 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Введение
Рис.1. Эволюция сетевых технологий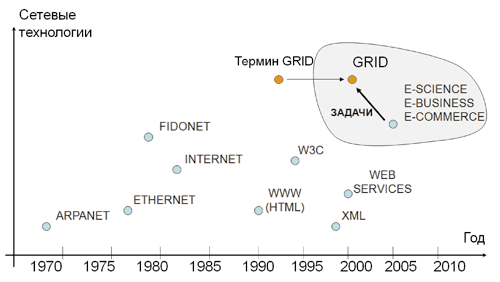
За время эволюции информационных технологий сама ГРИД не обособилась в отдельную сетевую вычислительную структуру, а напротив, за счет существующих прогрессивных технологий (протоколов) расширила области практического применения далеко за рамки чисто научных расчетов (см. Рис. 1) и из сферы e-Science перешла в e-Business.
Именно благодаря своей компонентной архитектуре и требованиям к существующим протоколам не составляет особого труда «развернуть» ГРИД-кластер в рамках отдельных организаций и осуществлять его дальнейшее расширение за счет присоединения дополнительных ресурсов.
Однако возникает вопрос о целесообразности, обоснованности и финансовой выгоде, которую можно получить от использования ГРИД-кластера при сдаче вычислительных мощностей в аренду. Как оценить рентабельность и производительность ГРИД-кластера? Как соотнести эти два параметра?
Структура ГРИД
Рассмотрим структуру ГРИД-системы на уровне виртуальных организаций (Рис.2). ГРИД состоит из совокупности ресурсов (сетевых, вычислительных и т.д.) объединенных в виртуальные организации. Виртуальная организация (Virtual Organization – VO) является динамическим сообществом людей и/или учреждений, которые совместно используют вычислительные ресурсы в соответствии с согласованными между ними правилами. Эти правила регулируют доступ ко всем типам средств, включая компьютеры, программное обеспечение и данные [3].
Таким образом, для доступа к распределенной системе вне зависимости от роли участника (пользователь или вычислительный узел, «производитель/потребитель») необходимым условием является принадлежность к той или иной виртуальной организации. На Рис. 2 пользователь userA и вычислительный узел hostA не могут получить доступ к системе, не являясь членами ВО, поэтому необходимо присоединиться (зарегистрироваться) к одной из существующих ВО (например, ВО А и ВО Б) или создать свою собственную, регламентировав отношения с ВО А и ВО Б.
Рис.2. Структура ГРИД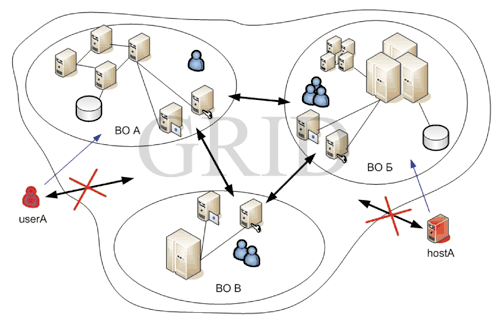
На основании структуры системы (Рис.2) необходимо выделить три основных позиции, которые влияют на методы оценки финансовых показателей ГРИД:
- Виртуальные организации не обозначают владение ресурсами, определенными в рамках их функционирования, они лишь устанавливают правила взаимодействия. Т.е. в рамках ВО ресурсы могут принадлежать разным финансовым учреждениям.
- Виртуальная организация владеет полной информацией о количестве ресурсов и пользователей, зарегистрированных в ней, однако не гарантирует их доступность и актуальность.
- Один и тот же GRID-ресурс может использоваться несколькими виртуальными организациями.
Таким образом, финансовые отношения, которые могут быть определены в рамках виртуальной организации, возможно описать только статическими моделями, что в свою очередь не позволяет определить динамику развития как системы в целом, так и ее отдельных частей.
Вертикальная и горизонтальная архитектура ГРИД
Для более четкого понимания структуры ГРИД-системы и построения ее детальной модели необходимо рассмотреть архитектуру ГРИД, обозначить ее отличие от высокопроизводительного кластера, суперкомпьютера или массива параллельных процессоров.
Для того чтобы определить функциональные и структурные отличия, целесообразно произвести декомпозицию ГРИД-системы в двух «плоскостях»:
- вертикальная архитектура;
- горизонтальная архитектура.
Рис. 3. Вертикальная архитектура ГРИД и Интернет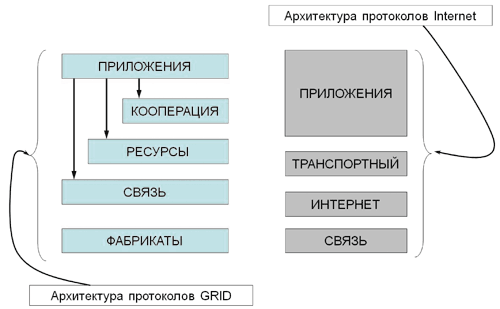
С точки зрения вертикальной архитектуры, ГРИД представляет собой стек протоколов, основанных на Интернете (Рис. 3) [4], поэтому необходимым условием присоединения ресурса является поддержка этих протоколов.
На сегодня практически любой вычислительный ресурс может быть подключен к глобальной сети, поэтому при построении модели ГРИД-системы считаем это условие выполненным и не будем учитывать нижележащие протоколы. Более подробно о назначении каждого уровня можно ознакомиться в[4].
Под горизонтальной архитектурой будем понимать совокупность сервисов, размещенных на уровне приложений (Application) (Рис.4).
Рис. 4. Вертикальная и горизонтальная архитектура ГРИД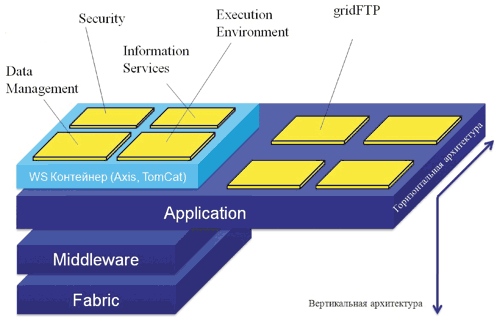
Для организации взаимодействия в рамках ГРИД-системы на этом уровне реализованы сервисы удаленного доступа:
- запуска заданий;
- пересылки файлов;
- мониторинга задач;
- авторизации и аутентификации;
- и т.д.
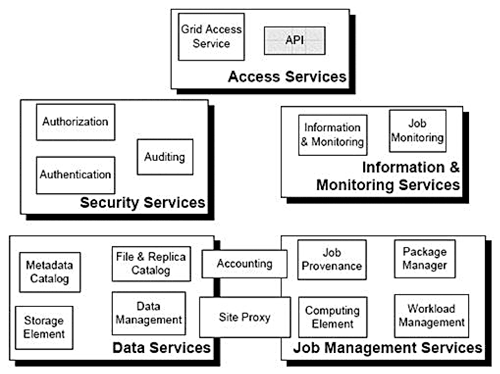
По мере развития сети Интернет с появлением технологии веб-сервисов [5] для достижения универсальности и повышения интероперабельности компонентов большинство функций в ГРИД-системе реализовано в виде сервисов (Рис. 4). Основным стандартом, описывающим сервис-ориентированную архитектуру ГРИД-системы, является Open Grid Services Architecture (OGSA) [6], которая определяет основные службы, функционирующие на уровне приложений и необходимые для построения ГРИД:
- Execution Management services (исполнительная подсистема);
- Data services (службы для работы с данными);
- Resource Management services (службы управления ресурсами);
- Security services (службы обеспечения безопасности);
- Information services (службы мониторинга и информации);
- Self-management services (службы самоуправления).
Зачастую последняя группа служб (Self-mangement) интегрируется в оставшиеся пять и в явном виде стандарт не требует ее отдельной реализации в ГРИД.
Рис. 5. ГРИДслужбы: а) в Globus; б) в gLite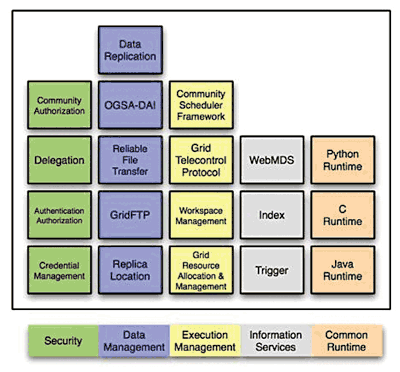
Чтобы понять, как отмеченные выше сервисы повлияют на предложенную ниже модель ГРИД-системы, необходимо рассмотреть их роль и функциональную зависимость на примере конкретных программных комплексов. Существует большое количество проектов и решений в области ГРИД, реализующих методы и разрабатывающих инструментальные средства имплементации ГРИД-систем. Рассмотрим два программных продукта – Globus [7], который стал стандартом де-факто и признан [8] многими мировыми производителями компьютерной индустрии: IBM, SGI, Sun Microsystems, Fujitsu, Hitachi, NEC, Veridian, Entropia, Platform Computing Inc, Microsoft, Compaq и gLite [9], распространение которого начато в рамках европейского проекта EGEE (Enabling Grids for E-Science) [10].
На Рис. 5 приведены рассмотренные выше группы служб, формирующие ядро ГРИД, которые в свою очередь состоят из набора отдельных сервисов, реализующих функциональность своей группы (на примере Globus и gLite).
Таким образом, любая вычислительная единица или ресурс (кластер, отдельный компьютер, сервер баз данных и т.д.), подключающийся к ГРИД, должен:
- поддерживать вертикальную и горизонтальную архитектуру ГРИД;
- принадлежать к одной или более группам служб (стандарт не оговаривает и неустанавливает ограничения на количество служб, установленных на одном компьютере, единственное ограничение – это снижение производительности);
- зарегистрироваться в ВО, в рамках которых он будет функционировать (узел может функционировать в рамках нескольких виртуальных организаций, зачастую используется именно такой подход).
Рис.6. Общий алгоритм решения задачи в рамках ГРИД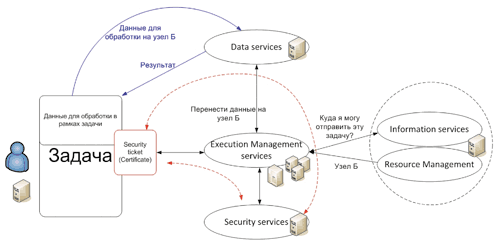
Общий алгоритм взаимодействия пользователей и сервисов в рамках ГРИД (Рис.6) следующий (подробная информация приведена в документации к программному обеспечению, например [9, 11]):
- Аутентификация пользователя с помощью механизма сертификатов.
- Пользователь формирует задачу, которая состоит из исполнительных файлов и данных для обработки.
- Пользователь отправляет задачу на выполнение, используя сервисы среды исполнения.
- Среда исполнения в свою очередь определяет и находит, с помощью информационных сервисов, вычислительные ресурсы, необходимые для решения задачи.
- После определения подходящего узла (или совокупности узлов) сервисы исполнения дают указание службам управления данными поместить необходимые файлы для обработки на найденный узел.
- После выполнения расчетов результат возвращается пользователю.
Следует также понимать, что все сервисы, необходимые для реализации ГРИД-системы, можно физически разместить на одном компьютере (на одном процессоре) или, например, часть реализовать на одном компьютере, а остальные – на другом. Такой подход абсолютно не приемлем, так как производительность узла падает пропорционально количеству реализуемых им сервисов (ролей), поэтому в реальных ГРИД один и тот же сервис, может быть продублирован на нескольких физически раздельных компьютерах.
Очевидно, что с увеличением количества узлов, выполняющих одну и ту же роль, повышается производительность как отдельных частей ГРИД-системы, так и всего окружения в целом. Однако с увеличением ресурсов увеличиваются и финансовые затраты на введение новой единицы техники, связанные с ее обслуживанием и дальнейшим сопровождением.
Таким образом, возникает актуальная задача оптимального развития ГРИД, заключающаяся в минимизации затрат на сопровождение инфраструктуры, с одной стороны, и повышения производительности – с другой. Предложенная нами упрощенная модель оценки стоимости и производительности ГРИД-системы позволяет:
- выбрать оптимальное количество узлов для получения наибольшей прибыли;
- рассчитать эксплуатационные затраты, связанные с необходимостью поддержки требуемого уровня пропускной способности;
- рассчитать производительность ГРИД-системы, которую можно обеспечить на основе имеющихся денежных средств.
Экономическая парадигма ГРИД-вычислений
С расширением сферы применения ГРИД-технологий до e-Commerce и e-Business достаточно актуальной стала идея продажи ресурсов, сдачи их в аренду или получения прибыли от вычислений, проводимых третьей стороной. Существует довольно большое количество публикаций и исследований, направленных на разработку и анализ распределения ресурсов в ГРИД-системах, с использованием экономического подхода [12-16] или получение прибыли от предоставления ресурсов.
Рис. 7. Формализация процесса торговли ресурсами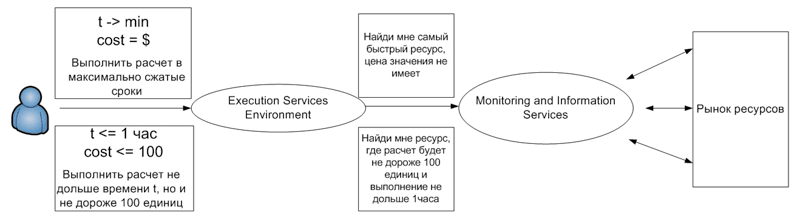
При экономическом подходе благодаря интероперабельности и масштабируемости ГРИД не изменяет свою структуру, а наоборот расширяет ее за счет введения дополнительных сервисов, отвечающих за так называемую торговлю ресурсами. Расширение производится на уровне информационных сервисов и сервисов мониторинга, а также за счет введения дополнительных механизмов описания стоимостных показателей (Рис.7).
При формировании требований, предъявляемых к решению задач, могут использоваться более сложные условные формы, чем стоимость и время обслуживания (Рис. 7). В частности, могут вводиться требования к надежности и достоверности полученных результатов, тогда в ГРИД-окружении принимаются решения о привлечении дополнительных ресурсов (дублирующих) для повышения надежности и диверсности полученных результатов и их последующий анализ. Все эти характеристики могут формировать (увеличивать или снижать) стоимость выполнения задачи ГРИД.
Модель ГРИД
Исследования и методики, приведенные в [12-16], не учитывают стохастическую природу как потоков задач в ГРИД, так и обслуживающих сервисов. Очень часто решение о выделении ресурсов на выполнение той или иной задачи формируется на этапе ее постановки, в то время как эти ресурсы уже были распределены между другими задачами, имеющими более низкий приоритет. Кроме того, возникают ситуации, когда для решения задач выделено больше ресурсов, чем можно было бы для поддержания соответствующего уровня сервиса, в результате чего уменьшается прибыль вследствие сдачи «лишних» узлов.
На основе структуры (Рис. 2) и горизонтальной архитектуры (уровень приложений) ГРИД-системы (Рис. 4) разработана модель ГРИД с использованием математического аппарата теории массового обслуживания (ТМО), которая учитывает характер потока заявок, поступающих в систему и интенсивность обработки задач. Данная модель позволяет рассчитать оптимальный по стоимости ГРИД-кластер, удовлетворяющий требованиям входящего потока задач.
Для наглядной демонстрации предложенного подхода построим упрощенную модель ГРИД-окружения и механизм денежного потока (Рис.8).
Рис. 8. Механизм денежного обращения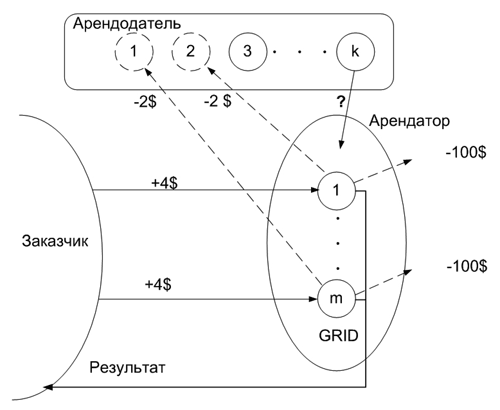
Согласно приведенной модели, в рамках финансовых отношений существует три субъекта:
- заказчик (пользователи, реализующие свои задачи);
- арендатор (субъект, содержащий ГРИД-кластер, состоящий из m вычислительных узлов);
- арендодатель (субъект, располагающий некоторым количеством ресурсов, сдаваемых в аренду).
Пусть количество вычислительных узлов m и в среднем в систему поступает l=8 заявок в день, при этом поток заявок носит пуассоновский характер [17, 18]. Среднее значение количества задач в рамках заявки Sz=5 (при норме обслуживания узлом 7 задач в день) следовательно, интенсивность обслуживания одного узла составит m=7/5=1,4 заявок в день. Для того чтобы исключить невыполнение обработки заявок в срок, система не принимает новые задачи, если ее очередь уже составляет n=6 заявок. За каждую выполненную задачу арендодатель получает 2 ден. ед., а также 100 ден.ед. ежемесячно с каждого узла, сданного в аренду (техническая поддержка, оплата электроэнергии и т.д.). При этом заказчик платит за каждую выполненную задачу по 4 ден.ед. (входные параметры предложенной модели для наглядности взяты из примерав [17]). Необходимо вычислить основные характеристики ГРИД-кластера (пропускная способность, производительность и т.д.), определить наиболее оптимальное количество вычислительных узлов, необходимых для получения максимальной прибыли арендатором от выполнения потока задач с заданной характеристикой.
Наиболее удобно и целесообразно рассмотреть описанную выше модель в виде многоканальной системы массового обслуживания (СМО) с ограниченной очередью [18].
Рис. 9. Граф функционирования СМО типа M/M/m/n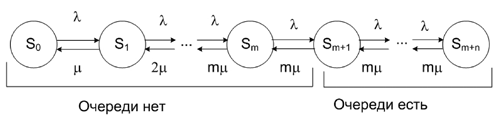
Пусть на вход СМО, состоящей из m каналов обслуживания, поступает пуассоновский поток заявок с интенсивностью l. Интенсивность обслуживания заявки каждым каналом равняется m, а максимальное число мест в очереди равняется n. Граф состояний и переходов такой системы представлен на Рис. 9.
В СМО такого типа в очереди может находиться не более n заявок, т.е. n+1 заявка отклоняется. Согласно принятым допущениям, поток заявок – пуассоновский, время обработки – случайная величина, распределенная по экспоненциальному закону, поэтому, согласно нотации Кендалла [18], ГРИД-системы можно рассматривать как СМО типа M/M/m/n (где M – экспоненциальное распределение, m – количество обслуживающих устройств, n – длина очереди ожидания). Таким образом, мы имеем СМО типа M/M/4/6, где l=8 и m,=1,4 заявок в день, по условию.
Следовательно, для такого типа СМО нагрузка на ГРИД-систему вычисляется по формуле (1) [17]:
где ?– интенсивность потока заявок, ?– интенсивность обслуживания потока одним узлом, m – количество узлов.
Вероятность простоя такой системы вычисляется по формуле (2) [18]:
а вероятность отказа в обслуживании [18] в нашем случае (3):
где m – количество каналов обслуживания, n – размер очереди.
Достаточно важным показателем, который необходим при анализе системы, является средняя длина очереди, вычисляемая по формуле (4) [18]:
Проведение вычислений
Проведем вычисления согласно формулам (2)-(4), когда в системе изменяется количество вычислительных узлов (ГРИД-узлов для обработки задач), т.е. m=1:12. Полученные расчеты занесем в таблицу для дальнейшего анализа (Табл. 1). Основные вычислительные параметры в таблице следующие: r – нагрузка на кластер, P0 – вероятность простоя системы, Pотк – вероятность отказа в обслуживании, Pобсл – вероятность обслуживания, q – среднее количество заявок, ожидающих выполнения, U – коэффициент загрузки, S – среднее число занятых каналов, k – среднее число заявок в СМО, g – пропускная способность, w – среднее время пребывания заявки в очереди, t – среднее время пребывания заявки в СМО.
Таблица 1. Основные характеристики ГРИД-системы для различного количества обслуживающих узлов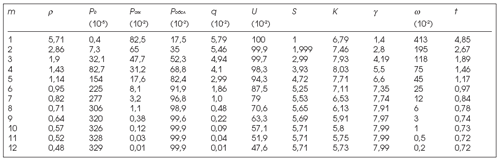
Для наглядности построим график зависимостей вероятности обслуживания Робсл и Ротк от количества эксплуатируемых узлов (Рис.10). Нетрудно заметить, что с увеличением количества узлов вероятность получения отказа в обслуживании падает, однако с вводом в эксплуатацию дополнительного компьютера увеличиваются расходы на техническое сопровождение.
Рис. 10. График зависимости вероятностей Робсл и Ротк от количества узлов m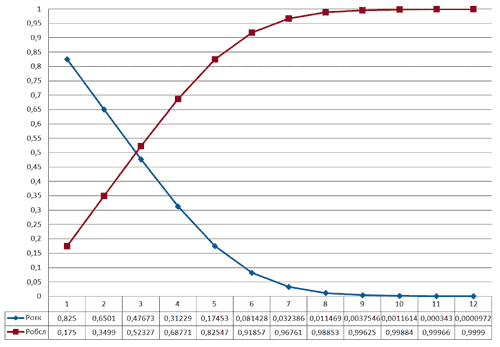
Произведем расчет прибыли M на основе полученных характеристик ГРИД-системы, который будет составлять разницу между выручкой (доходом) Mv и выплатами за аренду(расходами) Ma:
Средняя выручка за месяц составит:
где gm – среднее количество выполняемых задач в день gm=l*Pобсл для количества узлов m. (Табл.1);
Sz – среднее количество задач в заявке (по условию Sz=5);
Mdv – цена за выполнение одной задачи для заказчика Mdv=4 ден.ед. по условию.
Т – количество рассчитываемых дней Т=30.
Средние издержки, выплачиваемые за аренду узлов в месяц, составят:
где параметры аналогичны (6), Mda – арендная стоимость за задачу, Mda=2 по условию.
Также необходимо учесть ежемесячные отчисления в размере 100 ден.ед., выплачиваемые каждым узлом, тогда:
Таким образом, согласно (5), (6) и (8), для m=4 имеем:
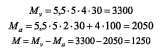
Определим количество узлов, при котором прибыль M будет максимальной, для этого выполним вычисления согласно (5), (6), (8) для m=1:12. Полученный результат занесем в таблицу 2. Динамику изменения прибыли в зависимости от количества арендованных узлов отобразим на графике (Рис.11).
Рис.11. Динамика изменения прибыли от количества узлов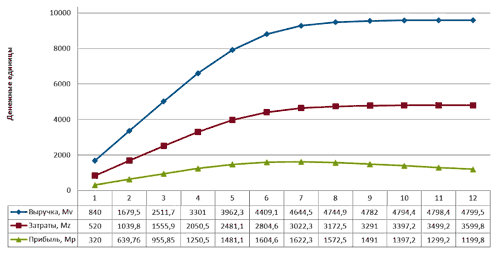
Анализ результатов расчетов показывает, что наибольшая прибыль составляет 1622 ден.ед. при m=7, однако следует отметить, что при увеличении количества узлов, прибыль, получаемая арендодателем с каждого сданного узла по отдельности уменьшается (см. (8) параметр m и gm) и составляет:
Динамика изменения прибыли на один узел Mu с увеличением узлов m (Табл. 2) приведена на Рис. 12.
Таблица 2. Изменение прибыли при увеличении количества обслуживающих узлов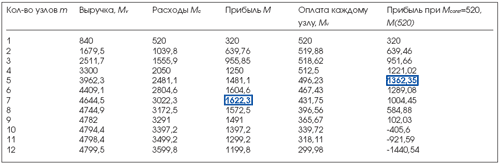
Рис.12. Прибыль арендодателя на каждый узел с увеличением m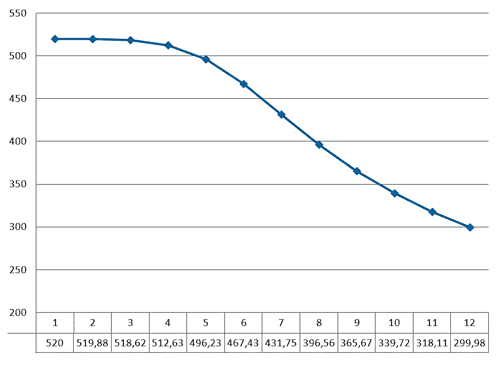
Очевидно, что такой порядок дел не устраивает арендодателя, когда при сдаче очередного узла, доход на каждый отдельный узел уменьшается. Поэтому арендатор вынужден удерживать уровень выплат на отметке 520 ден.ед. за каждый новый узел, вводимый в эксплуатацию. С учетом внесенных замечаний сделаем перерасчет прибыли M при Mconst=520 для m=1:12, тогда:
Полученные результаты занесем в таблицу 2.
На основании полученных результатов (10) построим график зависимости прибыли арендатора от количества узлов и с учетом поддержки выплат на уровне 520 ден.ед. (Рис. 13).
Рис. 13. График зависимости прибыли арендатора от количества узлов и с учетом поддержки выплат науровне 520 ден.ед.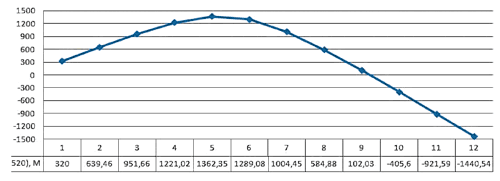
Таким образом, при увеличении количества узлов увеличивается прибыль, которая достигается за счет уменьшения отказов и повышения пропускной способности. Еще одним преимуществом является снижение времени выполнения задачи, например при m=4; t=1,46 дня, а при m=6; t=0,967 дня.
Негативной стороной увеличения количества узлов является потеря арендодателем прибыли при сдаче очередного узла в аренду, при m=1 он получает 520 ден.ед. за узел, а при m=7 получает 431,75 ден.ед. с каждого узла.
С учетом поддержания выплат на уровне 520 ден.ед. был сделан перерасчет, поэтому наиболее выгодным соотношением «цена/производительность» является m=5 узлов, при этом прибыль арендатора составит 1362,35 ден.ед.
Заключение
Приведенная выше модель ГРИД-системы имеет довольно большое количество допущений, поэтому использовать такой подход можно на ограниченных наборах GRID-компонентов или отдельных вычислительных кластерах, входящих в состав системы.
В рассмотренном примере для наглядности расчета финансовых показателей были взяты достаточно простые входные данные для построения модели СМО, на самом деле поток заявок в ГРИД носит сложный характер, причем в разных частях системы он может быть неоднороден [19-21]. Количество узлов для обработки задач также может динамически изменяться как во времени, так и в пространстве (мы же рассматривали бесперебойное функционирование узлов на протяжении 30 дней). Еще одним немаловажным фактом является то, что нами не была учтена последовательность прохождения заявок в системе (авторизация, отправка задачи в среду исполнения, перемещение данных, необходимых для обработки, возвращение результата и т.д.).
Для устранения рассмотренных недостатков нами было выделено два основных направления дальнейшего исследования:
- Разработка модели ГРИД на основе сетей Петри с очередями (Queueing Petri Nets – QPN) [22, 23], учитывающей качественные и количественные показатели оценки функционирования сетей такого рода. Использование данного подхода позволяет существенно упростить модель ГРИД-системы за счет уменьшения количества используемых вершин и переходов при формализации модели ГРИД в терминах сетей Петри, а также провести количественный анализ (производительность, отказоустойчивость, время простоя и т.д.) отдельных компонентов.
- Анализ потоков задач в ГРИД-системе, как на входе в систему, так и на уровне отдельных компонентов. Анализ публикаций по исследованию сетевого трафика в глобальной сети Интернет показал, что применение моделей на основе пуассоновского распределения не подходит для описания сетевых потоков [24 – 26].
Литература
- Stockinger H. Defining the grid: a snapshot on the current view // The Journal of Supercomputing, vol. 42. – 20-10-2007. – P. 3-17.
- Treadwell J.. Open Grid Services Architecture Glossary of Terms Version 1.6. GFD.120. Hewlett-Packard. December 12, 2007. http://forge.gridforum.org/projects/ogsa-wg
- http://grid.sinp.msu.ru/grid/roc/voinrdig
- Foster I., Kesselman C., Tuecke S. The Anatomy of the Grid: Enabling Scalable Virtual Organizations // International Journal of High Performance Computing Applications, 15 (3). – 2001. – P. 200-222.
- http://en.wikipedia.org/wiki/Web_service
- Foster I., Kishimoto H., Savva A., Berry D., Grimshaw A., Horn B., Maciel F., Siebenlist F., Subramaniam R., Treadwell J., Von Reich J. The Open Grid Services Architecture, Version 1.5. – 24 July 2006.
- Foster I., Kesselman C. Globus: A Metacomputing Infrastructure Toolkit // International Journal of Supercomputer Applications, 11(2). – 1997. – P. 115-128.
- 12 Companies Adopt ISI/Argonne Lab Globus Toolkit as Standard Grid Technology Platform. ISI News, 12 Nov 2001. http://www.isi.edu/news/news.php?story=25.
- http://glite.web.cern.ch/glite/
- http://public.eu-egee.org/intro/
- http://www.globus.org/toolkit/docs/4.0/
- Buyya R., Abramson D., Giddy J. A Case for Economy Grid Architecture for Service Oriented Grid Computing // In Proc. of 10th IEEE International Heterogeneous Computing Workshop (HCW 2001), San Francisco, CA. – Apr. 2001.
- Chun B. N., Culler D. E. User-centric Performance Analysis of Market-based Cluster Batch Schedulers // in Proc. of 2nd IEEE International Symposium on Cluster Computing and the Grid (CCGrid 2002), Berlin, Germany – May 2002.
- Waldspurger C. A., Hogg T., Huberman B. A., Kephart J. O., Stornetta W. S. Spawn: A Distributed Computational Economy // IEEE Trans. Software Eng., vol. 18, no. 2. – Feb. 1992. – P. 103-117.
- Chun B. N., Culler D. E. Market-based Proportional Resource Sharing for Clusters // University of California at Berkeley, Computer Science Division, Technical Report CSD-1092. – Jan. 2000.
- Chee Shin Yeo, Buyya R. A taxonomy of market-based resource management systems for utility-driven cluster computing // Software Practice and Experience, 36(13). – 2006. – P. 1381-1419.
- Смородинский С.С. Оптимизация решений на основе методов и моделей мат. программирования: Учеб. пособие по курсу «Систем. анализ и исслед. операций» для студ. спец. «Автоматизир. системы обраб. информ.» дневн. и дистанц. форм обуч. / С.С. Смородинский, Н.В. Батин. – Мн.: БГУИР, 2003. – 136 с.: ил.
- Дудин А.Н., Медведев Г.А., Меленец Ю.В. Практикум на ЭВМ по теории массового обслуживания [Электронный ресур]: Учебное пособие – Мн.: «Электронная книга БГУ», 2003.
- Li H. Workload dynamics on clusters and grids // Technical Report 2006-04, Leiden Institute of Advanced Computer Science, Leiden University, 2006.
- Li H., Muskulus M. Analysis and modeling of job arrivals in a production grid // ACM SIGMETRICS Performance Evaluation Review, v.34 n.4. – March 2007. – P.59-70.
- Li H., Muskulus M., Wolters L. Modeling Long Range Dependent and Fractal Job Traffic in Data-Intensive Grids // Technical Report TR No. 2007-03, Leiden Institute of Advanced Computer Science, April 2007.
- Bause F., Beilner H.. Analysis of a combined Queueing-Petri-Network World. Forschungsbericht Nr. 383 des Fachbereichs Informatik der Universitat Dortmund. – 1991.
- Kounev S., Nou R., and Torres J. Autonomic QoS-Aware Resource Management in Grid Computing using Online Performance Models // In 2nd International Conference on Performance Evaluation Methodologies and Tools (VALUETOOLS 2007), October 23th-25th, Nantes, France, ISBN: 978-1-59593-819-0, October 2007.
- Leland W. E., Taqqu M., Willinger W., Wilson D. V. On the Self-Similar Nature of Ethernet Traffic // Proc. SIGCOM93, San Francisco, California. – 1993. – P. 183-193.
- Paxson V., Floyd S. Wide-area Traffic: The Failure of Poisson Modeling // IEEE/ACM Transactions on Networking. – June 1995. – P. 226-244.
- Zhu X., Jie Yu, Doyle J. Heavy tails, generalized coding, and optimal Web layout // INFOCOM 2001. Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies. Proceedings. IEEE, Vol. 3. – 2001. – P. 1617-1626.

