 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

Сами по себе данные не представляют особого интереса. Номер телефона клиента компании является всего лишь набором символов. Эта информация становится ценной только тогда, когда с ее помощью можно выстроить какой-либо бизнес-процесс, позволяющий достичь желаемого результата. Оценка качества данных, как правило, также зависит от бизнес-процесса, в котором они используются, но можно выделить стандартный набор критериев, которым данные обычно должны соответствовать. К ним относятся полнота, согласованность, точность, актуальность и т.д. Например, для осуществления таргетированной SMS-рассылки база данных клиентов компании должна содержать, как минимум, имя клиента и его мобильный телефон. При наличии этой информации можно считать, что данные соответствуют критерию полноты для нашего бизнес-процесса. Если же предлагаемая в SMS услуга или товар нацелены на совершеннолетнюю аудиторию, то для обеспечения полноты требуется еще и наличие возраста клиента. Согласованность в данном случае потребуется для номеров мобильных телефонов, т.к. они должны быть записаны в стандартизированном формате, пригодном для обработки SMS-центром для организации рассылки.
Другим интересным случаем является организация рассылки маркетинговых материалов клиентам по почте. Т.к. процесс рассылки связан с затратами на печать и организацию доставки материалов, качество адресной информации должно быть в обязательном порядке подвергнуто оценке. Например, качество данных адресов можно проверить по КЛАДР (классификатор адресов России) или ФАИС (Федеральная государственная информационная система). В противном случае компании, скорее всего, грозят пустые расходы.
В качестве более подробного примера рассмотрим гипотетическую организацию, предлагающую какие-либо услуги. Компания успешно развивалась на протяжении длительного периода времени: ее штат постоянно пополнялся, она предлагала всё новые услуги, внедряла всё новые системы учета клиентов, заключала договоры с новыми контрагентами на перепродажу услуг и т.д. В один прекрасный момент персонал компании осознал, что для обеспечения бизнес-процессов используется множество информационных систем, в которых в разном объеме осуществляется учет сведений о клиентах. Качество этих данных в разных системах отличается, что приводит к рассогласованию сведений и снижению качества информации в целом. Например, более свежая запись о клиенте в какой-либо системе, как правило, содержит более актуальную информацию о его контактных данных. Отсутствие единой базы клиентов затрудняет решение задач, связанных с сопровождением процессов продаж, анализом клиентской базы и др. Все усугубляется тем, что даже в рамках одной системы данные не приведены к единому стандарту, нет понимания, какая важная информация отсутствует или наоборот дублируется.
При этом компания решает изменить направление бизнеса – она начинает проводить политику ориентации на клиентов. Но, к сожалению, качество существующей о них информации в системах не соответствует требуемым критериям для возможности организации желаемых бизнес-процессов.
Или другой пример – возьмем компанию, область деятельности которой связана со страхованием. В подобных организациях первичным, как правило, является не клиент, а договор с ним. Более того, для разных страховых продуктов требуются различные наборы информации о клиенте: в одном случае обязательно указание его телефона, в другом – место текущего проживания и т.д. Объединение информации о клиентах из различных договоров позволяет получить полное представление о каждом из них и ответить на такие вопросы, как: сколько всего у компании уникальных клиентов; сколько совокупно договоров или убытков у какого-либо конкретного клиента; кем является каждый из них – прибыльным/убыточным и т.д.
Приведенные нами примеры показывают, что прежде чем использовать клиентские данные, нужно организовать процесс повышения их качества. В современном ИТ-мире для достижения этой цели в рамках одной системы используются решения класса Data Quality, а в рамках нескольких систем – класса MDM (Master Data Management). Они позволяют организовать полный цикл процессов по профилированию данных, анализу их качества и его повышению. Реализация этих процессов приводит к созданию эталонных значений, или так называемых «золотых записей». Обработку исходных данных для приведения их к «золотым записям» можно разбить на ряд процессов:
- профилирование;
- стандартизация;
- очистка;
- обогащение;
- дедупликация.
Остановимся более подробно на каждом процессе.
Профилирование
Рис. 1. Процесс профилирования
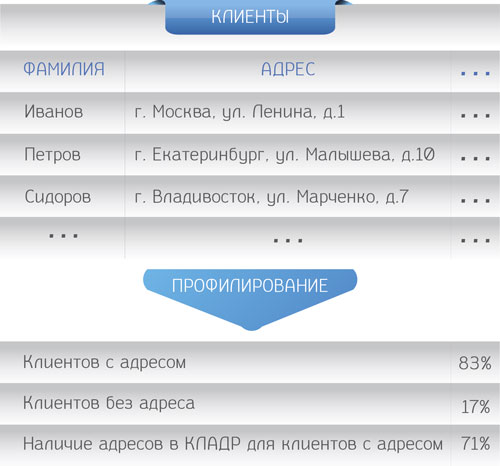
Это анализ существующих источников данных с целью определения их пригодности для использования в планируемом бизнес-процессе. Кроме того, профилирование позволяет определить те критерии, выполнение которых даст пригодные для использования данные. Т.е. этот процесс помогает компании заранее понять качество и полноту содержащейся в системе информации для организации нового для нее бизнес-направления.
Например, наша вымышленная компания решает организовать рассылку письменных уведомлений своим клиентам. Для этого проводится анализ их адресов, в результате в процентах оцениваются наличие, реальность адресов и отсутствие записей о месте проживания клиентов. Полученная информация позволяет компании понять применимость существующих данных для организации рассылок.
Стандартизация
Рис. 2. Процесс стандартизации

Это приведение данных к единому формату. Задачами стандартизации являются нормализация БД, увеличение атомарности и унификация представлений данных. Отметим, что конечная цель нормализации БД – это уменьшение потенциальной противоречивости хранимой в базе данных информации.
Стоит сказать несколько слов и об увеличении атомарности. Так, в нашей вымышленной компании информацию о ФИО клиента в системах вводили в разном формате: в ряде систем ФИО заносили в одно строковое поле, а в других для каждого значения была определена своя колонка в БД. Для стандартизации данных ФИО, которое вводили в одно поле, следует разбить на фамилию, имя и отчество (ФИО: «Иванов Иван Иванович» –> фамилия: «Иванов», имя: «Иван», отчество: «Иванович»).
В свою очередь, унификация представления данных – это процесс выбора единого формата записи значений. Например, номера сотовых телефонов должны быть приведены к стандартному виду, содержащему код страны, национальный код направления и номер абонента. Также к стандартизации можно отнести возможность приведения адресов клиентов к единому формату, поддерживаемому КЛАДР.
Очистка
Рис. 3. Процесс очистки
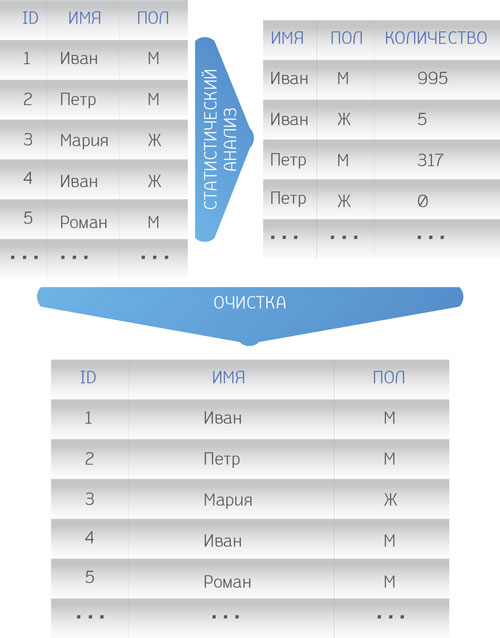
Это процесс выявления и исправления ошибок и несоответствий данных. Задачи очистки – анализ информации, определение ошибочных данных и устранение неточностей. Типичным случаем последнего является статистический анализ данных. Например, в нашей вымышленной компании статистический анализ выявил, что 995 клиентов с именем «Иван» имеют в качестве признака пола «мужской», а 5 клиентов с тем же именем – ошибочно введенный «женский». Ошибка может быть автоматически исправлена, и эта 1000 клиентов будет иметь в качестве признака пола «мужской». Отметим, что часто некорректность данных вызвана ошибками операторов, которые их вводили. Например, оператор вместо имени «Иван» ввел «Иаан». Существует множество методов, которые могут определять похожесть строк и автоматически исправлять ошибки. Наиболее часто используемый в данном случае алгоритм – вычисление расстояния Левенштейна (это минимальное количество операций вставки, удаления одного символа и его замены на другой, необходимых для превращения одной строки в другую). Еще одним интересным примером возможности выявления ошибок является метод анализа контрольных чисел. Например, код ОКАТО в 9-м и 10-м знаках содержит контрольное число, которое определяется по действующей методике расчёта и применения контрольных чисел ПР 50.1.024-2005 «Основные положения и порядок проведения работ по разработке, ведению и применению общероссийских классификаторов». Если контрольное число в коде ОКАТО не соответствует первым 8 символам, на основании дополнительной информации можно попытаться восстановить его правильное значение.
Обогащение
Рис. 4. Процесс обогащения

Под ним понимают процесс добавления к существующим данным новой информации, позволяющей сделать их более значимыми для бизнес-процессов компании, в которых они участвуют. Например, в одной из систем для данных по клиентам не было предусмотрено ведение пола. В таком случае пол можно определить на основании суффикса отчества: если оно заканчивается на «-ович», скорее всего, пол «мужской», если на «-овна», «женский». Довольно интересным примером является определение домохозяйств. Так, возможность анализа адреса клиента и его ФИО может дать информацию о родственных связях. Например, Сидоров Иван Иванович и Сидоров Петр Иванович, проживающие по одному адресу, скорее всего, являются родственниками. Если провести более глубокий анализ и на основании дат рождения определить, что их разница в возрасте составляет более 18 лет, то с заданной степенью вероятности можно утверждать, что они являются отцом и сыном. Рассмотренные сценарии позволяют обогатить информацию на основании уже присутствующих в системах компании данных. Но ее можно обогащать и из внешних источников. Например, часть данных о клиенте может быть использована для его поиска в социальных сетях (Facebook, LinkedIn, ВКонтакте и т.д.) и получения дополнительной информации.
ДедуПликация
Рис. 5. Процесс дедупликации
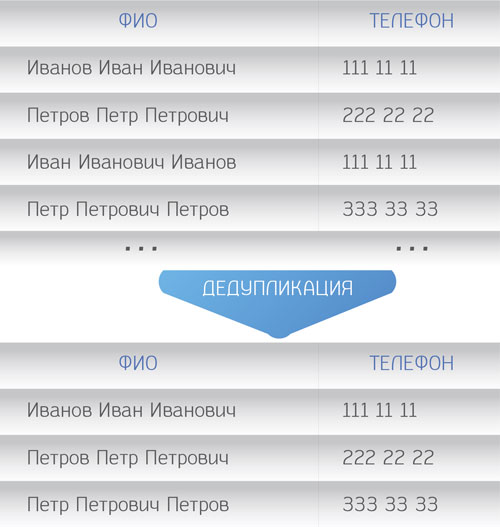
Это процесс обнаружения и исключения избыточных (совпадающих по каким-либо критериям) данных путем объединения одинаковых строк в одну эталонную, или «золотую», запись. Например, на основании совпадения ФИО, даты рождения и места проживания можно определить, что разные записи о клиентах в системе представляют одного и того же человека. Само объединение в процессе может учитывать дополнительные факты для создания «золотой» записи. Например, при объединении записей о клиенте в качестве номера его телефона может быть выбран номер из более свежей записи, т.к., скорее всего, он является наиболее актуальным. Тот же самый алгоритм может касаться и адреса проживания. При этом свежая запись не всегда может быть правильной, тогда используется принцип ранжирования качества информации о конкретных атрибутах клиента на основании весовых коэффициентов источников записей, участвующих в слиянии.
Итак, применение решений Data Quality для профилирования, стандартизации, очистки, обогащения и дедубликации данных позволило нашей гипотетической компании получить базу данных клиентов, качество информации в которой соответствует необходимым требованиям для обеспечения выполнения новых бизнес-процессов. Внедрение подобных решений предоставляет компании инструмент для организации таргетированных рассылок, анализа клиентской базы, построения прогнозов предоставления услуг и т.д. В перспективе это приведет к повышению прибыли компании. Расширение же этой парадигмы на все системы позволяет получить единую БД клиентской информации, данные в которой являются качественными.
Компания «Инфосистемы Джет» поддерживает полный цикл процессов по внедрению и сопровождению решений Data Quality различных вендоров. Нашими партнерами являются такие признанные в России и за рубежом компании, как TIBCO Software Inc. (продукт TIBCO Data Quality), Informatica Corporation (продукт Informatica Data Quality), HFLabs (продукт Фактор) и т.д.
В настоящее время создано большое количество алгоритмов/процессов для повышения качества данных, которые не представляется возможным рассмотреть в рамках одной статьи. Мы проанализировали этот процесс на примере клиентской информации. При этом Data Quality и MDM-решения позволяют повышать качество любых доменов/сущностей, которые могут быть использованы в различных бизнес-процессах. В качестве таковых могут выступать контракты, элементы продуктового каталога, контрагенты или номенклатура поставщиков и т.д.
Отдельно стоит отметить, что типичным примером использования данных, прошедших обработку системами класса Data Quality, является их анализ с помощью какого-либо BI-решения. На основании качественных данных возможны построение наиболее полных и корректных отчетов, прогнозирование процессов продаж, анализ текущей операционной деятельности компании и т.д. Если же BI-решение использовать на данных, не подвергнутых обработке процессами Data Quality, компания рискует получить некорректную информацию. Ее применение может привести к повышению рисков или вообще к снижению прибыли в связи с неправильным анализом или прогнозированием.
В заключение хотелось бы отметить, что внедрение решений Data Quality позволяет компаниям самых разных сфер деятельности (банки, телеком-операторы, страховые компании, ритейл и др.) повысить продуктивность как существующих, так и планируемых бизнес-процессов, направленных на достижение каких-либо заранее обозначенных целей: получение прибыли, увеличение лояльности клиентов, снижение трудозатрат и т.д. Более того, получение новой информации путем обогащения данных позволяет компании рассмотреть возможность реализации таких бизнес-процессов, использование которых до применения решения Data Quality не представлялось возможным.

