 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Представим вполне стандартные для ведения «ИТ-хозяйства» ситуации: мы добавили новый instance базы данных на сервер БД или новое задание резервного копирования (РК), подключили дополнительный сервер к дисковому массиву и во всех этих случаях столкнулись со снижением его производительности. Далее действовать можно по-разному.
Например, добавить сервер БД и перенести на него экземпляр базы данных, «пристегнуть» дополнительные резервные накопители, чтобы ускорить процесс РК, провести апгрейд процессоров и т.д. Но нужно понимать, что этот путь – простого наращивания аппаратных мощностей – наименее выгоден с точки зрения временных и материальных затрат. Гораздо эффективнее решать подобные проблемы на уровне логики работы ИТ-решений.
Почему буксуем
Зачастую проблемы с производительностью дискового массива связаны с тем, что при его изначальном конфигурировании не учитываются его архитектура, принципы функционирования, существующие ограничения. Так, если рассматривать массивы старого поколения, то их ахиллесова пята заключается в относительно невысокой пропускной способности внутренних шин – около 200 Мб/сек. К нам не так давно обратился один с заказчиков с просьбой проанализировать работу его дискового массива и дать рекомендации по ее оптимизации. Массив по факту был не загружен, при этом его скорость периодически оставляла желать лучшего. Анализ показал, что он был неправильно сконфигурирован: если брать сутки в целом, все внутренние диски были загружены примерно одинаково, но пики нагрузки распределялись по ним неравномерно. В результате одна из внутренних шин перезагружалась. То есть дисковый массив «буксовал» из-за превышения максимально допустимого порога у одной компоненты. Мы порекомендовали переразбить его для равномерной загрузки внутренних шин, после чего производительность возросла на 30%.
Кроме того, ошибка может закрасться при подключении серверов к системам хранения данных. Можно неправильно сконфигурировать дисковую емкость, которая презентуется хостам. Дело в том, что часть современных дисковых массивов имеет ограничения по такому параметру, как очередь команд (Queue Depth, QD). Здесь предлагаем немного углубиться в историю. В стандарте SCSI-I SCSI-драйвер сервера должен был дождаться выполнения одной команды и только после этого отправлять следующую. Со стандарта SCSI-II и выше SCSI-драйвер может отправить SCSI-диску одновременно несколько команд (QD). Максимальное количество SCSI-команд, параллельно обслуживаемых диском, является одной из его важнейших характеристик. Параметр IOPS (Input Output Operation per Second) показывает, какое количество запросов (SCSI-команд) может выполнить SCSI LUN в секунду. Соответственно, QD и IOPS могут вступать в непримиримое противоречие друг с другом.
В результате не исключена следующая ситуация: на стороне сервера характеристики ввода-вывода неприемлемы, время отклика на запросы очень большое, а дисковый массив не нагружен. Причина – неправильная настройка очереди команд (выше допустимого). В этом случае команды зависают в буфере массива до тех пор, пока не подойдёт их очередь на исполнение. На сервере же регистрируются большие service time.
Если же QD существенного ниже оптимального значения, вы также столкнетесь с неудовлетворительной производительностью. Время отклика будет замечательным, дисковый массив будет не загруженным, но количество обрабатываемых массивом запросов будет очень маленьким. Виной всему – большое время ожидания в очереди перед отправкой запросов к СХД.
Как поймать IOPS за хвост и не упустить?
Что делать, если время отклика зашкаливает, а дисковый массив не загружен? Или если просто хочется «выжать» из массива еще чуть-чуть?
Можно:
- посмотреть на настройки Queue Depth на сервере и сравнить максимально допустимую очередь команд с LUN массива. Сделать правильные настройки;
- посмотреть на статистику с массива. Возможно, на нем копится очередь команд к LUN;
- разбить один LUN на несколько и «склеить» на хосте в stripe или хотя бы в конкатенацию в зависимости от конфигурации. Конкатенация поможет в том случае, если нагрузка распределится по всем LUN.
- выбирать размер stripe unit size на дисковом массиве и хосте таким образом, чтобы характерная операция со стороны приложения нагружала как можно меньше физических дисков в массиве.
Рис. 1. Stripe Unit Size
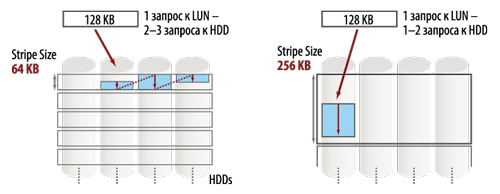
Здесь можно привести пример из нашего опыта: связка «сервер–массив» у заказчика не показывала заявленный уровень производительности. Анализ выявил, что серверу был дан очень большой LUN – на несколько терабайт, работа приложений была неудовлетворительной, а сам LUN был перегружен по очереди команд. Мы рекомендовали разбить этот LUN на несколько и разнести виды нагрузки на разные тома. На сервере «крутились» 4 instance баз данных, в итоге один из них начал работать в 6 раз быстрее, другой – в 2 раза.
Больше – не всегда лучше
Периодически мы сталкиваемся с тем, что ИТ-специалисты компаний-заказчиков не всегда понимают, какой тип RAID оптимальнее использовать для того или иного профиля нагрузки со стороны приложений. Все знают, что RAID 10 надежен, устойчив к потере нескольких дисков, показывает хорошую скорость на случайных операциях. Соответственно, чаще всего выбирают этот, весьма дорогостоящий вариант. Однако если приложение создает профиль нагрузки, подразумевающий мало операций случайной записи и много операций чтения или последовательной записи, лучше использовать RAID 5. На том же количестве дисков он может работать в полтора, а то и в два раза быстрее. Одна компания обратилась к нам с просьбой улучшить характеристики дискового ввода/ввода для одного из ее приложений. Приложение создавало большое количество операций чтения и незначительное число операций записи. На дисковом массиве был сконфигурирован RAID 10, и по анализу статистики было видно практически полное простаивание половины дисков в RAID-группе. Клиенту порекомендовали перейти на RAID 5 из точно такого же количества физических дисков, в результате удалось улучшить работу приложения более чем в полтора раза.
Практически каждая компания, эксплуатирующая вычислительный комплекс, сталкивается с проблемами производительности. Приведённые здесь примеры не единственные. Достаточно большое количество проблем, связанных с неудовлетворительной работой массивов, можно избежать, конфигурируя оборудование исходя из его архитектуры и предварительного анализа профиля нагрузки со стороны приложений. Дополнительно стоит отметить, что улучшение работы вычислительного комплекса не должно замыкаться на какой-то одной его составляющей – дисковом массиве, сервере, ПО или сети передачи данных. Наиболее продуктивные результаты будут достигнуты после проведения анализа всего комплекса в целом и изменения конфигурации не только массива, но и сервера и приложений.

