 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

В этот день вышел номер журнала «Nature» с темой номера «Большие Данные. Наука петабайтной эры» («Science in the Petabyte era»). Метафора «Большие Данные» в соответствии с «Nature» представляет собой продолжение такого ряда понятий, как «Большая вода», «Большая руда», «Большая игра» и указывает не на размер (хотя это первое, что приходит в голову), а на появление нового качества у данных. Что это за качество, нагляднее всего можно продемонстрировать на примере другого определения термина «Большая вода» – половодье, наводнение. Таким образом, Big Data – это цифровое «наводнение» в наших ЦОД.
Когда с самим термином, как мне кажется, мы более-менее определились, становится понятно, что Big Data и связанные с ними проблемы затрагивают далеко не всех и не всегда.
Отсюда и такие полярные мнения по этому вопросу: «кто большой воды никогда не видел – тот и плавать никогда не учился». Тех же, кто уже столкнулся с необходимостью работы с Большими Данными или всерьёз собирается это сделать, волнуют вопросы о способах хранения и инструментах их обработки. Далее хочется сделать небольшое отступление об устройствах хранения и привести несколько графиков.
Обычно данные хранят на жёстких дисках/дисковых массивах. Большие Данные в этом вопросе не являются исключением просто по причине отсутствия альтернативы. Следующие два графика (см. рис. 1) демонстрируют два показателя примерно за один период: рост ёмкости единичного диска и снижение стоимости 1 Гб.
Рис. 1. По материалам: A History of Storage Cost by Matthew Komorowski «Kryder’s Law». Scientific American.The Performance Gap Dilemma. By BillM. Storageoptics 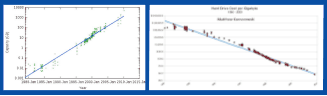
Конечно, возможны какие-то флуктуации цен, например, связанные с наводнением в Тайване в прошлом году, но в среднем всё достаточно ровно и линейно. Плотность записи на «пластину» в жёстком диске монотонно повышается, а стоимость падает. Производительность же одного диска (скорость чтения/записи) при этом, конечно, повышается, но ввиду технологических и физических ограничений достаточно медленно. Прорывом в этой области являются SSD-диски, но они сейчас существенно (в разы за 1 Гб) дороже традиционных решений. Эта тенденция сохранится ещё несколько лет.
В то же время есть другой ресурс, который также дешевеет, с одной стороны, и наращивает производительность – с другой. Речь о ресурсах центрального процессора (Central Processing Unit – CPU). На третьем графике (см. рис. 2) показаны рост производительности CPU в интервале 10 лет и в сравнении с ним рост производительности дисковых систем хранения данных за тот же период. Значительное расхождение этих кривых говорит о том, что рост производительности вычислительной составляющей сервера значительно опережает рост производительности его подсистемы ввода/вывода. Налицо performance gap.
Рис. 2. Рост производительности CPU в интервале 10 лет 
Этот факт не является открытием для отрасли, и давно существуют механизмы его использования в «мирных целях». Основных механизма два.
Количественный метод. Консолидировать значительное количество физических устройств хранения данных (дисков) под управлением мощного сервера. Этот подход является традиционным и до сих пор с успехом используется. Количество «шпинделей», на которых требуется разместить данные СУБД для необходимой производительности, до сих пор является обязательным параметром опросника (процедура Capacity Planning).
Качественный метод. Можно сделать наоборот – не консолидировать диски десятками до заполнения их суммарной производительностью performance gap, а воспользоваться вычислительной мощностью процессора для его ликвидации. Например, практически любой современный дисковый массив имеет свой процессор (часто не один) и, кроме традиционных «умений» вроде кэш-памяти, управляющих контроллеров, snapshot’ов и т.д., может предложить дедупликацию «на лету». Она повышает ёмкость массива за счёт исключения из хранения дублирующихся порций информации и thin-provisioning, позволяющего гибко наращивать физическую ёмкость системы хранения данных в отрыве от ёмкости логической.
Возвращаясь к теме Больших Данных и методам их хранения и обработки, хочу отметить, что это – развитие качественного метода с привнесением прикладной логики в систему хранения данных (когда устройство хранения знает, какие данные на нём содержатся, и может осуществлять поиск по шаблону).
Традиционная количественная концепция хранения и работы с данными представлена на рисунке 3. В фокусе находится прикладная задача. Все традиционные СУБД сейчас построены именно таким образом. Ниже приведены основные фазы работы с данными:
- Вспомогательные системы готовят данные из разных источников для загрузки в систему.
- Проводится загрузка данных.
- По этому набору данных выполняются действия прикладной задачи.
- Выдаётся результат.
- Результат может передаваться в другую задачу.
Такой метод построения хранилища и работы с данными как нельзя лучше подходит для традиционных реляционных СУБД. Зная заранее, какая задача будет работать с данными и каковы будут её типовые запросы, мы можем максимально точно подогнать под них схему размещения данных, индексы, партиции и т.п. для обеспечения оперативного получения ответа. Но когда возникают нетрадиционный запрос или нетипичные данные, не подходящие по формату (например, задача сохранить 1 млн фотографий и искать по образу), то здесь как раз и возникают трудности.
Наиболее частый случай – на порядок возрастает время получения ответа или стоимость решения.
Рис. 3. Концепции работы с данными 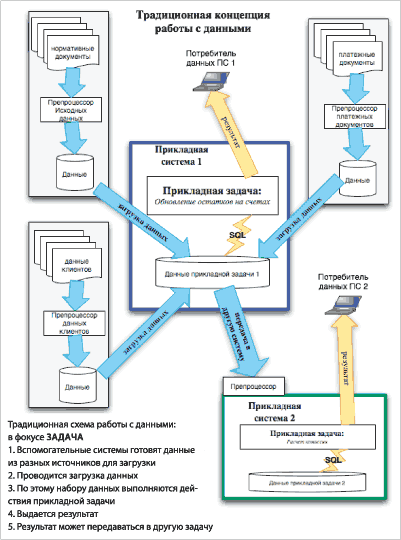
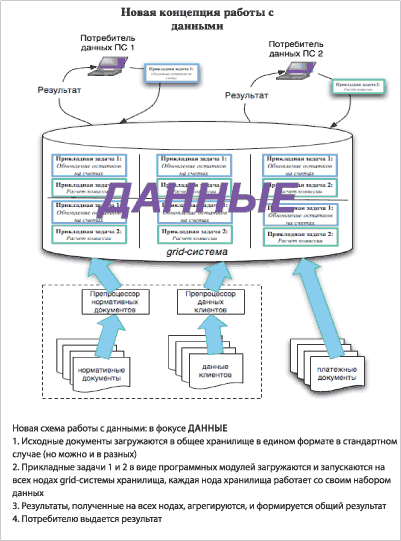
Теперь поговорим о том, как изменяется эта концепция, когда речь идёт о хранении и обработке Больших Данных.
В центре – данные и их хранилище. Хранилище представляет собой распределённую вычислительную систему (grid), где каждый узел (node или нода) наделён собственной, относительно небольшой ёмкостью для хранения, за которую он отвечает и умеет по запросу управляющего узла искать в ней данные.
Ниже приведены основные фазы работы:
- Исходные документы загружаются в общее хранилище с описанием в едином формате (но можно и в разных).
- Прикладные задачи 1 и 2 в виде программных модулей загружаются и запускаются на всех нодах grid-системы хранилища, каждая нода работает со своим набором данных.
- Результаты, полученные на всех нодах, агрегируются, и формируется общий результат.
- Результат выдаётся потребителю и может быть передан им в другую задачу.
Этот подход отличается от предыдущего тем, что на этапе планирования хранилища мы можем позволить себе точно не знать тех запросов и даже форматов данных, с которыми к нам потом придут потребители. Мы обеспечиваем платформу хранения и диспетчеризацию задач и ожидаем, что параллельно запускаемые на каждом узле нашей системы в виде программных модулей задачи сами могут выбрать из хранящихся на этом узле данных то, что им нужно. Сравнивать производительность первого и второго решения будет не совсем корректно, потому что они не конкурируют, а дополняют друг друга: второе решение начинается там, где заканчиваются возможности первого.
Я постарался вкратце рассказать об истории возникновения термина «Большие Данные» и подготовить почву для дальнейших, гораздо более технических и экспертных статей моих коллег.

