 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Какие ограничения имеет шкала CVSS, традиционно применяемая для ранжирования ИБ-угроз?
Чем data scientists могут помочь специалистам по информационной безопасности?
Как граф связанной информации помогает классифицировать уязвимости?
Когда вы сталкиваетесь с новой уязвимостью, какая мысль приходит первой? Конечно, отреагировать как можно быстрее. Однако скорость — всего лишь одно из условий эффективной борьбы с ИБ-угрозами. Когда речь идет о корпоративной безопасности, не менее важно безошибочно определять, на что стоит реагировать в первую очередь.
Для ранжирования уязвимостей по различным критериям — от сложности эксплуатации до наносимого вреда — традиционно применяется шкала CVSS (Common Vulnerability Scoring System) (рис. 1).
Но у CVSS есть слабое место: она строится на экспертных оценках, не подкрепленных реальной статистикой. Гораздо эффективнее было бы предлагать экспертам уже отобранные по определенным количественным критериям кейсы, чтобы решения принимались на основании проверенных данных. Где их взять и как верно интерпретировать? Это нетривиальная задача для датасаентиста. Именно этот вызов вдохновил команду QIWI совместно с проектом Vulners создать новую концепцию оценки и классификации уязвимостей на основе графа связанной информации.
На заметку
Почему именно графы? Они давно применяются для анализа социальных сетей и СМИ — от оценки распространения контента в новостном потоке и влияния топовых авторов на мнение читателей до кластеризации соцсети по интересам. Любая уязвимость может быть представлена как граф, содержащий данные (новости об изменениях в software или hardware и вызванных ими эффектах).
О данных
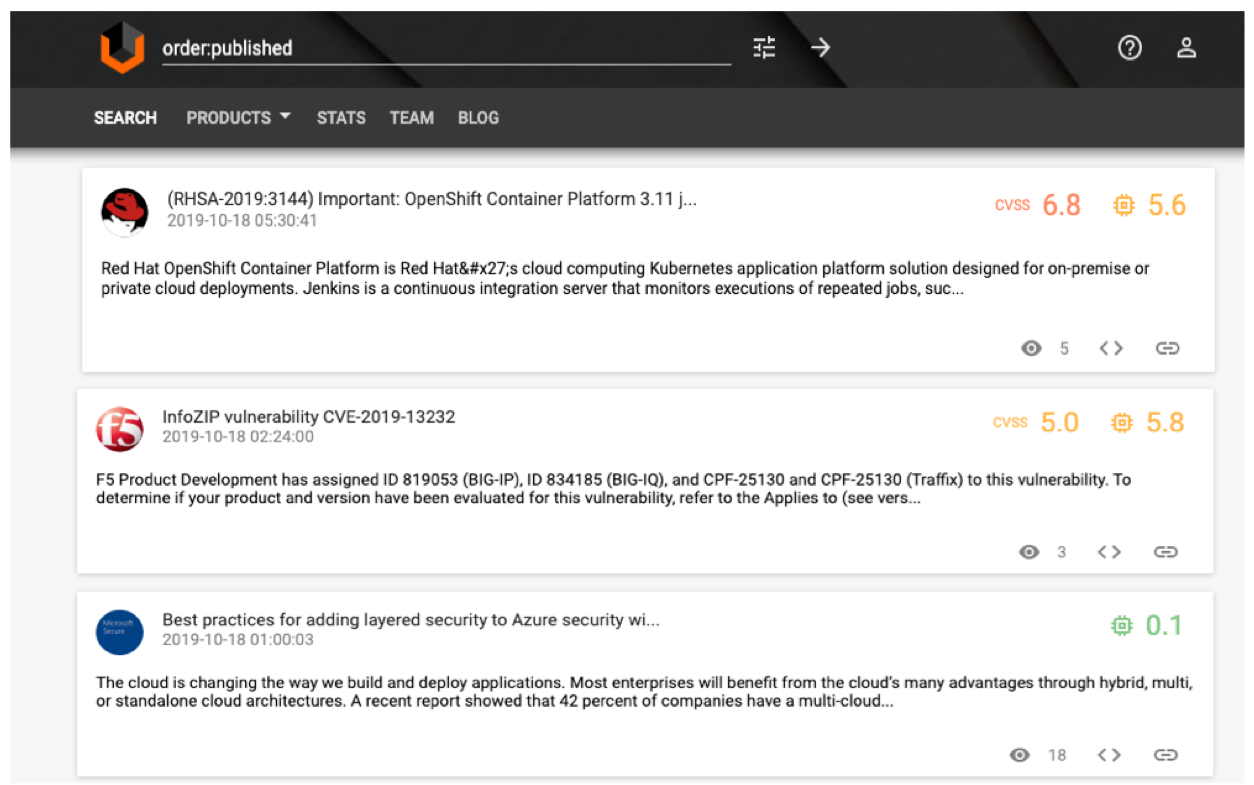
Нам не пришлось вручную собирать новости об угрозах ИБ, все необходимые тексты содержала открытая база vulners.com (рис. 2).
Каждая уязвимость в базе, помимо названия, даты публикации и описания, имеет присвоенные ей тип (CVE, nessus и др.), семейство (NVD, scanner, exploit и др.), оценку CVSS (здесь и далее используется CVSS V2.0). Также указаны ссылки на связанные новости.
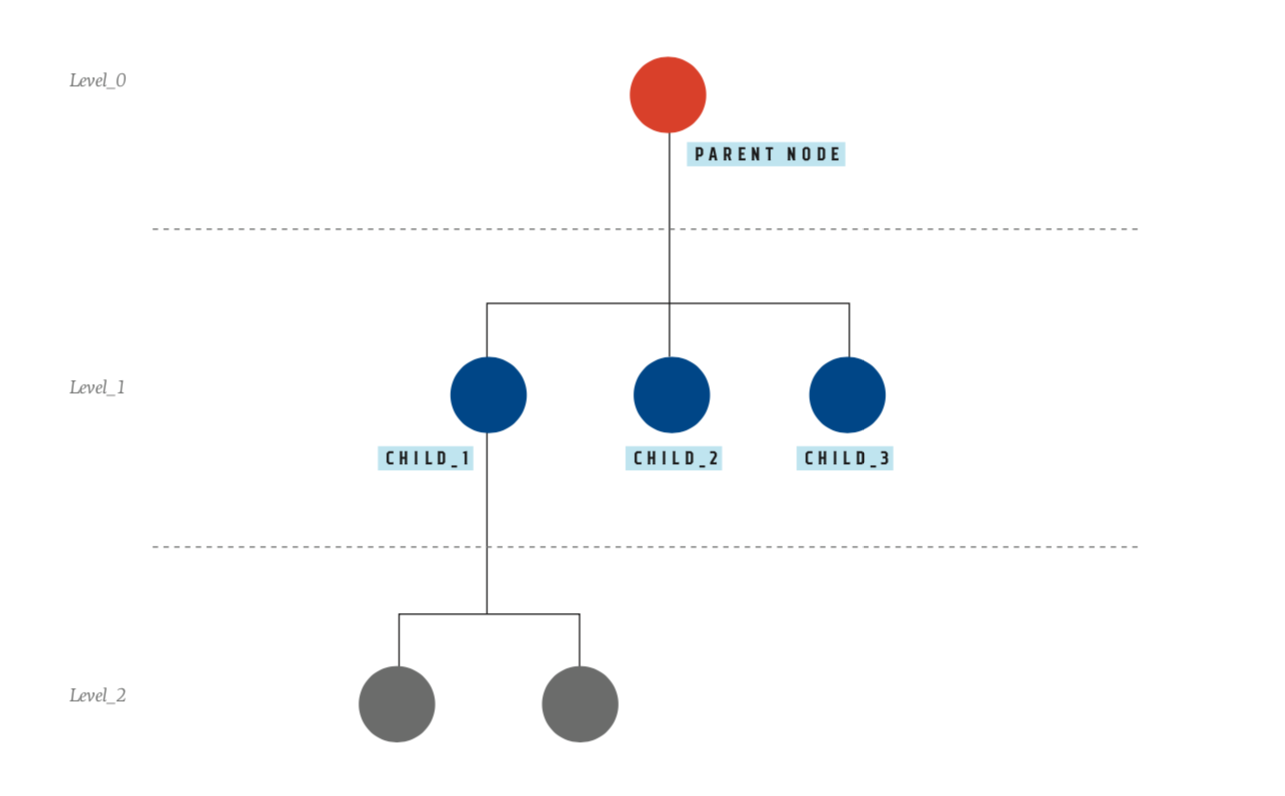
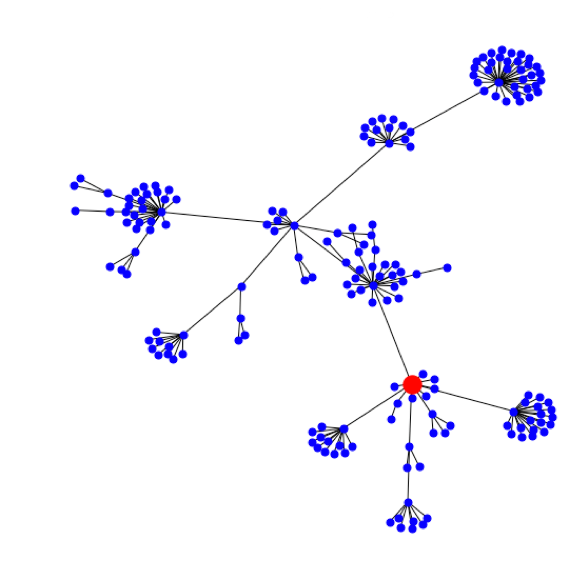
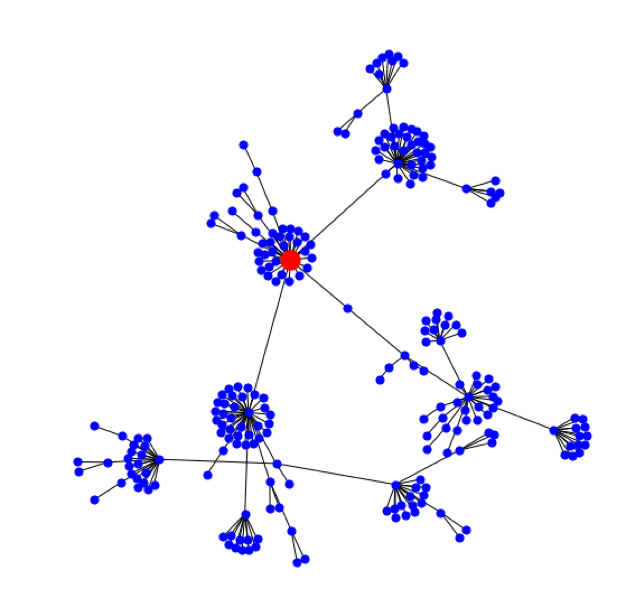
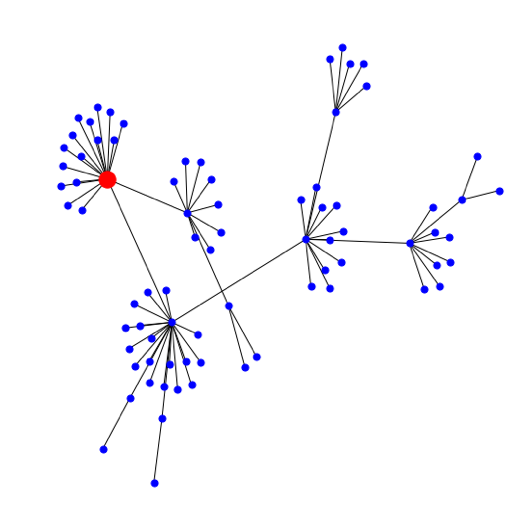
Если представить эти связи в виде графа, то каждая уязвимость будет выглядеть следующим образом (рис. 3): оранжевый кружок обозначает исходную, или родительскую, публикацию, черные кружки — новости, на которые можно кликнуть, находясь на родительской страничке, а серые — связанные новости, до которых можно добраться, только пройдя по публикациям, обозначенным черными кружками. Каждый цвет — это новый уровень графа связанной информации: от нулевого (исходной уязвимости) до первого, второго и т.д.
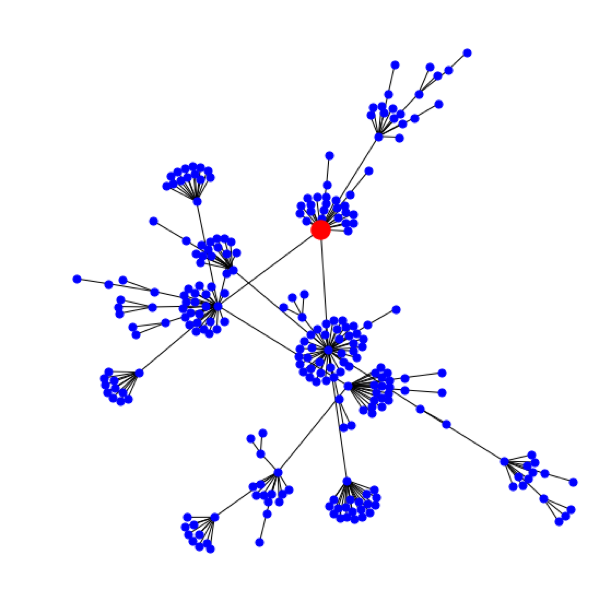
Конечно, при просмотре одной новости нам известны только нулевой и первый уровень. Поэтому для получения всех данных мы использовали метод обхода графа в глубину, позволяющий распутать клубок новостей от начала до самых последних связанных узлов (далее — нод графа). Как выглядят графовые данные? На рис. 4 мы представили граф известной, но не очень опасной уязвимости Heartbleed (5 из 10 баллов по шкале CVSS V2.0).
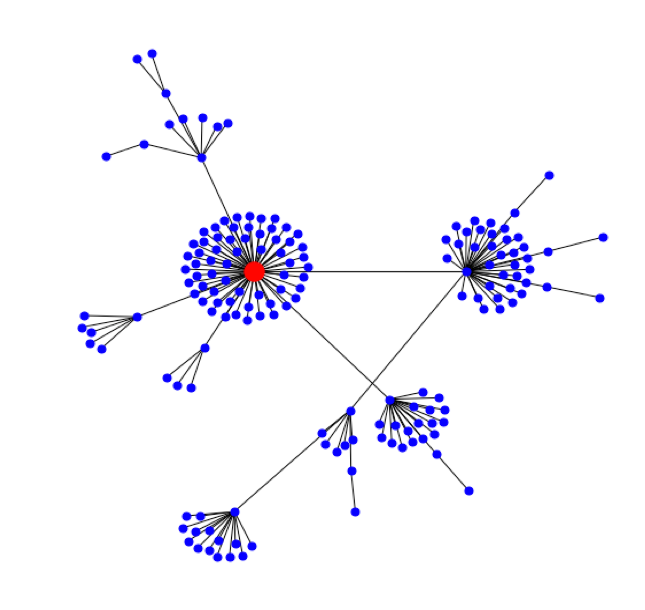
Глядя на этот пышный «букет» из связанных новостей и эксплойтов, где красная точка — исходная уязвимость, мы понимаем, что Heartbleed был существенно недооценен. Этот пример показывает, что графовые метрики качественно оценивают системность, продолжительность и другие параметры уязвимости. Ниже мы приведем несколько кейсов из нашего исследования, которые послужили базой для разработки альтернативной классификации:
- число нод в графе отвечает за «широту» уязвимости и показывает, насколько большой след она оставила в различных системах;
- число подграфов (крупных скоплений новостей) отвечает за гранулярность проблемы или наличие крупных проблемных зон для ИБ-специалистов внутри уязвимости;
- число связанных эксплойтов и патчей говорит о взрывоопасности уязвимости и о том, сколько раз ее приходилось «лечить»;
- количество типов и семейств новостей в графе — о системности, то есть числе подсистем, затронутых влиянием уязвимости;
- время от первой публикации до первого эксплойта и до последней связанной новости — о темпоральной природе уязвимости, тянется ли она с большим «хвостом» последствий или быстро развивается и затухает.
Конечно, это не все наши метрики, «под капотом» исследования сейчас порядка 30 показателей, дополняющих базовый набор критериев CVSS V2.0.
Открываем серую зону
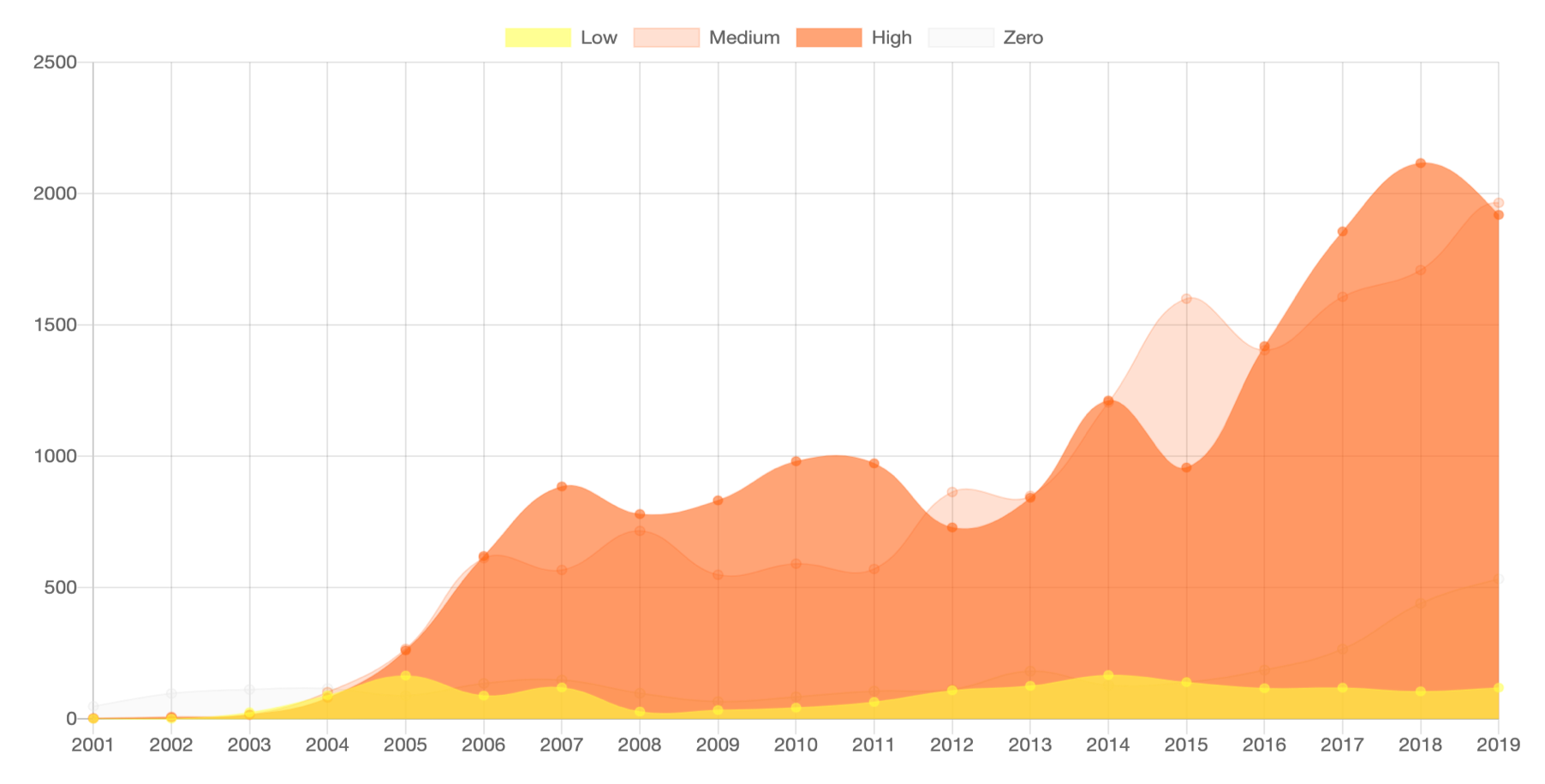
А теперь немного Data Science и статистики, ведь гипотезы нужно подтверждать на данных. Для эксперимента с альтернативной шкалой и новыми метриками мы отобрали новости, опубликованные в январе 2019 г. (2403 бюллетеня и более 150 тысяч строк в графе новостей). Все исходные уязвимости были разделены на 3 группы по CVSS:
- High — от 8 баллов включительно;
- Medium — от 6 (включительно) до 8 баллов;
- Low — менее 6 баллов.
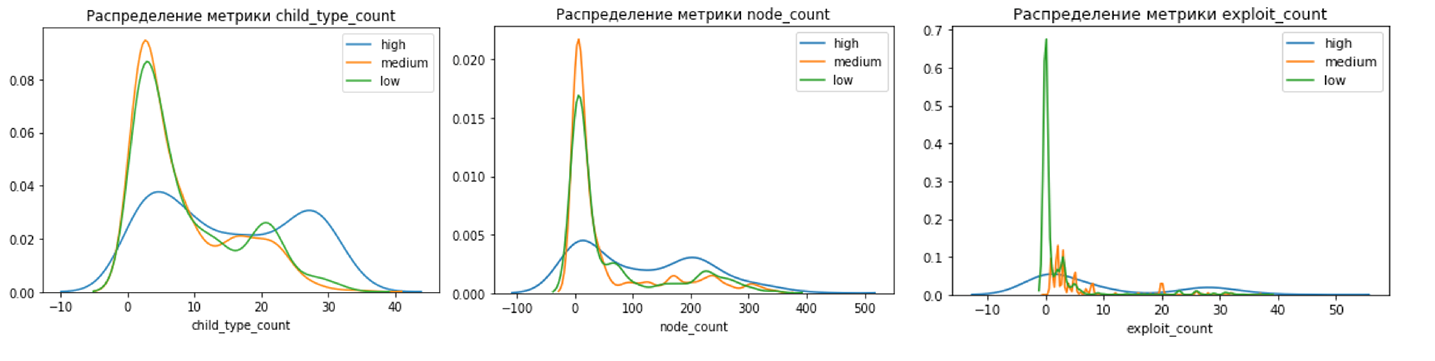
Для начала мы проверили, как CVSS-балл коррелирует с числом и типом связанных новостей в графе, а также с числом эксплойтов (рис. 5). В идеале мы должны были увидеть четкое разделение метрик на 3 кластера, однако этого не произошло. Это указало на возможное наличие серой зоны, которую CVSS не определяет.
Затем мы провели кластеризацию уязвимостей, сгруппировав их в однородные группы, и построили новую шкалу. Для первой итерации был выбран метрический классификатор и получена новая матрица оценок: по оси X — класс уязвимостей, где 2 — максимально крупные по нашим метрикам, 1 — новые уязвимости, 0 — самые маленькие; по оси У — исходные баллы (High, Medium, Low) (рис. 6).
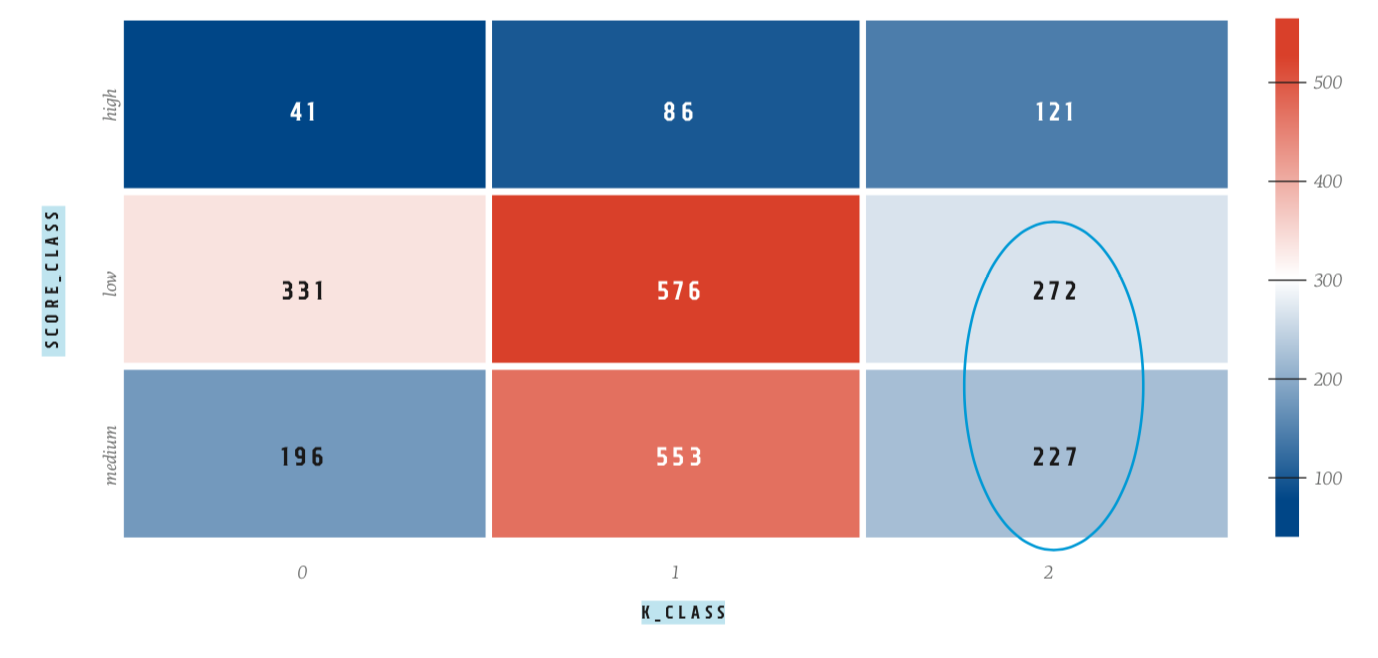
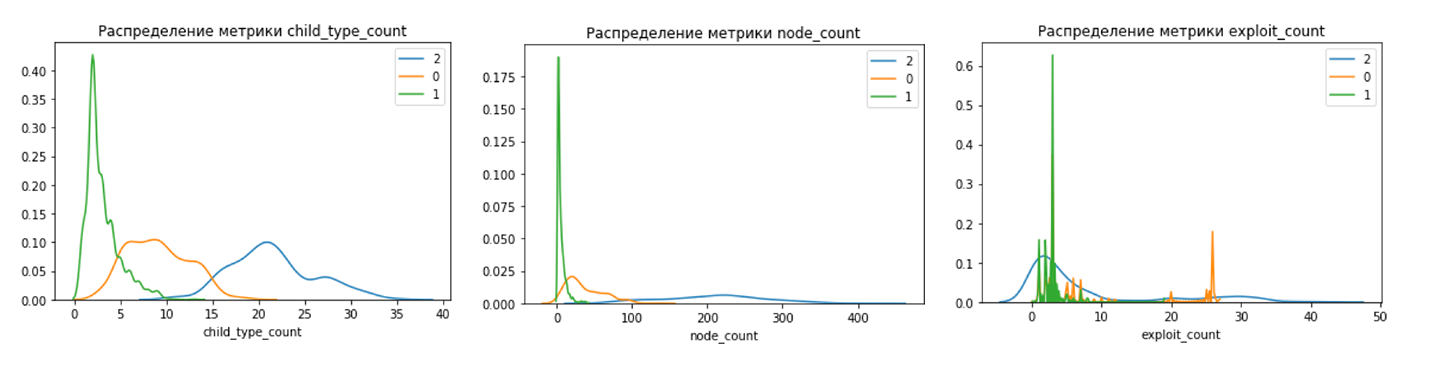
На рис. 6 зона, помеченная овалом (класс 2 с первоначальными оценками low & medium), — потенциально недооцененные уязвимости. Разделение на новые классы выглядит более четким по сравнению с CVSS, чего мы и добивались (рис. 7).
Однако просто доверять модели — плохая идея. Мы точечно проверили ее, взяв несколько уязвимостей для детального анализа. На рис. 8–11 представлены яркие образцы из серой зоны. Они имеют низкий балл CVSS, но высокий графовый балл, а значит, потенциально требуют другого приоритета работы с ними.



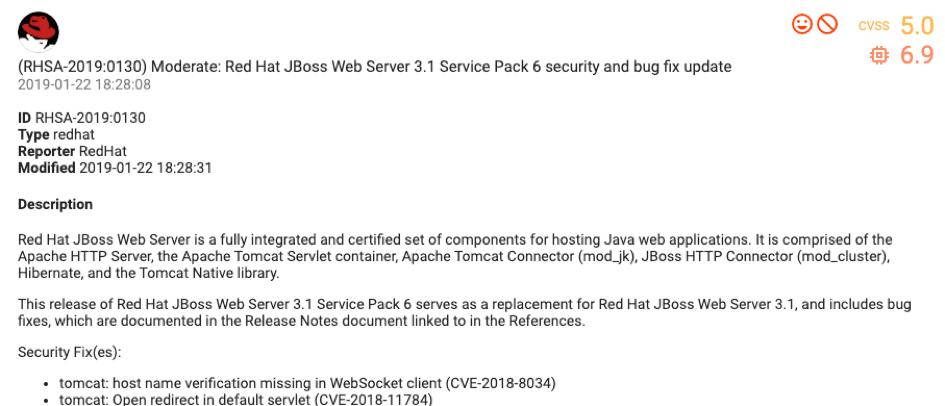
RHSA-2019:0130 (балл CVSS — 5,0, графовый класс 2 — high)
Концепция была подтверждена статистикой и точечной проверкой. В ближайшем будущем мы планируем автоматизировать сбор графовых метрик, а также реализовать production-версию нашего классификатора, чтобы команда ИБ использовала его в работе с уязвимостями. На этом пути еще много вызовов — от сбора огромного числа новых графов по не охваченным в исследовании месяцам до оптимизации модели.
Наш кейс показывает, что data driven и information security отлично дополняют друг друга.
В заключение
Хочу еще раз подчеркнуть роль, которую играют данные и их доступность для data scientists. Они позволяют проверить самые смелые гипотезы и лучше понять суть предметной области. Главное — не ограничиваться общепринятыми рамками. Поэтому, если вы еще не собираете или удаляете «ненужные» данные, задумайтесь: каждый байт можно использовать эффективно.


Павел Волчков
заместитель директора Центра информационной безопасности компании «Инфосистемы Джет»
Комментарий
Этот кейс будет интересен крупным компаниям, уделяющим внимание теме Vulnerability Management. Именно крупным, потому что одна из основных проблем ИБ-специалистов связана с приоритизацией уязвимостей. Что вообще нужно устранять? Что из этого — в первую очередь? Где и в какой срок необходимо закрыть самые критичные уязвимости? Ответы на эти вопросы невозможно найти, применяя шаблонные методики Vulnerability Management «в лоб». Использование кастомных наработок, подобных той, что была реализована в QIWI, дает прямую экономическую выгоду за счет сокращения времени, затрачиваемого на исправление уязвимостей, которые по факту таковыми не являются. Сама идея выглядит свежей и интересной. Вопрос, как это часто бывает, — в полноте ее реализации, а также в том, все ли значимые исходные параметры были учтены. На мой взгляд, для того чтобы использовать этот инструмент в повседневной деятельности ИБ-подразделения, его необходимо доработать.