 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
/ Атака в любой момент времени — теперь не исключение, а фоновый риск цифровой инфраструктуры
/ Защита не может оставаться статичной: любое изменение в инфраструктуре неизбежно требует пересмотра модели угроз и корректировки защитных механизмов
/ Сегодня DDoS — это не вопрос удачи, а элемент системного управления рисками
DDoS традиционно ассоциируется с атаками на федеральные порталы или крупные телеком-компании. Однако статистика последних лет демонстрирует иную картину: атаки направлены на организации любого масштаба — от госсектора до образовательных и игровых сервисов. Согласно отчету Cloudflare, 2025 год показал кратный рост числа DDoS-инцидентов — до 47,1 млн за год, что на 121% больше, чем в 2024-м. Это означает, что нападение в любой момент перестало быть исключением и стало фоновым риском цифровой инфраструктуры.
Чтобы рассмотреть проблему системно, разберем гипотетический сценарий на примере быстрорастущей компании из сегмента IoT, разрабатывающей и обслуживающей интеллектуальные дверные замки с удаленным управлением.
Бизнес быстро растет, продукт востребован, инфраструктура постепенно усложняется. Какие ресурсы для такой компании критичны? Прежде всего — люди и среда их работы. Это офисная сеть с устойчивым доступом в интернет, корпоративная почта, система видео-конференц-связи. Для удаленных сотрудников — RA VPN, обеспечивающий безопасный доступ к внутренним ресурсам, а также, при необходимости, корпоративная телефония.
Коммерческая модель предполагает активное онлайн-присутствие. Минимальный набор — публичный веб-портал, через который ведутся продажи и осуществляется коммуникация с клиентами. Однако для самого продукта требуется значительно более сложная ИТ-поддержка: система контроля и управления, серверы обновлений, а также мобильные приложения для iPhone и Android. Функция информационной безопасности формально выстроена: в штате есть руководитель и два специалиста. Однако приоритеты бюджета очевидны: основные инвестиции направлены на развитие продукта и масштабирование бизнеса, — тогда как ИБ финансируется по остаточному принципу.
Компания демонстрирует стремительный рост и уже занимает вторую позицию на рынке. Стратегическая цель — лидерство. Этому способствуют качественный продукт, стабильная работа сервисов и отсутствие публичных инцидентов. Репутация становится ключевым активом. Однако любая рыночная история предполагает наличие противодействующей стороны. Это может быть конкурент, группа хакеров или даже одиночный скрипт-кидди — иными словами, любая из категорий, которые в профессиональной среде принято обозначать термином «черная шляпа».
«Черная шляпа»
Перейдем к анализу ситуации с позиции атакующей стороны. Мотивация может быть различной — от прямого вымогательства до идеологического давления. Мы же в рамках рассматриваемого сценария сосредоточимся на варианте недобросовестной конкуренции.
Компания обслуживает тысячи интеллектуальных замков, внедрила технологию распознавания лица через видеоглазок и фактически сформировала у пользователей новую модель поведения — отказ от физических ключей в пользу мобильного приложения и биометрии. Удобство становится частью повседневной жизни, но именно эта цифровая зависимость и формирует точку уязвимости. В подобном бизнесе репутация — ключевой актив. Пользователь доверяет поставщику не просто устройство, а доступ в собственный дом. Следовательно, воздействие злоумышленников должно быть направлено на подрыв этого доверия. И наиболее чувствительный сценарий — нарушение доступности сервиса. Даже кратковременный отказ системы способен вызвать резонанс и поставить под сомнение надежность решения. Для атакующей стороны это очевидная цель. Рассмотрим возможные инструменты для ее достижения.
Первый вариант — DDoS-атака сетевого уровня модели OSI (L3). Механизм хорошо известен: перегрузка канала связи и сетевого оборудования за счет резкого увеличения объема трафика. Такие атаки относительно просты в реализации, при этом рынок DDoS-as-a-Service давно сформирован: аренда ботнета доступна за сравнительно небольшие средства. Если у цели опубликованы веб-приложения, логичным развитием становится комбинированная L3+L7-атака (она затрагивает не только сетевой, но и прикладной уровень).
Однако современный веб — это уже не набор статичных HTML-страниц. Типовой сервис включает авторизацию (в том числе с отправкой SMS-подтверждений), поиск, динамический контент, видеотрансляции и т. д. За каждым пользовательским действием стоят обращения к базам данных, системам хранения и сторонним сервисам — с соответствующей нагрузкой на вычислительные и финансовые ресурсы компании.
Второй вариант — атаки прикладного уровня (L7), ориентированные на логику приложения. Они не требуют большого объема трафика и поэтому менее заметны в общем потоке. Медленные соединения, сложные поисковые запросы, скачивание «тяжелого» контента — все это приводит к постепенному исчерпанию ресурсов сервера. Если дополнительно инициировать массовую отправку SMS-кодов через ограниченное число ботов, можно увеличить операционные затраты и ускорить деградацию сервиса.
В результате пользователь сталкивается не с мгновенным отказом, а с ухудшением качества его работы: задержками, ошибками авторизации, недоступностью функций. Для бизнеса, зависящего от доверия, этого уже достаточно.
Цель сформулирована — нарушение доступности и подрыв репутации. Инструменты определены. Сценарий выглядит реализуемым.
«Белая шляпа»
Вернемся из роли атакующего в позицию защитника. Все сценарии, которые мы только что рассмотрели, применимы к нашей инфраструктуре в полной мере. Вопрос «Готовы ли мы?» неизбежно трансформируется в более практичный: «С чего начать?»
Как и любая атака, защита начинается с разведки — но уже собственной. Необходимо провести инвентаризацию активов — в этом помогают открытые инструменты, такие как Shodan и BGP Looking Glass. Shodan позволяет выявить открытые порты и доменные имена, ассоциированные с конкретным IP-адресом. BGP Looking Glass (например, bgp.tools) предоставляет информацию об IP/AS, в том числе с отрисовкой графа связности автономных систем до Tier-1. Анализ маршрутов позволяет убедиться, что весь входящий трафик действительно проходит через заявленных провайдеров защиты и не имеет обходных путей.
Результатом инвентаризации должна стать карточка сервиса, содержащая как минимум:
- назначение сервиса;
- IP-адреса, порты и протоколы взаимодействия;
- доменные имена, закрепленные за сервисом;
- IP-адреса, порты и протоколы зависимых систем (внешние интеграции).
Дополнительно целесообразно подготовить сетевую или логическую схему с полной картой оборудования, через которое проходит трафик, а также зафиксировать результаты нагрузочного тестирования, если оно проводилось. Нагрузочные тесты могут выполняться с использованием Apache Jmeter, Gatling или облачных сервисов. В рамках нашего сценария карточек должно быть не менее шести: интернет, почта, ВКС, VPN, веб-портал, управление замками. Эта информация формирует базовые профили легитимного трафика и позволяет оценить потенциальные векторы атак. Важно учитывать, что атаки разных уровней требуют различного подхода и зачастую средств защиты разных классов.
Отдельного внимания заслуживает архитектура самих средств защиты. Любой компонент может стать точкой отказа. Размещение NGFW перед сервисом или использование его в качестве замены специализированного AntiDDoS-решения только на основании заявленного функционала способно привести к отказу самого NGFW раньше, чем будет достигнут предел устойчивости защищаемого сервиса.
Поэтому принцип эшелонированной защиты остается актуальным. Практика показывает, что эффективная AntiDDoS-архитектура включает:
- фильтрацию на стороне провайдера связи;
- сервис очистки трафика (scrubbing center), в том числе с антибот-функционалом для противодействия продвинутым L7-атакам;
- дополнительный уровень фильтрации внутри ИТ-контура компании.
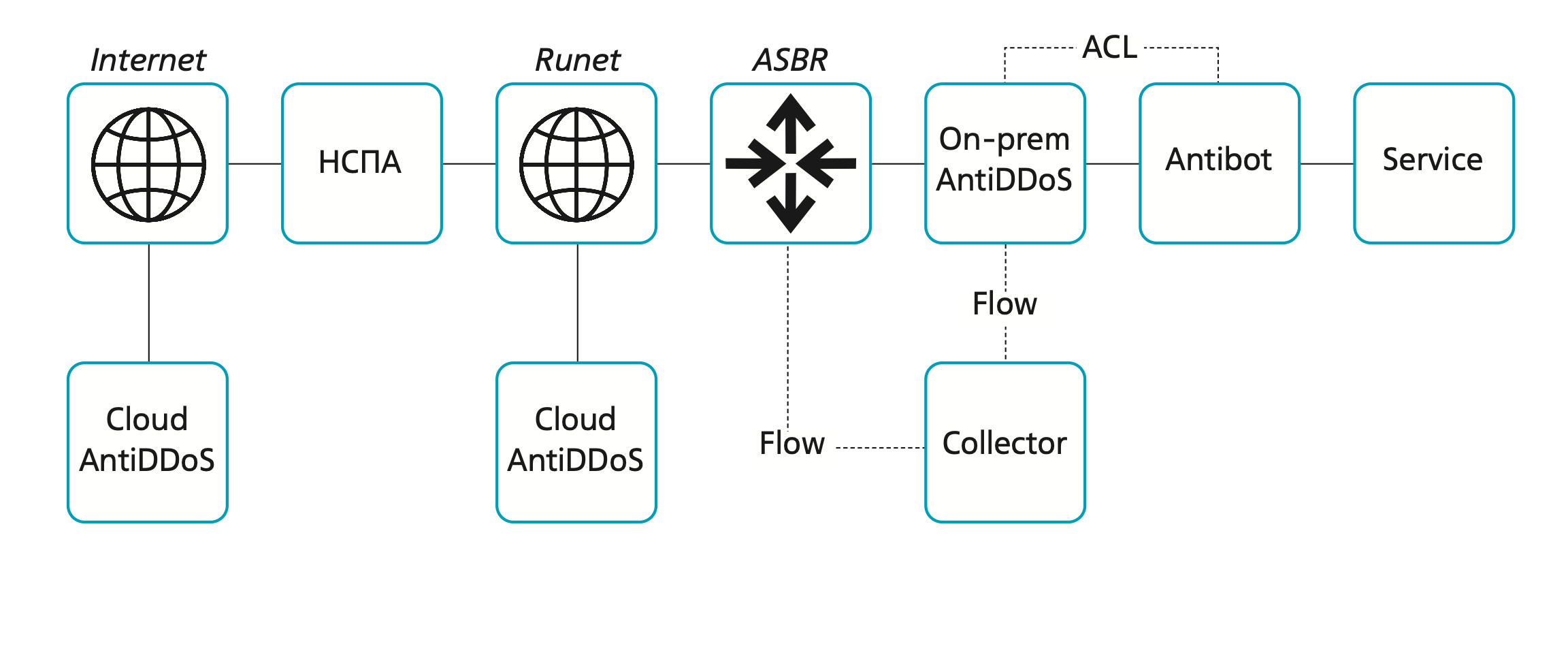
Компоненты должны быть интегрированы для автоматической передачи политик и запросов на очистку. Для повышения отказоустойчивости архитектуру желательно дублировать на уровне провайдеров. Однако при таком подходе стоимость защиты может оказаться несоразмерной стоимости защищаемых активов. Возникает необходимость оптимизации, и среди возможных мер:
- защита только критически важных опубликованных сервисов;
- формирование запаса прочности за счет масштабирования (например, средствами Kubernetes или путем добавления серверов приложений);
- использование CDN и кэширующих серверов для статического контента;
- ограничение обращений к базе данных по времени выполнения и объему выборки.
Отдельный вариант — перевод трафика на очистку только в период атаки. Такой режим требует наличия анализатора (FlowCollector) в собственной инфраструктуре, настройки передачи flow с пограничных маршрутизаторов и механизма оперативного обновления BGP-анонсов по сигналу анализатора.
Вернемся к нашему сценарию. Учитывая ограниченность бюджета и высокую значимость репутации, руководство принимает решение сосредоточиться на защите критических сервисов — веб-портала и системы управления замками. Подготовлены карточки сервисов, подключен сервис защиты от DDoS, настроены профили трафика. Формально — все готово, но реальность, как это обычно бывает, вносит свои коррективы. В праздничный день сервис оказывается недоступным: реагирование происходит без заранее отработанного плана и больше напоминает хаотичные попытки восстановить работоспособность. После стабилизации ситуации проводится разбор причин и выясняется, что защита функционировала корректно, но атака была направлена на устаревшие IP-адреса приложений, для которых отсутствовал ACL на прием трафика исключительно от сервиса защиты.
Еще один важный вопрос — обнаружение инцидента. Информация о проблеме поступила не от системы мониторинга, а была выявлена по факту недоступности сервиса. Это указывает на отсутствие полноценного контроля аномалий трафика и регламентированной процедуры уведомления.
Поэтому план реагирования в случае DDoS, помимо фильтрации, должен включать:
- мониторинг роста трафика и аномалий;
- уведомление дежурной смены;
- заранее определенный план реагирования;
- распределение ролей и взаимодействие с руководством и технической поддержкой.
Логичным этапом развития становится автоматизация. В качестве примера — автоматическая передача FlowSpec-правил провайдеру для применения на границе сети или внесение адресов в списки блокировки на сервисе DDoS по сигналу внутреннего анализатора.
Нормативная база и реальные подходы к AntiDDoS
До этого момента мы рассматривали ситуацию как гипотетический кейс. Возникает закономерный вопрос: насколько такие рассуждения соотносятся с реальной регуляторной практикой? Что предписывает государственный регулятор в части защиты от атак, направленных на отказ в обслуживании?
6 февраля 2026 года на сайте ФСТЭК России был опубликован проект методического документа «Мероприятия и меры по защите информации, содержащейся в информационных системах». В документе прописаны требования к реализации защиты от DDoS-атак, и значительная часть положений коррелируют с теми выводами, к которым мы пришли в рамках сценарного анализа. Однако присутствуют и акценты, заслуживающие отдельного внимания. Например, в документе указывается, что обеспечение защиты должно предусматривать «анализ логической схемы сети с целью поиска узких мест на пути прохождения трафика и реализацию мер по увеличению ресурсов для обработки трафика и сетевых соединений минимум с двухкратным запасом от ожидаемого легитимного трафика».
Иными словами, речь идет не только о фильтрации, но и о проектировании инфраструктуры с учетом потенциальных пиковых нагрузок и резервирования ресурсов. Кроме того, подчеркивается необходимость использования правил фильтрации, исключающих пропуск «всего трафика», то есть от любого сетевого адреса источника и (или) сервиса к любому адресу назначения. Реализуется принцип «все, что явно не разрешено, — запрещено». Это означает, что правила должны быть максимально специфичными и точными, не допускающими прохождения трафика по протоколам и сервисам, которые не используются информационной системой.
Формально требования документа распространяются на государственные информационные системы (ГИС), объекты критической информационной инфраструктуры (КИИ) и информационные системы персональных данных (ИСПДн). Однако с инженерной точки зрения изложенные подходы универсальны и применимы к любой организации, заинтересованной в устойчивости своих сервисов.
Документ пока имеет статус проекта, однако его появление уже сейчас доказывает, что рассмотренные нами сценарии не являются теоретическими допущениями. Их логика совпадает с подходами, которые регулятор закладывает в требования к защите от атак, направленных на отказ в обслуживании.
Защита как постоянная практика
Информационные системы динамичны по своей природе: они масштабируются, усложняются, обрастают новыми интеграциями и сервисами. Поэтому их защита не может оставаться статичной: любое изменение в инфраструктуре неизбежно требует пересмотра модели угроз и корректировки защитных механизмов.
AntiDDoS в этом контексте — не разовая настройка, а непрерывный процесс совершенствования. Он включает:
- проведение тестовых DDoS-атак с последующей корректировкой после результата;
- организацию киберучений для группы реагирования и оптимизацию процессов на основе полученного опыта;
- мониторинг и автоматическое пополнение черных списков на базе внешних источников (feeds);
- регулярную инвентаризацию защищаемых ресурсов и актуализацию применяемых политик;
- нагрузочное тестирование сервисов для определения предельной устойчивости;
- внедрение ловушек (ханипотов) и анализ поведения атакующих;
- группировку сервисов по профилям трафика и организацию гранулярных политик для каждой группы;
- проработку сценариев полного отказа (оперативное восстановление);
- системное взаимодействие с провайдерами связи и регулятором.
В качестве примера можно привести Национальную систему противодействия атакам (НСПА), в рамках которой круглосуточно осуществляется блокировка атак различной мощности. Организации могут подключать собственное on-site-оборудование защиты от DDoS для автоматической активации контрмер в общей инфраструктуре противодействия. Подобная модель позволяет перераспределить нагрузку, сократить время реакции и, как следствие, минимизировать потенциальный ущерб.
Практические шаги к снижению DDoS-рисков
Практический минимум, который можно выполнить уже сейчас:
- провести инвентаризацию опубликованных сервисов — собственными силами или с привлечением внешнего аудитора;
- оценить их значимость и выделить критичные для непрерывности бизнеса;
- зафиксировать метрики работы в «мирное» время;
- проработать вопрос блокировок на уровне провайдера связи;
- протестировать решения для on-prem- или cloud-защиты от DDoS.
Сегодня DDoS — это не вопрос удачи, а элемент системного управления рисками. Мотивация атакующих может различаться: конкурентная разведка, вымогательство, попытка дестабилизации или банальное хулиганство. Однако последствия для бизнеса предсказуемы: финансовые потери, снижение доступности сервисов и репутационные издержки.
Следовательно, ключевой принцип — проактивность. Ожидание инцидента как повода для действий в современной цифровой среде недопустимо. Необходимо заранее проверить устойчивость инфраструктуры, сформировать и отработать план реагирования, а также убедиться, что провайдер связи и выбранные средства защиты способны противостоять как сетевым (L3), так и прикладным (L7) атакам.
Конструируя безопасность
Идея внедрения комплексных систем безопасности, активно обсуждаемая в отрасли, когда-то звучала как лозунг, но сегодня уже получила практическое воплощение благодаря значительным достижениям производителей оборудования и софта. Современные решения позволяют объединить традиционные средства обеспечения физической безопасности объектов в рамках единых платформ классов ССОИ (система сбора и обработки информации) и PSIM (программный модуль для управления информацией о физической безопасности). Такие системы помогают настроить централизованное управление всеми компонентами безопасности и автоматизацию процессов выявления и устранения угроз.
Крупные промышленные компании, такие как «Норникель», управляют разветвленной инфраструктурой и активами, расположенными в разных регионах. В таких условиях стандартных решений уже недостаточно — требуется более масштабная и системная организация управления безопасностью. Одним из таких решений стала концепция системы ситуационно-аналитических центров безопасности (ССАЦБ).
Она объединяет инструменты мониторинга и аналитики в единую структуру, позволяет централизованно отслеживать ситуацию на объектах и оперативно реагировать на угрозы. Речь идет о контроле рисков в различных направлениях — от корпоративной и экономической до транспортной и антитеррористической безопасности. Такая модель обеспечивает целостное понимание происходящего и повышает управляемость всей системы защиты.
Концептуально архитектура управления ССАЦБ распределена по трем уровням с вертикальной цифровой связанностью:
- Пункты управления безопасностью объектов: сбор событий и потоков от объектовых систем безопасности, объединенных в PSIM-системы. Именно здесь происходит управление и оперативное реагирование на инциденты.
- Региональные САЦБ (ключевые регионы присутствия): работа с информацией, поступающей с первичного (объектового) уровня, аналитика. Они выступают промежуточным звеном, гарантирующим эффективную передачу необходимой информации без перегрузки верхнего уровня лишними деталями.
- Главный САЦБ (главный офис компании): агрегирование и обработка поступивших массивов информации, выработка предложений для принятия управленческих решений руководством на основании комплексного анализа ситуации и учета множества факторов риска.
В режиме реального времени на каждый уровень передаются только те события, которые требуют участия или решения вышестоящего звена; остальная информация агрегируется в виде статистики. Вертикальная интеграция системы позволяет при необходимости обратиться к первоисточнику — телеметрии датчиков, видеопотокам охранного телевидения, последовательности действий сотрудников безопасности. Инциденты обрабатываются на объекте и, при необходимости координации или принятия решений, эскалируются в региональные ситуационно-аналитические центры и далее — в главный центр.
Технологическим ядром ССАЦБ является портал безопасности — единая платформа, объединяющая потоки видеонаблюдения (CCTV), контроля и управления доступом, охранно-тревожной сигнализации, навигационных и анти-БПЛА-систем, а также данные по направлениям корпоративной безопасности, включая антифрод-модули и контроль сил и средств. Ключевой акцент сделан на аналитике — автоматизированной обработке показателей, выявлении закономерностей и формировании управленческих акцентов.
В результате предприятие получает цифровую экосистему безопасности в формате «единого окна» с распределением полномочий, прозрачной эскалацией и поддержкой управленческих решений. Такая архитектура обеспечивает эффективную работу с большими массивами данных, оперативное реагирование на инциденты, снижение ущерба и повышение устойчивости бизнеса.
