 Связаться с редакцией
Связаться с редакцией
СУБД Greenplum Database построена на основе архитектуры симметричных вычислений с массовым параллелизмом (Symmetric MPP) без разделения ресурсов, которая была разработана для бизнес-аналитики и аналитической обработки. Именно такая архитектура оптимальна для типичных операций аналитических БД, например, сортировки, агрегирования, объединения огромных таблиц, за счёт возможности параллельной обработки данных на всех узлах кластера БД и отсутствия «узких мест» (недостаточная пропускная способность сети передачи данных или кластерного интерконнекта, производительность СХД и т.д.).
Массово-параллельная архитектура без разделения ресурсов подразумевает физическое распределение данных таблиц на небольшие подмножества на отдельных серверах сегментов (рис. 1), каждый из которых имеет выделенный, независимый широкополосный канал подключения к локальным дискам.
Рис. 1. Архитектура MPP без разделения ресурсов системы Greenplum 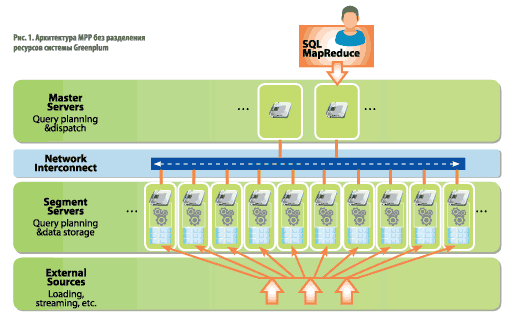
Серверы сегментов способны обрабатывать каждый запрос параллельно, одновременно использовать все подключения к дискам и эффективно распределять потоки данных между сегментами согласно плану запросов. Благодаря этому специализированные СУБД более производительны и масштабируемы, чем СУБД общего назначения, для задач бизнес-аналитики.
При работе с большими объёмами информации важно выполнить максимально возможное количество ресурсоёмких операций «максимально близко» к данным. В Greenplum мы рекомендуем организовать хранение на встроенных дисках серверов кластера (Direct Attached Storage, DAS). Тогда данные будут передаваться только по высокоскоростной внутренней шине узла и обрабатываться его процессорами в локальной оперативной памяти, без передачи по сетевой шине. Промежуточные результаты, объемы которых меньше исходных данных на порядок, также передаются по внутренней шине.
Не менее важное требование к аналитической системе – высокоскоростная, линейно-масштабируемая загрузка данных. Доступное на рынке сетевое оборудование обеспечивает ширину полосы пропускания от 1 до более чем 2,5 ГБ в секунду для каждого узла кластера. Greenplum за счёт отсутствия архитектурных «узких» мест позволяет линейно масштабировать скорость загрузки путем добавления узлов в кластер. Для каждой строки вставленных данных система вычисляет хэш значений столбцов, чтобы равномерно распределить строки между всеми своими сегментами (рис. 2).
Такой подход наряду с секционированием позволяет в большинстве случаев отказаться от индексов. Это положительно сказывается на скорости загрузки данных. В то же время Greenplum поддерживает и растровые индексы, и бинарные деревья для тех случаев, когда их применение необходимо.
Архитектура симметричных вычислений с массовым параллелизмом оптимальна для типичных операций аналитических БД, например, сортировки, агрегирования и объединения огромных таблиц
Технология Scatter/Gather Streaming (SG Streaming) позволяет линейно масштабировать скорость загрузки данных в СУБД Greenplum. За счёт того, что загрузка может выполняться всеми узлами кластера одновременно, наращивая количество узлов в кластере БД и источнике, можно добиться линейного роста скорости и соответствующего сокращения времени загрузки. На фазе «рассредоточения» (scatter) каждый узел загружает данные в кластер.
На фазе сбора данные перераспределяются между узлами в зависимости от значения хеш-функции ключа распределения.
Рис. 2. Параллельная загрузка данных 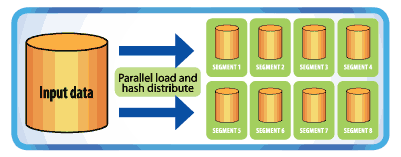
Greenplum обеспечивает возможность организации хранения данных таблицы как по записям, так и по столбцам. Причем способ хранения, благодаря технологии Polymorphic Data Storage, можно чередовать даже на уровне разделов (партиций).
Функционал СУБД Greenplum помогает компаниям эффективно решать актуальные бизнес-задачи, связанные с Big Data. Благодаря особенностям своей архитектуры, система может практически неограниченно расти вместе с данными, а также обрабатывать их с необходимой скоростью.
