 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Преимущества и недостатки гибридной архитектуры хранения данных.
Почему за этим подходом будущее?
Кейсы «Инфосистемы Джет».
Не успели банки, страховщики, промышленники и ритейлеры пожать плоды цифровизации — своих только что докрученных, оптимизированных и разогнанных DWH, — не успели наполнить озера данными и монетизировать их, как уже новые требования рынка заставляют снова менять подходы и поднимать планку гибкости, универсальности и скорости обработки информации.
Те, кто не успевают за темпом перехода на рельсы индустрии 4.0, рискуют выбыть из гонки. За последние 15 лет постиндустриальной экономики 52% компаний (260 организаций) из Fortune Global 500 покинули рейтинг, еще 40% —кандидаты на вылет.
Причиной вымирания бизнеса, как и в истории с динозаврами, становятся резкие глобальные изменения. Промышленность уступает место сфере услуг, а последняя завязана на обработке информации. Даниэл Бэл еще в 1973 году сформулировал тезисы новой постиндустриальной экономики в книге «Грядущее постиндустриальное общество»:
- создаются новые интеллектуальные технологии;
- на первое место выдвигается потребление интеллектуальных услуг;
- на смену нехватки благ приходит дефицит информации и времени;
- экономика может быть охарактеризована как информационная;
- рычаги управления сосредоточены в руках профессионалов, имеющих доступ к информации.
Именно поэтому вопросы управления данными вышли из зоны ответственности CIO и попали напрямую к CEO. Сегодня мы видим, как первые лица ведущих российских компаний, такие как Герман Греф, председатель правления ПАО «Сбербанк», Александр Дюков, председатель правления ПАО «Газпром нефть», Алексей Иванов, Президент ЕВРАЗа, становятся драйверами трансформации и говорят о ключевой роли данных в будущем их компаний.
«Цифровые активы, на мой взгляд, станут в ближайшее время одним из главных, ключевых активов и ресурсов любой компании. Если говорить об экономическом эффекте, то цифровая трансформация нашей компании, по нашим оценкам, должна приносить дополнительно каждый год не менее 20% от операционной прибыли — это порядка 200 млрд рублей».
Александр Дюков, председатель правления ПАО «Газпром нефть»
«Кроме прямой экономической выгоды, мы ставим себе и более масштабную задачу: перейти к управлению на основе данных на всех уровнях бизнеса. Мы убедились, что это не просто хайп, и к 2021 году почувствовали, что готовы масштабировать программу цифровой трансформации. Каждый из вице-президентов компании реализовал по крайней мере по одному проекту в качестве владельца продукта».
Алексей Иванов, президент ЕВРАЗа
Проследив изменившуюся роль данных в цифровой трансформации индустрии 4.0, мы видим, с какими вызовами сталкиваются компании, использующие классические архитектуру DWH, и почему гибридная архитектура хранения данных становится основным или даже неизбежным трендом следующего пятилетия. Об этих изменениях мы слышим и от бизнеса: компании объединяют разные системы, хранилища и инструменты работы с данными и управления ими в единую архитектуру.
«Мы внедрили сотни цифровых решений, и сейчас они стали складываться в комплексную систему. Они уже не могут жить по отдельности: мы связываем их с системами управления производством, выстраиваем под них новую инфраструктуру управления данными. У нас появилось понятие “умное производство”, которое подразумевает комплексную цифровизацию и автоматизацию целых блоков производственного процесса. Это следующий уровень цифровизации».
Григорий Федоришин, президент и председатель правления Группы «НЛМК»
«Чтобы весь этот «цифровой организм» работал быстро и слаженно, необходимо учитывать ряд важных факторов. Первый из них — это единая цифровая среда, единое информационное пространство, в котором во главу угла ставится работа с данными. Данные классифицируются, верифицируются и становятся основой для принятия управленческих решений. Второй — интеграция: используя цифровые монопродукты, максимальной эффективности не добиться».
Анатолий Чернер, заместитель председателя правления, заместитель генерального директора по логистике, переработке и сбыту ПАО «Газпром нефть»
Таким образом, мы видим, что сквозное объединение всех систем в единое информационное пространство с его многообразием хранилищ и типов данных неизбежно ведет к гибридной архитектуре. Ниже мы углубимся в эту тему и перейдем со стратегического уровня на тактический. Рассмотрим, как на практике мы реализуем эти задачи и с какими подводными камнями нам приходилось сталкиваться.
Что такое гибридная архитектура
Под этим термином мы понимаем архитектуру, в которой одновременно эксплуатируется несколько физических хранилищ данных, не являющихся копиями друг друга. Например, классическое хранилище с аналитическими витринами на Oracle и озеро данных на платформе Hadoop. Или когда одна часть хранилища реализована on-premise, а другая — в облаке, и для доступа к данным на физическом уровне необходимы коннекты к разным серверам и базам.
В некоторых компаниях гибридная архитектура появляется из-за того, что у подразделений возникают разные потребности в средствах хранения и обработки данных. Например, помимо общекорпоративного хранилища, маркетинг может использовать собственную систему поддержки рекламных кампаний. А аналитикам, создающим модели машинного обучения, требуется отдельная песочница на базе всеядного Data Lake. Другой повод для построения гибридной архитектуры — стоимость хранения единицы информации на разных платформах. Большие объемы сырых данных, которые используют редко и небольшое число пользователей или процессов обработки данных, лучше хранить подешевле, к примеру, в HDFS.
Также гибридная архитектура может стать следствием частичного переезда на другую платформу хранения или с on-premise в облако — когда часть данных уже на новом месте, а что-то осталось на прежнем. Иногда это временное явление (которое, тем не менее, может растянуться на месяцы и даже годы), но зачастую переносить на новую платформу устаревшие legacy-системы просто не имеет смысла, и они остаются доживать свой век на старом месте. Кроме того, всевозможные слияния и поглощения компаний обычно пополняют список legacy-систем и добавляют архитектуре гибридности. Помимо этого, причиной географически распределенного хранения данных может стать разветвленная филиальная сеть компании. Информацию не всегда можно централизовать физически, например, если у компании есть зарубежные филиалы или из-за требований законодательства о локализации данных. Соответственно, нужно строить гибридную архитектуру.
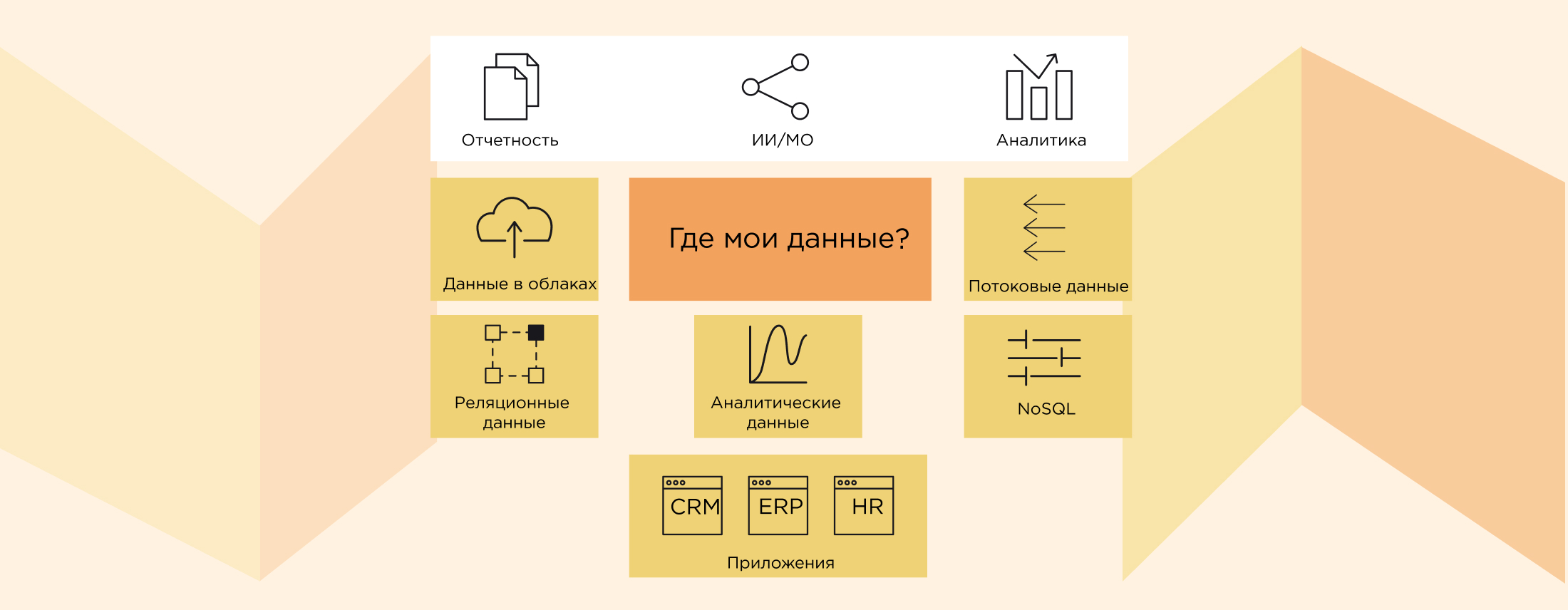
Рассмотрим несколько примеров реализации гибридной архитектуры хранения данных. Возьмем кейсы из разных отраслей — телеком, банк и промышленное предприятия с IoT — и заодно посмотрим, как работает виртуализация в гибридной архитектуре.
Кейс № 1: телеком-компания
Гибрид из трех компонентов: КХД Oracle Exadata, кластера Big Data (Hadoop, Spark, Hive) и Teradata.
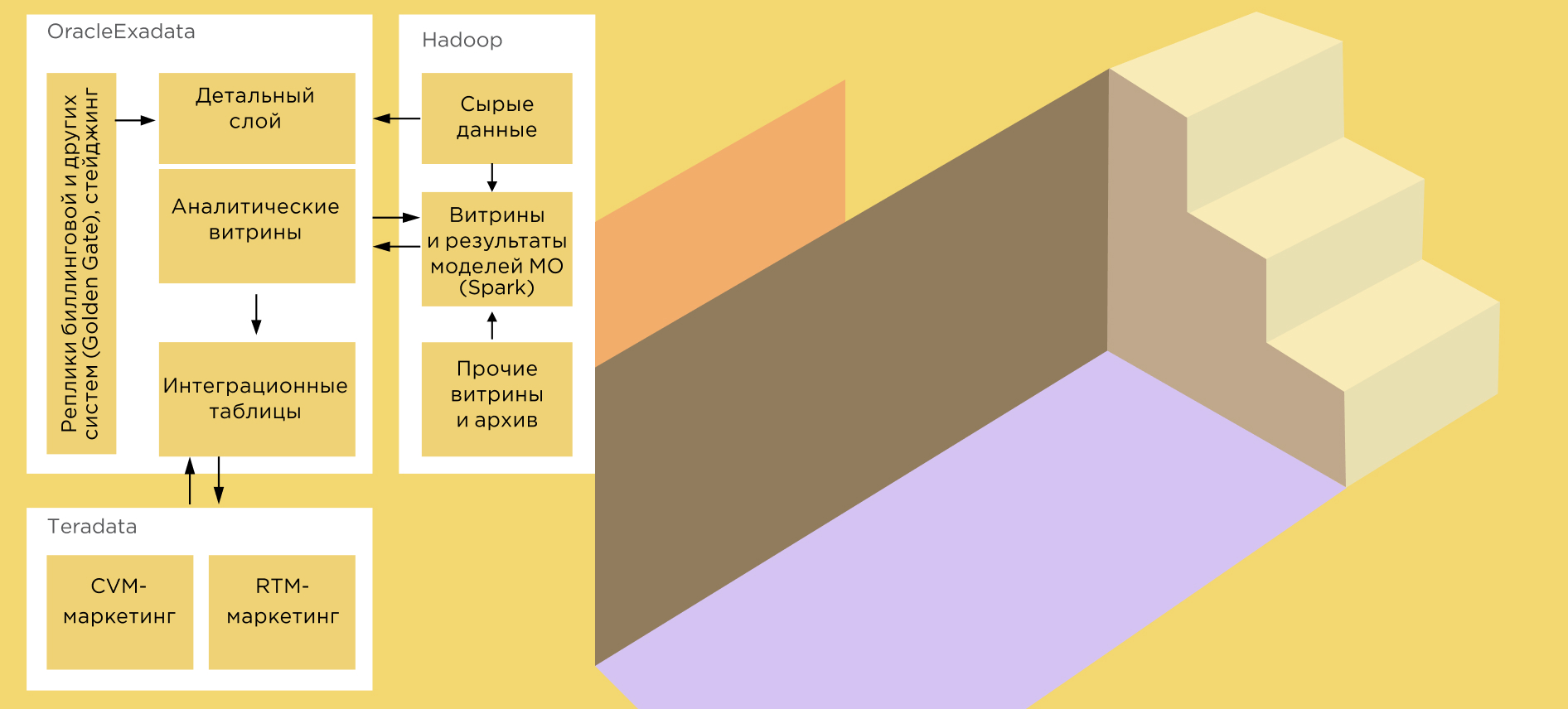
В этом кейсе процессы хранения и обработки данных распределены по трем системам.
Классическое хранилище с витринами данных на основе Oracle Exadata. Общекорпоративное хранилище, которым пользуются многие подразделения компании. Основной источник для BI-систем, содержит как детальные (например, звонки абонентов), так и агрегированные данные (абонент, клиент, услуга, тарифный план, регион, день, неделя, месяц и т. д.).
Кластер Big Data на основе Hadoop, Spark и Hive. Озеро данных позволяет:
- Обучать и эксплуатировать модели машинного обучения.
- Хранить и обрабатывать большие объемы сырых данных, например, записи CDR (Call Detail Record) с телекоммуникационного оборудования.
- Содержать архив данных, в котором, к примеру, хранится информация, уже удаленная из корпоративного хранилища.
Система поддержки маркетинговых кампаний на основе Teradata. Специализированная система, поддерживающая CVM (Customer Value Marketing) и RTM (Real-Time Marketing).
Преимущества подобной архитектуры:
- Каждая из трех систем сфокусирована на задачах, в которых проявляет свои сильные стороны. Корпоративное хранилище быстро предоставляет аналитические данные и регламентную отчетность, озеро данных дешево хранит большие объемы информации и помогает работать аналитикам, маркетинговая система решает специализированные задачи.
- Нагрузка на вычислительные ресурсы распределена, поэтому задачи, выполняющиеся в разных системах, не конкурируют друг с другом. При этом каждая из систем является кластером и поддерживает горизонтальное масштабирование — при необходимости в любую из них можно добавить вычислительные ресурсы.
- Системы дополняют друг друга. Например, стейджинг и первая стадия обработки большого объема сырых данных могут проходить в озере данных, а аналитические витрины — строиться уже в корпоративном хранилище данных. Или наоборот: детальные данные по абонентам можно держать в хранилище, а витрину с рассчитанными признаками (features) абонентов для моделей машинного обучения реализовать в озере.
Но у этой архитектуры есть и «темные стороны»:
- Данные отчасти дублируются. Например, в каждой из трех систем есть список абонентов с основной атрибутикой. Из этого вытекают традиционные минусы нескольких экземпляров одних и тех же данных — они могут быть несинхронизированы как по контенту, так и по структуре. В этом кейсе для синхронизации разработаны и используются дополнительные механизмы регулярного автоматического копирования данных из одной системы в другую или сразу в обе. В случае изменения структуры данных системы-источника может потребоваться доработка интеграции с системами-приемниками.
Потребители данных должны учитывать, в какой из систем содержатся нужные данные. Если необходимая информация находится сразу в нескольких системах, придется выяснить, это одни и те же данные или нет, и в чем между ними разница. В этом сотрудникам помогает документация по структурам данных и ETL-процессам, размещенная во внутренней базе знаний.
- Для администрирования каждой системы нужны отдельные знания.
Кейс № 2: промышленная компания
Гибрид on-cloud и on-premise на основе Greenplum, ClickHouse и S3
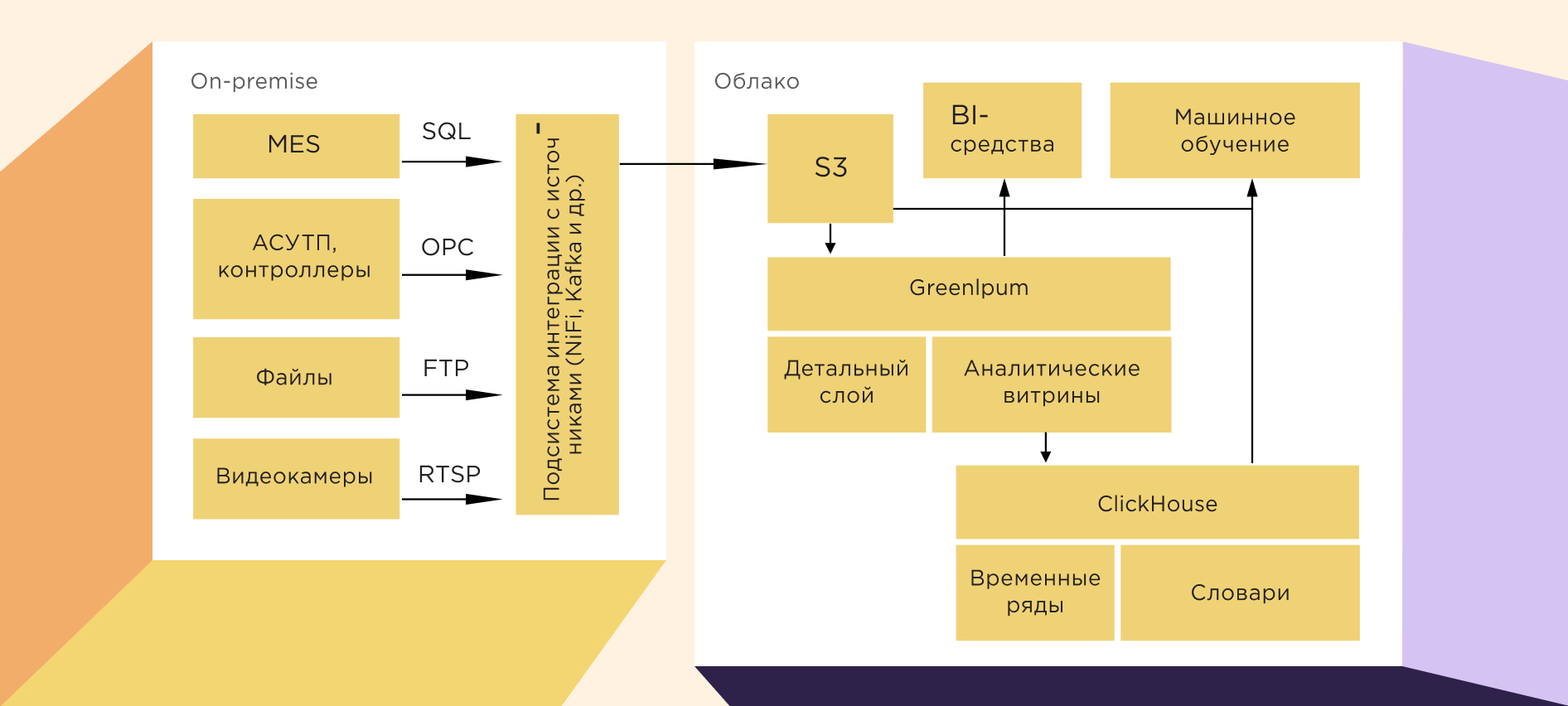
Пример гибрида из новой реальности: когда начались проблемы с железом, на сцене всеми красками заиграли облачные решения. В данном случае хранение и обработка технологических данных распределены между on-premise и облаком.
АСУ ТП и MES (Manufacturing Execution System) реализованы on-premise — вместе с подсистемой для получения из них изменившихся данных в пакетном или потоковом режимах. Собственно, хранилище данных расположено в облаке и состоит из трех подсистем:
- Хранилище технологических данных на основе Greenplum. Содержит как детальные данные технологических процессов, так и аналитические витрины. Основной источник информации для BI-систем.
- Хранилище данных временных рядов на основе ClickHouse. Содержит данные временных рядов, обогащенные атрибутами таких сущностей, как единица готовой продукции, участок цеха, агрегат, заказ, клиент и др. Обеспечивает решение аналитических производственных задач на больших объемах данных.
- Файловое хранилище на основе S3. Выполняет несколько функций: стейджинга для временного хранения изменившихся данных из источников, архива и песочницы для аналитиков (совместно с Greenplum).
Плюсы архитектуры:
- Горизонтальное масштабирование всех подсистем хранения, динамическое выделение ресурсов в облаке в зависимости от нагрузки.
- Специализированное решение для работы с временными рядами, т. е. с большим объемом данных с однократной записью, связанных с различными справочниками (словарями). Именно на этой задаче ClickHouse раскрывается с лучшей стороны.
- Дешевизна хранения, гибкость и всеядность S3, необходимая аналитикам машинного обучения.
- Отсутствие затрат на администрирование — квалифицированные специалисты не требуются.
К минусам можно отнести:
- Требуется дополнительная подсистема для интеграции источников данных on-premise и хранилища в облаке.
- Для связи с облачным провайдером необходим надежный канал с высокой пропускной способностью.
- Потребители данных, которым одновременно нужны данные из облака и on-premise систем, вынуждены так или иначе сводить их самостоятельно: с помощью MS Excel, Tableau и т. д.
Кейс № 3: банк
Классический гибрид Data Lake и DWH
При реализации нового функционала анализа данных в DWH заказчик регулярно сталкивался с проблемами. Это и растущие расходы на хранение больших объемов информации, и громоздкость структур, и, как следствие, сложности в управлении и поддержке существующих классических моделей (при добавлении новых сущностей, атрибутов и/или источников данных). Все это приводило к проблемам с Time-to-Market.
Для решения задачи мы внедрили заказчику озеро данных, которое соответствовало трем ключевым требованиям:
- Доступность данных. Теперь Data Scientist может сразу взять необходимые данные и построить модель, не дожидаясь выгрузки dataset’ов по согласованным регламентам.
- Гибкость работы с данными. Достигается за счет инструментария Cloudera Data Platform и Informatica Data Engineering Integration. Для реализации аналитической платформы использовалась многоуровневая архитектура (LSA — Layered Scalable Architecture).
- Минимизация затрат на внедрение и поддержку хранилища. Достигается за счет использования кластера Hadoop. Горизонтальная масштабируемость позволяет увеличить объем сбора данных даже в 100 и более раз, при этом наращивание мощностей будет проводиться без серьезных изменений в архитектуре системы.
В ходе проекта были решены задачи по обеспечению необходимого уровня ИБ, контролю и разграничению доступа к данным, обработке персональных данных и данных, содержащих коммерческую тайну. Также мы настроили протокол Kerberos, модули Ranger и Atlas.
К платформе данных подключены 80% систем, которые хранят информацию о клиентах (физических и юридических лицах). На ее основе запущен проект построения цифрового профиля клиента. Также к системе подключены внешние сервисы с данными из открытых источников. Дата-аналитики банка самостоятельно находят необходимую информацию в озере, что в конечном счете ускоряет процесс обслуживания клиентов. К тому же теперь банк готовит более точные персонализированные предложения.
Платформа реализована на гибкой архитектуре, в которую заложены возможности развития и трансформации под запросы бизнеса, добавления новых систем и источников, а также миграции на новое железо без потери данных и функциональности. Разработанная инфраструктура и инструментарий CI/CD обеспечивают подключение новых систем-источников данных за 2–3 месяца.
Обеспечена возможность хранения структурированных и неструктурированных данных, разработаны описания структур хранилища. Заказчик может регулировать доступ к данным, пользоваться инструментами продвинутой аналитики и создавать управленческие отчеты. При этом получение информации и операции с ней осуществляются мгновенно.
Таким образом, применение гибридной архитектуры позволило создать платформу Big Data, в которую входит комплекс информационных систем. Его ядром служит озеро данных, по мере растущих запросов бизнеса постепенно увеличивается взаимосвязь Data Lake с DWH банка.
Среди сложностей, возникших при внедрении, стоит выделить оргвопросы при переводе сотрудников на новые инструменты, настройку параметров ИБ и особенности работы с виртуальной средой Citrix: в нашем случае там стоял запрет на любые действия по копированию и переносу настроек и конфигураций для пользователей.
Виртуализация в гибридной архитектуре
Давайте посмотрим, как виртуализация применима в «гибридах».
Присущие гибридной архитектуре недостатки, связанные с дублированием или географической распределенностью данных, можно отчасти преодолеть, разместив над несколькими хранилищами данных слой виртуализации. Он скрывает от потребителей данных физическое расположение информации и предоставляет единую точку входа и «версию правды» для всех данных. Они по-прежнему хранятся в разных системах, но выглядят как единая виртуальная база, с которой можно взаимодействовать с помощью SQL-запросов. Платформа виртуализации преобразует пользовательские команды к источникам данных, получает ответы, при необходимости выполняет дополнительную обработку и возвращает результат.
Сегодня среди ведущих средств виртуализации можно выделить Denodo Platform.
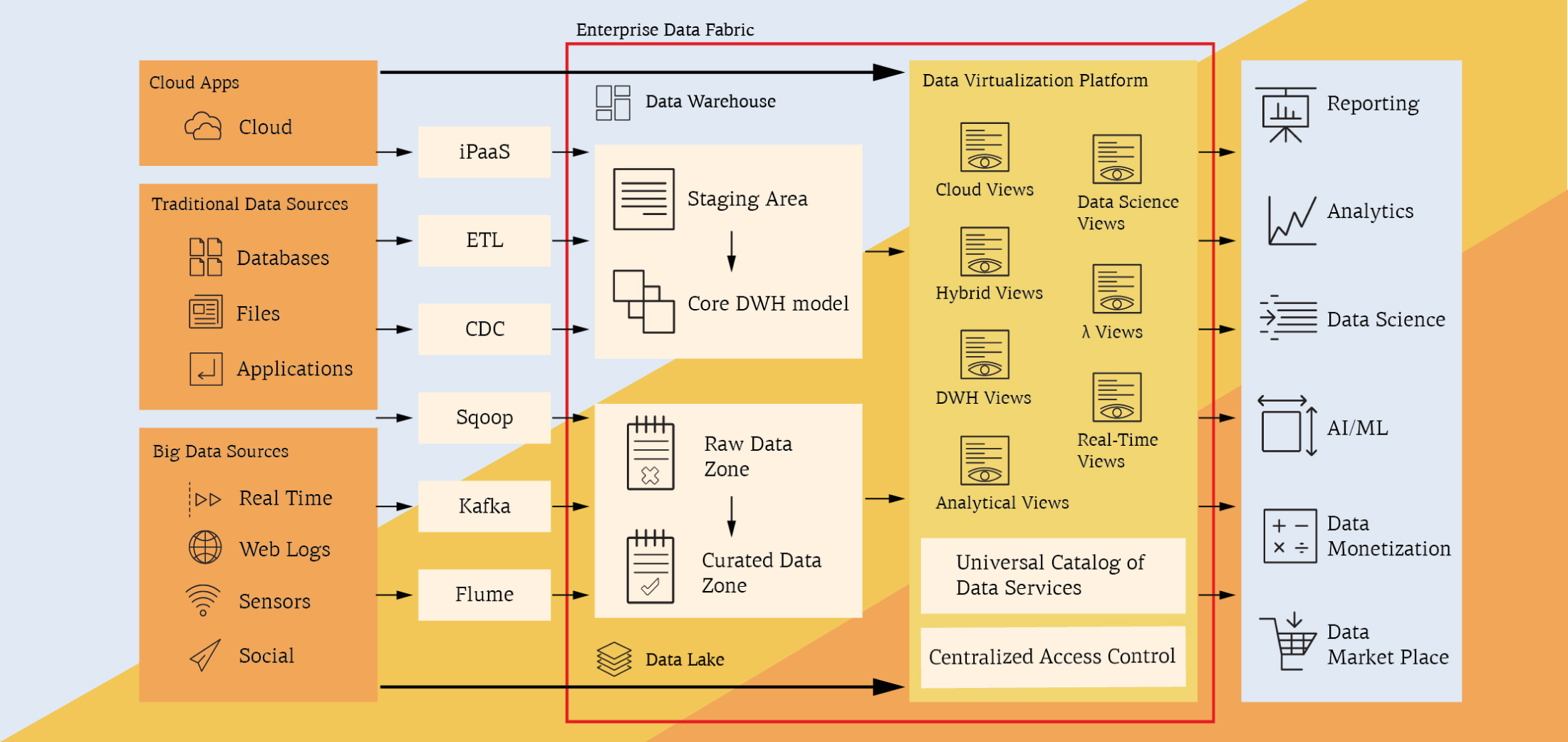
Платформа виртуализации Denodo позволяет:
- Предоставить потребителям логическое хранилище с единой моделью данных без физического перемещения информации.
- Обеспечить единую точку входа и управления доступом к данным (аутентификация, авторизация) в разных системах. Разграничить доступ к данным на уровне как отдельных представлений, так и колонок, строк и ячеек, а также выполнить маскирование данных источников.
- Обеспечить потребителей информацией о том, какие данные доступны им через платформу, каково происхождение тех или иных атрибутов, каковы примеры данных. Все это позволяет пользователю быстро найти нужные ему данные. Таким образом, платформа виртуализации позволяет построить гибкий, быстрый и доступный сервис самообслуживания для обычных пользователей.
- Провести плавную миграцию хранилища с одной платформы на другую (или с on-premise в облако) незаметно для пользователей в удобном для вас темпе. Для потребителей данные по-прежнему будут находиться в виртуальной БД.
- Встроить разнообразные источники данных в общую микросервисную архитектуру через полуавтоматическое создание типовых веб-сервисов (например, REST API) над их данными.
- Задействовать мощности имеющихся MPP-систем (Hadoop, Teradata, Exadata и др.) для ресурсоемких запросов по обработке больших объемов данных из разных источников.
Выводы
Мы рассмотрели факторы и причины возникновения гибридных архитектур хранения данных в разных компаниях, их связь с переходом на постиндустриальную экономику и цифровую трансформацию 4.0 Увидели, какую важную роль играют для CEO компаний данные и инструменты работы с ними, а также почему гибридные хранилища становятся все популярнее.

