 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Однако инфраструктура не нужна сама по себе: её разворачивают ради прикладных решений, приносящих реальную пользу компании. Несмотря на поток новых технологий, фундаментальные основы построения прикладных решений в последние десятилетия менялись мало. И вот мы являемся свидетелями того, как новые технологии в инфраструктуре – программно-определяемые ЦОД и облачные сервисы – начинают трансформировать подход разработчиков к построению ИС.
Масштабируемое приложение – что такое и зачем
Сегодня термины «облака» и «облачные технологии» встречаются буквально на каждом шагу. Каждый понимает их по-своему: кто-то считает, что это очередные громкие слова, за которыми ничего не стоит, а кто-то – что это технологии, перевернувшие ИТ-индустрию. Не претендуя на охват темы целиком, мы предлагаем «пощупать этого слона» с одной стороны: как облака могут изменить архитектуру прикладных информационных систем?
Есть ли способы определить, что конкретная система может выиграть от применения в ней облачных технологий? Есть ли какие-то характерные признаки того, что именно вашу систему стоит развивать в облаке? Придётся ли что-то менять в существующей системе или в подходе к разработке новой, чтобы получить отдачу от облака? В нашей статье мы ищем ответы на эти вопросы. Но для начала нужно разобраться с тем, что такое cloud-среда.
Общепринятое определение облачного сервиса принял Американский национальный институт стандартов и технологий. Сервис должен обладать определенными признаками.
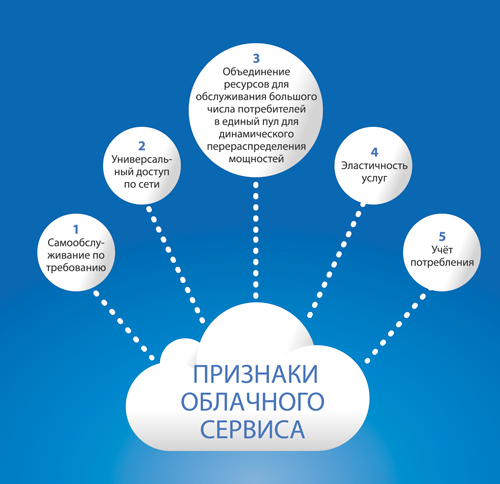
Для разработчика системы это прежде всего означает, что теперь можно динамически менять «размер» ИС: добавлять новые ресурсы, в первую очередь, вычислительные (процессор/память) и ресурсы хранения (дисковое пространство или сервисы хранения) или отказываться от тех из них, что стали не нужны.
Облака впервые позволили решить старую и больную проблему масштабирования приложений. Типичный пример её появления выглядит так: предположим, вы создаёте коммерческий сервис, обслуживающий пользователей. В сервис вы заложили архитектуру, позволяющую легко масштабировать его горизонтально, например, добавлением серверов приложений с балансированием нагрузки. Но сколько серверов вам, собственно, нужно развернуть при запуске сервиса? Вы решаете, что пока пользователей мало, достаточно двух, а дальше, по мере роста пользовательской базы, вы будете добавлять машины. Вы запускаете сервис, к вам приходят первые пользователи, всё идет прекрасно. О вас даже написали на Хабре, Slashdot’е или Википедии. Через два часа вместо первой сотни пользователей к вам наведываются сто тысяч. И девяносто девять из них, включая журналистов, потенциальных инвесторов или реальных заказчиков, увидят вместо сайта с вашим сервисом таймаут, или внутреннюю ошибку, или ещё что-нибудь столь же неприятное.
Наивная альтернатива этому сценарию – заранее продумать максимальную нагрузку и запускать сервис на аппаратной платформе, рассчитанной под нее: например, вместо двух серверов – пятьдесят или пятьсот. И все они 99% времени будут проедать электричество и деньги на вашем хостинге, простаивая в ожидании того самого пикового всплеска посетителей, который может и не случиться.
Если Хабр или Википедия кажутся вам надуманными источниками нагрузки, возьмем другой пример – интернет-магазин по продаже цветов. 360 дней в году его нагрузку выдержит один сервер, со всем front-end’ом, с приложением, базой данных и аналитикой. А оставшиеся дни – накануне 1 сентября и 8 марта – понадобятся пять серверов. Или пятьдесят. Причём плановое подключение-отключение серверов – тоже не панацея: можно ошибиться, во-первых, с оценкой сайзинга, во-вторых, с планированием нагрузки (например, бывает ещё – неожиданно – 14 февраля).
Даже если вы успели заметить рост нагрузки и готовы оперативно подключать/отключать новое оборудование, всё равно «оперативно» здесь измеряется в лучшем случае часами. Реальному миру свойственны проблемы с логистикой.
С появлением облачных сервисов эту проблему можно легко решить. Ваш сервис должен масштабироваться по горизонтали и позволять отслеживать свою загрузку, а также реагировать на её изменение. Тогда можно снабдить его несложной логикой вида «если в последние 30 секунд загрузка серверов приложений выше пороговой, добавить ещё один сервер; если в последние 2 минуты загрузка серверов приложений ниже пороговой, убрать один сервер».
Слово «легко» в предыдущем абзаце, конечно, надо воспринимать с изрядной долей юмора. Чтобы это стало действительно легким, ваша система должна быть с самого начала спроектирована с учётом возможности переезда в облако. В первую очередь это означает – используйте слабо связанные сервисы везде, где только можно. Один из первопроходцев облачных технологий компании Amazon Джефф Безос, говорят, в определенный момент издал всем командам разработки указ, смысл которого сводился к следующему:
- все команды публикуют свои данные и функциональность через сервисные интерфейсы;
- все команды обязаны взаимодействовать через эти интерфейсы;
- не допускается никакой другой формы межпроцессных коммуникаций: никакой прямой линковки, никакого прямого чтения из хранилища данных другой команды, никакой разделяемой памяти, никаких других «чёрных входов». Единственный разрешённый способ – сетевые вызовы сервисных интерфейсов;
- не имеет никакого значения, какую технологию использует та или иная команда;
- все сервисные интерфейсы без исключения обязаны проектироваться так, чтобы их можно было публиковать для использования разработчиками во внешнем мире.
Заканчивался указ следующей фразой: «Любой, кто этого не сделает, будет уволен. Благодарю Вас, удачного дня. Джефф Безос».
И посмотрите, где сейчас бывший книжный интернет-магазин Amazon.
Надёжные сервисы на ненадёжной инфраструктуре
Вынесение сервисов в облако имеет ещё одно фундаментальное отличие от привычной модели разработки. Это отношение к отказам. Старый подход заключается в том, что мир вокруг разработчика, в общем-то, безоблачен и безотказен. А отказ, если он все же случается, – это повод выбросить белый флаг и сдаться: «невозможно установить соединение – извините, повторите ваш запрос позже». Новый подход состоит в том, что отказы случаются постоянно и с ними нужно уметь работать так же, как мы работаем с разными значениями входных данных. Например, поиск Google работает на колоссальных размеров вычислительной ферме, часть которой (кажется, процентов десять) не функционирует (сломано, отключено, в плановом обслуживании). Google использует самые дешёвые аппаратные компоненты и легко заменяет их новыми при отказе. Что нужно, чтобы это работало? Программные компоненты должны стоически переносить эти отказы.
Для этого разработано множество технологий: кластеризация, обеспечивающая работу системы, пока поддерживается минимальный кворум сервисов; службы каталогов, дающие возможность динамически искать в сети работающие сервисы; репликация данных, позволяющая иметь избыточное количество доступных данных на случай отказа.
Но самое главное – мысль об обработке отказов должна всё время быть в голове у разработчика. Эфемерные экземпляры сервисов могут создаваться и удаляться подсистемой мониторинга из-за изменения нагрузки на систему. Сервисы могут просто отказывать и переставать работать. Они могут становиться недоступными (а потом снова доступными) из-за проблем с сетевой связностью. Недоступность сервиса, обрыв соединения, внутренняя ошибка – это одинаково вероятные события, реакцией на которые должно быть не бросание исключения («всё сломалось!»), а, например, повторный выбор узла с сервисом и еще одна попытка вызова.
Технологии масштабирования
Для того чтобы ваша система могла масштабироваться, должны быть разработаны простые и надёжные механизмы. Назовем некоторые из них.
Мониторинг и метрики. Как решить, в какие моменты пора разворачивать/сворачивать сервис? На этот вопрос отвечают метрики, за которыми следит система мониторинга. Поэтому для начала она должна у вас присутствовать, и каждая компонента должна уметь отвечать на запрос о своём здоровье. Это могут быть счётчики длин внутренних очередей, загрузки процессора/памяти/дисков, количество запросов в секунду, за последнюю секунду.
Балансировка. Простым добавлением виртуальной машины (ВМ) в ваше облако производительность системы не поднять. Все ваши компоненты должны уметь автоматически развёртываться на новой машине: установка пакетов, настройка и конфигурация, репликация данных – всё это должно существовать в виде скриптов, запускаемых после создания новой ВМ.
Кроме того, свежесозданный экземпляр сервиса должен автоматически начать получать свою долю нагрузки. Для этого можно пользоваться разными механизмами, самыми простыми из них являются различные балансировщики нагрузки и Round Robin DNS.
Кэширование. Время доступа к сетевому сервису на порядки превышает время доступа к локальным данным. Поэтому сразу после того, как вы вынесли доступ к данным в отдельную службу, вы начинаете думать о том, как кэшировать их в остальных службах, где они нужны, – со всеми сопутствующими проблемами в виде дисциплины инвалидирования и обновления данных и консистентности кэшей между экземплярами служб. Неприятно, но зато кэширование позволит сохранить изолированность компонент при сохранении оперативной доступности данных.
Облачные службы. Провайдеры облачных услуг обычно предоставляют огромное количество готовых компонент, необходимых для создания масштабируемых приложений. Наиболее востребованные из них:
- облачный хостинг: виртуальные машины;
- облачное объектное хранилище: служба распределённого хранения прикладных объектов;
- облачная база данных: обеспечивает наличие реплицированной базы данных (реляционной и/или типа «ключ – значение»);
- облачный мониторинг и автомасштабирование: предоставляет услуги сбора статистики с узлов облака, мониторинга использования ресурсов и автоматического добавления/удаления сервисов;
- CDN (Content Delivery Net-works): обеспечивает доставку статического контента географически и топологически распределённым пользователям системы.
Информационная безопасность с самого начала
И ещё один важный аспект облачного приложения – безопасность. В условиях, когда каждый компонент вашей системы – отдельный сервис, очень важно, чтобы все его аспекты, связанные с безопасностью, были продуманы на самом раннем этапе. Модели данных, роли пользователей, модель нарушителя должны быть согласованными между собой компонентами.
Не нужно забывать о готовых инструментах обеспечения безопасности – PKI, SSL, шифрование данных – зачастую уже предоставляемых используемой инфраструктурой. Пожалуй, худшее, что можно придумать в этой области, – разработка собственных оригинальных механизмов и алгоритмов, не подвергшихся тщательному многолетнему изучению.

