 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
На заре эпохи информатизации любая задача загрузки, обработки, а часто и выгрузки большого объема данных из баз решалась уникальным способом. Данных, по нынешним меркам было немного, баз данных и того меньше, а трудозатраты никто и не считал. Постепенно объем данных, и, что особенно важно, количество используемых БД увеличивались. Всё очевиднее становилась идея создания средств, которые позволили бы не изобретать каждый раз велосипед, а решать задачу интеграции данных максимально быстро и просто. Из этой идеи, как грибы после дождя, стали расти и развиваться продукты, общее назначение которых можно было описать тремя словами Extract, Transform, Load.
На текущий момент на рынке существует превеликое множество ETL-решений различных производителей. Среди них есть и флагманские продукты от крупных корпораций, например, Informatica Power Center или Oracle Data Integrator, и Open Source решения, разрабатываемые сообществом, такие как Pentaho или Talend. Причём часто они мало чем уступают коммерческим системам, к тому же обеспечивается их высококвалифицированная платная техподдержка.
Поэтому мало кому сегодня взбредёт в голову пытаться организовать сбор данных для хранилища с помощью процедур, написанных на коленке, ведь даже в случае ограниченного бюджета остаётся возможность использования бесплатных средств. А даже сложная in-house разработка, скорее всего, подчистую проиграет в удобстве использования, гибкости а, возможно, и производительности любому ETL-продукту. Однако как только мы сталкиваемся с более общей задачей интеграции данных между информационными системами, не связанной с хранилищами, ETL отходит на второй план и в первую очередь начинают рассматриваться разработка собственных решений или привлечение интеграции приложений.
То есть за ETL закрепилась репутация инструмента наполнения хранилищ данных, безусловно, важного и полезного, но очень узкоспециализированного. А ведь возможности современных ETL-продуктов гораздо шире, с их помощью можно решать задачи интеграции распределенных систем, особенно в условиях недостаточности инфраструктуры, для организации синхронизации данных и создания единой точки ввода, обеспечения безопасности, наполнения систем данными из смежных систем в случае отсутствия соответствующих сервисов и т.п. Конечно, все эти задачи могут быть решены «правильным» способом – путём внедрения корпоративной шины, использования сервис-ориентированной архитектуры, модернизации аппаратной и программной инфраструктуры, но реальная жизнь всегда оказывается сложнее, где-то приходится усмирять «зоопарк» legacy-систем, где-то крайне ограничен бюджет, где-то очень сжатые сроки и т.д.
В этой статье мы постараемся пролить свет на такую тёмную сторону ETL, как ее использование в прикладных задачах в отрыве от хранилищ данных. Для наглядности мы рассмотрим несколько примеров такого применения. Сразу отметим, что все примеры были взяты из реальной жизни, и хотя использование именно ETL-средства могло поначалу показаться неоправданным, оно во всех случаях позволило просто, быстро, с минимальными затратами и, как показала практика, с достаточно высокой степенью надёжности решить задачи, поставленные бизнесом перед ИТ.
Всё очевиднее становилась идея создания средств, которые позволили бы не изобретать каждый раз велосипед, а решать задачу интеграции данных максимально быстро и просто. Из этой идеи, как грибы после дождя, стали расти и развиваться продукты, общее назначение которых можно было описать тремя словами Extract, Transform, Load
История первая. Приём на работу
Работа в любой компании для нового сотрудника всегда начинается с заведения его данных в многочисленных учётных системах, причём в небольших и средних организациях вносить эту информацию, как правило, приходится разным людям из разных подразделений. В результате возникают ситуации, когда принятый на работу сотрудник подолгу не может получить банковскую карту, потому что не был вовремя заведён в бухгалтерии, уже уволенные сотрудники имеют доступ к корпоративной почте и приложениям, потому что их учётная запись в домене не заблокирована, и т.д. Представим себе следующую «диспозицию»: в компании используются контроллер домена, применяющий LDAP, кадровая система на базе СУБД Oracle, система бюджетирования 1С, внутренний портал со штатным расписанием, почта, Help Desk. Все эти системы не знают о существовании друг друга, при этом требуется уменьшить количество процедур ввода данных о сотруднике в учётные системы, а также обеспечить выравнивание бизнес-процессов. В целом это типичная задача сквозной интеграции бизнес-процессов. Она так часто встречается, что для её решения существует отдельный класс продуктов – IdM (Identity Management, подробнее о них можно прочитать в Jet Info 1 5, 2010). Однако это практически всегда масштабные решения, внедряемые не один месяц и подразумевающие внушительные капиталовложения, а их в небольших и даже средних компаниях часто не хватает. Для налаживания взаимодействия между системами можно воспользоваться ETL, причем это не потребует значительного времени и сложной разработки. Для наглядности вся картина приведена на рис. 1.
Рис. 1. Интеграция бизнес-процессов с помощью ETL
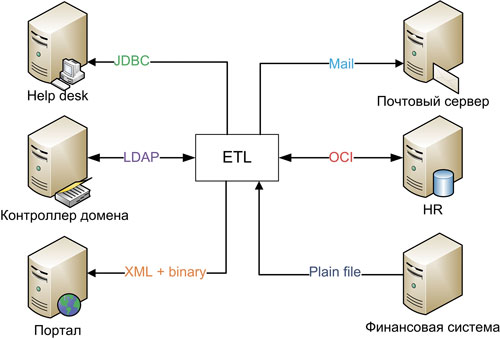
Итак, данные о новом сотруднике попадают в БД HR-системы: вводят его ФИО, должность, подразделение, дату рождения, табельный номер и добавляют фотографию. Для того чтобы сотрудник получил доступ к корпоративной сети и системам, учетную запись о нем требуется создать в Active Directory на контроллере домена (DC), это задача для специалистов Help Desk. И здесь в игру вступает ETL: заявка в системе на ввод данных нового сотрудника будет сформирована автоматически, поскольку ETL регулярно делает запрос в HR-систему для получения списка сотрудников без e-mail адреса (в рамках нашей компании это означает появление нового специалиста). Причём вводить массу информации, которая уже введена в штатное расписание, сотрудникам Help Desk не потребуется. Достаточно указать табельный номер, внести номер телефона подключенного сотрудника и его комнаты, а также e-mail. Эта информация будет передана обратно в штатное расписание, в то время как подразделение и должность попадут в контроллер домена, это обогащает обе системы нужными данными, не требуя при этом ручного ввода. Как мы уже отмечали, наша компания не крупная, поэтому опрос кадровой системы и контроллера домена раз в 5 минут с целью выявления данных, требующих синхронизации, никак не сказывается на их производительности. Это даёт ещё один неоспоримый плюс: в случае изменения e-mail или рабочего телефона, равно как и должности или подразделения вся информация будет синхронизирована автоматически.
Нужно отметить, что до того, как данные о сотруднике начнут распространяться по системам, происходит ещё одна важная проверка – достаточность бюджета подразделения для найма вакансии. Для этого используется простая выгрузка из финансовой системы, в случае если новый сотрудник не «влезает» в бюджет, заявка на ввод учётной записи в DC не формируется. В то же время создается письмо с отчётом, которое получают кадры, бухгалтерия и начальник подразделения для дальнейшего рассмотрения ситуации. Эта несложная с технической точки зрения операция позволяет выровнять вполне реальный бизнес-процесс и уменьшает количество инцидентов в бюджетировании. В реальности уже через несколько месяцев после её введения в эксплуатацию все начальники подразделений стали гораздо внимательнее относиться к найму нового персонала и согласовывать изменение бюджета заранее, а не по факту. И, что немаловажно, это не потребовало никаких репрессивных мер со стороны высшего руководства.
Наконец наш новый сотрудник принят и начались трудовые будни, но возникает вопрос: как проинформировать коллег о его номере телефона или электронном адресе, как им понять, какая у него должность, как он выглядит и когда можно праздновать его день рождения? Вся эта информация обычно представлена на внутреннем портале компании, но вводить её туда некому, а сам портал не обладает обширными связями с остальными информационными системами, фактически это простой web-сайт. И тут на помощь опять приходит ETL. Данные о сотруднике и его контактах попали в штатное расписание, откуда раз в день происходит выгрузка всей информации, в том числе его данных и фотографии в формате xml. Этот выгруженный файл и передается нашему порталу, где из него посредством xslt строится красивый и удобный список сотрудников, а также создаются уведомления о ближайших днях рождения.
Рано или поздно приходит время расстаться с нашим сотрудником. Обычно в таких случаях ему выдают длинный обходной лист, с которым нужно обойти все подразделения компании, преследуя цель отметить факт увольнения во всех учётных системах. Но и тут ETL может помочь – технология позволяет упразднить многие пункты обходного листа. Как только в HR-систему заносятся данные о дате окончания карьеры сотрудника на этом месте работы, информация о необходимости блокировки его записи поступает контроллеру домена, его почта автоматически архивируется, а почтовый ящик блокируется. При этом также возможен полуавтоматический режим с созданием заявки на блокировку в Help Desk. Как показала практика, такой режим может потребоваться для проведения кадровых перестановок.
Подведём итог. Мы смогли наладить взаимодействие между пятью разнородными системами, не имеющими штатных средств для интеграции, при этом в каждом из этих взаимодействий использовались разные способы доступа и форматы данных. Среди них были и прямой доступ в БД через JDBC-драйвер или OCI, и подключение к LDAP, и разбор плоского текстового файла, и формирование xml, и отправка почты. Да, это можно было реализовать с помощью написания собственного приложения, однако использование такого количества различных источников потребовало бы много времени на разработку. Фактически мы решили задачу интеграции сквозных бизнес-процессов без применения сложных и дорогостоящих технологий, и, что самое важное, на это было потрачено минимальное количество ресурсов и времени, а эффект был весьма ощутим.
История вторая. Разноска платежей
Другая задача, с которой так или иначе сталкивается большинство компаний, принимающих платежи от контрагентов через банки и платёжные системы, – это разноска платежей, то есть сопоставление информации, полученной в виде платёжных документов, с деньгами, поступившими на расчетный счёт. Часто это два независимых потока, которые сотрудники бухгалтерии или операционисты связывают вручную, при самом лучшем раскладе используемая корпоративная ИС имеет функционал автоматической привязки платежей.
В рассматриваемой нами компании информация о платежах поступает от платежной сети. Поскольку она содержит персональные данные, то в соответствии с 1 153-ФЗ поставляется в зашифрованном виде. Вторым потоком данных являются файлы в формате DBF, содержащие информацию о банках-контрагентах, которая требуется для геолокации платежа. И последними с минимальной задержкой в три банковских дня приходят деньги и выписка с платежами, проведёнными через банк-партнёр.
Нужно отметить, что в лоб эти потоки не связываются: номера документов, указанные в реестрах от платёжной системы и банка, не совпадают, а из-за особенностей работы банка дата платежа, которая значится в выписке, может не совпадать с датой реальной оплаты, которая содержится в реестре.
Рис. 2. Организация разноски платежей
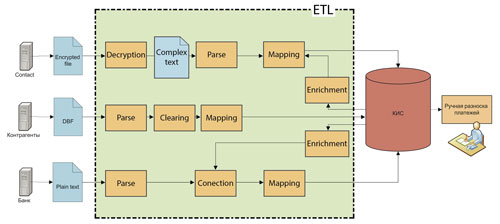
Процесс также осложняется тем, что файл реестра зашифрован, поэтому сначала требуется его расшифровать. Для этой цели платёжная система предоставляет консольную программу и набор ключей шифрования. В рассматриваемой компании был разработан несложный процесс трансформации: шифрованный файл забирают с внешнего FTP, помещают на локальный ресурс, а затем запускают преднастроенную программу для дешифровки.
За etl закрепилась репутация инструмента наполнения хранилищ данных, безусловно, важного и полезного, но очень узкоспециа- лизированного. А ведь возможности современных ETL-продуктов гораздо шире
На выходе специалисты получают текстовый файл сложной структуры, содержащий ФИО, телефон, паспортные данные плательщика, сумму и дату платежа, а также определённое количество дополнительных и технических данных. Немаловажно, что в последних содержится информация, идентифицирующая транзакцию, это позволяет в большинстве случаев связать платёж с данными из банковской выписки. Данные из реестра обогащаются информацией о банках-контрагентах (филиалах, подразделениях, городах и адресах отделений), после этого осуществляются их маппинг к конкретным полям таблиц корпоративных ИС и загрузка в базу. Естественно, обогащение данных происходит в рамках реляционной модели с использованием внешних ключей, кроме того, используются уже очищенные данные, загруженные в ИС. Отметим, что загрузка информации о банках и её очистка являются отдельным ETL-процессом. После прихода банковской выписки запускается ещё один процесс, задача которого состоит в сопоставлении ранее полученной информации о платежах с реально пришедшими деньгами. Так как выписки приходят из банка в текстовом формате, первым шагом трансформации является разбор файла, после этого идет процесс автоматической привязки платежей с использованием информации, ранее загруженной в корпоративную ИС из реестров платежей и банков. Нужно отметить, что в процессе привязки происходит сравнение не только ключей, идентифицирующих транзакцию (в некоторых случаях они не имеют пары), но и суммы и ФИО плательщика, а также отделения банка. Также решается задача исправления неверной даты платежа, указанной в банковской выписке, на реальную дату его совершения.
В итоге без привлечения сил разработчиков мы получили систему автоматической привязки платежей, при этом основные затраты были связаны с проектированием и изучением форматов файлов. На выходе происходит привязка до 90% платежей, что в условиях небольшой компании позволяет полностью снять с одного сотрудника обязанности проведения ручной привязки. По платежам, которые не привязываются автоматически, обогащение позволило существенно облегчить процедуру ручной привязки и даже повысило её эффективность. Например, наличие телефонного номера плательщика позволяет уточнить данные о платеже лично у него, геолокация платежа даёт информацию для аналитических отчётов, а также позволяет более эффективно отслеживать переводы от партнёров-брокеров.
Отметим, что описанная нами задача, как и первый случай, имеет чисто прикладной характер. Ÿ традиционное решение зачастую связано с работой разработчиков. Конечно, присутствие подобных задач говорит о незрелости бизнес-процессов компании, однако на этапе запуска бизнеса в России такое далеко не редкость. Использование ETL-средства в данном случае полностью оправдывает себя и не только позволяет автоматизировать процесс привязки платежей, но и высвобождает ресурсы, а также повышает качество, тем самым обеспечивая экономию бюджета компании.
Обе вышеприведенные истории нельзя рассматривать как некий Best Practice использования ETL, все же основной задачей этого инструмента остаётся интеграция данных. Но в условиях, когда функциональность продуктов ETL у большинства вендоров постоянно расширяется, использовать только 10% их потенциала неразумно. Современный ETL оставляет большое поле для экспериментов, часто позволяя решать задачи, не характерные для него, и делать это быстро, эффективно и с минимальным использованием навыков разработки.
