 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Современная архитектура непрерывности — это не про систему, которая «никогда не падает». Это про систему, которая продолжает работать, когда ее отдельные части выходят из строя. Для современных ИТ такая способность важнее формальной надежности, потому что изменения, отказы и атаки стали обычным режимом работы. На схеме это сразу видно: параллельно работают три автономных ЦОД. Нет основного и резервного, нет центра, от которого зависит все. Каждая площадка — самостоятельная зона доступности, и отказ одной из них не должен приводить к остановке бизнеса и информационных систем.
Слои доступа и внешнего трафика
(ISP Transport, Anti-DDoS, BAS, Autopentest)
Верхний слой схемы отражает работу каналов данных и внешних сервисов. Здесь показан доступ через провайдеров связи и представлены средства защиты от внешних воздействий. Этот слой выделен, чтобы разграничить внешние слои и внутреннюю архитектуру.
Рядом с Anti-DDoS находятся системы автоматического тестирования и симуляции атак — BAS и Autopentest. Внешняя среда рассматривается как нестабильная по умолчанию. Архитектура не опирается на оптимистичные допущения о характере трафика и не ограничивается установкой защитных механизмов «на всякий случай».
Anti-DDoS здесь — базовая гигиена. Он отсекает грубый шум, но сам по себе не делает систему устойчивой. Устойчивость обеспечивается тем, что намеренно и регулярно воспроизводятся синтетические негативные сценарии. Атаки и аномальные ситуации моделируются до того, как трафик попадает во внутренние слои, и система учится жить в этих условиях. Внешний стресс перестает быть неожиданностью и становится частью штатной эксплуатации.

Внутренняя сеть ЦОД
(Spine-Leaf, Switching, балансировщики)
Ниже по схеме расположен сетевой слой каждого ЦОД. Он построен автономно и не предполагает растянутых L2-доменов между площадками. Это не частный пример технического выбора, а одно из ключевых архитектурных решений. Растянутая сеть создает между площадками жесткие зависимости, которые в штатном режиме могут не проявляться. Пока система работает стабильно, такая схема выглядит оптимальной: меньше маршрутизации, проще миграции, меньше логики на уровне приложений. Однако при сетевом сбое или деградации локальная проблема быстро выходит за пределы одной площадки и начинает влиять на работу всей системы.
В современной инфраструктуре такое размещение намеренно исключается. Каждый ЦОД имеет собственную сетевую топологию и собственные домены отказа. Это снижает вероятность каскадных отказов и делает поведение системы при деградации более предсказуемым.
Балансировщик нагрузки в этой части схемы выполняет роль управляемой точки балансировки трафика между сервисами. Он позволяет централизованно управлять маршрутизацией запросов и проверкой «здоровья» конечного сервиса и его компонентов.
Сетевой и прикладной контуры безопасности
(Firewall, WAF, API Security, NAC, микросегментация)
Следующий слой схемы — сетевой и прикладной контуры безопасности. Межсетевые экраны, защита веб-приложений, API и механизмы микросегментации развернуты в каждом ЦОД автономно и не образуют единого растянутого контура.
Безопасность здесь не рассматривается как способ полностью исключить инциденты. Архитектура предусматривает возможность сбоев, ошибок конфигурации и компрометаций. Поэтому задача этого слоя — ограничить масштаб последствий.
Микросегментация и контроль доступа формируют внутри инфраструктуры набор изолированных зон. Если проблема возникает в одном сегменте, она не должна автоматически распространяться дальше. Такой подход позволяет переживать инциденты без остановки всей системы и без экстренного вмешательства на уровне инфраструктуры. Важно, что все элементы данного слоя существуют автономно в каждом ЦОД. Это исключает ситуацию, когда сбой или перегрузка одного защитного компонента начинают влиять на работу всех площадок сразу.
Слой приложений и сервисного взаимодействия
(Applications, Service Mesh, Service Bus)
В центре схемы изображены приложения и компоненты их взаимодействия. Именно на этом уровне можно увидеть ключевое изменение в сравнении с классическими архитектурами.
Service Mesh отвечает за управляемое сетевое взаимодействие микросервисов: маршрутизацию, балансировку, контроль доступа и наблюдаемость. Service Bus используется для асинхронной интеграции и обмена событиями между системами. Оба компонента снижают связанность приложений и позволяют им взаимодействовать без жестких прямых зависимостей.
Принципиально важно, что приложения в этой архитектуре не воспринимают инфраструктуру как внешний механизм отказоустойчивости. Они проектируются с учетом того, что могут быть недоступны отдельные сервисы, происходить задержки и асинхронно приходить ответы. ИТ-инфраструктура в этом случае предоставляет правила и инструменты взаимодействия, но не пытается компенсировать архитектурные ограничения приложений за счет растянутых кластеров или сложных схем репликации. Такой подход требует большего внимания на этапе разработки приложений, но в результате система становится устойчивее. Частичный отказ перестает быть аварией, поскольку система остается управляемой.
Контейнерная платформа
(Kubernetes)
Под слоем приложений расположен Kubernetes — платформа, которая управляет жизненным циклом сервисов. Именно на этом уровне антихрупкость начинает проявляться не на уровне схем и документов, а в ежедневной эксплуатации. В работе Kubernetes изначально учитывается возможный выход из строя отдельных компонентов. Контейнер может быть остановлен, узел — стать недоступным, конфигурация — измениться. Это не аварийные сценарии, а штатные события. Благодаря декларативному подходу, согласно которому каждый компонент инфраструктуры описывается в виде манифеста его конфигурации, платформа следит за тем, чтобы фактическое состояние системы соответствовало описанному, и при необходимости автоматически приводит его в порядок.
В такой архитектуре компонент не рассматривается как ценность сам по себе. Если сервис (контейнер) перестал отвечать или начал вести себя нестабильно, он не анализируется и не «лечится» вручную. Он удаляется и создается заново в соответствии с заданной конфигурацией. Такой подход радикально снижает операционные риски и убирает зависимость от ручных действий в критических ситуациях. Система становится устойчивой не потому, что в ней нет отказов, а потому, что она умеет быстро и предсказуемо пересоздаваться.
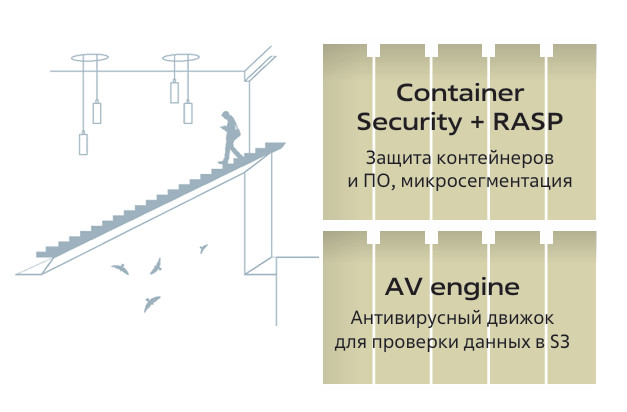
Защита контейнеров и данных
(Container Security, RASP, AV engine для S3)
Рядом с контейнерной платформой на схеме показаны средства защиты контейнеров и проверки данных. Это важное изменение в подходе к безопасности: защита больше не сосредоточена только на периметре.
Container Security и RASP работают непосредственно в среде выполнения приложений. Они позволяют контролировать, что именно делает сервис во время работы, и реагировать на его аномальное поведение. Это особенно важно в микросервисных архитектурах, где классические средства периметральной защиты уже не дают полной картины происходящего.
Антивирусный движок для проверки данных в S3-хранилищах решает отдельную, критичную задачу. Объектные хранилища часто используются как точка интеграции между системами, и данные могут попадать туда из разных источников (информационных систем). Проверка на входе и выходе позволяет снизить риск распространения вредоносного контента внутри ИТ-инфраструктуры.
Слой данных
(SQL DB, NoSQL DB, Data Lake, S3/SDS, Database Firewall)
Слой данных — один из самых сложных и чувствительных в современной архитектуре. Именно здесь чаще всего возникает желание сделать всё устаревшими, но зарекомендовавшими себя способами с помощью инфраструктуры. На практике такой подход быстро приводит к снижению непрерывности.
При таком устаревшем подходе СУБД или другие данные растягиваются (реплицируются) различными средствами между несколькими ЦОД, что неизбежно приводит к потере их автономности и фактическому объединению ЦОД в одну зону доступности. Кроме того, наличие одной «основной» СУБД плохо сочетается с микросервисной архитектурой. В таких схемах переключение между экземплярами СУБД часто требует ручных операций (изменения конфигураций, переподключения приложений или их перезапуска), что приводит к простою сервисов.
Современный подход подразумевает, что разные данные имеют разную бизнес-ценность и разные требования к их доступности и согласованности. Для одних операций допустима задержка или асинхронная репликация данных, для других — нет. Попытка обеспечить одинаковые гарантии для разных данных приводит к появлению тяжелых и плохо управляемых решений, а также к значительному увеличению стоимости ИТ-инфраструктуры. Поэтому часть ответственности за согласованность данных сознательно переносится в логику приложений и промежуточных слоев. Это усложняет разработку, но делает архитектуру в целом более гибкой и масштабируемой. Инфраструктура «перестает притворяться», что может всеобъемлюще обеспечить консистентность данных бизнес-приложений, находящихся в разных ЦОД.
Database Firewall в этой схеме выполняет роль дополнительного защитного слоя. Он ограничивает доступ к данным, позволяет контролировать аномальные запросы и снижает риск неконтролируемых изменений, особенно в сложных интеграционных сценариях.
Инфраструктурный фундамент
(Виртуализация, SAN, VM Sec)
Ниже на схеме расположен инфраструктурный слой, включающий виртуализацию, системы хранения данных и средства защиты виртуальной среды. Эти технологии остаются важной частью архитектуры, но их роль принципиально меняется в сравнении с классическими подходами.
В такой модели ИТ-инфраструктура непрерывности перестает быть основным механизмом, обеспечивающим отказоустойчивость на уровне всей системы. От нее больше не ожидают, что она свяжет сервисы между площадками или обеспечит непрерывность работы за счет растянутых кластеров системы виртуализации и синхронной репликации на уровне СХД. Теперь инфраструктура отвечает за стабильную и предсказуемую работу ресурсов внутри одного ЦОД. Все компоненты этого слоя работают строго в пределах своей площадки и не образуют растянутых доменов между разными ЦОД. Такое ограничение намеренно снижает архитектурную сложность. Процессы виртуализации и работа систем хранения в аварийных сценариях становятся более понятными и управляемыми, а локальный сбой не перерастает в проблему сразу для нескольких площадок.
Благодаря этому можно обеспечить отказоустойчивость системы в целом, используя автономные зоны доступности, платформенные механизмы и логику приложений. Инфраструктура при этом остается надежным фундаментом, но перестает быть точкой концентрации рисков.
Резервное копирование как последний рубеж
(Автономная СРК, резервные копии между ЦОД)
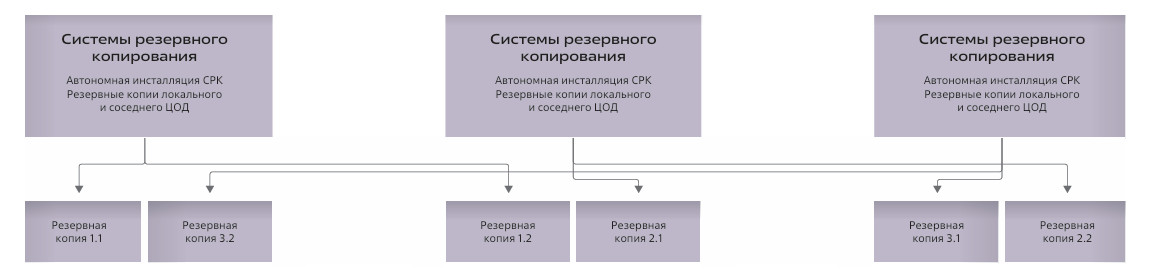
Самый нижний слой схемы включает системы резервного копирования и восстановления данных. Он предназначен для восстановления системы в ситуациях, когда не сработали остальные механизмы: при воздействии логических ошибок, влиянии разрушительных ИБ-инцидентов, эффекте человеческого фактора. Именно поэтому системы резервного копирования развернуты автономно, а копии данных распределены между площадками.
Здесь разрушается иллюзия «абсолютной защиты», поскольку могут произойти события, после которых потребуются откат и восстановление. Наличие независимого, изолированного контура резервного копирования делает такое восстановление реальным, а не формальным, а соответствие правилу 3-2-1 с отчуждаемыми копиями данных в соседнем ЦОД повышает шансы на восстановление.
Почему система продолжает работать при отказах
Современная инфраструктура работает потому, что честно учитывает реальные условия эксплуатации современных приложений. Отказы отдельных компонентов, изменения конфигураций и обновления происходят постоянно, и архитектура рассчитана именно на это.
Ключевое решение — автономные зоны доступности без единого центра. В схеме используется конфигурация из трех ЦОД. Это практический инженерный компромисс. Система сохраняет работоспособность при отказе одной площадки и позволяет выполнять плановые работы. В схеме три независимых ЦОД, но количество зон доступности может быть и больше трех.
Второй важный принцип — наблюдаемость. В первую очередь важно видеть, что приложение корректно отвечает и выполняет свою бизнес-функцию, а не просто формально «работает». Мониторинг нижележащей инфраструктуры и сети в этом случае является вспомогательным инструментом, позволяющим быстрее диагностировать причины проблем, но не подменяет контроль за состоянием самого сервиса.
Отдельно стоит отметить адаптивность как ключевое свойство такой архитектуры. Сбой рассматривается не как катастрофа, а как источник информации. Команда сопровождения должна не только устранять аварии и писать post-mortem, но и проактивно учиться на этих инцидентах. Это предполагает внедрение в повседневную работу современных практик, таких как Chaos Engineering и SRE. Авария системы становится поводом для улучшения как технических решений, так и процессов эксплуатации.
Третий важный принцип — пересоздание вместо восстановления. Контейнерная оркестрация и подход Infrastructure-as-Code делают описание системы более важным в сравнении с конкретными экземплярами ресурсов. Потеря отдельного компонента перестает быть инцидентом, требующим ручного вмешательства, и обрабатывается автоматически в рамках заданной модели.
Немаловажным фактором является и киберустойчивость. Цель современных атак — не нарушение конфиденциальности, а остановка бизнеса путем удаления или шифрования данных. Поэтому для обеспечения киберустойчивости реализуются сразу две взаимодополняющие концепции. Первая — внедрение средств информационной безопасности на всех этапах жизненного цикла приложения (от разработки до эксплуатации в продуктивном ландшафте). Вторая — использование автономных, не связанных между собой систем резервного копирования в каждом ЦОД и дополнительная передача резервных копий данных в другую зону доступности в режиме «только чтение» (WORM).
Такой подход позволяет максимально защитить приложения и обеспечить оперативное и гарантированное восстановление сервисов в случае катастрофических сценариев.
Современная ИТ-инфраструктура непрерывности не обещает отсутствия аварий. При их наступлении она обеспечивает непрерывность бизнес-процессов. И поэтому такая архитектура постепенно становится базовой моделью для современных ИТ-систем.
