 Связаться с редакцией
Связаться с редакцией
/ Системы усложняются — мониторинг не справляется
/ Три столпа наблюдаемости: метрики, логи, трейсы
/ Без мониторинга невозможно вовремя узнать о существовании проблемы, а без наблюдаемости — понять, как ее решить
Чем крупнее бизнес, тем сложнее его ИТ-инфраструктура и серьезнее последствия инцидентов. В какой-то момент становится понятно: традиционный мониторинг работы систем не позволяет предотвращать нежелательные события. Требуется внедрять практику наблюдаемости: это кардинально повышает прозрачность процессов, что позволяет с легкостью находить и устранять ключевые проблемы. В каких случаях стоит использовать такой подход и как сделать это правильно, оправдав необходимые затраты? Ответы — в нашей статье.
Инструменты не успевают за объемами?
Мировой объем генерируемых данных уже давно растет двузначными темпами, что стимулирует активное расширение ИТ-инфраструктуры. К тому же новая информация все чаще создается за счет использования распределенных сред, а их контроль требует иных методов в сравнении с традиционными монолитными приложениями.
«Привычные инструменты уже не в состоянии обрабатывать такой объем данных и не предоставляют достаточной информации о состоянии приложений, позволяющей быстро понять, как исправлять возникающие проблемы. Как правило, традиционный мониторинг может оперативно зафиксировать нарушение, но сегодня этого уже недостаточно. Важно не только обнаружить поломку, но и предупредить ее возникновение, а также скорректировать системы, чтобы ситуация не повторилась».
Алексей Акопян,
руководитель отдела систем мониторинга компании «Инфосистемы Джет»
Такая проактивность обеспечивается благодаря подходу, который получил название «наблюдаемость» (англ. — observability).
Здесь могут возникнуть вопросы:
- Где проходит граница между мониторингом и observability?
- В каких случаях нужна наблюдаемость, а когда достаточно мониторинга?
Последовательно разберемся с каждым из этих двух подходов.
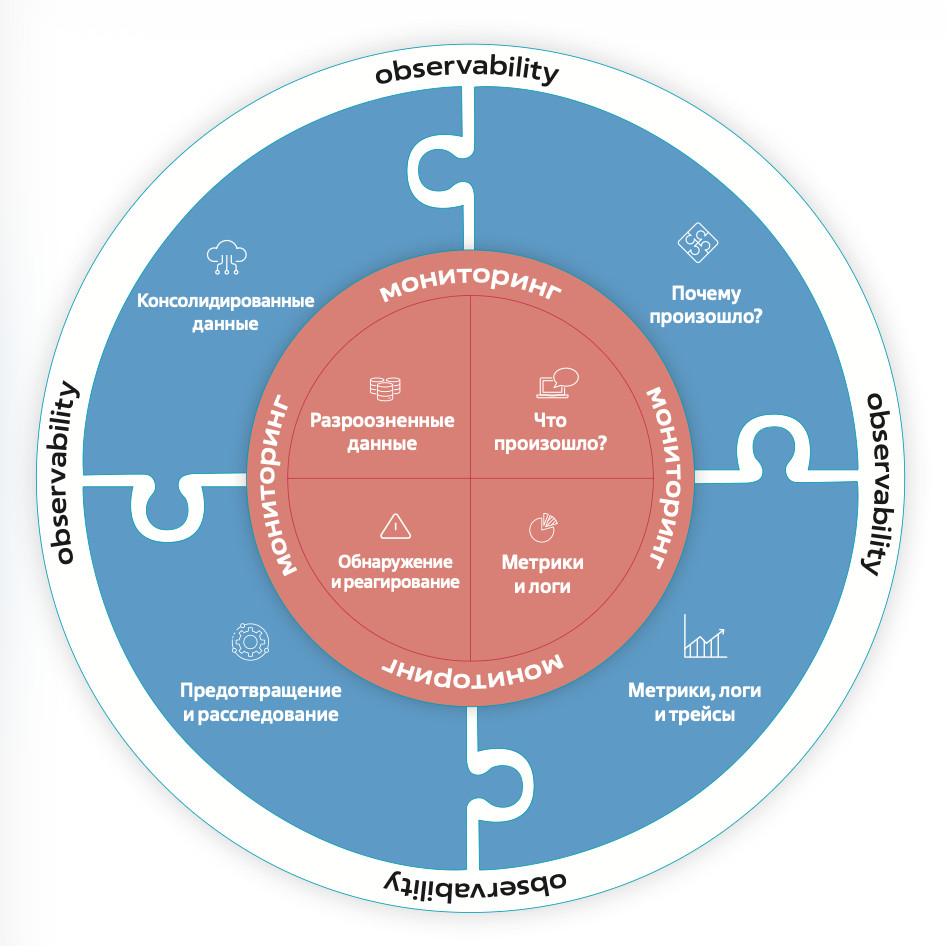
Мониторинг оперирует неким набором критериев, которые заведомо известны, и именно поэтому их можно отслеживать, а еще решает целый ряд задач:
- обнаруживает отказы и деградации;
- контролирует состояние сервисов и инфраструктуры в реальном времени;
- сигнализирует о проблеме;
- сокращает время до обнаружения инцидента.
Норма инцидентов
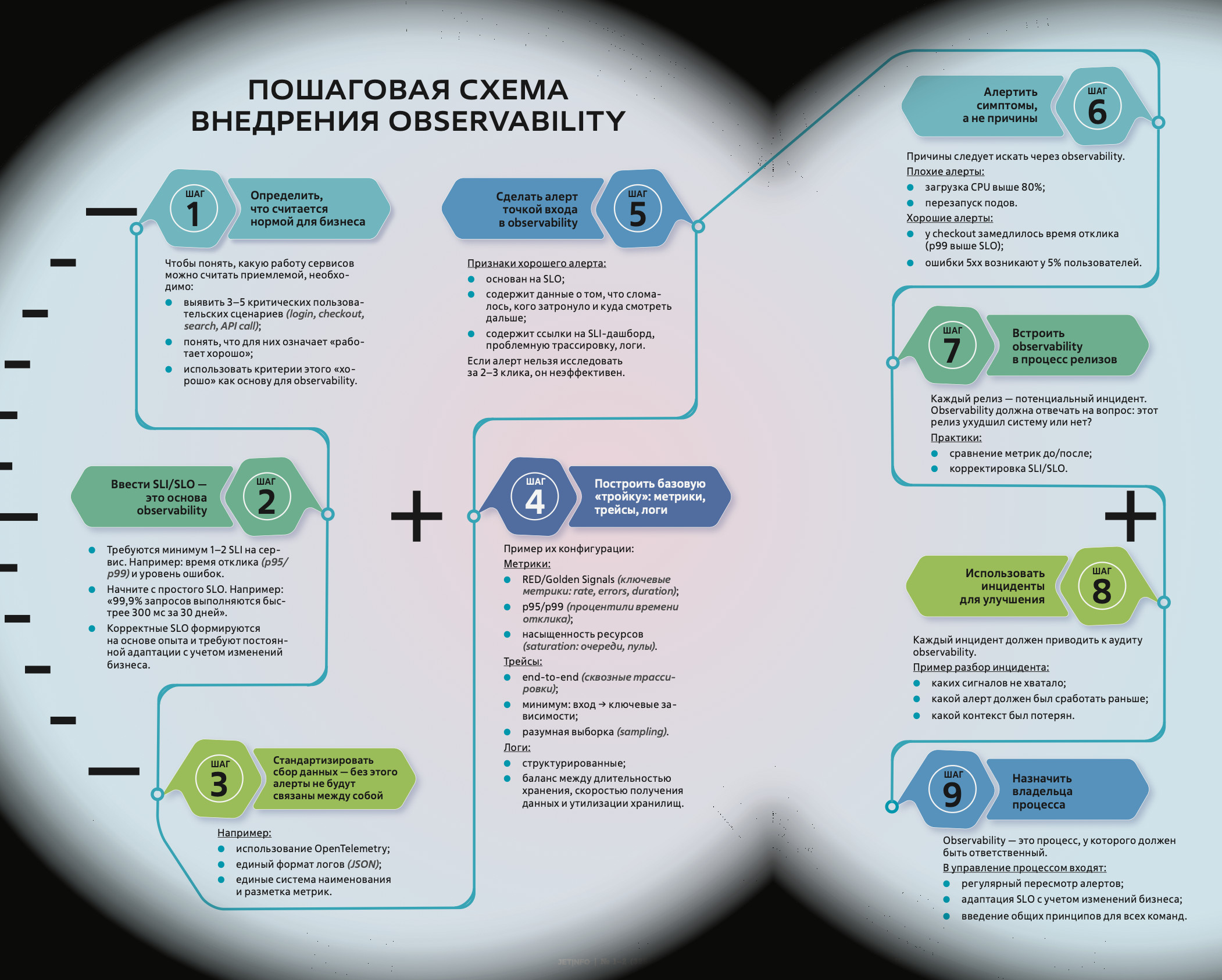
Мониторинг также позволяет понять, какую работу сервисов можно считать приемлемой. В этом помогают три составляющие: SLA (обещанный уровень работы сервиса), SLO (целевые показатели) и SLI (конкретные измеряемые показатели).
«Мониторинг системы задает норму качества через SLA, SLO и SLI. Недостаточно сказать, работает система или нет. Через SLO определяются конкретные показатели, показывающие насколько хорошо она функционирует. И именно на основе SLO рассчитывают бюджет ошибок (допустимое количество сбоев за определенный период) и приоритизируют работу инженеров по устранению аварий».
Алексей Акопян,
руководитель отдела систем мониторинга компании «Инфосистемы Джет»
Благодаря правильно настроенному мониторингу удается максимально быстро обнаружить и локализовать проблему, а также получить общий срез работы системы, что дает возможность составить картину для проведения диагностики. В результате специалисты могут минимизировать время восстановления (MTTR — Mean time to repair).
«Верная настройка мониторинга позволяет управлять алертами, снижая уровень “шума” за счет сокращения количества бесполезных показателей и повышения точности сигналов. Это одно из условий эффективности мониторинга. Избыток информации (система постоянно сигнализирует об опасности тогда, когда ее в действительности нет) может привести к тому, что по-настоящему опасный сигнал на этом фоне будет проигнорирован».
Алексей Акопян,
руководитель отдела систем мониторинга компании «Инфосистемы Джет»
«Почему это сломалось?»
Наблюдаемость принципиально отличается от мониторинга. Здесь тоже не обойтись без отслеживания данных, но основа метода другая: система, анализируя эту информацию, способна «рассказать» о своем внутреннем состоянии так, что инженер может понять, что с ней происходит.
То есть, имея некий черный ящик, куда невозможно проникнуть, мы должны делать выводы о его работе на основании того, как он реагирует на входящие в него сигналы. По этим реакциям предстоит понять, что находится внутри, как это работает, правильно ли оно функционирует и как исправить нарушения.
Не инструмент, но подход
Как правило, observability внедряют не ради собираемых данных, а для решения конкретной проблемы. И в этом отличие наблюдаемости от мониторинга. Мониторинг отвечает на вопросы, cломалось или нет, что сломалось, когда сломалось, сколько раз сломалось. А observability позволяет выяснить, почему это сломалось. Причем наблюдаемость дает возможность найти проблему даже в случае, когда в компании не знают, где она может быть локализована и что собой представляет.
Именно поэтому наблюдаемость позволяет решить проблему до того, как она станет инцидентом. Такую проактивность позволяют обеспечивать следующие функции:
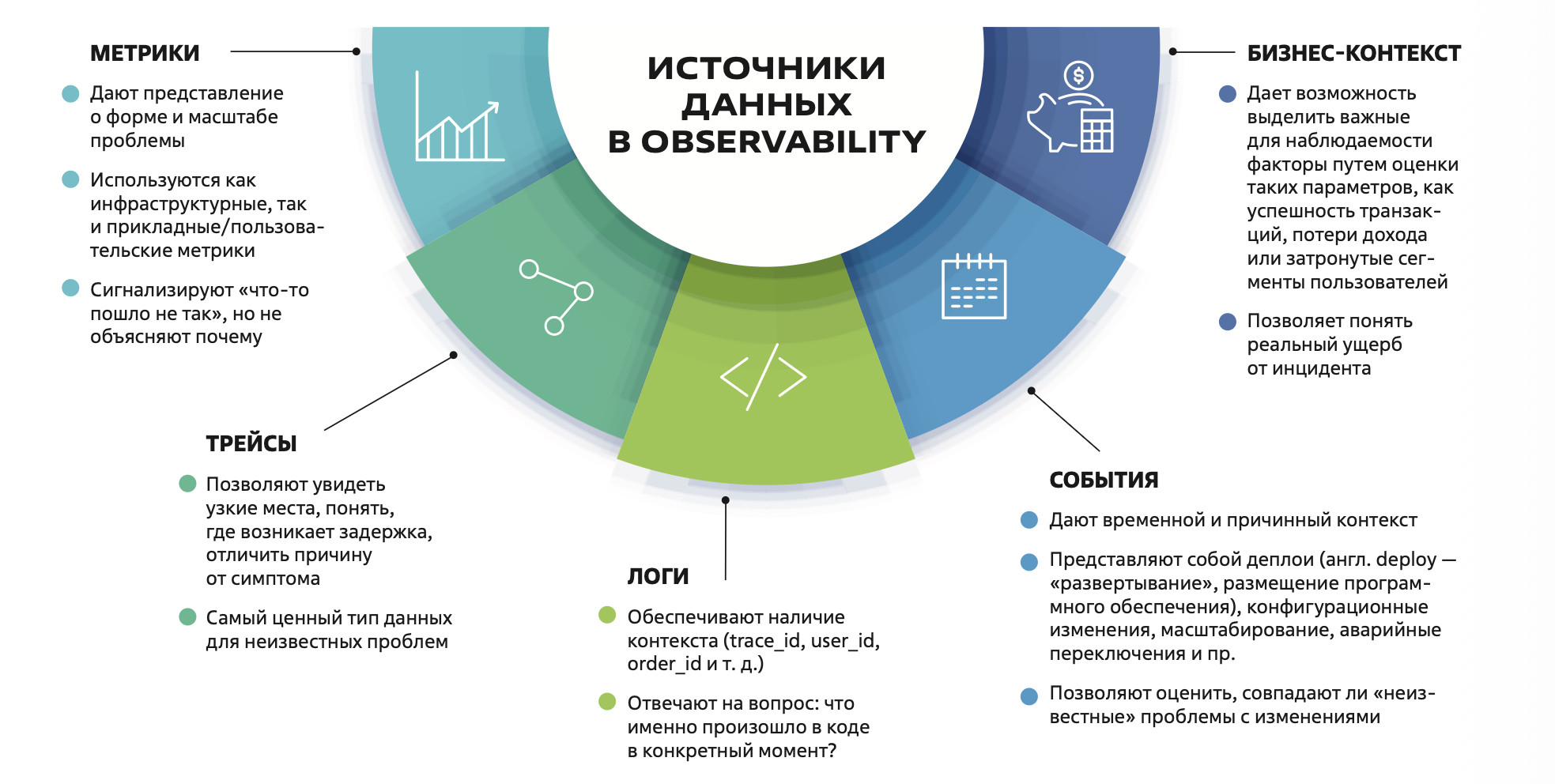
- выявление деградации до момента отказа благодаря контролю изменений в поведении сервисов;
- предоставление контекста вместо разрозненных сигналов — за счет корреляции метрик, логов, трейсов и привязки сигналов к бизнес-контексту;
- прогнозирование поведения сложных систем при обнаружении неожиданных состояний и новых типов сбоев до того, как они станут массовыми;
- обеспечение автоматизации действий (runbook automation) на основе сигналов.
«Понятие observability шире, чем только метрики, логи и трейсы. Это методология работы с телеметрией процессов и их автоматизацией. В ее рамках обеспечиваются управление алертами, инцидент-менеджмент, инвентаризация и планирование ресурсов серверов. При этом телеметрия должна предоставляться в виде, удобном для каждого из потребителей — от инженеров и аналитиков до кибербеза».
Юрий Пирогов,
руководитель направления Observability X5 Digital
Реализация observability позволяет видеть любые отклонения в работе систем, поскольку фиксируются все события и изменения. Благодаря этому удается выстроить зрелый процесс инцидент-менеджмента и сократить потери бизнеса.
Методология наблюдаемости широко применяется в компании «Яндекс». Сетевые инженеры и аналитики с помощью observability-платформы Monium в реальном времени отслеживают динамику конверсий и оценивают эффективность ключевых бизнес-сценариев. В компании отмечают, что практики observability внедрялись постепенно и прошли путь от базовых инструментов к единой платформе, которой сегодня пользуются более 16 тысяч сотрудников «Яндекса». Развитием платформы занимается команда Yandex Infrastructure — подразделение, отвечающее за дата-центры, сетевую инфраструктуру, распределенные хранилища данных, платформы разработки и деплоя, а также решения для машинного обучения.
«Наша платформа observability помогла компании обрести “глаза”: инженеры и бизнес-команды научились лучше понимать работу распределенных систем. Новая информация значительно обогатила контекст, на основе которого принимаются решения о развитии наших продуктов. Такие концепции, как SLO (целевой уровень обслуживания, service level objective) и бюджет ошибок, позволили на уровне всей компании сделать понятными ожидания бизнеса и инженерных команд относительно ключевых показателей работы систем».
Даниэль Халиулин,
технический менеджер платформы Monium (команда Yandex Infrastructure)
Единая observability-платформа и выстроенные практики повышают надежность систем: сбои удается обнаруживать и устранять быстрее. Снижается и нагрузка на инженеров — теперь им реже приходится переключаться между разрозненными инструментами
мониторинга, что дополнительно ускоряет реакцию на инциденты. «Яндекс» использует платформу Monium не только для внутренних задач: решение проходит апробацию и у внешних пользователей, включая «ОТП Банк» и одну из крупных FMCG-компаний.
За хлебом на джипе?
«Главное для построения проактивной работы с ИТ-инфраструктурой — взаимодополняемость мониторинга и observability. Эти подходы не являются альтернативными или конкурирующими. Они представляют собой части одного процесса: мониторинг фиксирует проблему, observability позволяет расследовать инцидент и предотвратить его повторение».
Дмитрий Унтила,
CPO «Пульта» и «Графини»
Однако применять observability следует далеко не всегда, поскольку это более сложный, а значит, и более дорогостоящий подход по сравнению с базовым мониторингом. Их стоимость может различаться на порядки, поэтому необходимо вовремя уловить момент, когда мониторинга становится недостаточно.
ИНСТРУМЕНТЫ ДЛЯ OBSERVABILITY
С открытым исходным кодом:
- OpenTelemetry — стандарт и набор инструментов для сбора и передачи телеметрии
- Prometheus — система мониторинга для работы с временными рядами данных
- Zabbix — система мониторинга состояния серверов, сетевого оборудования и приложений
- Grafana — платформа для визуализации данныхи алертинга
- Loki — система агрегации и хранения логов
- Tempo/Jaeger — инструменты для трассировки распределенных систем
Коммерческие российские продукты:
- «Пульт» — система мониторинга ИТ‑инфраструктуры
- «Графиня» — платформа для сбора, мониторинга и визуализации данных
- Gmonit — универсальная система мониторинга, управления метриками, событиями, логами и трейсами с использованием ИИ
- Proto Observability Platform — платформа наблюдаемости и аналитики операционных данных
- Smart Monitor — универсальная платформа для сбора и анализа машинных данных
- Monq — all-in-one — платформа наблюдаемости, мониторинга и автоматизации
«Это как с автомобилями: если машина вам нужна, чтобы пару раз в неделю закупаться в гипермаркете, до которого полчаса езды по ровной городской улице, то использовать для этого Land Rover или Geländewagen нерационально. Ну а там, где вместо асфальта ямы и буреломы, без внедорожника не обойтись. Как правило, observability требуется в случаях, когда цена ошибки перекрывает стоимость самой наблюдаемости».
Дмитрий Унтила,
CPO «Пульта» и «Графини»
Как же определить, что уже пора «брать джип»? Самое время — если:
- корпоративная ИТ-инфраструктура построена не как монолитное приложение
с ограниченным набором серверов, а включает микросервисы и сервисно-ориентированные архитектуры, облачные платформы и гибридные среды, контейнеризацию и оркестрацию; - в компании активно используются интеграция внешних сервисов, API сторонних поставщиков, SaaS-сервисы, платежные шлюзы, сервисы аутентификации и облачные хранилища;
- бизнес требует быстрой доставки новых функций, высокой доступности, отказоустойчивости, безопасности и соответствия стандартам.
Оценивать эффективность работы системы эксперты советуют от противного — исходя из отсутствия перечисленных ниже признаков:
- Специалисты не могут за пять минут понять, почему количество ошибок выросло в несколько раз.
- Логи разрознены, а также нет trace-id (либо они не совпадают между сервисами).
- Существующие дашборды не удается полноценно использовать — на них отображаются данные, которые не имеют особой ценности.
- При наступлении инцидента команда предпринимает хаотичные действия, пытаясь попасть в цель.
- Специалисты не понимают, что делать с получаемыми алертами.
- Команде неизвестны структура системы и назначение ее компонентов.
- Главная цель ИТ-команды — не решить задачу, а найти сотрудника, на которого можно возложить ответственность за провал.
Разумеется, необходимо соотносить затраты на построение системы наблюдаемости с отдачей от ее использования. В «Яндексе» придерживаются схожего подхода: в качестве ключевых ориентиров используют метрики семейства MTTx (Mean Time To X) — показатели, отражающие время прохождения основных этапов работы с инцидентами: от обнаружения (MTTD) до восстановления (MTTR) и других стадий. Среди основных издержек выделяют расходы на инфраструктуру, а также затраты на работу инженерной команды, которая отвечает за поддержку и развитие observability-системы.
«По нашему мнению, подходы observability превосходят традиционные как с точки зрения получаемой ценности, так и в плане затрат. Бизнес повышает надежность ИТ и усиливает прозрачность процессов, получая дополнительный контекст для принятия решений. Затраты при этом оптимизируются: больше не нужно поддерживать зоопарк разных решений».
Даниэль Халиулин,
технический менеджер платформы Monium (команда Yandex Infrastructure)
Одна из наиболее сложных задач, с которыми столкнулись специалисты X5 Digital при внедрении observability, — незаметная для пользователей смена стека. Для ее решения требовалось выстроить работу в трех направлениях:
- Управление сбором телеметрии, которое производится в компании с помощью инструментов непрерывной доставки и развертывания (continious delivery & deployment) и клиентских библиотек для продуктовых сервисов. При этом большая часть алертов и дашбордов создается в автоматическом режиме.
- Контроль жизненного цикла правил алертов, за что отвечает отдельный сервис, с помощью которого происходит автоматизация управления правилами и ауди-
та изменений в них (к этому процессу в том числе подключаются автогенераторы). - Высокая точность срабатывания алертов, которая достигается за счет собственной разработки компании — инструмента, динамически изменяющего уровни их срабатывания на основе собранных метрик нагрузки на сервисы в конкретное время.
Собственные решения в X5 Digital, в частности, используют для того, чтобы снизить риск попадания чувствительных данных в хранилища логов, а также заменить часть зарубежных компонентов open source в соответствии с требованиями кибербезопасности. После внедрения observability у сотрудников появился более полный обзор происходящего с сервисами во время инцидентов: стали доступными данные об изменениях, релизах, срабатываниях алертов и других событиях.
«Мы применяем превентивный подход — заранее прорабатываем алерты, срабатывание которых предупреждает инциденты, а не реагируем на них постфактум. Затем покрытие сервисов такими алертами автоматизируется и контролируется поддержкой и инцидент-менеджерами. При этом мы предоставляем разработчикам библиотеки и средства автоматического создания дашбордов по шаблонам алертов. В результате внутренняя команда не тратит время на ручную настройку».
Юрий Пирогов,
руководитель направления Observability X5 Digital
Все только начинается
Выстраивая систему наблюдаемости, необходимо понимать, что ее работа подразумевает гибкую, постоянно меняющуюся архитектуру. Например, искусственный интеллект все активнее внедряется в мониторинг и observability. Платформы используют ИИ для анализа телеметрии: умной корреляции событий и снижения шума алертов, автоматического выявления аномалий и прогнозирования проблем, помощи в поиске первопричин аварий.
По мере усложнения распределенных систем и интеграций все больше внимания уделяется безопасности: системы сигнализируют об аномалиях, нарушениях политик, уязвимых маршрутах и т. д. Ожидается, что в ближайшие годы мониторинг будет эволюционировать, усложняться, становиться более эффективным и постепенно переходить в наблюдаемость.
Возможно, через несколько лет компании вовсе перестанут разграничивать два этих подхода, считая их составляющими единого процесса, необходимого любой ИТ-инфраструктуре.
Значимость темы observability для российского рынка подтверждается и интересом к ней профессионального сообщества. Так, в 2026 году впервые в России прошло отраслевое мероприятие, полностью посвященное вопросам построения наблюдаемости в организациях. Конференция Observability, прошедшая 19 марта в Москве, собрала 300 участников офлайн и более 2000 зрителей в олайн-формате.
В рамках события также была организована выставка ведущих производителей отечественного софта: Т-банк, Monq, Wisla, «Инфосистемы Джет» и «Лаборатория Числитель» с продуктом «Пульт» представили инновационные решения и провели живые демонстрации, позволив участникам на практике оценить их надежность и функциональность. Конференция имеет все шансы стать ежегодным событием и занять заметное место в повестке российского ИТ-сообщества.

