на это требование, разработчики СУБД предусматривают такую возможность. Однако при этом сервер только хранит такие объекты, и не обладает возможностями их обработки. Например, работая с графическими объектами, сервер не делает различий между изображением автомобиля BMW и структурой ДНК. Сервер вынужден передавать их для интерпретации прикладной программе, которая сможет разобраться, что есть что.
Не следует забывать и о проблеме целостности. Если одна программа интерпретирует данные некоторого типа, преобразуя их в собственный формат, то ничто не мешает делать то же самое другой программе — с той только разницей, что формат представления тех же данных будет уже другим. Это делает принципиально невозможным контроль целостности данных хотя бы потому, что различные программы интерпретируют их по-разному.
Отметим, что отсутствие в СУБД нестандартных типов данных сильно сказывается на их производительности, так как нормальное взаимодействие клиента и сервера возможно только тогда, когда и тот и другой адекватно воспринимают типы данных, с которыми ведется работа. Фактически, в такой схеме появление нестандартных типов данных приводит к деградации системы к архитектуре с файловым сервером. Не понимая нового типа данных, сервер способен лишь послушно сохранять его, не умея сравнивать, сортировать, выполнять какие бы то ни было операции над данными.
С другой стороны, это ограничение приводит к тому, что основная тяжесть обработки данных нестандартных типов ложится на прикладные программы. При этом вопрос о целостности данных остается открытым, поскольку не поддерживается централизованный контроль типов данных, несомненно, являющийся функцией сервера базы данных.
Итак, в традиционной технологии, решение задач, о которых речь шла выше, ложится целиком на прикладные программы. Недостатки традиционной технологии — следствие того, что в модели взаимодействия "клиент-сервер" последнему отводится в основном пассивная роль. Во-первых, сервер базы данных лишен функций хранения и обработки знаний о предметной области. Во-вторых, за границами возможностей сервера остается контроль за состоянием базы данных и программирование реакции на ее изменения. В-третьих, пассивный сервер не имеет средств отслеживания событий в базе данных, а также средств воздействия на работу прикладных программ и возможностей их синхронизации.
Современные решения
Идеи, реализованные в СУБД третьего поколения (пока, к сожалению, не во всех), заключаются в том, что знания выносятся за рамки прикладных программ и оформляются как объекты базы данных. Функции применения знаний начинает выполнять непосредственно сервер баз данных.
Такая архитектура является воплощение концепции активного сервера. Она опирается на четыре "столпа":
- процедуры базы данных;
- правила (триггеры);
- события в базе данных;
- типы данных, определяемые пользователем.
Процедуры базы данных
В различных СУБД они носят название хранимых (stored), присоединенных, разделяемых и т.д. Ниже будем пользоваться терминологией, принятой в СУБД Ingres.
Использование процедур базы данных преследует четыре цели.
Во-первых, обеспечивается новый независимый уровень централизованного контроля доступа к данным, осуществляемый администратором базы данных.
Во-вторых, одна процедура может использоваться несколькими прикладными программами — это позволяет существенно сократить время написания программ за счет оформления их общих частей в виде процедур базы данных. Процедура компилируется и помещается в базу данных, становясь доступной для многократных вызовов. Так как план ее выполнения определяется единожды при компиляции, то при последующих вызовах процедуры фаза оптимизации пропускается, что существенно экономит вычислительные ресурсы системы.
В-третьих, использование процедур баз данных позволяет значительно снизить трафик сети в системах с архитектурой "клиент-сервер". Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры. В процедуре, как правило, концентрируются повторяющиеся фрагменты из нескольких прикладных программ (Рис. 13). Если бы эти фрагменты остались частью программы, они загружали бы сеть посылкой полных SQL-запросов.
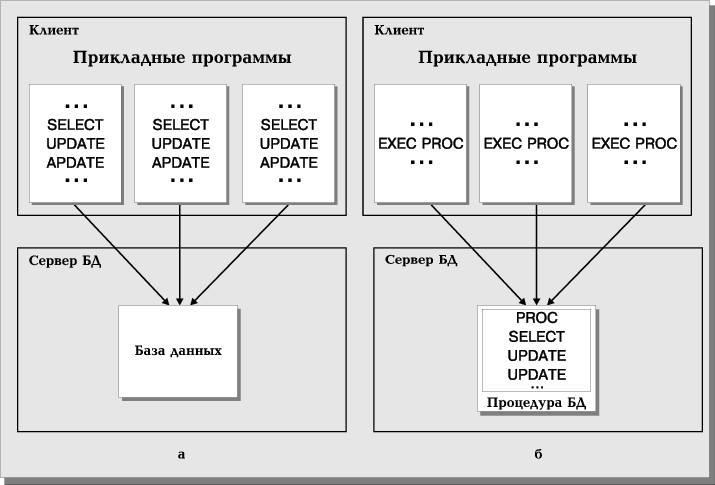
Наконец, в-четвертых, процедуры базы данных в сочетании с правилами, о которых речь пойдет ниже, предоставляют администратору мощные средства поддержки целостности базы данных.
В современных СУБД процедура хранится непосредственно в базе данных и контролируется ее администратором. Она имеет параметры и возвращает значение. Процедура базы данных создается оператором CREATE PROCEDURE (СОЗДАТЬ ПРОЦЕДУРУ) и содержит определения переменных, операторы SQL (например, SELECT, INSERT), операторы проверки условий (IF/THEN/ ELSE) операторы цикла (FOR, WHILE), а также некоторые другие.
Пусть, например, необходимо разработать процедуру, которая переводила бы рядового сотрудника в резерв на выдвижение на руководящую должность. Процедура Назначение перемещает строки из таблицы Сотрудник, содержащей сведения о сотрудниках, в таблицу Резерв для всех сотрудников с указанным номером. Номер сотрудника представляет собой целое число (тип integer), который не может иметь пустое значение, является параметром процедуры и передается ей при вызове из прикладной программы оператором EXECUTE PROCEDURE (ВЫПОЛНИТЬ ПРОЦЕДУРУ).
CREATE PROCEDURE Назначение
(Номер_сотрудника integer not nul)
AS
BEGIN
INSERT INTO Резерв
SELECT *
FROM Сотрудник
WHERE Номер = Номер_сотрудника;
DELETE
FROM Сотрудник
WHERE Номер = Номер_сотрудника;
END
Правила
Механизм правил (триггеров) позволяет программировать обработку ситуаций, возникающих при любых изменениях в базе данных.
Правило придается таблице базы данных и применяется при выполнении над таблицей операций включения, удаления или обновления строк.
Применение правила заключается в проверке сформулированных в нем условий, при выполнении которых происходит вызов специфицированной внутри правила процедуры базы данных. Важно, что правило может быть применено как до, так и после выполнения обновления, следовательно, возможна отмена операции.
Таким образом, правило позволяет определить реакцию сервера на любое изменение состояния базы данных. Правила (так же, как и процедуры) хранятся непосредственно в базе данных независимо от прикладных программ.
Одна из целей механизма правил — отражение некоторых внешних правил деятельности организации. Пусть, например, в базе данных Склад содержится таблица Деталь, хранящая сведения о наличии деталей на складе завода. Одно из правил деятельности завода заключается в том, что недопустима ситуация, когда на складе число деталей любого типа становится меньше некоторого числа (например, 1000).
Это требование реальной жизни описывается правилом Проверить_деталь. Оно применяется в случае обновления столбца Количество таблицы Деталь: если новое значение в столбце меньше 1000, то выполняется процедура Заказать_деталь. В качестве параметров ей передаются номер детали данного типа и остаток (число деталей на складе).
CREATE RULE Проверить_деталь
AFTER UPDATE (Количество) OF Деталь
WHERE Деталь.Количество < 1000
EXECUTE PROCEDURE Заказать_деталь
(Номер детали = Деталь.Номер,
Остаток = Деталь.Количество);
Таким образом, если возникает ситуация, когда на складе количество деталей какого-либо типа становиться меньше требуемого, запускается процедура базы данных, которая заказывает недостающее количество деталей этого типа. Заказ сводится к посылке письма (например, по электронной почте), на завод или в цех, который изготавливает данные детали. Все это происходит автоматически, без вмешательства пользователя. Пример этот, разумеется, упрощенный — в нем не учтено, что заказ мог быть уже сделан раньше.
Важнейшая цель механизма правил — обеспечение целостности базы данных. Один из аспектов целостности — целостность по ссылкам (referential integrity) — относится к связи двух таблиц между собой. Напомним, что эта связь поддерживается внешними ключами.
Пусть, например, таблица Руководитель содержит сведения о начальниках, а таблица Сотрудник — о сотрудниках некоторой организации (см. пример в Разд. Реляционная база данных — основные понятия). Столбец Номер руководителя является внешним ключом таблицы Сотрудник и является ссылкой этой таблицы к таблице Руководитель.
Для обеспечения целостности ссылок должны быть учтены два требования. Во-первых, если в таблицу Сотрудник добавляется новая строка, значение столбца номер руководителя должно быть взято из множества значений столбца Номер таблицы Руководитель (сотрудник может быть подчинен только реальному руководителю). Во-вторых, при удалении любой строки из таблицы Руководитель в таблице Сотрудник не должно остаться ни одной строки, в которой в столбце Номер руководителя было бы значение, тождественное значению столбца Номер в удаляемой строке (все сотрудники, если их руководитель уволился, должны перейти в подчинение другому).
Как учесть эти требования на практике? Очевидно, что должны быть созданы правила, их реализующие. Первое правило Добавить_сотрудника срабатывает при включении строки в таблицу Сотрудник; его применение заключается в вызове процедуры Проверить_руководителей, проверяющей, существует ли среди множества значений столбца Номер таблицы Руководитель значение, тождественное значению поля Номер_руководителя добавляемой строки. Если это не так, процедура должна ее отвергнуть. Второе правило применяется при попытке удалить строку из таблицы Руководитель; оно состоит в вызове процедуры, которая сравнивает значения в столбце Номер_руководителя таблицы Сотрудник со значением поля Номер в удаляемой строке. В случае совпадения значение в столбце Номер_руководителя обновляется.
CREATE RULE Добавить_сотрудника
AFTER INSERT INTO Сотрудник
EXECUTE PROCEDURE
Проверить_руководителя
(Номер = Сотрудник.Номер_руководителя);
Механизм правил позволяет реализовать и более общие ограничения целостности. Пусть, например, таблица Сотрудник содержит информацию о сотрудниках, в том числе имя и название отдела, в котором они работают. Таблица Отдел хранит для каждого отдела количество работающих в нем сотрудников в столбце Количество сотрудников. Одно из ограничений целостности заключается в том, что это количество должно совпадать с числом строк для данного отдела в таблице Сотрудник. Как учесть это ограничение? Одно из возможных решений состоит в использовании правила Добавить_сотрудника, которое применяется при включении строки в таблицу Сотрудник и запускает процедуру Новый_сотрудник. Она, в свою очередь, обновляет значение столбца Количество_сотрудников, увеличивая его на единицу. Параметр процедуры — название отдела.
CREATE RULE
AFTER INSERT INTO Сотрудник
EXECUTE PROCEDURE Новый_сотрудник
(Отдел = Сотрудник.Отдел);
Разумеется, на практике при помощи механизма правил реализуются более сложные и изощренные ограничения целостности.
Механизм правил — сердце активного сервера базы данных. Аналогом правил послужили триггеры (triggers), которые впервые появились в СУБД Sybase (насколько известно автору) и впоследствии были реализованы в том или ином виде и под тем или иным названием в большинстве многопользовательских СУБД.
События в базе данных
Механизм событий в базе данных (database events) позволяет прикладным программам и серверу базы данных уведомлять другие программы о наступлении в базе данных определенного события и тем самым синхронизировать их работу. Операторы языка SQL, обеспечивающие уведомление, часто называют сигнализаторами событий в базе данных (database event alerters). Функции управления событиями целиком ложатся на сервер базы данных.
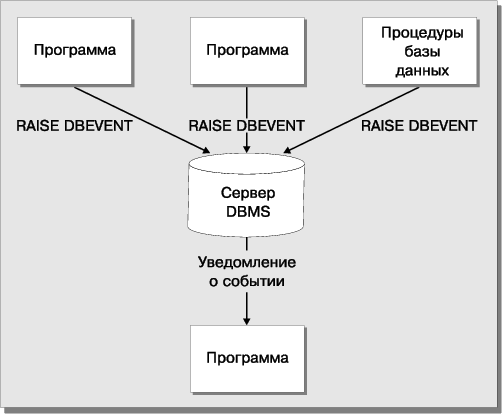
Рис. 14 иллюстрирует один из примеров использования механизма событий: различные прикладные программы и процедуры вызывают события в базе данных, а сервер оповещает монитор прикладных программ об их наступлении. Реакция монитора на события заключается в выполнении действий, которые предусмотрел его разработчик.
Механизм событий используется следующим образом. Вначале в базе данных для каждого события создается флажок, состояние которого будет оповещать прикладные программы о том, что некоторое событие имело место (оператор CREATE DBEVENT — СОЗДАТЬ СОБЫТИЕ). Далее, во все прикладные программы, на ход выполнения которых может повлиять это событие, включается оператор REGISTER DBEVENT (ЗАРЕГИСТРИРОВАТЬ СОБЫТИЕ), который оповещает сервер базы данных, что программа заинтересована в получении сообщения о наступлении события. Теперь любая прикладная программа или процедура базы данных может вызвать событие оператором RAISE DBEVENT (ВЫЗВАТЬ СОБЫТИЕ). Как только событие произошло, каждая зарегистрированная программа может получить его, для чего она должна запросить очередное сообщение из очереди событий (оператор GET DBEVENT — ПОЛУЧИТЬ СОБЫТИЕ) и запросить информацию о событии, в частности, его имя (оператор SQL INQUIRE_SQL).
Следующий пример иллюстрирует обработку всех событий из очереди.
loop
EXEC SQL GET DBEVENT;
EXEC SQL INQUIRE_SQL (:event_name =
DBEVENTNAME);
if (event_name = 'event_1')
обработать событие event_1
else if (event_name = 'event_2')
обработать событие event_2
else
...
endif
until event_name = ' '
Рассмотрим пример из производственной системы, иллюстрирующий использование механизма событий в базе данных совместно с правилами и процедурами. События используются для определения ситуации, когда рабочий инструмент нагревается до температуры свыше допустимой и должен быть отключен.
Создается правило, которое применяется всякий раз, когда новое значение температуры инструмента заносится в таблицу Инструмент. Как только оно превосходит 500 градусов, правило вызывает процедуру Отключить_инструмент.
CREATE RULE Перегрев_инструмента
AFTER UPDATE OF Инструмент
(Температура)
WHERE Новое.Температура >= 500
EXECUTE PROCEDURE
Отключить_инструмент
(Номер_инструмента =
Инструмент.Номер);
Создается процедура базы данных Отключить_инструмент, которая вызывает событие Перегрев; она будет выполнена в результате применения правила, определенного на шаге 1.
CREATE PROCEDURE Отключить_инструмент
(Номер_инструмента) AS
BEGIN
UPDATE Инструмент
SET Статус = 'ВЫКЛ'
WHERE Номер = Номер_инструмента;
RAISE DBEVENT Перегрев;
END;
Создается событие Перегрев, которое будет вызвано, когда инструмент перегреется:
CREATE DBEVENT Перегрев;
Наконец, создается прикладная программа Монитор Инструментов, которая следит за состоянием инструментов. Она регистрируется сервером в качестве получателя события Перегрев с помощью оператора REGISTER DBEVENT. Если событие произошло, программа посылает сообщение пользователю и сигнал, необходимый для отключения инструмента.
...
EXEC SQL REGISTER DBEVENT Перегрев;
...
EXEC SQL GET DBEVENT;
EXEC SQL INQUIRE_SQL (Имя события =
DBEVENTNAME, ...);
if (Имя события = 'Перегрев') then
послать сообщение;
отключить инструмент;
endif;
Описанные выше конструкции в совокупности определяют следующую логику работы (Рис. 15):
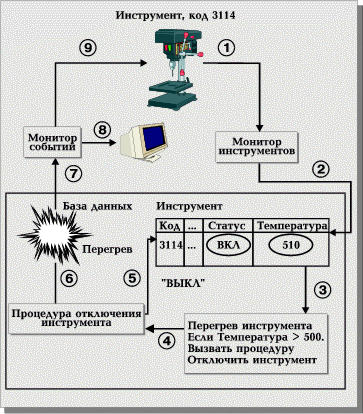
- Прикладная программа Монитор Инструментов периодически регистрирует с помощью датчиков текущие значения параметров множества различных инструментов.
- Та же программа заносит в таблицу Инструмент новое значение температуры для данного инструмента.
- Всякий раз, когда это происходит, то есть обновляется значение в столбце Температура таблицы Инструмент, применяется правило Перегрев_инструмента.
- Применение правила состоит в проверке нового значения температуры. Если оно превышает максимально допустимое, то запускается процедура Отключить_инструмент.
- Она изменяет значение в столбце Статус таблицы Инструмент на 'ВЫКЛ'.
- Она же вызывает событие Перегрев.
- Программа Монитор Событий получает (перехватывает) событие Перегрев.
- Она же посылает сообщение на экран диспетчеру.
- Она же отключает инструмент.
В том случае, когда используются традиционные методы опроса БД, логика работы была бы совершенно иной. Пришлось бы разработать дополнительную программу, которая периодически выполняла бы операцию выборки из таблицы Инструмент по критерию "Температура > 500". Это очень сильно сказалось бы на эффективности, поскольку операция SELECT влечет серьезные накладные расходы.
Разумеется, пример приведен лишь для иллюстрации схемы срабатывания механизма "правило — процедура — событие" и ни в коей мере не отражает реальные схемы управления технологическими процессами на производстве.
Типы данных, определяемые пользователем
Проблемы с типами данных, о которых шла речь выше, решаются за счет интеграции в сервер новых типов данных. К сожалению, далеко не все современные СУБД поддерживают типы данных, определенные пользователем. Пока только СУБД Ingres включает такой механизм. Эта система предоставляет программисту возможность определять собственные типы данных и операции над ними и использовать их в операторах SQL. Для определения нового типа данных необходимо написать и откомпилировать функции на языке Си, после чего собрать редактором связей некоторые модули Ingres. Отметим, что введение новых типов данных является, по сути, изменением ядра СУБД. Важно также то, что в Ingres типы данных, определяемые пользователем, могут быть параметризованными.
Определение нового типа данных сводится к указанию его имени, размера и идентификатора в глобальной структуре, описывающей типы данных. Чтобы с новым типом данных можно было использовать функции, которые реализуют стандартные операции (сравнение, преобразование в различные форматы, и т.д.), программист должен разработать их самостоятельно (интерфейс функций предопределен). Указатели на эти функции являются элементами глобальной структуры. Как только новый тип данных определен, то все операции выполняются над ним, как над данными стандартного типа. Разрешение пользователю создавать собственные типы данных по сути является одним из шагов развития реляционных СУБД в направлении объектно-реляционных систем.
Обработка распределенных данных
Одна из главных особенностей современных информационных систем — распределенный характер. Возрастает их масштаб, они охватывают все больше число точек по всему миру. Современный уровень принятия решений, оперативное управление информационными ресурсами требует все большей их децентрализации. Информационные системы находятся в постоянном развитии — в них добавляются новые сегменты, расширяется диапазон функций уже действующих. Примером распределенной системы может послужить система резервирования билетов крупной авиакомпании, имеющей свои филиалы в различных частях Земли.
Главная проблема таких систем — организация обработки распределенных данных. Данные находятся на компьютерах различных моделей и производителей, функционирующих под управлением различных операционных систем, а доступ к данным осуществляется разнородным программным обеспечением. Сами компьютеры территориально удалены друг от друга и находятся в различных географических точках планеты.
Ответом на задачи реальной жизни стали две технологии: технология распределенных баз данных (Distributed Database) и технология тиражирования данных (Data Replication).
Под распределенной базой данных подразумевают базу, включающую фрагменты из нескольких баз данных, которые располагаются на различных узлах сети компьютеров, и, возможно, управляются различными СУБД. Распределенная база данных выглядит с точки зрения пользователей и прикладных программ как обычная локальная база. В этом смысле слово "распределенная" отражает способ организации базы данных, но не внешнюю ее характеристику ("распределенность" базы не должна быть видна извне).
В отличие от распределенных баз, тиражирование данных предполагает отказ от их физического распределения и опирается на идею дублирования данных в различных узлах сети компьютеров. Ниже будут изложены детали, преимущества и недостатки каждой технологии.
Однако, прежде чем переходить к рассмотрению проблем обработки распределенных данных, необходимо разобраться с некоторыми аспектами сетевого взаимодействия (доступ к удаленным данным).
Аспекты сетевого взаимодействия
В Разд. Сервер базы данных были рассмотрены четыре модели технологии "клиент-сервер". Традиционной и наиболее популярной является модель доступа к удаленным данным (RDA-модель). Рассмотрим ее еще раз, но более детально. Итак, имеется компьютер, на котором запускаются программы переднего плана (в которых реализованы как функции интерфейса с пользователем, так и прикладные функции) — клиент (называемый обычно локальным узлом — local node), соединенный в сети с компьютером, на котором выполняется сервер базы данных и находится сама база данных (обычно его называют удаленным узлом — remote node). Все проблемы, возникающие при взаимодействии клиента и сервера, должен решать специальный компонент СУБД, называемый коммуникационным сервером (Communication Server, DBMS Server Net). Для поддержки взаимодействия клиента и сервера он должен функционировать на удаленном узле; в то же время на локальном узле должна выполняться программа связи, взаимодействующая с коммуникационным сервером (DBMS Client Net).
В основу взаимодействия прикладных программ — клиентов и сервера базы данных, положен ряд фундаментальных принципов, определяющих функциональные возможности современных СУБД в части, касающейся сетевого взаимодействия и распределенной обработки данных, среди которых:
- Прозрачность расположения;
- Прозрачность сети;
- Автоматическое преобразование форматов данных;
- Автоматическая трансляция кодов;
- Межоперабельность;
- Прозрачность расположения.
Прозрачный (для пользователя) доступ к удаленным данным предполагает использование в прикладных программах такого интерфейса с сервером БД, который позволяет переносить данные в сети с одного узла на другой, не требуя при этом модификации текста программы. Иными словами, доступ к информационным ресурсам должен быть полностью прозрачен относительно расположения данных.
Любой пользователь или любая прикладная программа оперирует с одной или несколькими базами данных. В том случае, когда прикладная программа и сервер БД выполняются на одном и том же узле, проблемы расположения не возникает. Для получения доступа к базе данных, пользователю или программе достаточно указать имя базы, например: SQL Dbname.
Однако в том случае, когда прикладная программа запускается на локальном узле, а база данных находится на удаленном, возникает проблема идентификации удаленного узла. Для того, чтобы получить доступ к базе данных на удаленном узле, необходимо указать имя удаленного узла и имя базы данных. Если использовать жестко фиксированное имя узла в паре "имя_узла, имя_БД", то прикладная программа становится зависимой от расположения БД. Например, обращение к БД "host::stock", где первый компонент есть имя узла, будет зависимым от расположения.
Одно из возможных решений этой проблемы состоит в использовании виртуальных имен узлов. Управление ими обеспечивается специальным программным компонентом СУБД — сервером имен (Name Server), который адресует запросы клиентов к серверам.
При установке компонентов DBMS Client Net на локальных узлах выполняется процедура идентификации узлов, когда реальному имени удаленного узла ставится в соответствие виртуальное имя, которое затем используется при обращении к базе данных. Если база данных перенесена на другой узел, то никаких изменений в прикладную программу вносить не нужно — достаточно лишь поставить в соответствие виртуальному имени имя нового узла.
Прозрачность сети
Клиент и сервер взаимодействуют по сети с конкретной топологией; для поддержки взаимодействия всегда используется определенный протокол. Следовательно, оно должно быть организовано таким образом, чтобы обеспечивать независимость как от используемого сетевого аппаратного обеспечения, так и от протоколов сетевого обмена. Чтобы обеспечить прозрачный доступ пользователей и программ к удаленным данным в сети, объединяющей разнородные компьютеры, коммуникационный сервер должен поддерживать как можно более широкий диапазон сетевых протоколов (TCP/IP, DECnet, SNA, SPX/IPX, NetBIOS, AppleTalk, и др.).
Автоматическое преобразование форматов данных
Как только несколько компьютеров различных моделей под управлением различных операционных систем соединяются в сеть, сразу возникает вопрос о согласовании форматов представления данных. Действительно, в сети могут быть компьютеры, отличающиеся разрядностью (16-ти, 32-х и 64-х разрядные процессоры), порядком следования байт в слове, представлением чисел с плавающей точкой и т.д. Задача коммуникационного сервера состоит в том, чтобы на уровне обмена данными обеспечить согласование форматов между удаленным и локальным узлами с тем, чтобы данные, извлеченные сервером из базы на удаленном узле и переданные по сети, были правильно истолкованы прикладной программой на локальном узле.
Автоматическая трансляция кодов
В неоднородной компьютерной среде при взаимодействии клиента и сервера возникает также задача трансляции кодов. Сервер может работать с одной кодовой таблицей (например, EBCDIC), клиент — с другой (например, ASCII), при этом происходит рассогласование трактовки кодов символов. Поэтому, если на локальном узле используется одна кодовая таблица, а на удаленном — другая, то при передаче запросов по сети и при получении ответов на них необходимо обеспечить трансляцию кодов. Решение этой задачи также ложится на коммуникационный сервер.
Мы рассмотрели детали взаимодействия одной пары "клиент-сервер". Однако в реальной жизни сервер базы данных должен обслуживать одновременно множество запросов от клиентов — следовательно, в один момент времени таких пар может быть несколько. И все проблемы взаимодействия, о которых речь шла выше, должны решаться коммуникационным сервером для всех этих взаимодействующих пар.
Системы с архитектурой "один-к-одному" (см. Разд. Сервер базы данных) для обслуживания сервером базы данных одновременно множества клиентов вынуждены загружать отдельный коммуникационный сервер для каждой пары "клиент-сервер". В результате нагрузка на операционную систему увеличивается, резко возрастает общее число ее процессов, расходующих вычислительные ресурсы. Это — один из недостатков архитектуры "один-к-одному".
Именно поэтому для современных распределенных СУБД важно иметь многопотоковый коммуникационный сервер, который берет на себя задачи сетевой поддержки множества клиентов, одновременно обращающихся к серверу. На каждом узле сети он поддерживает множество пар соединений "клиент-сервер" и позволяет существовать одновременно множеству независимых сеансов работы с базами данных.
Распределенные базы данных
Суть распределенной базы данных выражена формулой: "Доступ к распределенной базе данных выглядит для клиента точно так же, как доступ к централизованной БД".
Рассмотрим пример. Пусть БД Склад расположена на узле Узел_1, а БД Предприятия — на узле Узел_2. В первой содержится таблица Деталь, во второй — Поставщик. Пусть БД Номенклатура должна включать таблицы Деталь и Поставщик, физически принадлежащие различным БД. Логически она будет рассматриваться как нераспределенная БД. Ниже приведены операторы SQL, которые устанавливают ссылки на таблицы локальных баз данных. Они включены в описание распределенной базы данных и передаются серверу распределенной БД, о котором речь пойдет ниже.
REGISTER TABLE Деталь AS LINK
WITH NODE = Узел_1,
DATABASE = Склад;
REGISTER TABLE Поставщик AS LINK
WITH NODE = Узел_2,
DATABASE = Предприятия;
Таким образом, при описании распределенной БД Номенклатура явно задаются ссылки на конкретные таблицы реально существующих баз данных; однако при работе с такой базой это физическое распределение данных прозрачно для пользователя.
До сих пор мы говорили о проблемах сетевого взаимодействия клиента и сервера. Их решение с помощью коммуникационного сервера является необходимым (но не достаточным) условием поддержки распределенных баз данных. Неразрешенными пока остаются следующие задачи:
- Управление именами в распределенной среде;
- Оптимизация распределенных запросов;
- Управление распределенными транзакциями.
Первая решается путем использования глобального словаря данных. Он хранит информацию о распределенной базе: расположение данных, возможности других СУБД (если используется шлюз), сведения о скорости передачи по сети с различной топологией и т.д.
Глобальный словарь данных — это механизм отслеживания расположения объектов в распределенной БД. Данные могут храниться на локальном узле, на удаленном узле, или на обоих узлах — их расположение должно оставаться прозрачным как для конечного пользователя, так и для программ. Не нужно явным образом указывать место расположения данных — программа должна быть полностью независима от того, на каких узлах размещаются данные, с которыми она оперирует.
Что касается второй задачи, то она требует интеллектуального решения. Распределенный запрос затрагивает несколько баз данных на различных узлах, причем объемы выборки могут быть весьма различными. Обратимся к БД Номенклатура, которая распределена по двум узлам сети. Таблица Деталь хранится на одном узле, таблица Поставщик — на другом. Размер первой таблицы — 10000 строк, размер второй — 100 строк (множество деталей поставляется небольшим числом поставщиков). Допустим, что выполняется запрос:
SELECT Название_детали,
Название_поставщика,
Адрес_поставщика
FROM Деталь, Поставщик
WHERE Материал = 'Пластмасса';
Результат запроса — таблица, содержащая столбец Название_детали из таблицы Деталь и столбцы Название_поставщика и Адрес_поставщика из таблицы Поставщик. То есть результирующая таблица представляет собой объединение (join) двух таблиц. Оно выполнено по столбцу Номер_поставщика в таблице Деталь (внешний ключ) и столбцу Номер таблицы Поставщик (первичный ключ).
Данный запрос — распределенный, так как затрагивает таблицы, принадлежащие различным локальным БД. Для его нормального выполнения необходимо иметь обе исходные таблицы на одном узле. Следовательно, одна из таблиц должна быть передана по сети. Очевидно, что это должна быть таблица меньшего размера, то есть таблица Поставщик. Поэтому оптимизатор распределенных запросов обязательно должен учитывать размеры таблиц. В противном случае запрос будет выполняться непредсказуемо долго.
Помимо размера таблиц, оптимизатор распределенных запросов должен учитывать также множество дополнительных параметров, в том числе статистику распределения данных по узлам, объем данных, передаваемых между узлами, скорость коммуникационных линий, структуры хранения данных, соотношение производительности процессоров на разных узлах и т.д. Все эти данные как раз и содержатся в глобальном словаре данных.
Что касается обработки распределенных транзакций, то эта тема будет обсуждаться в следующем Разд. Обработка транзакций.
Решение всех трех задач, о которых речь шла выше, возложено на специальный компонент СУБД — сервер распределенных баз данных (Distributed Database Server).
Если база данных расположена на одном узле, а сервер БД и прикладная программа выполняются там же, то не требуется ни коммуникационный сервер, ни сервер распределенной БД. Когда же прикладная программа выполняется на локальном узле, БД находится на удаленном узле и там же выполняется сервер БД, то на удаленном узле необходим коммуникационный сервер, а на локальном — сервисная коммуникационная программа.
Если локальные БД расположены на нескольких узлах, то для доступа к распределенной БД необходим и сервер распределенной БД, и коммуникационный сервер.
Важнейшее требование к современным СУБД — межоперабельность (или интероперабельность). Это качество можно трактовать как открытость системы, позволяющую встраивать ее как компонент в сложную разнородную распределенную среду. Межоперабельность достигается как за счет использования интерфейсов, соответствующих международным, национальным и промышленным стандартам, так и за счет специальных решений.
Для СУБД это качество означает следующее:
- способность приложений, созданных средствами разработки данной СУБД, оперировать над базами данных в "чужом" формате так, как будто это собственные базы данных;
- свойство СУБД, позволяющее ей служить в качестве поставщика данных для любых приложений, созданных средствами разработки третьих фирм, поддерживающих некоторый стандарт обращения к базам данных.
Первое достигается использованием шлюзов, второе - использованием интерфейса ODBC, который будет рассмотрен в Разд. Взаимодействие с PC-ориентированными СУБД.
До сих пор мы рассматривали однородные базы данных, то есть БД в формате конкретной СУБД. В то же время СУБД может осуществлять доступ к БД в другом формате. Это делается с помощью шлюза. Например, СУБД Ingres получает доступ к базе данных в формате СУБД Rdb через специальный шлюз. Если СУБД Альфа осуществляет доступ к базе данных в формате Бета (или просто к базе данных Бета), то говорят, что Альфа имеет шлюз в Бета.
Современные информационные системы требуют доступа к разнородным базам данных. Это означает, что в прикладной программе для реализации запросов к базам данных должны быть использованы такие средства, чтобы запросы были понятны различным СУБД, как реляционным, так и опирающимся на другие модели данных. Одним из возможных путей является обобщенный набор различных диалектов языка SQL (как это сделано, например, в СУБД OpenIngres).
Система, в которой несколько компьютеров различных моделей и производителей связаны в сеть, и на каждом из них функционирует собственная СУБД, называется гетерогенной. Рассмотрим пример такой системы (Рис. 16).
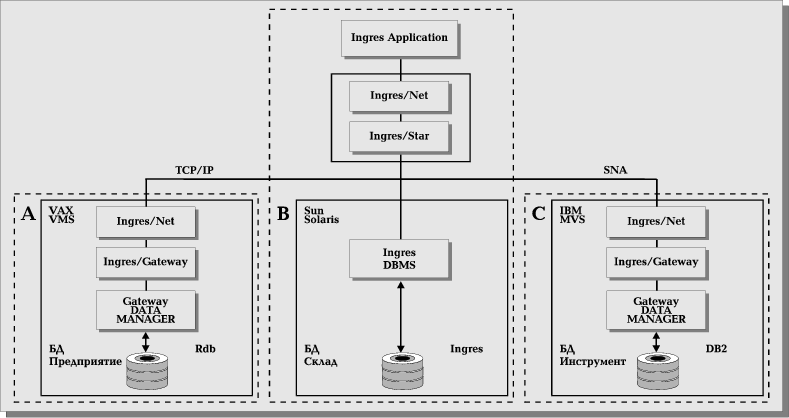
Глобальная база данных распределена по трем узлам. Узел A — это компьютер VAX 6000/560 с ОС VMS и СУБД Rdb, где расположена локальная БД Предприятия в формате Rdb. Второй узел (B) представляет собой компьютер SUN Sparc Server 1000 под управлением операционной системы Solaris. На нем функционирует СУБД Ingres и находится локальная БД Склад в формате Ingres. В качестве узла C выступает mainframe IBM с операционной системой MVS и СУБД DB2. На нем расположена локальная БД Инструмент в формате DB2.
Сервер распределенной БД — компонент СУБД Ingres — выполняется на узле B. Коммуникационные серверы Ingres работают на всех трех узлах. Узлы A и B используют для взаимодействия протокол TCP/IP, в то время как узлы B и C общаются в соответствии со стандартом SNA.
Локальные БД на всех трех узлах управляются абсолютно автономно. Распределенная БД Производство содержит таблицы из всех трех локальных БД. Для доступа сервера распределенной БД к БД Предприятия необходим шлюз из Ingres в Rdb, а для доступа к БД Инструмент — шлюз из Ingres в DB2.
Шлюз из Ingres в DB2 позволяет манипулировать данными в формате DB2 так, как будто они — данные в формате Ingres. Шлюз из Ingres в Rdb позволяет оперировать с данными в формате Rdb так, как будто они — данные в формате Ingres.
Все эти детали не видны конечному пользователю. Он работает с БД Производство так, как будто это централизованная БД Ingres. Это и есть полностью прозрачный доступ к данным.
Отметим, что технология распределенных БД защищает инвестиции в программное обеспечение. Она может рассматриваться как "мост", перекинутый от mainframe-систем и нереляционных СУБД к современными профессиональным СУБД на платформе RISC-компьютеров. Она позволяет разрабатывать для них прикладные программы, обеспечивая им доступ к огромным массивам информации на больших ЭВМ, и тем самым гарантирует мягкий и безболезненный переход к новой платформе.
Технология тиражирования данных
Принципиальное отличие технологии тиражирования данных от технологии распределенных баз данных (которую часто для краткости называют технологией STAR) заключается в отказе от распределенных данных. Ее суть состоит в том, что любая БД (как для СУБД, так и для работающих с ней пользователей) всегда является локальной; данные всегда размещаются локально на том узле сети, где они обрабатываются; все транзакции в системе завершаются локально.
Тиражирование данных — это асинхронный перенос изменений объектов исходной базы данных (source database) в БД, принадлежащие различным узлам распределенной системы. Функции тиражирования данных выполняет специальный модуль СУБД — сервер тиражирования данных, называемый репликатором (replicator). Его задача — поддержка идентичности данных в принимающих базах данных (target database) данным в исходной БД. Сигналом для запуска репликатора служит срабатывание правила (см. Разд. Сервер базы данных), перехватывающего любые изменения тиражируемого объекта БД. Возможно и программное управление репликатором посредством сигнализаторов о событиях в базе данных.
В качестве базиса для тиражирования выступает транзакция к БД. В то же время возможен перенос изменений группами транзакций, периодически или в некоторый момент времени, что дает возможность исследовать состояние принимающей БД на определенный момент времени.
Детали тиражирования данных полностью скрыты от прикладной программы; ее функционирование никак не зависит от работы репликатора, который целиком находится в ведении администратора БД. Следовательно, для переноса программы в распределенную среду с тиражируемыми данными не требуется ее модифицировать.
Технология распределенных БД и технология тиражирования данных — в определенном смысле антиподы. Краеугольный камень первой — синхронное завершение транзакций одновременно на нескольких узлах распределенной системы, то есть синхронная фиксация изменений в распределенной БД. "Ахиллесова пята" технологии STAR — жесткие требования к производительности и надежности каналов связи. Если БД распределена по нескольким территориально удаленным узлам, объединенным медленными и ненадежными каналами связи, а число одновременно работающих пользователей составляет десятки и выше, то вероятность того, что распределенная транзакция будет зафиксирована в обозримом временном интервале, становится чрезвычайно малой. В таких условиях (характерных, кстати, для большинства отечественных организаций) обработка распределенных данных практически невозможна.
Реальной альтернативой технологии STAR становится технология тиражирования данных, не требующая синхронной фиксации изменений (и в этом ее сильная сторона). В действительности далеко не во всех задачах требуется обеспечение идентичности БД на различных узлах в любое время. Достаточно поддерживать тождественность данных лишь в определенные критичные моменты времени. Следовательно, можно накапливать изменения в данных в виде транзакций в одном узле и периодически копировать эти изменения на другие узлы.
Просуммируем очевидные преимущества технологии тиражирования данных. Во-первых, данные всегда расположены там, где они обрабатываются — следовательно, скорость доступа к ним существенно увеличивается. Во-вторых, передача только операций, изменяющих данные (а не всех операций доступа к удаленным данным, как в технологии STAR), и к тому же в асинхронном режиме позволяет значительно уменьшить трафик. В-третьих, со стороны исходной БД для принимающих БД репликатор выступает как процесс, инициированный одним пользователем, в то время как в физически распределенной среде с каждым локальным сервером работают все пользователи распределенной системы, конкурирующие за ресурсы друг с другом. Наконец, в-четвертых, никакой продолжительный сбой связи не в состоянии нарушить передачу изменений. Дело в том, что тиражирование предполагает буферизацию потока изменений (транзакций); после восстановления связи передача возобновляется с той транзакции, на которой тиражирование было прервано.
Технология тиражирования данных не лишена некоторых недостатков, вытекающих из ее специфики. Например, невозможно полностью исключить конфликты между двумя версиями одной и той же записи. Они могут возникнуть, когда вследствие все той же асинхронности два пользователя на разных узлах исправят одну и ту же запись в тот момент, пока изменения в данных из первой базы данных еще не были перенесены во вторую. Следовательно, при проектировании распределенной среды с использованием технологии тиражирования данных необходимо предусмотреть конфликтные ситуации и запрограммировать репликатор на какой-либо вариант их разрешения.
Завершая обсуждение, отметим, что тиражирование данных — это не очередной технологический изыск и не прихоть разработчиков СУБД. Жизненность концепции тиражирования подтверждается опытом ее использования в области, предъявляющей повышенные требования к надежности — в сфере банковских информационных систем.
Взаимодействие с PC-ориентированными СУБД
Первоначально профессиональные СУБД создавались для мощных высокопроизводительных платформ — IBM, DEC, Hewlett-Packard, Sun. Но затем, учитывая все возрастающую популярность и широкое распространение персональных компьютеров, разработчики приступили к переносу (портированию) СУБД в операционные среды desktop-компьютеров (OS/2, NetWare, UnixWare, SCO UNIX).
В настоящее время большинство компаний — поставщиков СУБД развивает три направления своих систем. Во-первых, совершенствование СУБД для корпоративных информационных систем, которые характеризуются большим числом пользователей (от 100 и выше), базами данных огромного объема (их часто называют сверхбольшими базами данных — Very Large Data Base — VLDB), смешанным характером обработки данных (решение задач оперативной обработки транзакций и поддержки принятия решений) и т.д. Это — традиционная область mainframe-систем и приближающихся к ним по производительности RISC-компьютеров.
Другое, не менее важное направление — СУБД, поддерживающие так называемые рабочие группы. Это направление характеризуется относительно небольшим количеством пользователей (камерный характер применения СУБД) с сохранением, тем не менее, всех "многопользовательских" качеств. Системы этого класса ориентированы преимущественно на "офисные" применения, не требующие специальных возможностей. Так, большинство современных многопользовательских СУБД имеют версии системы, функционирующие в сетевой операционной системе Novell NetWare. Ядро СУБД оформлено здесь как загружаемый модуль NetWare (NetWare Loadable Module — NLM), выполняющийся на файловом сервере. База данных также располагается на файловом сервере. SQL-запросы поступают к ядру СУБД от прикладных программ, которые запускаются на станциях сети — персональных компьютерах (отметим, что, несмотря на использование файлового сервера, здесь мы имеем дело с RDA-моделью).
Наконец, новый импульс в развитии получило направление настольных (desktop) версий СУБД, ориентированных на персональное использование — преимущественно в операционной среде MS Windows (системы этого класса получили неформальное определение "light").
Стремление компаний — поставщиков СУБД иметь фактически по три варианта своих систем, покрывающих весь спектр возможных применений, выглядит для пользователей чрезвычайно привлекательно. Действительно, для специалиста исключительно удобно иметь на своем портативном компьютере локальную базу данных (постоянно используемую во время командировок) в том же формате и обрабатываемую по тем же правилам, что и стационарную корпоративную базу фирмы, куда собранные данные могут быть без труда доставлены.
В последние годы (1987-94) в нашей стране было разработано множество программ, ориентированных на использование СУБД типа PARADOX, FoxPRO, dBASE IV, Clipper. При переходе на более мощную многопользовательскую СУБД у пользователей возникает естественное желание интегрировать уже существующие разработки в эту среду. Например, может возникнуть потребность хранить локальные данные на персональном компьютере и осуществлять к ним доступ с помощью системы FoxPRO, и одновременно иметь доступ к глобальной базе данных под управлением СУБД Oracle. Организация такого доступа, когда программа может одновременно работать и с персональной, и с многопользовательской СУБД, представляет собой сложную проблему по следующей причине.
Как известно, разработчики PC-ориентированных СУБД первоначально использовали свой собственный интерфейс к базам данных, никак не учитывая требования стандарта языка SQL. Лишь впоследствии они стали постепенно включать в свои системы возможности работы с базой данных при помощи SQL. В то же время для истинно многопользовательских СУБД интерфейс SQL — фактический стандарт. При этом возникла задача согласования интерфейсов СУБД различных классов. Она может решаться несколькими способами, но большинство из них имеют частный характер. Рассмотрим наиболее общее решение этой задачи.
Специалисты фирмы Microsoft разработали стандарт Open Database Connectivity (ODBC). Он представляет собой стандарт прикладного программного интерфейса (Application Programming Interface — API) и позволяет программам, работающим в среде Microsoft Windows, взаимодействовать (посредством операторов языка SQL) с различными СУБД, как персональными, так и многопользовательскими, функционирующими в различных операционных системах. Фактически, интерфейс ODBC универсальным образом отделяет чисто прикладную, содержательную сторону приложений (обработка электронных таблиц, статистический анализ, деловая графика) от собственно обработки и обмена данными с СУБД. Основная цель ODBC — сделать взаимодействие приложения и СУБД прозрачным, не зависящим от класса и особенностей используемой СУБД (мобильным с точки зрения используемой СУБД).
Отметим, что стандарт ODBC является неотъемлемой частью семейства стандартов, облегчающих написание и обеспечивающих вертикальную открытость приложений (WOSA — Windows Open Services Architecture — открытая архитектура сервисов системы Windows).
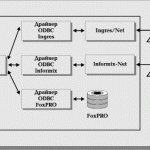
Интерфейс ODBC (Рис. 17) обеспечивает взаимную совместимость серверных и клиентских компонентов доступа к данным. Для реализации унифицированного доступа к различным СУБД было введено понятие драйвера ODBC (представляющего собой динамически загружаемую библиотеку).
ODBC-архитектура содержит четыре компонента:
- приложение;
- менеджер драйверов;
- драйверы;
- источники данных.
Роли среди них распределены следующим образом. Приложение вызывает функции ODBC для выполнения SQL-инструкций, получает и интерпретирует результаты; менеджер драйверов загружает ODBC-драйверы, когда этого требует приложение; ODBC-драйверы обрабатывают вызовы функций ODBC, передают операторы SQL СУБД и возвращают результат в приложение; источник данных (data source) — объект, скрывающий СУБД, детали сетевого интерфейса, расположение и полное имя базы данных и т.д.
Действия, выполняемые приложением, использующим интерфейс ODBC, сводятся к следующему. Для начала сеанса работы с базой данных приложение должно подключиться к источнику данных, ее скрывающему. Затем приложение обращается к базе данных, посылая SQL-инструкции, запрашивает результаты, отслеживает и реагирует на ошибки и т.д., то есть имеет место стандартная схема взаимодействия приложения и сервера БД, характерная для RDA-моде-ли. Важно, что стандарт ODBC включает функции управления транзакциями (начало, фиксация, откат транзакции). Завершив сеанс работы, приложение должно отключиться от источника данных.

