 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
О мониторинге по истории мониторинга
Вы не задумывались над тем, почему термин «мониторинг бизнес-приложений» появился в нашем обиходе совсем недавно? Разве 20 лет назад не существовало бизнес-приложений или мониторинга? Они были довольно распространены. Тогда в чем дело? Давайте вспомним: давным-давно на Земле бал правили... нет-нет, не динозавры, а Мейнфреймы. Подобная машина занимала площадь, аналогичную пространству современного ЦОД средних размеров, обеспечивала работу прикладного ПО и обслуживалась большим штатом высококвалифицированных специалистов. Специалисты имели в своем арсенале инструменты (как правило, встроенные в ОС), определяющие состояние «здоровья» такого суперкомпьютера. С их помощью фиксировались параметры загрузки процессоров, оперативной памяти, объем свободного места в системах хранения и т. д. – показатели, которые и сегодня не потеряли своей актуальности при оценке состояния работы систем. Можно сказать, что инструменты, применявшиеся в то время, являлись (опосредованно, конечно) и инструментами мониторинга бизнес-приложений.
Через несколько лет появились локальные сети, которые связали между собой отдельно стоящие компьютеры, и первым инструментом контроля состояния их работоспособности являлся анализатор протоколов. Его функционала было достаточно, т.к. первые сети не отличались надежностью и высокой скоростью работы. Как следствие, критерии работоспособности используемого в них ПО были тождественны критериям работоспособности самой сети, а именно: отсутствие ошибок на канальном уровне и достаточная полоса пропускания (другими словами, низкая утилизация канала связи). Именно тогда de facto выработались стандарты для мониторинга сетей, позже, с появлением сети на основе коммутаторов, появился еще один параметр – % широковещательных пакетов.
Вернемся к инструменту, который мог успешно контролировать перечисленные параметры, – анализатору протоколов. В то время, когда сети строились на основе толстого коаксиального кабеля, без использования коммутаторов и мостов, можно было подключить анализатор на любом участке сети и таким образом контролировать все важнейшие параметры. Анализатор протоколов собирал статистические данные о параметрах работы бизнес-приложений: если сеть функционировала удовлетворительно, т.е. указанные параметры находились в пределах своих пороговых значений, работа бизнес-ориентированного ПО не вызывала нареканий.
Положение дел постепенно менялось, информационные технологии развивались и усложнялись. В сетях всё активнее стали применять коммутацию, маршрутизацию, приоритезацию и прочие новшества. В серверном хозяйстве всё еще разнообразнее: появились виртуализация, кластеризация, запуск ПО с использованием терминальных служб, активнее используются SAN'ы. И, конечно, сами разработчики системного и бизнес-ПО не отстают от производителей оборудования – трёхзвенная архитектура бизнес-ПО уже является хорошим тоном.
О ситуации, как она есть
Таким образом, для сегодняшнего дня характерна ситуация, когда типичный пользователь бизнес-ориентированного ПО со своей рабочей станции запускает тонкого клиента на ферме терминальных серверов Citrix. Тонкий клиент обращается к кластеру web-серверов, оттуда поступает запрос к серверам бизнес-логики (приложений), те, в свою очередь, обращаются к БД, данные которой хранятся в сети SAN. При этом процесс осуществляется в географически распределенной инфраструктуре, компоненты которой могут размещаться в нескольких временных зонах. В итоге уже не существует единственного средства, которое бы контролировало элементы этой инфраструктуры и однозначно характеризовало работоспособность бизнес-ориентированного ПО с точки зрения конечного пользователя.
Более того, сейчас возникает вопрос, что же необходимо контролировать в инфраструктуре, обеспечивающей работу бизнес-ПО, и какими должны быть пороговые значения выбранных параметров? Пороговые значения, на которые мы могли ориентироваться лет 10 назад, de facto уже не актуальны, а новые нормы de iure пока не определены. Единственное, что может помочь нам в их определении, – это рекомендации самого производителя оборудования и системного ПО, которые обычно не отличаются конкретностью, поскольку не учитывают особенности инфраструктуры компаний.
Именно здесь нам на помощь и приходят решения, которые позволяют провести анализ качества работы пользователей с бизнес-ориентированным ПО с точки зрения самого конечного пользователя. Это совершенно самостоятельный класс ПО, который появился на рынке не так давно и еще не оценен по достоинству большинством заказчиков.
На наш взгляд, структура ИТ-отделов многих компаний такова, что в них исторически отсутствуют люди, отвечающие за конечную работу бизнес-ориентированного ПО. В ИТ-подразделении востребованы «сетевики», отвечающие за каналы связи, ее наличие между условными точками А и Б. К сожалению, большинство из них ориентируются на результаты команды ping, запущенной в ответ на получение жалобы от пользователя. Относительно низок процент тех специалистов, которые оперируют понятием «качество канала связи» и работают с параметрами Jitter, One-way Delay, Packet Loss. Большинство администраторов серверов следят не более чем за 5–7 параметрами: утилизацией процессоров, объемом свободной оперативной памяти, свободным местом на дисках, загрузкой сетевого интерфейса сервера и скоростью дисковых операций. Эти величины измеряются в %, их значения очень легко анализировать, при этом их количество оптимально, поскольку уследить за большим числом параметров уже проблематично. Аналогичная ситуация складывается и с администраторами БД, терминальных серверов, дисковых массивов и т. д. Но, как обычно, за все отвечает CIO. И, как правило, для оценки качества работы своего ИТ-подразделения он использует отчеты из системы класса Service Desk (SD).
Каким образом она позволяет оценить удовлетворенность конечного пользователя работой с бизнес-ориентированным ПО, и как применить эту информацию для улучшения качества предоставления сервиса и ИТ-инфраструктуры2? В лучшем случае мы можем оценить доступность работы бизнес-ПО с точки зрения предоставления сервиса. В ситуации, когда ПО «подводит», пользователю не остается ничего другого, кроме как инициировать инцидент в SD. Что же конкретно предпринимает пользователь, если он не доволен скоростью работы ПО, если оно периодически «подвисает», если обработка операций происходит слишком медленно, из-за чего, например, возникает очередь из посетителей (думаю, вам приходилось видеть недовольных клиентов банка, стоящих в очереди в кассу, и слышать слова кассира-операциониста о том, что программа «тормозит», и быстрее он работать не может)? Максимум, пользователь сообщит о накладках в конце рабочего дня: общими словами и в том случае, если его об этом спросят. Информации о том, в какой именно момент это случилось, с каким ПО и на совершении какой бизнес-операции, мы, скорее всего, не получим. Соответственно, ценность информации стремится к нулю. Нам же необходимо в режиме реального времени контролировать параметры работы ПО:
- Время отклика, или скорость выполнения бизнес-операции: измеряется в секундах и показывает, как быстро система отрабатывает пользовательские запросы. Очевидно, что чем быстрее они будут отрабатываться, тем лучше. Не существует четкого значения для указания порога этого параметра. Все зависит от того, насколько «тяжелую» операцию мы контролируем. Естественно, что на построение масштабного отчета за длительный период уйдет больше времени, чем, например, на поиск по индексированному полю «Фамилия» или «Расчетный счет».
- Доступность бизнес-ориентированного ПО с привязкой к конкретной бизнес-операции: измеряется в % и рассчитывается как отношение количества всех выполненных операций к успешным. Этот параметр показывает, насколько часто тестируемая операция была успешно выполнена. Чем выше его значение, тем лучше.
- Правильность возвращаемых данных. Это опциональный параметр, и часто его не используют, но упомянуть о его наличии необходимо. Пользователю важно, чтобы программа отрабатывала не только быстро, но и правильно. Хорошим примером здесь служит запрос несуществующей web-страницы. Обычно браузер быстро возвращает вам ответ сервера с сообщением о том, что страница отсутствует или не найдена, и с точки зрения самого браузера никакой ошибки в его работе нет. Чего не скажешь, если смотреть на ситуацию с точки зрения пользователя: его время потрачено зря. Параметр позволяет оценивать результат тестируемой операции и в случае получения данных, отличных от ожидаемых, реагировать на это.
Хочется особо отметить, что перечисленные метрики – особенно первая и вторая – часто являются SLA'ными, т.е. именно их любят прописывать в соглашении об уровне обслуживания.
О плюсах, минусах и равно
Существуют три вида решений, способных эффективно измерять эти параметры. Они классифицируются по типу методов получения данных:
- Решения, измеряющие доступность, скорость работы (время отклика) и правильность возвращаемых данных от бизнес-ориентированного ПО путем эмуляции действий пользователя – так называемые GUI-роботы (метод синтетических транзакций). Их принцип работы основан на однократной записи всех действий, производимых пользователем при работе с ПО: нажатий клавиш на клавиатуре, перемещений и нажатий кнопок мыши с запоминанием последовательности действий. Результатом, как правило, является скрипт, в котором все выполненные действия описаны с использованием внутреннего языка. Полученный первичный скрипт подвергается ручной модификации: в нем устанавливаются метки, которые сообщают о том, длительность каких именно операций необходимо измерять, добавляются команды, отслеживающие появление и исчезновение окон или графических элементов, вводятся операторы цикла и т. д. После этого скрипт запускается на выделенной рабочей станции с установленным бизнес-ориентированным ПО, и записанные в нем действия повторяются с заданной периодичностью. В итоге мы получаем значения перечисленных выше метрик на постоянной основе практически в режиме реального времени.
- Решения, анализирующие сетевой трафик и на его основе измеряющие скорость работы ПО с точки зрения конечного пользователя. Этот метод противоположен использованию GUI-роботов. В первом случае мы создаем виртуального пользователя и выполняем действия от его имени, здесь же все метрики формируются на основе реальной работы пользователей с контролируемым бизнес-ориентированным ПО. Весь сетевой трафик от пользователей до сервера ПО перенаправляется на специализированное программно-аппаратное устройство (аплайнс) с помощью зеркалирования порта коммутатора или разветвителя трафика. Устройство является продвинутым анализатором протоколов: оно способно анализировать не только стандартные протоколы (IP, TCP/UDP, HTTP, SMB, SQL и т. д.), но и знакомо с внутренними протоколами контролируемого приложения. Это позволяет на основе реального трафика определять, с какими подсистемами бизнес-ориентированного ПО сейчас работают пользователи, и как быстро и правильно выполняются их запросы.
- Агентские решения, которые измеряют набор метрик, характеризующих качество работы бизнес-приложений на стороне пользователя («глазами пользователя»), а именно:
- Время реакции бизнес-приложений, измеряемое на стороне пользователя (E2E RT – End-to-End Response Time): от момента, когда он, работая в бизнес-приложении, отправляет запрос на выполнение определенной функции, до момента, когда эта функция выполнена (например, поиск товара в справочнике).
- Количество выполненных пользователем транзакций с разделением их на успешно выполненные, принудительно завершенные в результате определенного события (например, ошибки, тайм-аута и т. д.), завершенные успешно, но выполненные с нарушением стандартной последовательности действий.
- Количество ошибок при выполнении транзакций с разделением на системные и пользовательские. Системные ошибки вызываются сбоями в работе ИТ-инфраструктуры или ошибками в коде самих приложений. Пользовательские – результат неправильных действий пользователей.
Это достаточно новый метод, который еще практически не знаком российским компаниям. Он соединяет в себе лучшие качества вышеперечисленных решений и добавляет новую функциональность, а именно – возможность определять «время пользователя» (think time), т. е. то время, которое потратил непосредственно сам пользователь при выполнении бизнес-транзакции в контролируемом ПО (например, на ввод данных о клиенте, подсчет денег и т. д.).
+-Доступность и простота реализации. Все, что вам нужно для реализации такого подхода, – соответствующий софт и немного времени для его настройки. Существуют как коммерческие, так и свободные решения.
Поддержка любого ПО.
Используя этот метод, вы можете контролировать любое пользовательское бизнес-ПО.
Это могут быть самописные приложения, коммерческий софт, тонкий клиент (ПО на базе web-клиента), «толстое» или консольное приложение – все что угодно.
И это является самым большим достоинством этого метода.Вы всегда имеете в своем распоряжении данные вне зависимости от того, работают ли сейчас пользователи в контролируемом ПО, или нет.
Это очень простой вариант для контроля поддерживаемых приложений. Не нужно ничего прописывать, настраивать (не считая зеркалирования трафика), вы сразу получаете нужные вам метрики в режиме реального времени
на основе реального трафика.Контроль ПО только на уровне GUI. Вы можете измерить время только тех операций, которые имеют графический интерфейс. Как правило, это не проблема для пользовательских приложений, но контролировать ПО b2b вы уже не сможете.
Высокие затраты на поддержание робота. Поскольку скрипт содержит описание действий пользователя, в том числе нажатий на экранные кнопки, при изменении графической формы он перестает быть актуальным, соответственно, перестает работать. Вам придется модифицировать его, и так каждый раз при изменении экранных форм контролируемого приложения.
Нет гарантий, что у каждого пользователя всё так же хорошо, как и у робота. При использовании этого метода не учитывается влияние самой рабочей станции пользователя и ее настроек. Это означает, что несколько пользователей могут испытывать проблемы с работой ПО, и робот не всегда их определит. Другой проблемой является то, что необходимо расставлять выделенные рабочие станции с роботами во всех местах работы пользователей. Если у вас множество территориально распределенных офисов, это может стать проблемой.
Вы контролируете только то, что контролируете. В реальности нет возможности контролировать все бизнес-операции, которые могут выполняться пользователями. Вы пишете GUI-робота только для контроля нескольких наиболее типичных, распространённых и самых важных операций. Остальное остается для вас тайной – это одно из упущений метода.
Очень ограниченный круг поддерживаемых бизнес-приложений.
К сожалению, в списке поддерживаемых приложений у такого устройства вы не встретите ни одного российского бизнес-ПО.
Это значит, что вы ограничены, и часть вашего ПО останется без контроля при использовании данного метода.У вас есть данные только во время работы пользователей. Как только пользователи прекращают свою работу, прекращаются и измерения. Графики метрик будут иметь прерывистый вид, и это может негативно влиять на определенные функции системы мониторинга.
Интерпретировать результаты сложнее. При использовании синтетических транзакций вы всегда выполняете один и тот же набор действий, как правило, над одними и теми же документами идентичного объема. Т. е. ваша тестовая операция остается постоянной. Изменение времени ее выполнения, скорее всего, произойдет из-за изменений в эксплуатационном режиме самой ИТ-инфраструктуры, поддерживающей работу ПО. Здесь же нет одинаковых транзакций, это реальная работа пользователя, и в один момент будет измерена реакция бизнес-ПО на обработку документа, содержащего одну позицию, а в другой – 40 позиций. Очевидно, что время обработки будет различным.
Для измерения интересующих нас метрик используется агент, устанавливаемый на компьютерах пользователей. Чтобы агент мог распознавать выполняемые транзакции, их ключевые признаки и атрибуты предварительно определяются в соответствующем шаблоне (тип, бизнес-приложение, бизнес-процесс и др.). Поэтому на компьютерах пользователей должны быть установлены не только агенты, но и шаблоны, соответствующие критически важным транзакциям используемых бизнес-приложений.
Принцип работы агента заключается в автоматическом отслеживании всех выполняемых на компьютере процессов и связанных с ними событий. Если осуществляющийся процесс не описан в шаблоне, соответствующие ему события игнорируются. Если описание процесса присутствует в шаблоне, все связанные с ним события автоматически регистрируются и хронометрируются.
Равно
Каких же результатов позволяют добиться эти решения?
- Увеличить общую производительность ИТ-службыза счет автоматизации процесса диагностики сбоев в работе бизнес-приложений. Диагностика может выполняться автоматически, при этом уменьшается MTTR (Mean Time To Repair).
- Повысить лояльность пользователей бизнес-приложенийпутем улучшения качества их работы и упрощения процедуры регистрации инцидентов. Сбои в работе ИТ-инфраструктуры и бизнес-приложений могут регистрироваться автоматически и устраняться до обращения пользователей в Service Desk. Увеличивается MTBF (Mean Time Between Failures).
- Сократить затраты ИТ-службыза счет:
- автоматического контроля соблюдения SLA поставщиками ИТ-услуг;
- автоматической квалификации инцидентов. ИТ-служба оперативно получает информацию о том, что, где и когда произошло, что позволяет автоматически квалифицировать инциденты и уменьшить нагрузку на первую линию поддержки.
О жизни после внедрения
Ну, хорошо, скажет читатель, предположим, что мы внедрили у себя вашего «робота». Настроили его на контроль нашего приложения и стали получать информацию о скорости работы пользователей с ним. Действительно, заметно, что в некоторые моменты приложение «тормозит». И теперь – внимание, вопрос – что делать дальше? Как понять, чем вызвана эта просадка по производительности?
Действительно, инструментарий, о котором говорилось выше, позволяет увидеть только то, как работает приложение, но не отвечает на вопрос, с чем это связано. Интеграция и совместная обработка данных о работе инфраструктурных элементов и бизнес-приложений является одной из наиболее интересных и важных задач. Ее решение позволяет определить, что нужно сделать, чтобы избавиться от провалов в скорости работы бизнес-приложения. Для этого необходимо предпринять определенные шаги:
Во-первых, импортировать в единую базу данных информацию, характеризующую работу всех элементов ИТ-инфраструктуры, и данные от робота. Здесь очень важна возможность решения получать информацию из как можно большего числа существующих средств мониторинга. Т. е. наличие готовых коннекторов является важной составляющей системы мониторинга бизнес-приложений. Также должна быть возможность импорта информации из популярных форматов хранения данных – Excel, XML БД и т. д. Отметим, что, в отличие от большинства зонтичных систем, которые ориентированы на сбор событийной информации от инфраструктурных элементов (SNMP Trap, сообщения Syslog, различные события из журналов ОС и системных сервисов) и систем мониторинга класса EMS (Element Management System), системы мониторинга бизнес-приложений в большей степени ориентированы на работу с трендами, т. е. с «сырыми» метриками, характеризующими работу инфраструктуры.
Во-вторых, нужно статистически обработать эту информацию. Обработка получаемых метрик в системах подобного класса является одной из ключевых «фишек». Давайте рассмотрим типичную работу традиционной системы мониторинга класса EMS: администратор настраивает эту систему на сбор параметров, которые уже «зашиты» в ней производителем, или применяет так называемые модули знаний, уже содержащие список метрик, которые необходимо контролировать. После этого для нескольких метрик настраиваются статические пороговые значения, при достижении которых система генерирует событие. Такое событие отображается на дисплее, к нему может быть привязано оповещение, например, отправка почтового сообщения на адрес администратора. Таким образом, система периодически получает значение контролируемых метрик, сравнивает их с пороговым значением и в случае чего генерирует информационное событие. Но подобная схема, к сожалению, имеет ряд недостатков. Мы видим две проблемы:
Вы должны сами указать системе значение порога. Это значит, что вы берете всю ответственность за это значение на себя, и система не помогает вам с его определением. Если указано слишком низкое значение, вы будете получать очень много ложных сообщений о проблемах в системе, и через некоторое время просто перестанете на них реагировать. И как раз в этот момент можно не заметить реальную проблему. Ситуация напоминает басню о мальчике, который часто кричал «Волки, волки!».
Вспомните, на каком количестве метрик у вас настроены пороговые значения. Наверняка, их число не превышает 10–15. И большинство из них измеряются в %. Скорее всего, это утилизация процессоров и сетевого интерфейса, количество свободной оперативной памяти и места на жестких дисках, число ошибок на сетевых интерфейсах и т. д. Перечисленные параметры легко интерпретировать: мало ошибок – хорошо, низкая утилизация – плохо. Но любая система характеризуется массой метрик. Достаточно открыть ПО «Системный монитор» в Windows 7 и убедиться, что их число измеряется сотнями. Перефразируя В. Маяковского: если есть такое количество счётчиков, значит, это кому-нибудь нужно. Другими словами, вы берете на себя ответственность за то, какие именно счетчики контролируются. Если вы не смогли спрогнозировать аварию из-за того, что система мониторинга не отреагировала на изменение параметра, который она не контролирует, – виноваты только вы.
Рис. 1. Пример количества счетчиков из встроенного в Windows 7ПО «Системный монитор» 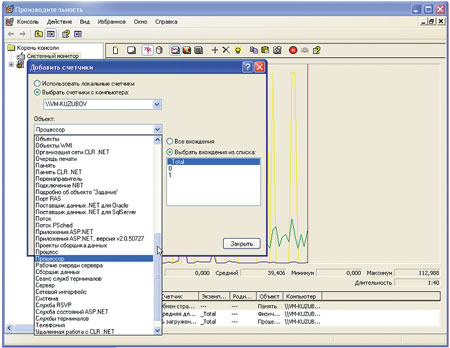
К счастью, когда узкие места обозначены, проблему вполне можно решить. Мы предлагаем следующий подход. Для начала нужно собрать все метрики по элементам ИТ-инфраструктуры. Сейчас это не представляет особой сложности, достаточно иметь мощный сервер и большую дисковую емкость – и значения всех возможных метрик за последние две недели в вашем распоряжении. Далее с помощью GUI-робота вы получаете значения метрик, характеризующих работу бизнес-приложения.
Необходимо импортировать все собранные данные в единую БД с привязкой к единой временной шкале и провести парный корреляционный анализ зависимости времени отклика приложения от каждой метрики. Если метрики, полученные от GUI-робота, условно назвать «функцией», а характеристики работы сети, серверов, БД и др. – «аргументами», то с помощью системы можно получить точные количественные оценки того, в какой степени та или иная функция зависит от одного или нескольких аргументов. Например, как время отклика бизнес-транзакции при оформлении проводки в Интернет-банкинге зависит от степени утилизации сети или сервера, числа ошибок при передаче данных и т. п. На выходе мы получим топ-10 метрик, наиболее влияющих на скорость работы бизнес-приложения, а, значит, и на удовлетворенность конечного пользователя.
Последний шаг – это определение статических пороговых значений для наиболее значимых метрик с помощью регрессионного анализа зависимостей между метриками элементов ИТ-инфраструктуры и времени отклика бизнес-приложения. Пороговое значение времени отклика мы берем из SLA и по описанной выше схеме находим соответствующие значения метрик, которые в наибольшей степени на него влияют.
Рис. 2.Процесс анализа бизнесПО 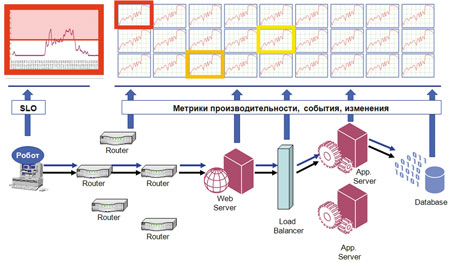
Никто не отменял пословицу «лучше один раз увидеть, чем 100 раз услышать» (или прочитать). Поэтому все, кто заинтересовался нашим подходом к мониторингу бизнес-приложений или давно присматривается к этим решениям и хочет воплотить их в жизнь в своей компании, – милости просим. Презентация, живая демонстрация, референсный визит и, наконец, пилотный проект у вас в компании – вот то немногое, что мы можем предложить.
Комплексная система мониторинга бизнес-приложений должна:
- Обладать возможностью измерять в режиме, близком к real time, метрики, характеризующие качество работы бизнес-приложений с точки зрения конечного пользователя (скорость, доступность, правильность возвращаемых данных).
- Иметь возможность самостоятельно измерять метрики, характеризующие работу элементов ИТ-инфраструктуры (серверы, активное сетевое оборудование, дисковые массивы, SAN и т. д.), либо импортировать значения метрик из различных систем, эксплуатируемых у заказчика.
- Обладать развитым математическим аппаратом для эффективного выявления влияющих метрик и определения их пороговых значений.
- Включать в себя механизмы предсказания сбоев, определения первопричины возникшей проблемы и отслеживания аномального поведения отдельных элементов.
И, конечно, ни один успешный проект не обойдется без ITSM-поддержки в виде разработанного набора регламентов, позволяющих поддерживать систему в актуальном состоянии, контролировать адекватность ее работы и предотвращающих ее внезапную «смерть».



