 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Когда же, казалось бы, техническая проблема ведения справочников попадает в фокус внимания бизнеса? Во-первых, при автоматизации сквозных бизнес-процессов, когда интегрируются несколько ИС. Например, работа с желающим взять кредит клиентом начинается в CRM, где формируется заявка, собираются данные о клиенте и желаемых условиях кредитования. Собранная информация передается в АБС для расчета условий кредита и графика платежей и в скоринговую систему для оценки кредитных рисков. Для иллюстрации рассмотрим передачу атрибута «пол». Справочники «Пол» в системах могут выглядеть по-разному (см. рис. 1).
Рис. 1. Справочники «Пол» в разных системах
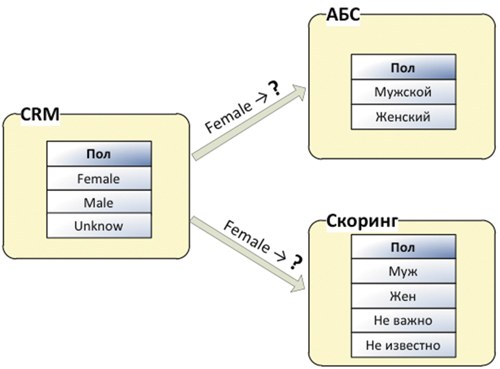
Очевидно, что значение атрибута «пол», полученное из CRM, не будет корректно обработано АБС и скоринговой системой. Для того чтобы разные приложения «понимали» друг друга, они должны либо говорить на одном языке – иметь одинаковые справочники, либо общаться через переводчика – где-то должны быть зафиксированы правила сопоставления справочников. Вторым случаем, привлекающим внимание бизнеса, является построение консолидированной отчетности.
Например, в единое хранилище загружаются данные по кредитным договорам из учетных систем филиалов компании. Требуется посмотреть гендерное распределение заключенных договоров и общей суммы выданных кредитов за период. Если справочники в учетных системах филиалов ведутся независимо, то с большой степенью вероятности мы получим ситуацию из предыдущего примера, когда женский пол – это и «Female», и «Женский», и «Жен», может быть и еще что-то неучтенное. И по какому значению делать выборку договоров? Мы получаем проблему при построении простейшего отчета. Таким образом, рассогласованность справочных данных в различных системах-источниках может привести к некорректным операциям агрегации и, следовательно, низкому качеству данных в отчетах.
И третья проблема – получение корректной информации на прошедшую дату. Довольно часто возникает необходимость предъявить контролирующим органам данные за прошлые периоды (3, 5 и более лет). Но справочные данные меняются, и старые записи ссылаются уже на новые справочные значения, информация становится некорректной. На компанию могут быть наложены штрафные санкции. Следовательно, помимо хранения исторических данных, нужно сохранять и все изменения справочной информации.
Каким образом обычно решаются перечисленные проблемы? К сожалению, очень часто для этого используются организационные методы. Например, в компании может быть выработан специальный регламент. В соответствии с ним в случае изменения записи в справочнике одной системы следует изменить соответствующие записи в аналогичных справочниках других систем. Понятно, что любая рассогласованность в действиях пользователей, отвечающих за ведение справочников, а также ошибки, связанные с человеческим фактором, приведут к некорректным обработкам интеграционных взаимодействий между ИС. И такой сценарий развития событий весьма вероятен.
Второй способ, достаточно популярный в последнее время, – использование для управления НСИ систем класса MDM (Master Data Management). Эти решения предназначены для получения качественных консолидированных основных данных компании. Чаще всего это информация о контрагентах (клиентах) или номенклатуре (товарах). Системы MDM обеспечивают полный цикл обработки основных данных: проверку, очистку и приведение к единому формату, выделение атрибутов из слабо структурированных текстовых данных, дедупликацию и исключение «мусорных» данных, обогащение информацией из внешних и внутренних систем. В результате решение создает «золотые записи», представляющие собой наиболее полные и корректные консолидированные справочные данные, используемые как эталонные.
Стоит отметить, что системы класса MDM могут осуществлять управление НСИ для информационного обмена, однако для решения только этой задачи они избыточны, дороги и недостаточно производительны.
Как управлять НСИ?
Итак, какие основные сложности встречаются на пути к полному взаимопониманию информационных систем и корректной консолидированной отчетности?
- Не все информационные системы умеют работать с загружаемыми извне справочниками.
- Не всегда требования к показателям качества бизнес-процессов компании позволяют вести НСИ централизованно, тратя время на ввод и согласование справочных данных в центральной системе управления НСИ.
- Не для всех справочников можно выделить единственную мастер-систему, которая отвечает за их ведение. Например, бухгалтерия чаще всего не доверяет данным о контрагентах, полученным из CRM, а сотрудники отдела продаж не могут ждать, пока запись о клиенте добавят в бухгалтерскую программу.
- Не всегда используемые справочники совпадают по структуре и количеству записей.
Например, справочник статусов кредитного договора плоский, а такой же справочник в CRM-системе имеет 3 уровня иерархии.
На сегодняшний день разработано много сценариев управления справочными данными, порой изощрённых. И очень трудно найти на рынке решение, позволяющее их реализовать. По нашему опыту, на практике все это многообразие в условиях российской действительности сводится к 2 основным сценариям. Их комбинация покрывает практически все информационные потоки, которые возникают при организации интеграционных процессов и построении хранилищ данных.
Первый сценарий – это репликация справочников. Если для ведения справочника можно выбрать единственную мастер-систему, а другие ИС умеют работать со справочниками, загружаемыми извне, правильнее всего использовать именно его. В чем он заключается? Каждый справочник ведется только в одной ИТ-системе (источнике). Новые и измененные записи справочника передаются в систему управления НСИ. Справочная информация предоставляется системам-потребителям (см. рис. 2).
Рис. 2. Репликация справочников
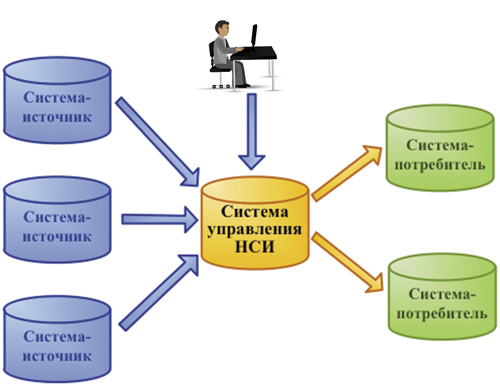
Процесс репликации может быть реализован как по online- схеме (справочные значения сразу передаются конечным системам), так и по варианту offline (периодическая передача данных каким-либо плановым заданием). Та или иная схема выбирается в каждом конкретном случае на основании специфики интеграционных процессов.
В результате во всех системах-потребителях одна и та же запись имеет одинаковый первичный ключ, который связан с ключом системы-источника. Это позволяет организовать информационный обмен между ИС и формировать корпоративную отчетность без дополнительных затрат на выверку и перекодировку данных. Этот сценарий является наиболее предпочтительным, но, к сожалению, его не всегда удается реализовать.
При невозможности использования системами общих справочников (неоднозначное соответствие записей между собой, разная степень детализации, особенности архитектуры ИС) интеграция данных выполняется путем взаимного сопоставления справочников систем-участников информационного обмена.
Традиционно такое сопоставление оказывается «размазанным» по всей ИТ-инфраструктуре: в ESB-адаптерах, ETL-процедурах, процедурах построения отчетов и т.п. При этом у бизнес-подразделений нет доступа к механизмам сопоставления справочников, поэтому корректировать процесс приходится ИТ-департаменту. Актуализация соответствия происходит с большим запозданием, т.к. изменения должны быть внесены во всех точках. К тому же часть информации может теряться из-за проблем с коммуникациями между подразделениями.
Второй актуальный для российской действительности сценарий – это централизованное управление сопоставлением справочников.
- Справочники ведутся независимо в ИТ-системах.
- Новые и измененные записи справочников передаются в систему управления НСИ.
- В системе управления НСИ настраиваются правила сопоставления записей.
- При наличии изменений в структуре исходных справочников оповещаются лица, ответственные за настройку правил сопоставления.
При информационном обмене справочные данные передаются в систему управления НСИ и преобразуются в соответствии с настроенными правилами в термины системы-приемника (см. рис. 3).
Рис. 3. Перекодирование справочных значений/идентификаторов при передаче данных
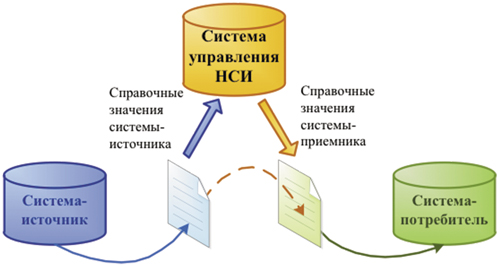
В результате сопоставление справочников ведется централизованно, изменения отслеживаются, все правила сопоставления настраиваются в одной системе. И, что немаловажно, доработка ИТ-систем не требуется.
Используя наш обширный проектный опыт, мы разработали решение, которое объединяет оба описанных выше сценария. Оно включает в себя созданную нашей компанией технологическую платформу и экспертизу по управлению НСИ. Решение позволяет быстро и эффективно организовать процесс управления справочными данными и обеспечивает:
- Поддержку сценариев централизованного ведения НСИ (репликация справочников). Ведение справочников возможно через интерфейс как системы управления НСИ, так и выбранной «мастер-системы».
- Сопоставление справочников (в случае, если невозможно их централизованное ведение). При этом бизнес-пользователи могут самостоятельно сопоставлять значение справочников из разных систем без привлечения технических специалистов. При появлении в информационном потоке данных, для которых не сопоставлены справочные значения, бизнес-пользователям, ответственным за выполнение соответствующей бизнес-операции, рассылается автоматическое уведомление.
- Поддержку версионности справочных данных – получение исторических данных на конкретную дату. Такая возможность исключает необходимость ведения версионности в учетных и операционных системах, которые для этого не предназначены.
Таким образом, комплексное решение объединяет весь набор базовой функциональности для эффективного управления НСИ. Оно позволяет избежать необходимости внедрения «тяжелых» технологических платформ для решения задачи интеграции.

